基于CRF和多元规则的层次化句法分析
2020-11-26杨陈菊皮乾东邵玉斌
杨陈菊, 孙 俊, 皮乾东, 邵玉斌, 龙 华
(昆明理工大学 信息工程与自动化学院, 昆明 650504)
句法分析是信息抽取、 机器翻译、 问答系统等应用不可缺少的部分, 是语义理解的基础,如张建明等[1]提出结合语义概念进行复杂事件抽取. 句法分析分为短语结构分析和依存句法分析. 其中短语结构句法信息丰富, 并且可根据转化规则将结构句法分析的结果转换为依存结果, 反之则不行[2], 表明短语结构句法树比依存句法树有着更广泛的范畴.
早期句法分析性能依赖于人工总结的规则, 近年来机器学习方法已广泛应用于组块识别, 并进行句法分析. 其中使用条件随机场(conditional random field, CRF)的效果最好[3], 但这些研究只是对原始语句进行了组块识别. 随着深度学习的发展, 神经网络逐渐应用于图像[4-5]、 文本等方面, 对句法的研究也不再停留于浅层分析: 皮乾东等[6]基于汉语语序算式化融合设计了句法分析器; 贾继康等[7]通过规则合成的方法进行了层次化语句识别; 谷波等[8]提出了一种基于RNN(recurrent neural network)的中文二分结构句法分析, 但忽略了中文部分语句不满足二分结构而满足三元结构的语句状况, 这也是其句法分析正确率偏低的一个原因. 在英文句法分析中, Nguyen等[9]提出了一种改进的神经网络模型进行词性识别和依存句法分析, 在实验语料中效果较好; Kitaev等[10]提出了自注意力(Self-Attentive)机制的编码方式以及分离位置信息和内容信息等进行结构句法分析, 提高了句法分析的准确率. 但使用深度学习进行句法分析, 会对汉语研究逐渐黑盒化.
在目前对句法分析的研究成果中, 基于规则方法中词语搭配的规则太多, 并且规则搭配的优先级反复变动; 基于深度学习方法的可解释性较差, 数据资源和计算力成本高, 且仍不能得到较好的句法分析结果. 现有句法分析的组块识别环节通常只能识别出一种结果, 或者根据所需值识别出细粒度的组块, 或者只识别粗粒度的组块, 而在层次句法分析中, 在低层次需要识别细粒度的组块, 而在高层次需要识别出粗粒度的组块, 从而需要训练很多模型去识别不同粒度的组块. 为解决该问题, 本文提出一个结合CRF和多元规则的层次化句法分析模型. 在使用具有特定参数模板CRF算法训练好的模型下, 首先对具有词性标注的细粒度语句进行组块识别, 将这些新识别出的组块分配新的词性, 识别出的组块及未识别的词语块构成一个具有词性标注的粗粒度语句, 然后使用具有不同优先级的二元、 三元规则对粗粒度语句做进一步的组块分析.
