双通道多感知卷积神经网络图像超分辨率重建
2020-11-18王翠荣
王 鑫,王翠荣,王 聪,苑 迎
(东北大学 计算机科学与工程学院,辽宁 沈阳 110169)
单幅图像超分辨率重建旨在将模糊的低分辨率(low-resolution,LR)图片重建为更加清晰的高分辨率(hight-resolution,HR)图片.它可以解决视频监控,医学、卫星成像等领域存在的图片模糊、噪声干扰等问题.常用的单幅图像超分辨率重建方法有插值法、基于稀疏表示的方法、局部线性回归法,以及基于深度学习的方法.
近年来,基于深度学习的单幅图像超分辨率重建取得了巨大成功[1-12].其中Dong等[2]最先提出了一个包含3个卷积层的SRCNN模型,完成了单幅图像超分辨重建;Kim等[3]提出的VDSR模型首次将残差学习[4]引入单幅图像超分辨率重建中,并将神经网络深度提升到20层;Lim等[5]提出的EDSR模型是对文献[4]中的残差神经网络去除其规范化(batch normalization,BN)网络层后的改进,使其更加适合超分辨重建任务,其神经网络深度有69层,网络宽度包含256个特征通道;Zhang等[6]通过堆叠残差稠密块构建的RDN模型,是密度神经网络模型[7]的进化,神经网络深度达到了149层.
不断增长的神经网络规模,带来了单幅图像重建效果的提升,但也引发神经网络的构建和训练难度的增加,需要更加合理地设计神经网络以避免训练中出现梯度消失等问题,同时神经网络在计算过程中的时间复杂度和空间复杂度也在成倍增长,对GPU硬件依赖度高.为此,Li等[13]通过多尺度特征提取、层间融合的方法,构建了MSRN模型,只使用29层神经网络获得了接近文献[5]中EDSR方法的单幅图像重建效果,但该方法在缩小神经网络规模的同时,网络性能也有明显的损失.
本文提出的双通道多感知卷积网络(DMCN),构建了一个双通道多感知残差模块(dual-channel multi-perception residual block,DMRB).作为网络的基础模块,该模块能最大化感知图片特征,重建中有较强的高频信息还原能力,同时将各层DMRB模块的输出经过卷积后输入融合层,进行特征融合并提取全局特征信息.最后通过上采样层(Upsample)将图片放大到特定倍数,完成超分辨重建.DMCN通过DIV2K[14]数据集训练,在Set5,Set14,B100和Urban100基准数据集测试中,多数测试结果好于MSRN,EDSR等对比算法.
1 DMCN模型的设计
1.1 神经网络结构
卷积神经网络仿照生物视觉机制在计算机视觉领域有广泛应用.在超分辨率重建中,卷积神经网络利用其学习功能,通过训练建立起低分辨率图片ILR到高分辨率图片IHR的映射关系.
本文提出的神经网络模型结构如图1所示,包括了三个组成部分:浅层特征提取层、深度特征提取层、放大重建层.
1) 浅层特征提取层对输入网络的低分辨率图片ILR进行升维,将RGB格式的图片特征由3维提升到深度特征提取层的64维,并获得图片的初步特征信息,输出特征图X0.
2) 深层特征提取层作为整个神经网络的核心,决定了整个神经网络对信息感知能力的强弱.DMCN重建模型包含了多层堆叠的双通道多感知模块DMRB,以及对各层进行融合的卷积层.DMRB内部结构将在1.2小节详细论述,层间融合结构将在1.3小节详细论述.深层特征提取层的末端是由跳跃连接(skip connection)构建的残差结构,并最终输出特征图Xd.
3) 放大重建层将图片通过上采样模块放大到特定倍数,再通过重建层重建图片.上采样模块可以通过反卷积法、最近邻上采样法和亚像素卷积上采样法[15]等方法实现,本文使用了亚像素卷积法.
