大数据平台下基于类型的小文件合并方法
2020-10-23秦加伟刘辉方木云
秦加伟 刘辉 方木云
摘 要:Hadoop存储海量小文件将导致存储和计算性能显著下降。本文通过分析HDFS架构提出了一种基于文件类型的小文件合并方法,即根据文件类型将相同类型的小文件合并为大文件,并建立小文件到合并文件的索引关系,索引关系存储于HashMap中。为了进一步提高文件读取速度,建立了基于HashMap的缓存机制。实验表明该方法能显著提高HDFS在存储和读取海量小文件时的整体性能。
关键词:HDSF;HashMap;索引;合并;缓存
中图分类号:TP3-0 文獻标识码:A
Type-based Small File Merging Method on Big Data Platform
QIN Jiawei, LIU Hui, FANG Muyun
(School of Computer Science and Technology, Anhui University of Technology, Ma'anshan 243002, China)
738437340@qq.com; liuhui@ahut.edu.cn; fangmy@ahut.edu.cn
Abstract: Storage of large numbers of small files by Hadoop will lead to inefficiency in storage and computing performance. This paper proposes a small file merging method based on file type by analyzing the framework of HDFS (Hadoop Distributed File System), that is to say, small files of the same type are merged into large ones, and an index relationship of small files to the merged files is established. The index relationship is stored in HashMap. In order to further improve the file reading speed, a cache mechanism based on HashMap is established. Experiments show that this method significantly improves the overall performance of HDFS when storing and reading massive small files.
Keywords: HDSF; HashMap; index; merge; cache
1 引言(Introduction)
随着互联网和5G技术的快速发展,数据处理需求日渐提高,基于此,大数据[1]和云计算[2]技术应运而生。以Hadoop[3]为主的大数据处理平台因其优秀的稳定性和高扩展性而成为主流。Hadoop由HDFS(Hadoop Distributed File System)[4]、MR(MapReduce)[5]、YARN等构成,其中HDFS负责存储数据,MR负责处理数据。HDFS设计的目的是为了存储并访问超大文件。研究发现,FaceBook、Twitter、微信、QQ等社交软件每天产生的社交数据总量都在PB级,而这些数据大多是一些KB级别的小文件,包含日志、照片、短消息等[6]。所谓小文件,目前没有准确的定义,一般意义上是指小于HDFS储存块(Hadoop1.x默认64M,Hadoop2.X默认128M)大小的文件,当HDFS存储海量小文件时,其性能会显著降低。
2 HDFS存储小文件的不足(The lack of HDFS to store small files)