1 模型构建
1.1 组块的定义与处理
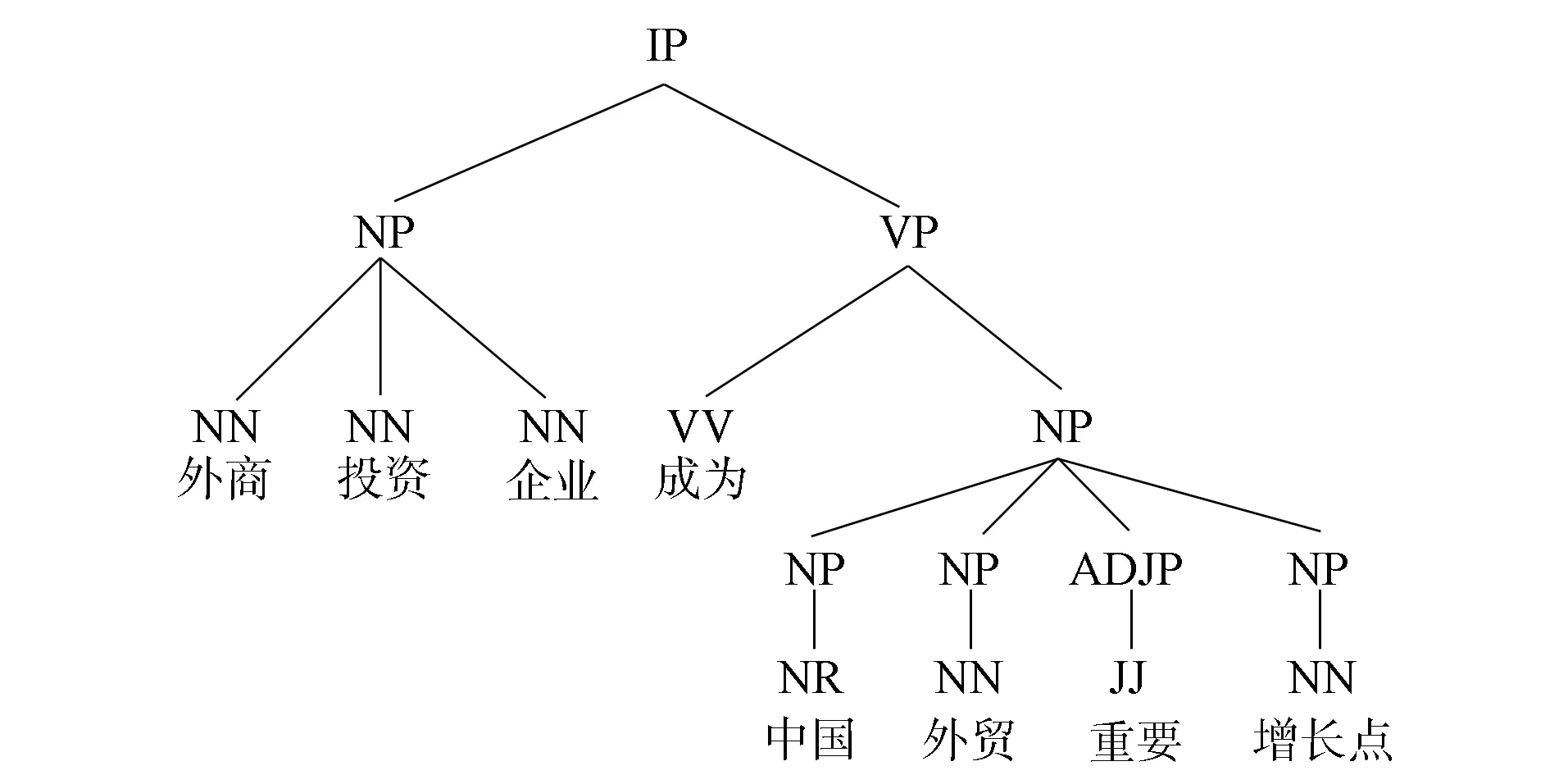
图1 结构句法树Fig.1 Structure syntax tree
句法分析是分析各词语之间的组合和搭配关系, 最终形成一棵句法树, 如图1所示, 关联大的词语更易形成一个词组. 图1中: IP表示一个简单句子; NP,VP,ADJP分别表示名词短语、 动词短语和形容词短语, 这里均视为名词组块、 动词组块和形容词组块; NN,VV,NR,JJ分别表示普通名词、 动词、 专有名词和修饰语. 由图1可见, 在细粒度语句中, 组块识别能识别出具有相同性质或属性相似的词语,并组成一个组块. 本文结合CRF组块识别和多元规则的层次句法分析模型给出如下定义, 其中涉及到的组块标准参考文献[11].
定义1(中文组块) 中文组块是非递归、 非嵌套、 不重叠的相邻词序列.
本文在组块识别中使用CTB8.0(Chinese TreeBank8.0)的标记方式对语句词语进行词性标注, 并对选取的语料进行统计, 根据语料统计得到组块总数为121 412, 去除标点符号使用的组块标记“IP”16 850个. 表1列出了出现次数最多的10个组块标记(不包括IP组块, 该组块包含标点符号、 语句等)类型分布.
根据不同关系, 相邻词语之间组合构成新的具有一定词性的词语, 循环迭代, 最终合成一棵句法树, 其中涉及多次迭代.
定义2一个或多个词语按组合规则合成一个新的词语称为一次层次迭代.
对语句
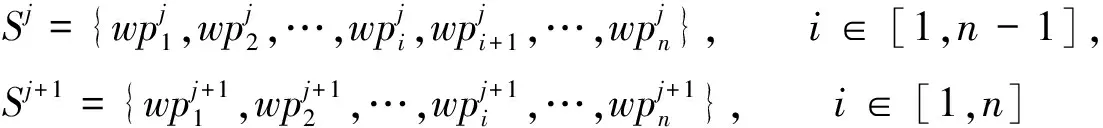
(1)

图2 一次层次迭代示意图Fig.2 Schematic diagram of a hierarchical iterative
进行层次迭代转换,如图2所示. 其中:i表示第i个词语的词性单元(word part of speech unit, WPN);j表示融合层数;n表示WPN的个数.
由于CRF是基于语料统计的模型, 为降低模型对语料的依赖, 提高分析准确性, 本文只进行一次层次迭代. 由表1可见, 组块识别还能兼容一些多元规则, 如“李富荣/NR 和/CC 吴永文/NR”涉及到的三元规则是NP→N(P)+C+N(P), 即“名词词性+连词词性+名词词性”构成一个新的具有名词词性的组块.
关于组块的标记, 本文采用{B,I,E,O}标记集, 其中:B表示一个组块左边界的开始;I表示组块中的词语;E表示组块的结束词语;O表示组块外的其他词语. 本文以语句“上海浦东开发与法制建设同步”为例, 标记列于表2.