如果将浅层特征提取功能定义为HSFE(·),深层特征提取功能定义为HDFE(·),放大和重建功能定义为HUP_REC(·),则模型将低分辨图片ILR重建为超分辨率图片ISR的过程可表示为
ISR=HUP_REC(HDFE(HSFE(ILR))).
(1)
进一步将整个网络功能表示为HDMCN(·),它所完成的工作表示为
ISR=HDMCN(ILR).
(2)
1.2 双通道多感知残差模块
神经网络结构中,深层特征提取层的核心是堆叠的双通道多感知残差模块(DMRB),这构成了一个典型的深度网络结构.浅层特征提取层的输出值X0经过该深度结构时,图片特征在各层间被充分提取,并在最后一层输出特征值Xn.这一深度提取过程可表示为
(3)
DMRB的内部结构如图2所示,左右两侧的特征提取通道分别采用了3×3和5×5的卷积核.不同卷积核可使卷积操作获得不同尺度上的图片特征信息,如果将此信息融合并做进一步特征提取,能有效增强深度结构的感知能力,这种做法在GoogLeNet网络[16]中得到成功应用,文献[8]中的MSRN网络也使用了类似结构.本文的结构与他们不同之处在于,DMRB中除了融合了两种卷积操作输出的特征信息外,还融合了局部稠密连接信息.具体方法如下.
1) 左右通道的第一层分别对输入数据进行卷积操作,并通过线性整流函数ReLU进行修正.该过程表示为
(4)
(5)
其中:W1代表卷积层的权重;bi代表偏置项bias;ρ代表激活函数ReLU.左侧通道使用3×3过滤器,右侧通道使用5×5过滤器,右侧通道对输入图片的感受范围大于左侧,这保证了左右通道的输出具有不同的特征感受力.
2) 经过第一层处理后,通道连接节点Concat1对左右通道的输出值及原始输入值进行连接,即
(6)
(7)
(8)
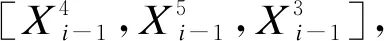
(9)
第三层的1×1卷积的另外一个功能是把接收的特征值维度降低到模块原始输入值Xi-1的特征维度,以便和跳跃连接求和,完成残差结构的计算.最后模块输出Xi的表达式为
(10)
1.3 全局特征融合
基于深度卷积网络的超分辨重建中,网络深度越大,在输出端能够感受到的输入图片范围也越大,即感受也越大,特征提取也更加充分.但这也引发了新的问题,特征信息从输入端向网络深处传递的过程中,很多有效信息会在卷积运算中逐渐消失.为了解决这个问题,文献[6]中RDN模型中提出了密集特征融合方法,将深度结构的各层输出特征值通过跳跃连接输入到融合层进行信息融合,来增强重建效果.但该方法的不足是融合操作将所有输入信息等同对待,每一层在特征融合中作用都是相同的.
本文提出的全局特征融合方法,将除最后一层输出Xn外,X0到Xn-1都经过一个1×1卷积层进行权重平衡,1×1卷积层的输出和最后一层的输出Xn求和后再输入一个卷积融合层(Fusion)进行特征融合.这样除最后一层输出在融合中有固定作用外,其他层会由1×1卷积层动态调节在融合中的权重,从而能够提取出更加准确的图片特征值.为了提高重建效果,融合层之后连接残差操作.该过程可以表示为
(11)
其中:W代表卷积层的权重;b代表偏置项bias.
1.4 损失函数
(12)
其中,θ是神经网络中所有参数的集合.目前,基于深度学习的超分辨率重建中常用的损失函数有L1损失、L2损失和对抗损失等,本文选择L1损失作为网络损失函数,L1损失函数能获得更高的测试指标,同时也和实验中主要对比网络MSRN和EDSR采用的损失函数保持一致.最终的损失函数定义为
(13)
2 DMCN模型的实现
2.1 算法实现
本文给出了一种基于双通道多感知卷积神经网络模型的图片超分辨率重建方法.重建过程是:首先对输入的低分辨率图片进行上采样,提取初步图片特征信息,然后通过堆叠的双通道多感知模块以及层间融合结构对图片进行深层特征提取,最后对图片进行放大重建,实现图片的超分辨率重建.具体过程参见算法1.
