基于新冗余度的特征选择方法
2020-11-18李占山吕艾娜
李占山,吕艾娜
(吉林大学 计算机科学与技术学院,吉林 长春 130012)
特征选择是机器学习和数据挖掘领域中一个重要的数据预处理过程.特征选择的目的是从原始特征集中选出相关特征子集,这些子集可以有效地描述样本数据,减少冗余或无关特征对预测结果的影响.目前特征选择有过滤式、包裹式、嵌入式三种类型.过滤式方法基于一些衡量指标,如距离[1]或互信息[2]评估特征,结合基于贪心思想的搜索方法,如顺序向前SFS向后SBS[3]进行特征选择,生成特征子集.这会导致算法过早收敛,陷入局部最优.包裹式方法则直接针对给定学习器进行优化.由于包裹式方法在特征选择过程中需要多次训练学习器,因此包裹式特征选择的计算开销要比过滤式方法大得多.在过滤式和包裹式方法中,特征选择过程与学习器训练过程有明显的分别.而嵌入式方法则是在学习器训练过程中自动地进行特征选择.
特征选择本质上是一个多目标优化问题,通过最大化特征与标签的相关度,同时最小化特征间的冗余度,筛选出对学习器贡献大的特征.由于多目标进化算法的启发式搜索可以有效地避免搜索陷入局部最优陷阱,因此现有过滤式特征选择算法通常结合进化计算方法生成特征子集.但是目前过滤式结合多目标进化算法进行特征选择的方法存在两个问题:①衡量特征间冗余度时没有考虑标签信息对特征的影响;②现有方法采用的多目标算法大都是基于非支配排序框架,而大量实验结果表明基于分解的框架,可以获得更低的时间复杂度,找到更好的Pareto前沿面,得到对学习器贡献更大的特征子集.
本文利用多目标进化算法能充分考虑特征空间的优势,结合新的冗余度衡量标准MIFS-CR[4]及基于分解框架的多目标优化算法MOEA/D-DE[5],将特征选择问题转化为一个多目标优化问题.同时为保证子集的稀疏性,引入l1正则化作为稀疏项.实验表明本文的方法能很好地缩减特征子集的维度并提高学习器的学习率.
1 基于信息论的过滤式方法
熵与互信息(mutual information,MI)是信息论中两个重要的概念.熵(H)是随机变量不确定度的度量指标.互信息(I)则用来衡量两个随机变量之间的相关性,互信息和熵具有以下关系,如式(1)和图1所示.
I(X;Y)=H(X)-H(X|Y)=H(Y)-H(Y|X)=
H(X)+H(Y)-H(X,Y).
(1)
近年来,涌现出大量基于信息论的特征选择方法并取得了令人满意的结果.Battit首先提出MIFS[6]方法来解决特征间冗余度问题.MIFS采用的衡量标准:
(2)
其中:fi表示待选特征;fs是已选特征;C是标签.J(fi)越大,特征fi对提高学习器准确率的贡献程度越高.参数β用来调节相关度与冗余度的相对重要程度.
Kwak等[7]提出了MIFS-U方法:
I(fi|fs;C)=I(fi;C)-{I(fs;fi)-I(fs;fi|C)}.
(3)
其中,I(fi|fs;C)表示在fs给定的条件下,标签C与特征fi之间的互信息.I(fi|fs;C)可以根据假设:信息在整个H(fs)区域均匀分布,进行适当估计:
(4)
该方法认为特征间的冗余信息受标签信息的影响,并提出新的熵与互信息的关系,见图2.
H(fs)=H(fs|C)-I(fs;C),
(5)
(6)
经过式(5),式(6)的推导,MIFS-U最终的特征选择标准:
(7)
由于将标签信息考虑进来,因此MIFS-U能比MIFS方法更好地衡量特征之间的关系.
2 MOEA/D-DEFS方法
2.1 新冗余度衡量标准
实际上I(fi;fs)中的信息分布取决于fs和fi,不像MIFS-U中那样仅认为I(fi;fs)区域中的信息分布由H(fs)中的信息分布确定.类似MIFS-U,本文假设信息也是均匀分布在H(fi)区域中的,那么有
(8)
改进后的特征间冗余度标准:
(9)
2.2 目标函数
特征选择的目的是找到一个特征子集S,保证组成该特征子集的特征与标签高度相关.
(10)
同时特征之间的冗余度FRED最小:
(11)
为了让搜索到的特征子集的维度|S|尽可能小,本文引入了一个稀疏项l1正则化,保证特征子集的稀疏性.文中定义了两个目标函数F1,F2.
(12)
其中,FREL用来衡量特征与标签的相关度.由于FREL恒正,本文取FREL的相反数,保证在求解多目标问题(13)时,特征与标签间的相关度更大,能找到更好的解.λ1,λ2是惩罚系数,经过在不同数据集上的实验,当λ1=0.03,λ2=0.01时实验效果最好.