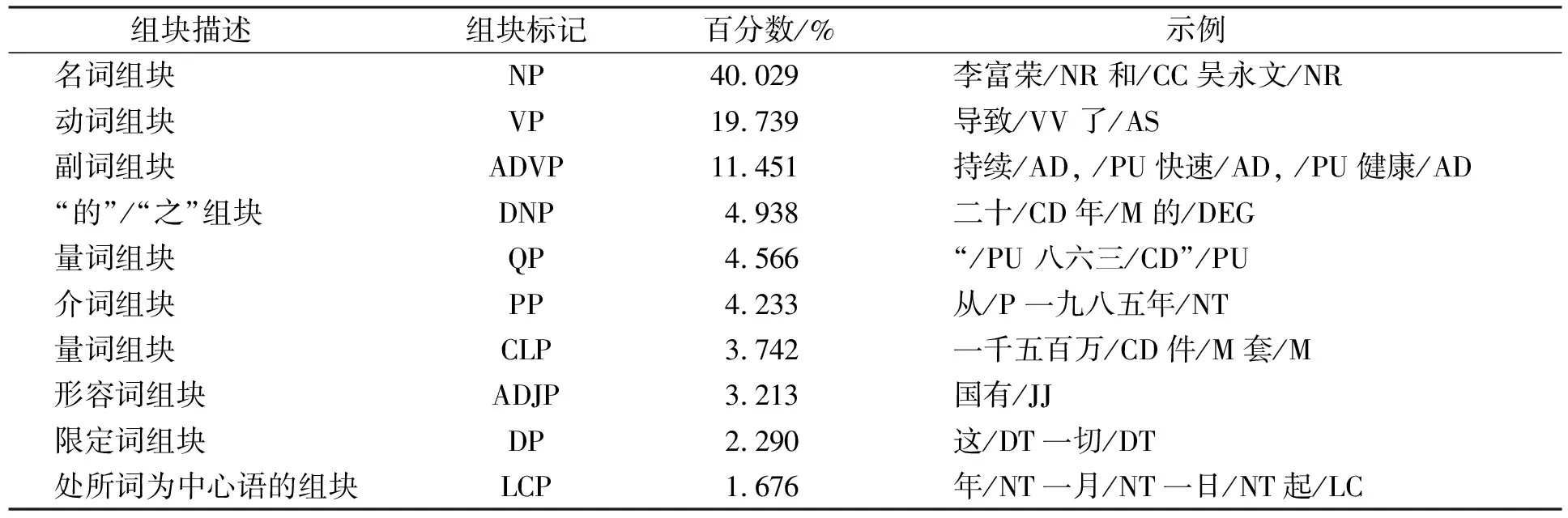
表1 组块类型分布

表2 组块标记实例
1.2 条件随机场模型
低层次组块识别要求识别细粒度的组块, 细粒度的组块如果使用规则分析, 则要求大量的和完备的组合规则. 现有技术中使用深度学习方法缺少可解释性,因此采用CRF解决该问题.
组块的识别就是将语句标注成不交叉、 非嵌套、 非递归的具有一定词性属性的序列块, 其本质是一个序列标注问题. 对于给定的中文观测序列Sentence={wp1,wp2,…,wpn}, 即无向图模型中n个输入节点的值, 对应的组块边界标注结果序列为C={C1,C2,…,Cn}, 其为长度与Sentence长度相同的状态序列, 表示无向图模型中n个输出节点的值. 对于一个带有参数的特征函数Λ={λ1,λ2,…,λn}的线性链, CRF将根据给定的中文输入序列Sentence得到状态序列条件概率, 定义为
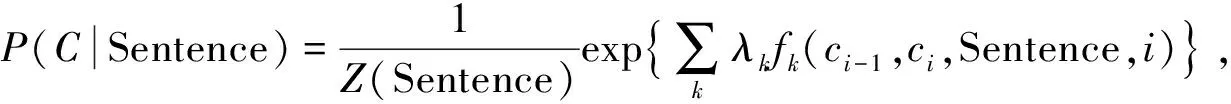
(2)
其中:Z(Sentence)为归一化因子, 定义为
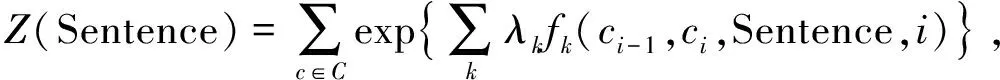
(3)
其作用是使给定中文输入序列上所有可能状态序列的概率之和为1;fk(ci-1,ci,Sentence,i)为整个观测序列和相应标记序列中位置为i和i-1标记的特征函数;λk为在语料训练中得到的并与特征fk相关权重中的值. 在给定训练集训练出CRF模型后, 对任意给定的具有词性标注语句序列Sentence, 经过CRF训练出的模型即输出得到相应的分数C:
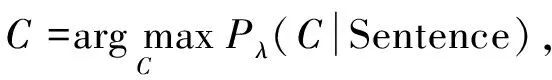
(4)
其中标记后序列中最优标记序列即为使得条件概率取最大值的标注结果. 关于使用CRF进行组块识别的分析可参照文献[3]. CRF与其他学习算法相同, 训练数据特征的选取直接影响后期模型预测结果的准确率.