算法 1 图片超分辨率重建
输入:低分辨率图片ILR.
输出:重建的超分辨率图片ISR.
1) 对输入的低分辨率图片ILR通过卷积操作进行上采样,将其特征通道数提高到64,输出特征图X0;
2) 将浅层特征提取的输出X0输入堆叠的双通道多感知模块DMRB,每一层的输出Xi作为下一层输入,直到最后一层DMRB,得到输出Xn;
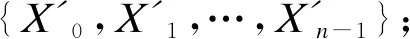
5) 将特征融合的结果和X0求和,完成残差操作,得到特征图Xd;
6) 将特征图Xd放大scale倍(scale=2,3,4)后进行降维,生成输出图片ISR.
2.2 神经网络结构参数
将图片特征提取通过两条卷积通道完成,除了便于设置不同的卷积核获得图片在不同范围下的特征信息外,还能够有效降低卷积网络的计算复杂度.相同卷积核下,将一个卷积操作按特征通道等分成两个卷积操作后,卷积的参数变为原来的一半,计算量同样随之减半.本文提出的深度卷积网络模型中3个组成部分的卷积结构参数如表1所示.为了获得良好的重建效果,同时将网络规模控制在最小规模,深度特征提取部分采用了8层DMRB模块堆叠.
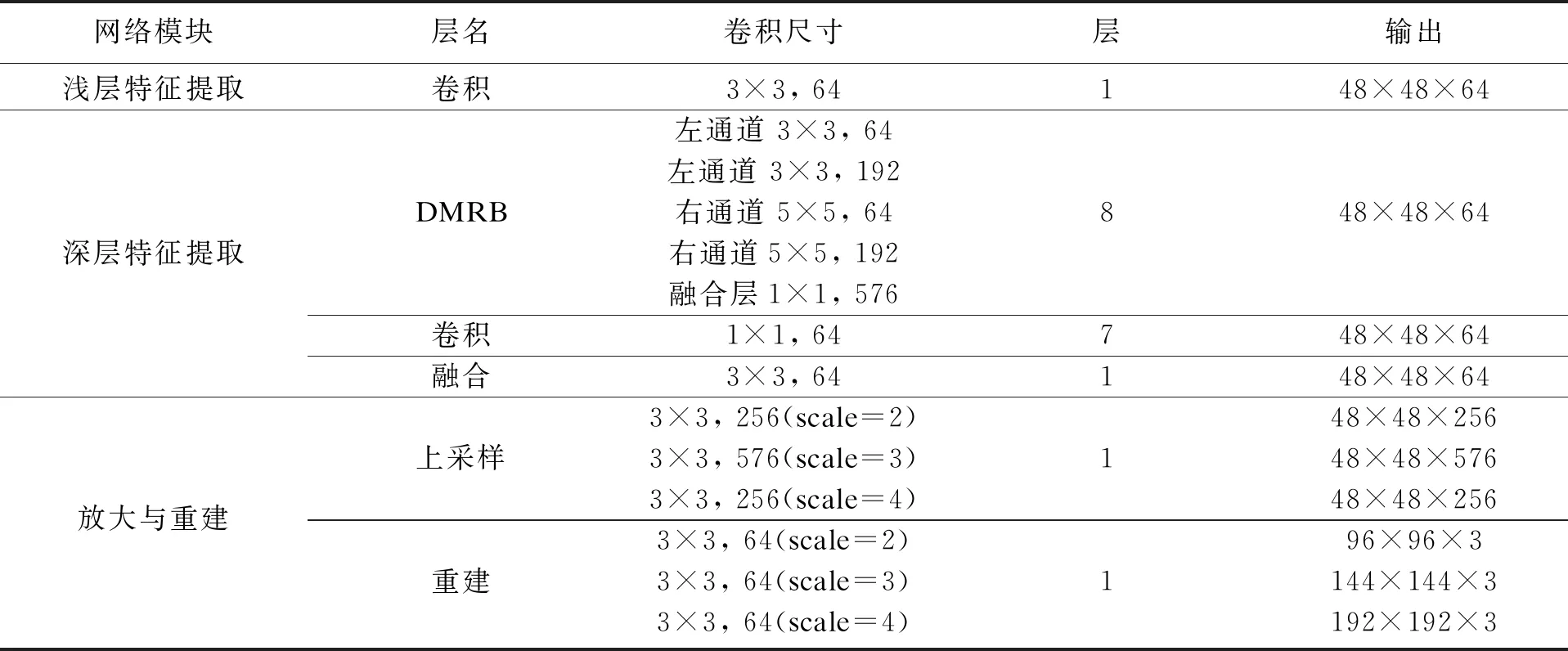
表1 卷积神经网络结构参数
3 实验及结果分析