至此特征选择被转化为求解一个多目标优化问题:
(13)
多目标优化问题指的是要同时优化的多个目标之间存在相互冲突,一个解在某个目标上是好的,而在其他目标上却可能是较差的.因此,存在一个折中解的集合,称为Pareto最优解集.
2.3 MOEA/D-DEFS
本文采用基于分解的框架MOEA/D结合差分进化(DE)算子将特征选择问题视为一个二目标问题.通过找到一组相关度大、冗余度小的特征子集,训练分类器并验证特征子集对分类准确率的影响.MOEA/D-DE算法的具体实现及其相应的伪代码,详见2.3.1~2.3.3节.
算法1 MOEA/D-DEFS框架
输入:多目标优化问题(13);N:子问题数量;T:邻居集合大小;λ1,λ2,…,λN:一组随机分布权重向量.
输出:分类准确率.
1)MOEA/D-DEFS;
2)生成Pareto 非支配解(特征子集);
3)返回生成的特征子集及其对应的分类准确率.
2.3.1 MOEA/D方法及其初始化
MOEA/D采用近邻思想:子问题与其对应邻居子问题拥有相似的最优解.将多目标优化问题分解成N个单目标优化子问题并相应地为每个子问题赋予一个权重向量λ.由于权重向量的距离较小, 因此子问题与对应邻居子问题拥有相似的最优解.依照权重距离的大小为每个子问题构建邻居集合B,通过比较当前个体与对应邻居子问题择优替换,更新参考点z.
MOEA/D方法的初始化:
1)通过计算任意两个权重向量之间的欧氏距离,初始化邻居集合B;
2)在目标空间中随机初始化种群{x1,…,xN};
3)通过公式(13)计算子问题的目标函数F(xi),∀i=1,…,N;
根据近邻思想, 针对繁殖算子和替换策略,通过维护邻居集合, 在选择繁殖个体和替换个体时均从相应的邻居集合里选择.
2.3.2 繁殖算子与修复策略
DE算子[8]和多项式突变[9]已被证明对于大多数多目标优化问题是高效的.本文采用DE算子生成子代解,通过多项式突变策略,维护种群的多样性,充分利用的特征空间,来提升算法性能.DE算子生成子代解的过程如下:
(14)
式中:xr1是当前迭代子问题的解;xr2,xr3是其邻域中随机选择的两个解;CR和F是差分进化的两个参数;rand是均匀分布在[0,1]间的随机数.再对中间解ui依照多项式变异策略生成新解xi.
(15)
(16)
由于差分进化算子本身是求解连续空间中的多目标优化问题,因此,需要一个阈值Δ与每个决策变量进行比较,将连续的决策空间修复为0,1组成的离散空间.仅当决策变量大于阈值Δ时才选择相应的特征.为了限制所选特征的数量,本文取Δ=0.6.决策变量的值的可行域为[0,1]的概率值.
2.3.3 替换策略
替换策略在MOEA/D框架中起着非常重要的作用,实际上,它决定了如何保留解、分配何种子问题为解.MOEA/D有4种分解方法[10],将多目标规划(MOP)问题的PF近似值转换为多个单目标优化问题.
1) Tchebycheff(TCH)方法.
(17)
2) Penalty Boundary Intersection(PBI)方法.
(18)
z*是参考点,与TCH方法相同;θ>0是一个惩罚参数,通常θ=5.
3) Normalization Tchebycheff(NTch)方法.
(19)

4) 改进的Tchebycheff(MTch)方法.
(20)
当分母λi=0时,本文将其替换为一个较小值10-6.
本文研究了4种不同的分解方法,来寻找组成Pareto前沿面的Pareto最优解集P*,以确定采用何种分解方式生成的特征子集更利于提高学习器的学习率.
替换更新:
1)fori←1,…,Ndo
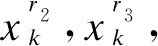
4)替换:B中每个索引j∈B(i)={i1,…,iT},如果满足g(xnew|λj,z)≤g(xj|λj,z)则xj=xnew,同时F(xj)=F(xnew).
5)end for
3 实验结果与分析
3.1 实验数据集
为了验证所提出算法的执行效率,本文在来自真实世界的15个数据集上进行了实验,数据源来自UCI数据库,详见表1.