本文采用条件随机场工具包CRF++0.58进行实验, 对选取的CTB8.0语料进行组块长度统计, 统计结果列于表3. 该统计只取一次层次迭代结果的组块, 当词语序列中组块长度(包含词语个数)低于6个时, 组块数目占实验所有组块的88.317%, 基本上涵盖了所有组块, 为减少无效的模型训练时间, 对本文CRF模型构造的特征函数设置识别窗体词语长度为5, 并只进行一次层次迭代组块识别.

表3 组块长度统计
1.3 多元规则
在高层次粗粒度组块识别中, 对词性的组合要求极大降低, 为解决训练大量不同层次的识别模型, 本文利用多元规则方法解决该问题.

(5)
其中Rsize表示规则集中规则的总数.
在进行句法分析过程中, 传统算法多数使用二元规则, 其中Chomsky范式是二元规则的间接反映. 在汉语处理中, 文献[8]用汉语语法特性进行句法分析, 但有时仍会涉及到满足三元规则的词语序列, 对于四元规则及多于四元的规则, 则很少出现, 因为可以通过二元规则、 三元规则不断将能进行组合的词语序列进行层次迭代. 表4和表5分别列出了部分二元规则和三元规则, 其中词性表示参照文献[12]. 随着汉语的发展, 中文逐渐出现满足三元规则的语句, 例如“在/p桌子/n 上/f”, 其词性序列对应为D→P+N+F, 表示“介词+名词+方位词”词语序列构成具有副词属性的组块, 整体表现为副词词性.
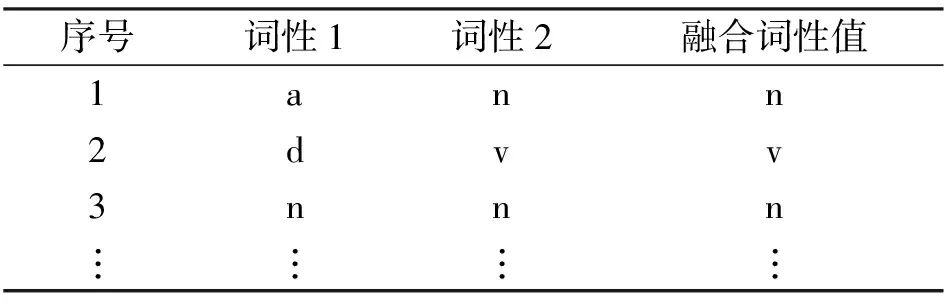
表4 二元规则
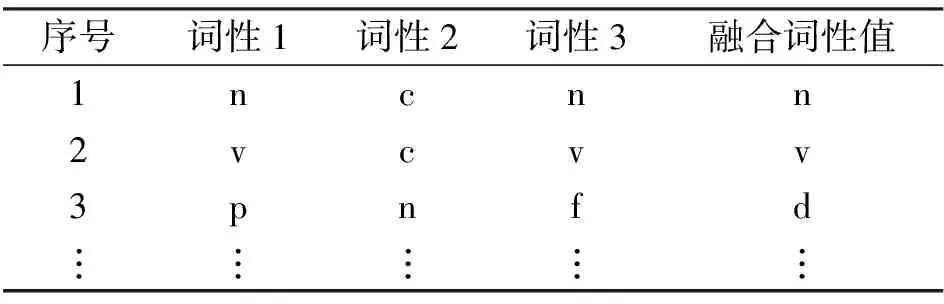
表5 三元规则
1.4 模型实现
图3为句法分析流程示意图, 图4为模型执行框图. 首先在语料库中提取出满足本模型的数据集, 设定CRF特征模板, 通过CRF工具进行语料训练得到CRF组块识别模型; 然后将需要分析的细粒度语句序列用CRF模型进行组块识别, 获取具有{B,I,E,O}标记集标记的汉语语句序列, 并将该序列提取出词语词性数据, 进行基于多元规则的句法分析; 最后通过使用多元句法规则不断迭代分析, 得到分析结果.

