基于活动发生关系的流程相似性度量方法
2020-10-12李东月
李东月,方 欢
(安徽理工大学数学与大数据学院,安徽淮南 232001)
1 引言
随着业务流程管理(business process management,BPM)在企业中的影响力越来越大,流程模型在企业管理中得到了广泛的应用.业务流程是对企业业务执行的一种描述,对企业的运营具有重要的指导意义.因此,业务流程模型已经成为每个组织宝贵的智力资产,企业不可缺少的一部分.值得注意的是,累积的流程模型已经达到了一个惊人的数字[1],管理动辄数以万计的流程模型已经成为人们面临的一个挑战.流程模型的相似性度量已经被证实是管理这些宝贵资产高效的解决方案[2].然而,在处理现有业务流程的多样性时,应根据用户需求,选择一种适当的方法来分析业务流程的相似性.相似性度量有3种观点:1)元素匹配相似度,比较附加到流程模型上的节点和边的对应关系;2)比较元素标签与流程模型拓扑结构的结构相似性;3)比较过程模型中元素标签及其因果关系的行为相似性[3].其中,流程模型的行为(执行语义)最能体现一个模型的本质.
基于标签(元素匹配)的相似性方面往往以模式匹配和本体论为基础,例如基于标签对齐的相似性度量算法[4]和基于标签语义的相似性度量方法[1].
现今对流程模型的相似性分析主要从行为相似性和结构相似性两个方面来展开.首先,在模型的行为相似性方面,基于行为的流程相似性度量方法主要包含以下两种:
1) 基于流程模型中活动间的时序关系,如执行顺序等:文献[5]提出了一种基于两个流程变迁紧邻关系(transition adjacency relation,TAR)集的相似性定义,对流程的相似性进行度量,该方法没有考虑活动紧邻关系的重要性,因此对顺序结构和循环结构的区分不敏感;文献[6]提出行为轮廓的概念,对比基于迹等价一致性与行为轮廓一致性的计算结果,突出行为轮廓相似性算法的优越性.文献[7]在文献[5]的基础上,将紧邻关系的重要性加以区分,提出一种基于变迁紧邻关系重要性的相似性算法TAR++.文献[8]提出一种基于任务之间的时间关系查询流程模型的方法,通过将截断事件连接到延续事件来扩展完全有限前缀,提取任务之间的所有时间关系,进而查询流程模型;文献[9]拓展变迁的紧邻关系,利用完全有限前缀,提出基于任务最短距离矩阵的流程模型行为相似性算法,但该算法需要计算两个流程模型的同维化矩阵,不能直接用于模型索引.文献[10]提供了一个基于迹语义和抽象的行为包含概念,根据网系统能否重放查询行为进行模型匹配,衡量模型的相似性,该方法只匹配了活动间的行为关系,没有考虑模型结构;文献[11]提出了一种基于业务流程内部结构的相似性度量方法,给出映射函数,通过计算单个节点(变迁和库所)的相似性,将所有变迁或库所的相似性加权求和,进而求得流程的相似性.文献[12]提出了基于Petri网的映射变迁关系相似性度量方法,给出5种变迁关系定义,利用变迁的行为关系,度量相同变迁节点在不同流程中结构上的相似性,计算流程相似性;文献[13]通过将模型的行为关系用变迁标签图来表征,结合图理论,提出一种基于可覆盖图编辑距离的行为相似性度量算法(transition-labeled graph edit distance,TAGER);文献[14]提出了一种基于包含领域知识的语义任务重要性紧邻关系(semantic task adjacency relations with importance,ISTARs)的语义工作流行为相似度度量方法.文献[15]利用Petri网的完全前缀展开理论和任务的发生关系,提出一种基于任务发生关系的流程模型相似性度量(task occurrence relation,TOR);文献[16]将行为轮廓中的交叉关系细化为6种类型,提出了细化的基于行为轮廓矩阵的相似性度量方法.
2) 基于流程模型的变迁发生序列集合[11].文献[17]提出了一种基于主变迁序列的相似度度量方法(principal transition sequences,PTS),利用过程模型的语义,将主变迁序列分成三类,分别定义每类主变迁序列的相似性计算方法,进而计算流程的相似性;该方法将完整的发生序列分开考虑,破坏了语义的完整性;文献[18]对文献[17]的方法进行研究,针对PTS方法存在的问题,利用完整的发生序列表征模型的行为,提出一种基于触发序列的流程相似分析方法PTS++;文献[19]提出了一种基于约束迹的过程相似度量化方法,以约束的最长公共子序列为基础,利用约束迹对齐计算流程的相似性.