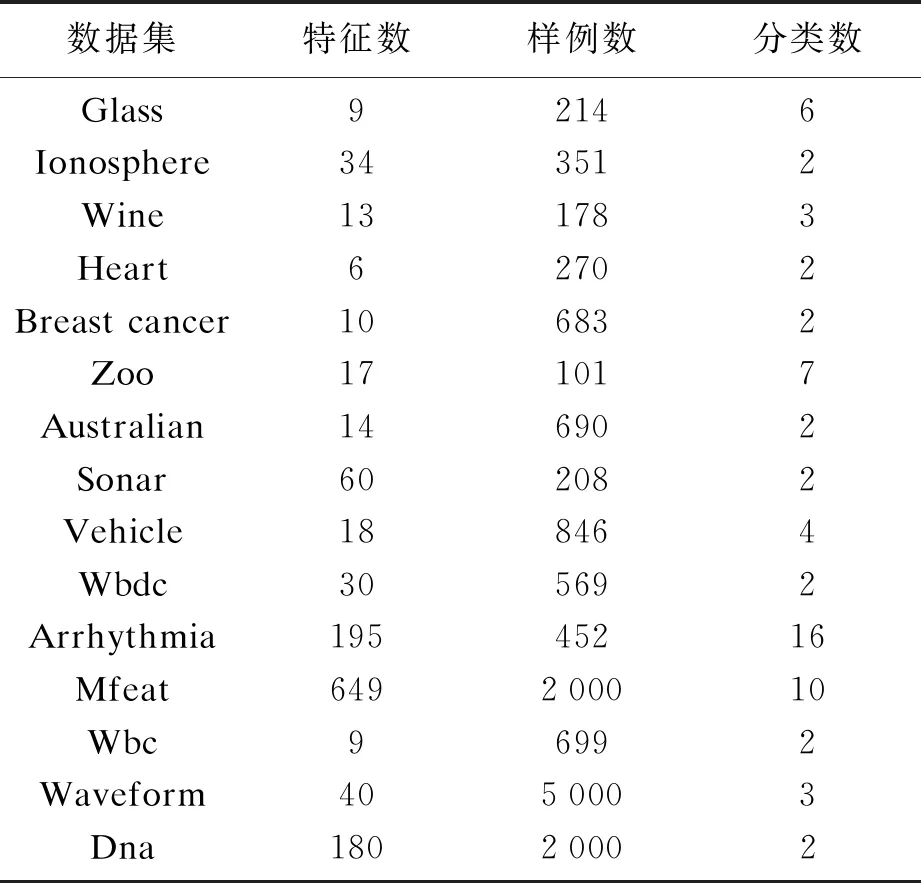
表1 数据集
3.2 实验参数设置
在实验中本文采用knn-5分类器作为学习器,分别独立进行了10次10折交叉验证.DE算子中的参数CR与F分别为1和0.5.多项式变异算子中的参数设为η=20,pm=1/n,n是特征子集特征的维数.对比算法信息详见表2.

表2 对比算法的信息
3.3 实验结果分析
实验通过对分类器分类准确率(Acc)的提升效果和算法所选择的特征数(Atts)来评估本文算法及表2中算法的执行效率.
表3给出了不同分解方式对实验结果的影响.从实验结果来看,两种基于改进的TCH分解方式生成的特征子集的准确率和维度缩减的程度要优于TCH方法和PBI方法,能更好地提高学习器的学习效果.在TCH方法表现不好的数据集上基于PBI的分解方法能获得更好的分类准确率.例如在Zoo和Wine数据集上基于PBI分解的方法分别比基于TCH的分类准确率高出2.73%和1.63%.

表3 不同分解方式对分类准确率和特征的影响
表4中列出本文的方法与表2中对比算法运行的结果.与同SFS,SBS比较,本文提出的方法在大部分数据集上的表现都是最好的,仅有Zoo的分类准确率要略差一些.这是因为SFS与SBS方法实际上属于贪心搜索方法.这类方法存在明显的缺点:在选择特征时它们没有考虑特征间的相关性对学习器的影响,仅以准确率衡量特征的重要程度,特征一旦被加入或剔除特征子集就不能再修改,容易出现生成的子集陷于局部最优陷阱,影响学习器的学习效果.GWOFS方法虽然采用了启发式搜索,但它的搜索是盲目的,同样没有考虑冗余度的影响.因此得到的结果大部分落后于本文方法.另外同其他基于互信息的方法相比较,本文方法的学习效果都优于它们.例如在Heart数据集上本文方法在选择更少特征的情况下比MOEA_MIFS与DEMOFS的准确率分别高出5.53%和3.26%.这表明,本文采用的新冗余度衡量标准,对衡量特征间的冗余度是高效的,同时稀疏项的引入能够保证特征子集的维度尽可能小.同SWFS方法相比,本文的结果表现得更好,因为本文是从信息论的角度去考虑问题,而SWFS仅仅考虑数据点之间的距离,随着特征维度的增加,SWFS方法搜索最具判别力特征的能力逐渐下降.

表4 本文方法与其他算法的比较
4 结 论
1) 本文方法引入的稀疏项l1正则化,能最大程度缩减特征子集的维度.
2) 从实验结果看TCH方法由于简单易实现更适用于作为MOEA/D-DEFS的替换策略来获得特征子集,提高学习器的学习率.
3) 采用启发式策略可以有效地改善贪心搜索陷入局部最优陷阱,获得更好的特征子集.