HDFS是一个分布式多节点存储集群架构,有一个NameNode节点和多个DataNode节点构成。NameNode节点用于管理HDFS的元数据信息。DataNode节点用于存储实际的文件,DataNode以存储块的形式存储数据,当文件大于存储块时文件会分多个块存储于多个DataNode节点中。HDFS中无论文件多大,其在NameNode中存储的元数据大致为150字节,固定大小的NameNode内存决定了只能存储固定数量的元数据。当存储的文件中小文件占大多数时将极大的消耗NameNode内存,影响元数据的检索速度,进而显著降低HDFS存取性能。
3 相关研究工作(Related research work)
基于小文件问题,HDFS自身提供了四种解决方案,分别是Hadoop Archive方案[7]、CombineFileInputFormat方案[8]、
SequenceFile[9]方案和MapFile[10]方案。这些方案应用场景较为广泛但也存在一些问题,如Hadoop Archive(简称Har方法)合并后没有删除原文件且需运行MapReduce合并文件、CombineFi-leInputFormat没有真正合并小文件、SequenceFile没有建立索引,读取小文件只能遍历,效率低、MapFile虽然添加了索引但没有缓存机制且随机读取文件效率低。
一些学者针对小文件的问题也展开了相关研究。游小荣、曹晟基于教育资源小文件间的关联关系提出了存储优化方案,即把同一课程的关联小文件归类合并成大文件并建立预取机制加快读取速度[11]。赵晓永等提出一种基于Hadoop的海量MP3文件存储架构,利用MP3文件自身包含的丰富描述信息,通过归类算法将相关性较强的文件合并为大文件,同时通过引入索引机制,加快了读取文件的速度[12]。淘宝针对自己平台产生的特定小文件,基于HDFS开发了TFS:Taobao File System[13],以实现对小文件的高效存储。
以上方案在一定程度能解决小文件所带来的问题,但仍然存在一些问题。例如,一些方案只能针对特定的应用场景,不具有普适性。另一些方案则能应用在所有的应用场景,但其做法通常是不考虑文件类型将所有文件全部合并,这将不利于合并后对小文件进行分类管理和处理。基于此本文提出基于文件类型的小文件合并方法,即将大量小文件按照文件类型合并到各自类型的大文件中。
4 解决方案(Solution)
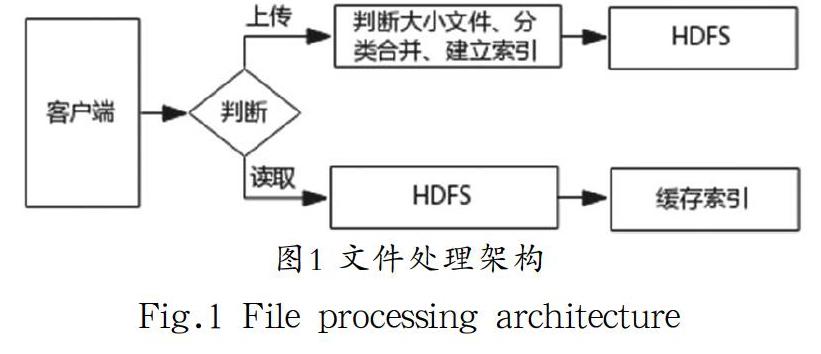
本方案主要有四个模块,即大小文件判断模块、分类合并模块、建立索引模块和索引缓存模块。为了减小NameNode内存压力,本方案在文件上传时需判断大小文件,大小文件判定阈值目前没有准确的定义,大多数学者认为小于存储块的文件即可认为是小文件。以存储块大小作为判断阈值显然没有试验做支撑,文献[14]通过一系列测试得出阈值为4.35M,故本文沿用文献[14]的结论以4.35M作为阈值。上传的小文件一般包括多种类型,常见的有日志文件、文本文件以及图片,具体的场景会有差异。文件合并模块中需要为每一种类型的文件建立一个大的合并文件,上传时根据文件的类型合并到该类型的合并文件中,并为每一种类型的合并文件建立索引。索引中存储的是每个小文件在合并文件中的起始字节偏移量和文件字节长度,索引关系存储在HashMap中,上传完成后写入到相应的索引文件。为了进一步提高读取效率,本方案创建了基于HashMap的索引缓存模块,该缓存模块可以显著提高查询重复文件时的效率,小文件合并处理架构如图1所示。
4.1 合并文件
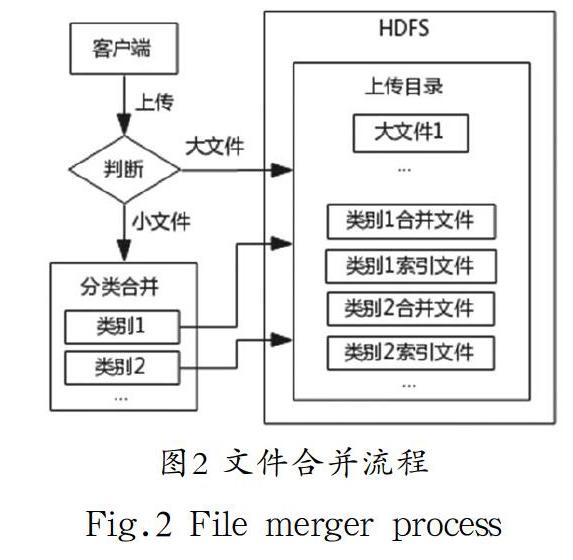
客户端向HDFS上传文件时,首先在HDFS的上传目录中打开对应文件类型的合并文件输出流和创建用于保存合并文件索引关系的HashMap对象(在索引机制中详细说明)。上传文件时根据大小文件判断阈值将文件分为大、小文件,大文件直接存储于HDFS上传目录,小文件则根据其文件类型合并到该类型的合并文件中。合并完成后关闭合并文件输出流并将保存有索引关系的HashMap对象写入到上传目录,此时上传目录中只存在大文件和分类合并文件及其索引文件,文件合并流程如图2所示。
4.2 索引机制
在介绍索引机制前先介绍HashMap,HashMap是Java语言中的一种数据结构。它的特点是以key-value对存储,且通过key不需或经过少量比较即可查询到value,查询value的速度几乎不受HashMap长度的影响,在查询大量数据时具有明显的优势。HashMap对象可以通过对象流写入文件和还原回内存中的对象。可以根据这种特点应用于存储索引关系,由于其完全由Java语言内置,可以极大地提高查询效率。