其次,在流程模型的结构相似性研究方面,目前大多研究方法基于图的理论进行结构相似度计算[20–21],而在模型结构转为图的过程中会丢失一些语义信息,导致无法有效区分图中活动之间存在的是选择关系还是并发关系,因此仅仅将结构转为有向图不能准确表现原有流程,必须结合一些流程行为信息,以更全面地表达原流程.为了弥补上述不足,文献[22]提出了一种基于Petri网选择性约简模型的业务流程结构相似性分析方法,以识别不同业务流程之间的相似活动,分析流程的结构相似性;文献[23]综合考虑模型结构与日志行为,提出一种基于模型结构与日志行为的流程相似度计算方法,根据模型中行为在日志中的发生概率为业务流程图加权,并根据加权业务流程图编辑距离的定义计算流程的相似性.文献[24]提出了一种基于累积分布函数的相似度计算方法.该方法通过隐马尔可夫模型(hidden Markov model,HMM)建模和状态序列引用从拓扑结构中挖掘底层拓扑语义,并根据累积分布函数计算两种拓扑结构之间的相似度.文献[25]以现有流程行为相似度度量方法的不足为出发点,提出了一种基于扩展转移关系集(etri集)的业务流程行为相似度综合度量方法.通过构造一个并发可达图获得etri集,定义一种新的流程行为相似度度量方法,进行流程相似性度量.
综上所述,现有的流程模型行为相似性算法大都基于变迁发生序列或存在计算效率较低的问题,因此,本文提出一种基于活动发生关系的流程相似性度量方法,利用活动节点的左右集及发生关系度量流程的相似性.本文的主要贡献主要有以下几点:
1) 基于标签Petri网进行业务流程建模,并提出了活动发生关系的概念和活动节点的左右集概念;
2) 在最佳活动映射的前提下,将活动在左右集上的结构特征与活动间发生关系变化与否相结合,提出了两个不同流程之间的活动相似性,反映了相同活动节点在不同结构上的相似性,并提出流程相似性度的概念来计算整个流程的相似性.
3) 提出了一种基于活动发生关系的流程相似性算法,通过实验对该算法进行了分析验证,给出了一种流程行为相似性度量的新方法.
2 相关知识
本文以Petri网建模语言为工具,采用图形的方式将不同的业务流程展现出来,对其相似性加以分析和度量.
定义1标签Petri网[13].
满足下列条件的五元组LN=(P,T;F,Φ,L)称为一个标签Petri网:
1) P为库所的有限集合;
2) T为变迁的有限集合;
3) F ⊆(P ×T)∪(T ×P)为流关系,即有向边的集合;
4) L:T →Φ ∪{ε}是标签映射函数,其中,Φ为活动标签的集合;
若满足前3个条件,则称为一个Petri网,记为N=(P,T;F).
P和T统称为网LN的节点,即P ∪T ∈X,若∃y∈X,使得(y,x)∈F,则称y为x的前集节点,所有前集节点的集合称为x的前集,即·x={y ∈X|(y,x)∈F};若∃y ∈X,使得(x,y)∈F,则称y为x的后集节点,所有后集节点的集合称为x的后集,即x·={y ∈X|(x,y)∈F}.与节点相邻的边称为节点的边,包含输入边和输出边.图1给出了一个最简单的标签Petri网的示例.
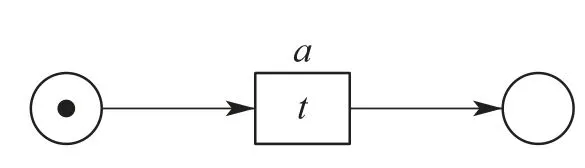
图1 最简单的标签Petri网Fig.1 The simplest label Petri net
当选择Petri网作为建模工具的时候,通常会考虑Petri网的子类–工作流网(work flow net,WF–net).由于其只有一个源库所(起始库所)和一个结束库所,流程开始于源库所(起始库所),完成于结束库所,并且所有节点都属于从源库所(起始库所)到结束库所的路径上.其简洁明了的结构特性便于人们进行业务流程的分析.此时,变迁表示实际业务流程中的行为活动,库所表示相关活动的执行条件或状态.
定义2工作流网[7].
满足下列条件的标签Petri网称为一个工作流网(WF–net):
1) 只存在一个输入库所i ∈P,使得·i=∅;
2) 只存在一个输出库所o ∈P,使得o·=∅;
3) LN=(P,T;F,Φ,L)为强连通的,即N的所有节点x ∈P ∪T,都属于i到o的一条有向路径上.