图3 模型层次分析流程示意图Fig.3 Schematic diagram of flow chart of model hierarchical analysis
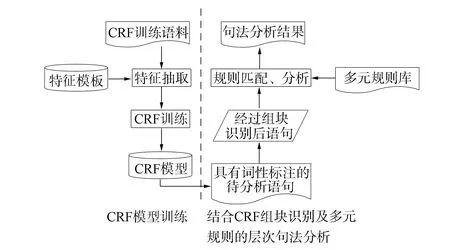
图4 模型系统框图Fig.4 Block diagram of model system
在汉语中, 词语之间的修饰有先后顺序, 即多元规则具有优先级, 并且针对汉语的修饰关系很容易得到“前修饰后”、 “中心词在后”的规律, 因此本文模型在使用不同优先级的多元规则进行句法分析时, 均采用逆向扫描方式查找满足规则的词性序列, 例如, 下列使用不同优先级的二元、 三元规则语句“盛/n 云龙/n 从/p 这/r 件/q 事/n 中/f 受到/v 启发/n”, 将其代入式(1), 可得
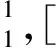
对其进行句法分析可得:

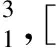

(7)
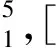

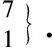
句法分析如图5所示. 根据北京大学标记人民日报语料的统计分析、 相关语法以及相关经验可知, 有不同优先级的多元规则部分结果列于表6. 优先级值越小, 对应规则值优先级越高, 根据不同等级的规则融合成新的WPN序列, 可能出现新产生的WPN序列块满足高等级规则, 从而使得在每次层次迭代中都需要逆向扫描和高等级重新搜索、 匹配多元规则.

表6 部分不同等级的多元规则
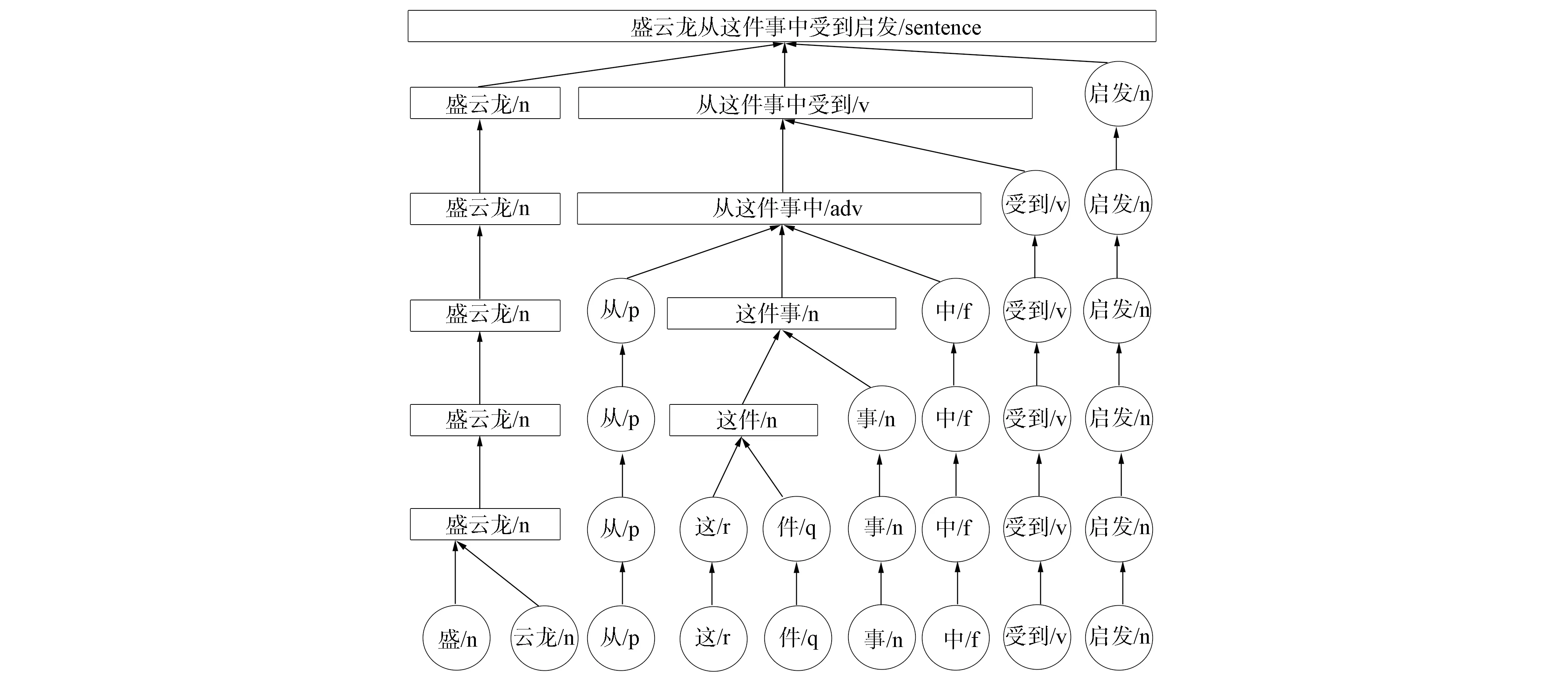
图5 层次分析流程示意图Fig.5 Schematic diagram of flow chart of hierarchical analysis