实验用DIV2K数据集中的800张图片对卷积网络进行了训练,输入图片为RGB图像并裁剪为48×48大小,对输入图像按EDSR网络中的方法进行旋转、翻转等变换,以增强训练效果.每次训练样本数(batch size)为16,共迭代1 000次.训练中对2倍、3倍、4倍重建分别进行训练.训练结果基于Set5,Set14,B100和Urban100基准数据集进行测试,评价指标为峰值信噪比(peak signal to noise ratio, PSNR)和结构相似性(structural similarity inex, SSIM).DMCN网络基于PyTorch 1.1框架搭建,实验中使用了一张TitanRTX GPU.训练使用Adam优化器,参数为β1=0.9,β2=0.999,ε=10-8.学习率初始为10-4,每经过50次迭代衰减为原来的90%.表2给出了本文方法与几个经典超分辨方法的比较,其中对MSRN原文采用Y色彩通道,本文统一采用了RGB通道进行实验,图片切割尺寸为48×48.
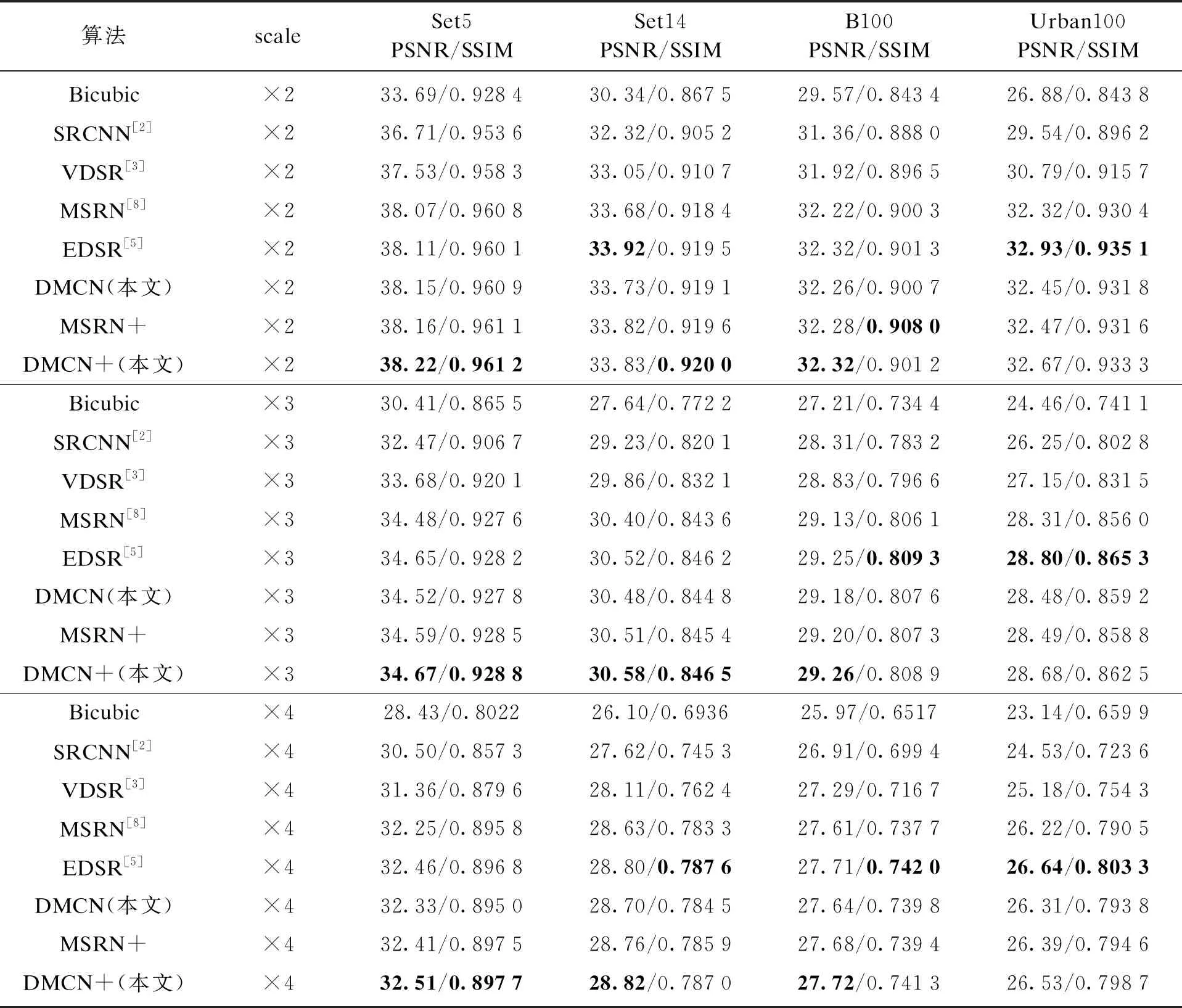
表2 基准数据集测试结果
表中加粗字体为测试中最好结果,DMCN+与DMCN不同之处在于,DMCN+在测试阶段使用了文献[5]中的几何自集合(geometric self-ensemble)方法,将同一输入图片进行旋转、翻转后再进行测试,然后对输出结果取平均值.实验结果可以看出在多数测试中DMCN+都取得了最好的测试成绩,只在Ubran100测试集中全面落后于EDSR网络.DMCN和EDSR网络模型之间的比较如表3所示.