HashMap支持泛型,其key和value的数据类型可自行指定。本文中key为文件名,故其类型指定为String,value需记录小文件在合并文件中的起始字节偏移量和字节长度,故其为可记录字节偏移量和长度的Info类类型。
为检索合并文件中的小文件,在合并文件的过程需要建立每个小文件到合并文件的索引关系。即当每一个小文件写入到该类型的合并文件后,以该文件名为key,该小文件在合并文件中的字节偏移量和长度封装为Info对象作为value添加到该类型的HashMap对象中,合并完成后将HashMap对象通过对象输出流写入到对应类型的索引文件中,合并文件和索引文件的存储结构如图3所示。
4.3 缓存机制
在读取文件时,最耗时的是通过文件名查找文件的索引信息,它需向NameNode发送读取索引文件的请求,而后从相应的DataNode中将索引文件还原为HashMap对象,并通过HashMap对象获取索引信息。每次读取文件都要经过这一过程,这在查询重复文件时效率较低。基于此本方案通过将历史访问的索引信息保存在内存中的HashMap中,并记录每个索引被缓存命中的次数,缓存容量的阈值N可以根据硬件配置自行指定,当缓存容量超过阈值时将命中次数最少的索引信息移除。利用HashMap缓存在读取重复文件时效率显著提高且无论缓存容量多大,查询任意索引的效率同样高。
4.4 文件读取
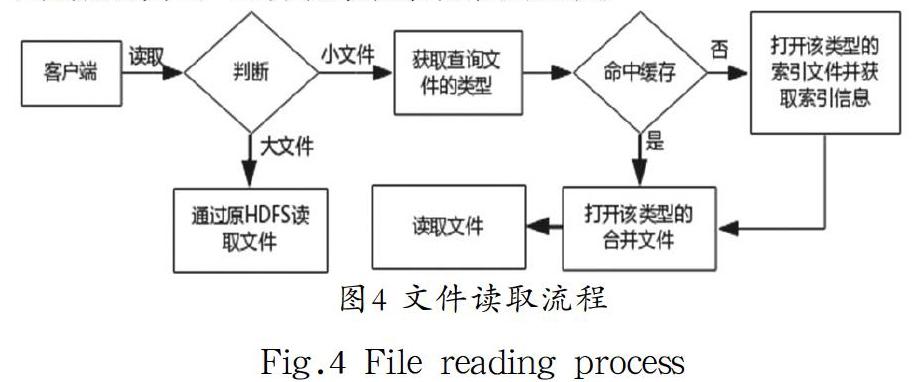
读取文件时先根据阈值判断大小文件,大文件直接通过原HDFS查找并读取,小文件则先通过文件名在缓存中查找,如命中缓存则根据文件类型打开读取目录下该类型的合并文件并根据缓存中的索引信息读取数据,缓存命中次数加1。如沒有命中缓存则根据文件类型打开读取目录下该类型的索引文件并将该文件还原为HashMap对象,根据文件名查找索引信息,获取索引信息后即打开该类型的合并文件并读取数据。由于缓存机制的存在,需将本次读取的索引信息添加到内存中的缓存HashMap中,因首次读取该文件,故将缓存命中次数置为0,文件读取流程如图4所示。
5 实验验证(Experimental verification)
本实验Hadoop版本为2.7.2,Hadoop运行模式为伪分布式模式,操作系统为CentOS-6.8,数据块副本数为3。计算机处理器Intel(R) Core(TM) i7-3540M @ 3.0GHz、内存大小为8G、机械硬盘60G。本实验测试数据集为10000个文件,共包含为三类,第一类为文本文件,平均大小为100kB,占比57.18%。第二类为图片文件,平均大小18kB,占比41.76%。第三类为视频文件,平均大小6.8MB,占比1.06%。
将10000个文件随机打乱,分成4组测试数据,每组数据量分别为2500、5000、7500和10000个。下面分别从写入速度、NameNode内存占用和读取速度三个方面进行比较。
5.1 写入速度测试
为验证本文方法在上传速度上效率的提升,将四组文件分别通过本文方法、原HDFS方法及Har方法上传至HDFS,分别记录每组上传所用的时间。每组每个方法实验进行五次,并去除最大和最小值,取余下数据的平均值,实验结果如图5所示。
由实验结果可知,本文方法所用时间远小于原HDFS及Har方法。其原因在于原HDFS客户端每次上传小文件时都要向NameNode发送写文件请求,发送请求的时间远远大于写入文件的时间,故其上传速度最慢。Har方法上传之前需要运行MapReduce进行合并,故其上传速度介于原HDFS和本文方法之间。本文方法在上传之前不需要运行MapReduce且直接将合并文件写入到HDFS中,所以其速度最优。
5.2 NameNode内存占用测试
为测试本文方法在NameNode内存占用方面和原HDFS的差异,分别通过本文方法和原HDFS方法将4组文件上传至HDFS。每组文件上传完成之后记录NameNode编辑日志edit_inprogress所占空间增长情况,实验结果如图6所示。
由实验结果可以看出,本文方法在NameNode内存占用方面拥有较好的性能。主要原因在于本文方法通过将小文件分类合并为大文件,在上传至HDFS之后有效地减少了元数据的数量,进而显著降低了NameNode内存占用量。