2 实 验
2.1语料库选择与数据预处理
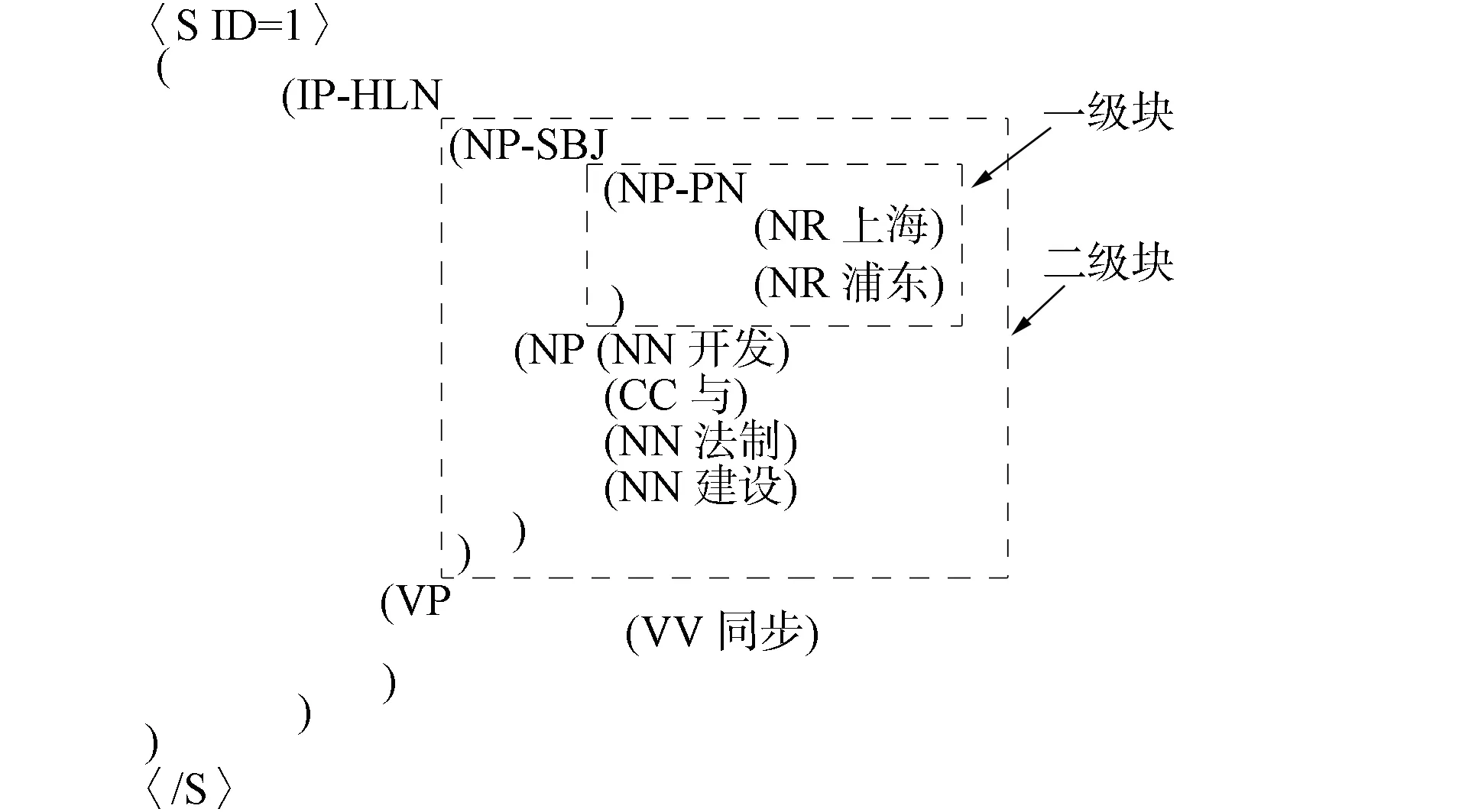
图6 一级组块Fig.6 Primary chunk
在进行实验前需提取出语料中“一级块”的信息, 如图6所示, 将语料转换为只有一级块的标记语料, 并满足CRF训练所需标准格式, 且只选择最初的一次层次迭代组块数据, 如语料“((IP-HLN (NP-SBJ(NP-PN(NR上海)(NR浦东))(NP(NN开发)(CC与)(NN法制)(NN建设)))(VP(VV同步))))”. 该句语料只提取出“上海浦东/NP”、 “开发与发展建设/NP”和“同步/VP”3个组块, 而前两个NP组块可构成一个名词组块, 然后再与动词组块构成IP组块, 由于已经是第二、 三次层次迭代组合, 所以无需提取, 将在后续句法分析中使用多元规则处理. 为方便实验与比较, 本文需剔除一些非组块标记的语料, 由于新闻类型文章的特殊性, 因此应去除一些对实验意义较小的句子, 该类语句组块名称为FRAG. 根据上述要求, 在本文实验中共选取10 000条实验语料.
2.2 实验设计
本文实验选取的语料只有10 000条语句, 数据相对较少, 因此采用K-折交叉验证(K-fold cross validation,K-CV)方法对模型进行验证. 选取5-折交叉验证法, 将10 000条语句语料信息均匀分成5份, 其中选4份作为训练语料, 1份作为模型验证语料, 每组训练语料均会训练出一个模型, 分别记为Modelk,k∈[1,5], 而测试语料记为Testk,k∈[1,5], 并与不使用CRF组块识别的基于二元、 多元规则的句法分析方法, 以及结合CRF组块识别与二元句法分析方法进行比较, 共进行5组实验, 下面以其中一组实验为例进行实验设计.