表3 EDSR与DMCN的比较
不难看出DMCN的网络规模明显更小,处理时间也明显更短,但DMCN+的重建结果比EDSR更好或者接近.DMCN网络在Ubran100数据集合测试中落后于EDSR的原因在于Ubran100这种高分辨率图片集的重建对网络的感受也更加敏感,更大的感受也能带来更佳的重建效果,而通常网络深度和感受也成正比.EDSR有69层的深度,同时残差结构中通道数为256,而DMCN只有29层,残差通道数也只有64.
图3给出了在难度较高的4倍重建中DMCN模型与几个主流重建模型重建效果的比较.从主观视觉感受上,可以明显看出DMCN的重建结果图包含更加丰富、准确的高频细节信息,与原始图片更加接近.这一结果主要得益于DMCN的神经网络结构能更全面地感知图片中的各类信息,从而在重建中表现更佳.
4 结 论
1) 本文提出了一种能高效进行图片超分辨率重建的双通道多感知卷积神经网络模型,模型对具有不同卷积核的双卷积通道进行局部稠密连接,获得了对图片特征信息的多种感知能力;用带有卷积调节功能的层间融合结构还原出更加准确的图片信息.
2) 实验在深度学习框架Pytorch 1.1下完成了神经网络的训练和测试.结果表明双通道多感知卷积神经网络在较小的网络规模下完成了优良的图片重建,在多数测试结果中图片峰值信噪比和结构相似性指标优于对比组重建算法,视觉效果包含更多细节图片信息.