5.3 读取速度测试
为了验证本文方法在读取文件速度方面和原HDFS及Har方法的差异,记录每组读取单位大小的文件所用的时间,每组实验进行五次并去除最大和最小值,取余下数据的平均值。同时为了验证缓存机制对读取文件时的影响,设置缓存容量阈值N为1000,实验结果如图7所示。
实验结果表明,本文方法显著优于原HDFS和Har方法,在重复读取时由于命中缓存,读取时间进一步缩短,且读取时间不随文件数量的增大而提高,在文件数量越多时优势越明显。原因在于随着HDFS存储的小文件增多,HDFS检索元数据的性能下降,而本文方法由于使用HashMap保存索引信息,在通过文件名查找索引信息时直接获取,时间复杂度为O(1)。在读取重复文件时,由于首次读取已将索引信息添加到内存中的HashMap对象中,再次读取时直接从内存中的HashMap中查询索引信息,读取效率进一步提高。
6 结论(Conclusion)
本文通过分析Hadoop存储模块HDFS的架构并引出其存储海量小文件的不足,进而提出一种基于分类合并思想的改进方案。即将小文件按照文件类型(扩展名)分类合并为大文件,并为每一类型的合并文件添加索引,将索引保存在HashMap中,最终写入到索引文件。同时为了进一步提高读取文件的速度,本方案设置了基于HashMap的缓存机制,即在内存中缓存已读文件的索引信息。实验表明,本方案在写入速度、NameNode内存占用,以及读取速度上均显著优于原HDFS。
参考文献(References)
[1] 冯贵兰,李正楠,周文刚.大数据分析技术在网络领域中的研究综述[J].计算机科学,2019,46(06):1-20.
[2] 王佳隽,吕智慧,吴杰,等.云计算技术发展分析及其应用探讨[J].计算机工程与设计,2010,31(20):4404-4409.
[3] 夏靖波,韦泽鲲,付凯,等.云计算中Hadoop技术研究与应用综述[J].计算机科学,2016,43(11):6-11;48.
[4] 郭建华,杨洪斌,陈圣波.基于HDFS的海量视频数据重分布算法[J].计算机科学,2016,43(S1):480-484.
[5] 李建江,崔健,王聃,等.MapReduce并行编程模型研究综述[J].电子学报,2011,39(11):2635-2642.
[6] 郑通,郭卫斌,范贵生.HDFS中海量小文件合并与预取优化方法的研究[J].计算机科学,2017,44(S2):516-519.
[7] 李三淼,李龙澍.Hadoop中处理小文件的四种方法的性能分析[J].计算机工程与应用,2016,52(09):44-49.
[8]刘斌.Hadoop小文件编程处理的性能优化[J].工业控制计算机,2018,31(12):47-48.
[9] 谭台哲,向云鹏.Hadoop平台下海量图像处理实现[J].计算机工程与设计,2017,38(04):976-980.
[10] 段隆振,洪新利,邱桃榮.基于MapFile的HDFS小文件存取优化[J].南昌大学学报(工科版),2017,39(02):175-178.
[11] 游小容,曹晟.海量教育资源中小文件的存储研究[J].计算机科学,2015,42(10):76-80.
[12] 赵晓永,杨扬,孙莉莉,等.基于Hadoop的海量MP3文件存储架构[J].计算机应用,2012,32(06):1724-1726.
[13] 赵洋.淘宝TFS深度剖析[J].数字化用户,2013,19(03):58-59.
[14] Bo Dong, Qinghua Zheng, Feng Tian, et al. An optimized approach for storing and accessing small files on cloud storage[J]. Journal of Network and Computer Applications, 2012, 35(6): 1847-1862.
作者简介:
秦加伟(1995-),男,硕士生.研究领域:大数据,大数据分析.
刘 辉(1979-),男,硕士,副教授.研究领域:软件工程,信息系统.
方木云(1968-),男,博士,教授.研究领域:软件工程,信息系统.