使用模型Model1和测试语料Test1进行基于二元规则的句法分析(E1)、 基于多元规则的句法分析(E2)、 结合CRF组块识别与二元规则的句法分析(E3)以及结合CRF组块识别与多元规则的句法分析(E4). 根据语料数据数量, 将每个实验分别进行8次, 分8段累加统计分析准确率, 以确定其稳定性, 测试语料数目分别为250,500,750,1 000,1 250,1 500,1 750,2 000. 其中基于二元规则的句法分析方法使用本文总结的二元规则进行句法分析; 基于多元规则的句法分析方法是本文在二元规则基础上增加三元规则的句法分析; 结合CRF组块识别的句法分析方法是本文在组块识别基础上结合二元、 三元规则的句法分析. 在进行句法分析时, 这几种句法分析方法均采取逆向扫描方式, 并用具有不同优先级的规则, 此外, 在组块识别过程中, 未识别成组块的词语, 其词性使用输入数据的词性, 不使用预测后的词性. 通过比较这4种句法分析方式的5组实验, 验证本文提出的结合CRF组块识别和多元句法分析方法的有效性和稳定性.
2.3 测评指标
由于汉语语言的特殊性, 语句可以是单独结构, 所以本文将进行句法分析的语句最后能合成一个根节点作为判定准确的标准, 因此评价指标为准确率:

(8)
2.4 实验结果与分析
下面利用5组实验结果验证本文文句法分析模型的分析效果. 根据句法分析使用的二元、 三元规则及是否基于CRF模型进行组块识别的句法分析, 设计5组实验, 每组有4个大实验, 32个小实验, 其结果列于表7. 实验结果正确率曲线如图7所示. 5组实验中4种对比实验的平均正确率列于表8.
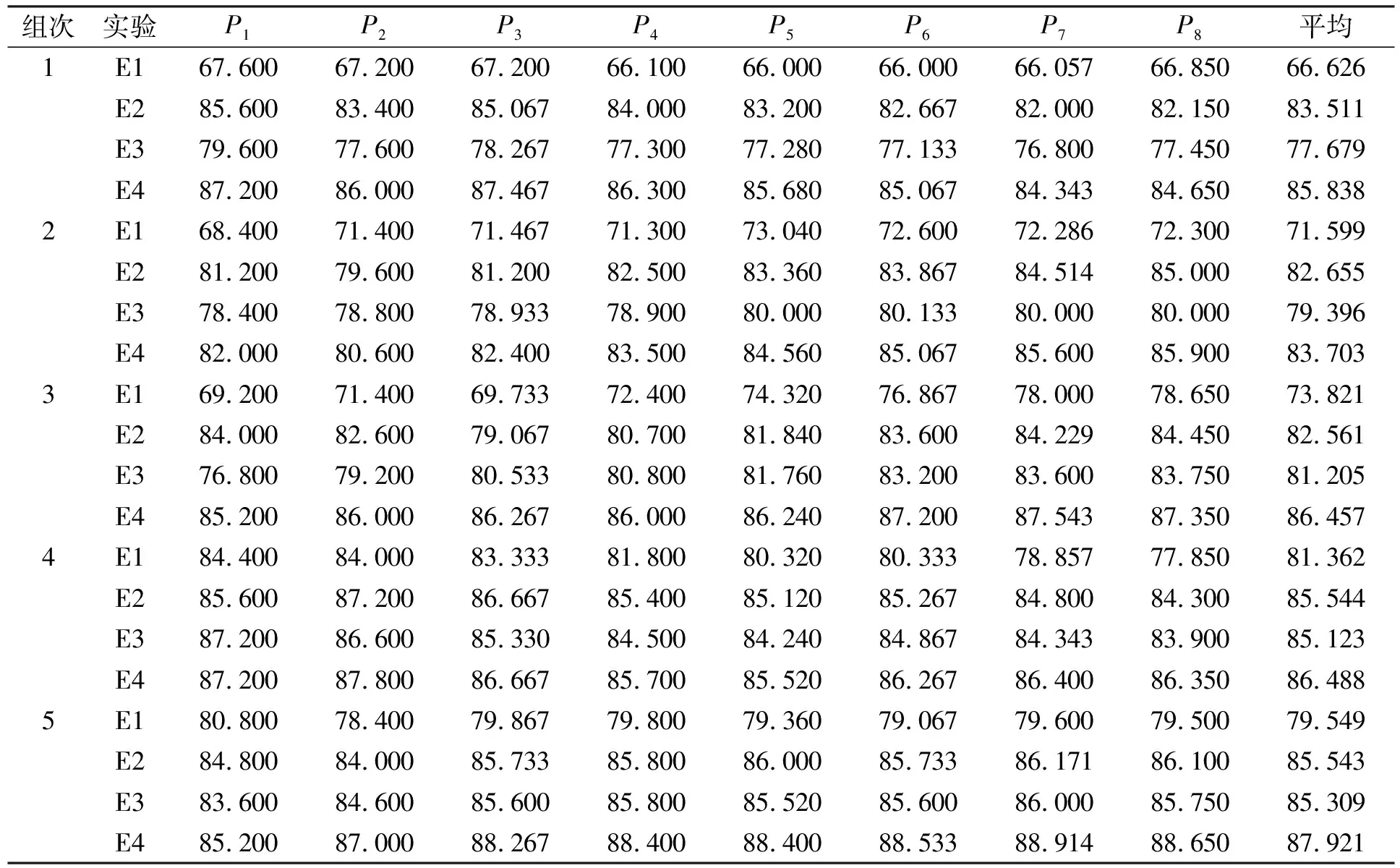
表7 句法分析准确率(%)

表8 句法分析平均正确率
由表8可见, 使用传统基于二元规则的句法分析方法, 在测试集中平均准确率达74.591%; 当使用结合基于组块识别和二元规则进行句法分析后, 模型在测试集中平均准确率约提升10%; 使用改进传统的二元规则并增加三元规则的句法分析方法, 在测试集中的平均准确率达81.742%, 相比于仅使用二元规则的句法分析方法, 在测试集中平均准确率约提升8%; 使用结合CRF组块识别和多元规则的层次句法分析方法进行句法分析, 在测试集中平均准确率最高, 相比于其他句法分析方法, 其正确率分别约提高12%,3%,5%, 且其正确率最平稳, 表明本文模型是有效、 稳定的.