六元组WFN=(P,T;F,Φ,L,M0)称为一个工作流网系统,其中M0为网系统的初始标识.
定义3迹.
令六元组WFN=(P,T;F,Φ,L,M0)为一个工作流网,变迁的发生序列称为工作流网的迹,记作σ=(t1,t2,···,tn),其中ti∈T(i=1,2,···,n).
在工作流网的基础上,任意2个变迁在整个工作流网的结构上存在着不同的关系,为了便于表述,在进行活动发生关系相似性度量之前,首先对活动之间的关系进行如下定义(见定义4).
定义4活动发生关系.
令六元组WFN=(P,T;F,Φ,L,M0)为一个工作流网,Tr为WFN所有可能的执行序列集合,并且活动a,b ∈T.
1) 强序关系(strict order):若存在一条迹σ=(···,ti,tj,···)∈Tr,其中j=i+1,使得ti=a,tj=b,则活动a和活动b称满足强序关系,记作a →b.显然,强序关系不具有对称性和传递性;
2) 并发关系(concurrency):至少∃σ1,σ2∈Tr,σ1=(···,ti,tj,···),σ2=(···,tj,ti,···),使得ti=a,tj=b,则活动a和活动b称满足并发关系,记作a+b.显然,并发关系具有对称性,不具有传递性;
3) 互斥关系(mutex):不存在σ=(···,ti,···,tj,···),使得ti=a,tj=b,即活动a与活动b不会出现在同一条迹中,则活动a和活动b称满足互斥关系,记作a×b,显然,互斥关系具有对称性.
强序关系、并发关系和互斥关系统称为活动的发生关系,记作R.
图2对活动的强序关系、并发关系和互斥关系作了一个直观的阐释.
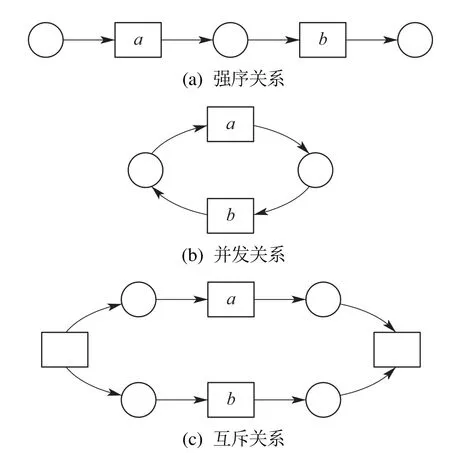
图2 活动的发生关系Fig.2 Occurrence relationship between activities
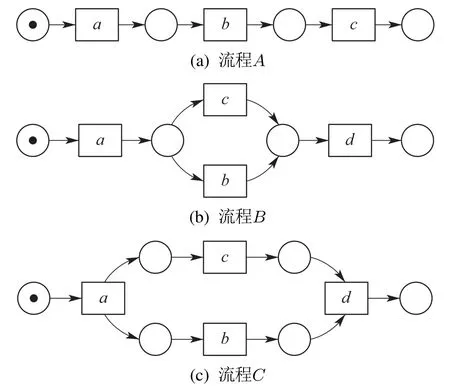
活动发生关系的变化在流程相似性分析中至关重要,例如:活动a和活动b在流程A中为强序关系,在流程B中为互斥关系,在流程C中为并发关系,假设流程A对应的模型为原模型,那么活动a和活动b的行为关系由强序变到互斥,说明这种行为变化将本来直接跟随的两个活动直接变成了不会同时出现在一条迹中,严重破坏了流程A与流程B的相似性;如果活动a和活动b的发生关系由强序变到并发,由于并发关系保留了活动a和活动b的强序关系,所以此种行为关系变化对流程A与流程C相似性的破坏相对较小.下面将这种破坏性程度定义为违背度,并给出形式化定义:
定义5违背度.
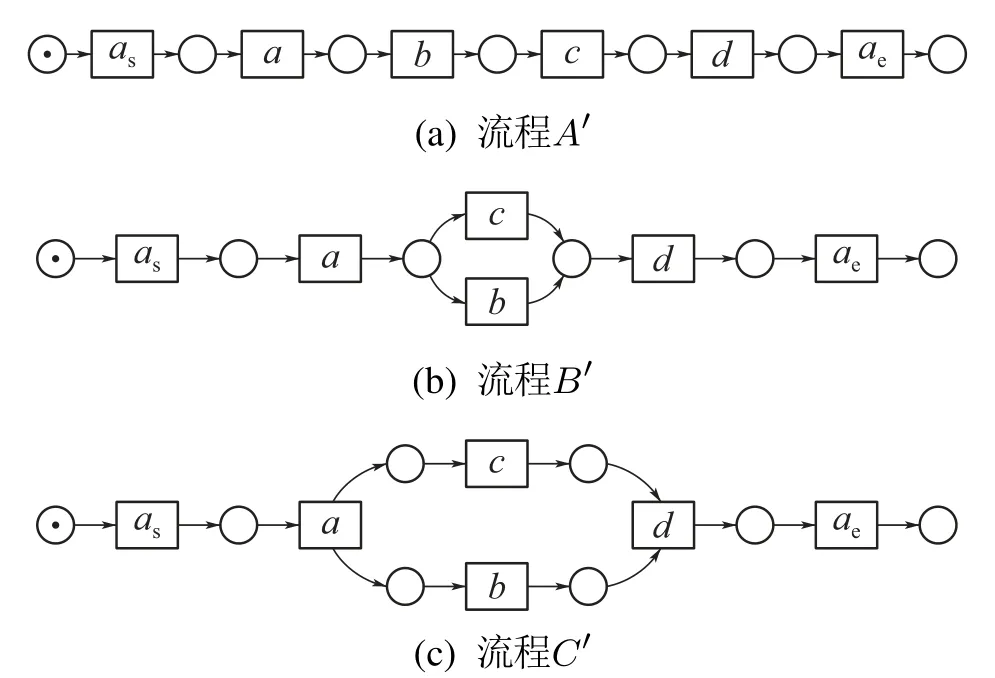
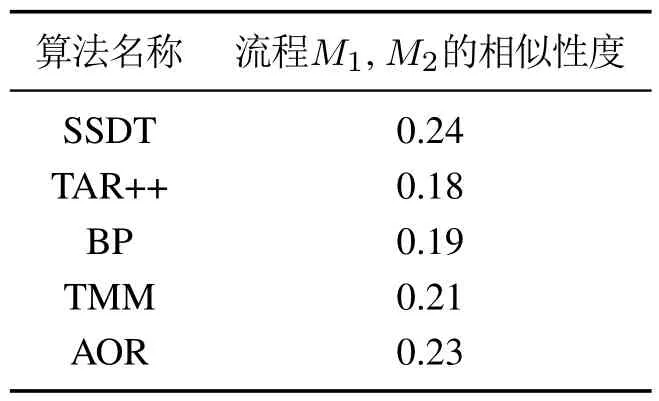
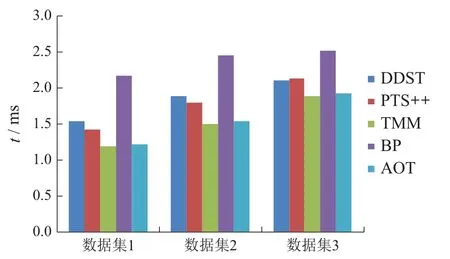
两流程中相同活动对发生关系的偏差程度称为违背度,记作V(R,R′).令流程A中活动a和活动b的发生关系为→,流程B中活动a和活动b的发生关系为×,流程C中活动a和活动b的发生关系为+,则V(→,+) 定义6左集和右集. 令六元组WFN=(P,T;F,Φ,L,M0)为一个工作流网,Tr为WFN所有可能的执行序列,并且a,b,c ∈T,若∃σ=(···,ti,tj,tk,···)∈Tr,其中:i=j −1,k=j+1,使得ti=b,tj=a,tk=c,则称b为a的左集活动,c为a的右集活动,a的所有左集活动组成的集合称为a 的左集,记作La,a的所有右集活动组成的集合称为a的右集,记作Ra. 本文所讨论的Petri网,均是基于安全的工作流网.所谓安全的,是指流程在运行时,网的任意库所中最多只有一个token. 在大多数相似性计算方法中,建立表示两个模型元素之间对应关系的映射函数是首要工作,而本文是在良好变迁映射的前提下,通过计算不同流程中同一活动节点(相同活动节点)在结构上的相似度,进而求得整个流程的相似度. 本文从活动节点的角度考察流程的相似性,认为一个活动节点的左集和右集共同作用,影响流程的相似性,故将活动节点相似性分为两部分:左集相似性、右集相似性,具体定义如下所示. 定义7活动相似性. 经过反复多次实验计算,本文中取α,β ∈{0.4,0.5,0.6},形式化取值法则将在下文第3.1节“基于活动发生关系的流程相似性算法(activity occurrence relation,AOR)”中进行阐述. 在这里α,β不仅起到权重的作用,同时通过巧妙地选择左右集权重的取值,权衡了不同流程中活动的相似性程度,也体现了违背度的具体含义与文章前半部分的中心思想.同时α,β的具体取值要根据实际情况进行分析(结合活动发生关系的变化情况(违背度)与单个活动的结构相似性特征). 图3对权重α和β选择(0.4,0.5,0.6)何值作出具体解释. 图3 流程A,B,C的Petri网模型Fig.3 Petri net models of process A,B and C 为了符合定义6,为图3中的流程分别人工添加一个开始库所ps和变迁as,一个结束库所pe和变迁ae,4条边(ps,as),(as,p0),(p4,ae),(ae,pe),如图4所示. 图4 人工改造后的A′,B′,C′Petri网模型Fig.4 Manual modified Petri net models of process A′,B′and C′ 此时考察流程A与C中活动b和c的相似性:同理可得 发现有SA,B(b)=SA,C(b),SA,B(c)=SA,C(c),这是因为活动b在流程A与B中左右集,与在流程A与C中的左右集相等,活动c同理,同时也说明了引入α,β的必要性.这时,因为b,c在流程A中的发生关系为b →c,在流程B中的发生关系为b×c,在流程C的发生关系为b+c,又由于V(→,+) 综上所述,当活动发生关系不变或由强序变为并发时,取α=β=0.5;发生关系由强序变为互斥时,根据活动左右结构相似性的大小进行取值(α,β ∈{0.4,0.6}). 需要说明的是,上述讨论的是两个强序关系的活动变为互斥或并发的情况,对于由弱序变为互斥或并发时,此方法同样适用. 定义8流程相似性. 