E1和E2的实验结果表明, 汉语语句多元规则占比较大, E2和E4的实验结果准确率相差较小, 表明基于CRF模型进行组块识别的方法, 在本质上识别出的是多元规则需识别出的内容, 同时也验证了低层次中细粒度组块识别的多样性很大程度上高于高层次的粗粒度组块识别, 在低层次的细粒度组块中, 组合方式无论是词语自身还是词性的组合均更复杂多样, 仅利用规则不能满足要求, 利用CRF细粒度组块识别, 高效地解决了该问题; 而高层次的粗粒度组块已进行了细粒度组块的结合, 综合了词性的组合值, 极大减少了词性的丰富性. 本文利用多元规则进行粗粒度的组块分析, 减少了模型的训练负担, 可更准确地分析出完整句子, 同时增强了句法分析的可解释性, 比黑盒更易接受. 基于统计的方法能为人们提取语言中的句法规则, 并能将其运用到句法分析中以达到机器学习的目的.

图7 实验结果对比Fig.7 Comparison of experimental results
实验结果表明, 本文模型在句法分析中分析失败的原因主要是汉语中词块分配的词性存在歧义, 如“国家/n 应/v 加大/v 对/p 国企/n 的/ud 保护扶持力度/n ./w”, 其中“保护扶持力度/n”已被CRF组块识别, 并进行新的词性标注. “对/p 国企/n 的/ud 保护扶持力度/n”根据本文定义的规则, 其分析结果应为一个副词, 而在原语料中, 该部分最后被标记为一个NP, 如果按主谓宾语句结构分析, 则这部分应该是一个名词块, 说明这部分存在本文未找到的规则, 使得“对/p 国企/n 的/ud 保护扶持力度/n”为一个名词块.
2.5 性能对比
为验证本文模型的有效性, 选择与几个最新的句法分析模型进行对比, 实验结果列于表9. 由表9可见: 文献[8]将中文句子全部二分化, 正确率稍低; 文献[6-7]加入了与本文相同的规则成分, 正确率有所提升; 文献[13]采用传统基于最大熵的移进规约方法进行句法树边界的识别, 识别率最高. 本文方法采用CRF与规则方法相结合, 既解决了多模型训练的困难, 又保留了句法分析的可解释特性, 实验结果也表明, 本文方法的结果优于大部分模型, 在数据集上均取得了较理想的结果.

表9 句法分析成果对比
综上所述, 本文结合CRF和多元规则的层次化句法分析模型, 不仅能自动识别出句子中最细粒度的组块, 而且能识别相对高层次的粗粒度组块, 降低了语句中一些标点符号对句法分析的影响, 突破了传统方法需要训练多个模型的问题. 本文模型将CRF组块识别方法应用到细粒度语句的组块识别中, 利用基于统计的方法和多元规则相结合的方法识别出不同词性的组块; 为有效解决句法分析中词语搭配规则多及有效减少搭配优先级变动的影响, 本文模型在识别出的组块中引入不同优先级的二元、 三元规则; CRF组块识别和多元规则的结合实现了同时进行细粒度和粗粒度组块的识别, 能更好服务于句法分析. 在测试集中的平均正确率及正确率趋势均验证了本文模型的有效性和稳定性.