令WFN1=(P1,T1;F1,Φ1,L1,M0)为流程1的工作流网,WFN2=(P2,T2;F2,Φ2,L2,M′0)为流程2的工作流网,则流程1与流程2的相似性为 其中分母减去2是为了消除人工初始、结束变迁的影响. 根据式(2),图3中流程A与B的相似性为 流程A与C的相似性为 算法1基于活动发生关系的流程相似性算法. 输入:流程模型M1和M2; 输出:M1和M2的相似性度. 步骤如下: 首先分析算法的时间复杂度.给定一个工作流网W,变迁集为T,库所集为P,流关系集为F,AOR算法遍历W中除输出库所外的所有节点及流关系,操作所需时间为O(|T|+|P|+|F|).条件判断、计算权重、并入操作、赋予颜色、出队、入队等操作所需时间均为O(1),总时间为O(1).因此AOR算法的时间复杂度为O(|T|+|P|+|F|),而目前主流算法中,计算效率较高的基于变迁紧邻关系重要性的流程相似性(TAR++)算法的最坏时间复杂度为O(V +E+N!),是一个阶乘级的复杂度,即使运用所给的两种加速方式,其时间复杂度也不可能低于O(|T|+|P|+|F|). 本节通过两个具体的业务流程来验证所提出相似性算法的可行性,即利用基于活动发生关系的流程相似性算法(AOR),度量两个业务流程的相似程度(省略人工改造后的Petri网模型),流程模型如图5所示. 图5 流程1和2的Petri网模型Fig.5 Petri net models of process 1 and 2 下面以流程1和流程2的Petri网模型作为输入,执行基于活动发生关系的流程相似性算法(AOR). 执行算法Step1,输出相同活动的左右集: 实验机器环境为:Intel Core I5–7200U CPU@可加速至3.1 Hz,内存为8 GB,Window10 64位操作系统. 本节实验主要分两阶段进行,第1阶段为算法的可行性分析,第2阶段为算法的性能分析.实验涉及的数据集由两部分组成:450个典型的业务流程模型来自SAP模型库,50个人工流程模型,为满足实验需要由人工编撰.首先将500个业务流程模型运用本文提出的相似性算法(AOR),计算出两两模型之间的相似性度,利用实验结果分析以及相似性结果均属于0∼1,初步验证算法的可行性,并对同样的模型运用主流的相似性算法,与AOR算法结果作对比,进一步验证算法结果的正确性.然后,对不同规模的数据集应用本文算法和主流的相似性算法,通过算法运行时间对比,验证本算法良好的性能体现. 对500个业务流程模型应用本算法,限于篇幅,本节仅给出10个流程模型(其中6个来自SAP模型库,4个来自人工模型,具体请参见链接https://pan.baidu.com/s/1PmQDvFrEXg-JTzT2UoD-Gw)的实验结果,如表1所示.可以看出,本算法得出的实验结果均在0 ∼1范围内,当流程完全相同时,实验结果为1,当流程完全不同时,实验结果为0.由此,初步验证了本算法的可行性. 表1 AOR算法得到的10个流程模型的相似性度Table 1 Similarity of 10 process models derived from AOR algorithm 为进一步验证算法的正确性,从500个流程模型中任意抽出300个模型运用主流的相似性算法与AOR相似性算法,将得到的实验结果与本算法做对比.对比算法包括基于行为的度量方法:1)行为轮廓相似性算法(behavioral profile,BP)[6,8],细化了活动发生关系,给出行为轮廓概念,进而度量模型相似性,但该算法对并发结构不敏感;2)任务最短跟随距离矩阵的相似性算法(shortest sucession distances between tasks,SSDT)[9],用两两活动间的最短跟随距离表征模型行为,问题在于该算法需要计算两个流程模型的同维化矩阵,降低了算法的运算效率.基于变迁紧邻关系重要性的流程相似性算法(TAR++)[7],在考虑模型行为的基础上对边加权,有效的改进了现有的算法.基于模型内部结构的流程相似性度量方法(total-mappingmodel,TMM)[11],该方法采取迭代映射来映射库所和变迁,进而识别两个模型的对应关系.但其忽略活动文本标签的语义,使得到的模型不够准确. 本节仅给出人工模型M1和M2(图6)及其实验对比结果(表2),根据本文提出的AOR相似性算法,模型M1和M2的行为相似性度为0.23,由表2可以看出,AOR算法的运算结果与主流算法比较接近,进一步验证了算法的正确性. 图6 Petri网模型M1和M2Fig.6 Petri net models M1andM2 表2 与主流算法的实验结果比较Table 2 Comparisons with experimental results of mainstream algorithms 为评估AOR算法在实际应用中的性能体现,将抽取的300个实验模型分成不同的数据集(数据集1、数据集2、数据集3),分别包含70,90和140个流程模型,表3列出了各数据集的基本特征:所含平均变迁数、最大变迁数、平均库所数、最大库所数、平均边数、最大边数.目的是利用算法在不同复杂程度模型上的花费,验证算法的性能表现. 为更加直观地比较AOR算法与其他主流算法,根据表3信息,将算法在不同复杂程度数据集上的运行时间制成柱形图,横坐标为不同的数据集,纵坐标为运行时间,如图7所示.由图7可以看出,对于任意一种复杂程度的数据集,AOR算法所花费的时间都稍低与其他算法,运算效率最高,而行为轮廓相似性算法(BP)的运行时间明显高于其他算法,运算效率最低. 表3 不同规模下的算法性能体现Table 3 Performance of algorithms at different scales 图7 不同算法的运行时间对比Fig.7 Comparisons of runtime for different algorithms 另外,本文方法(AOR)与文献[11](TMM)不同之处在于不需要定义不同流程中的活动节点映射,本文是在最佳的变迁节点映射条件下,进行流程的相似性度量.并且文献[13]是从左右集的交叉元素与节点左右分支的结构考虑节点的相似性,进而度量整个流程的相似性.而本文是结合活动节点左右集的重复元素与活动发生关系在整个流程中是否发生变化,来度量流程的相似性. 为了一定程度上解决大量流程模型的管理问题,提高模型检索、重用以及流程合并的效率,本文提出了一种基于模型时序关系(执行顺序)的流程行为相似性算法,该算法在标签Petri网和良好的变迁映射基础上,模型结构与行为相结合,将活动在左右集上的结构相似性与活动间发生关系在不同流程的变化情况综合考虑,进一步识别活动的相似性,然后,通过将活动的相似性进行归一化处理,给出流程相似性定义,最后,提出基于活动发生关系的流程相似性算法(AOR)度量不同流程的相似性.实验结果表明,该算法能够正确的计算不同流程的相似性,与其他相似算法相比,具有更高的时空复杂度. 该相似性算法尚存在一些不足,算法适用于当相同活动节点的左右集与“原模型”左右集不同时,未考虑左右集相等的情况.另外,如何将AOR方法应用于工业场景,未来将对这些工作做进一步研究,以使算法具有更强的适应能力.3 基于活动发生关系的流程相似性分析方法
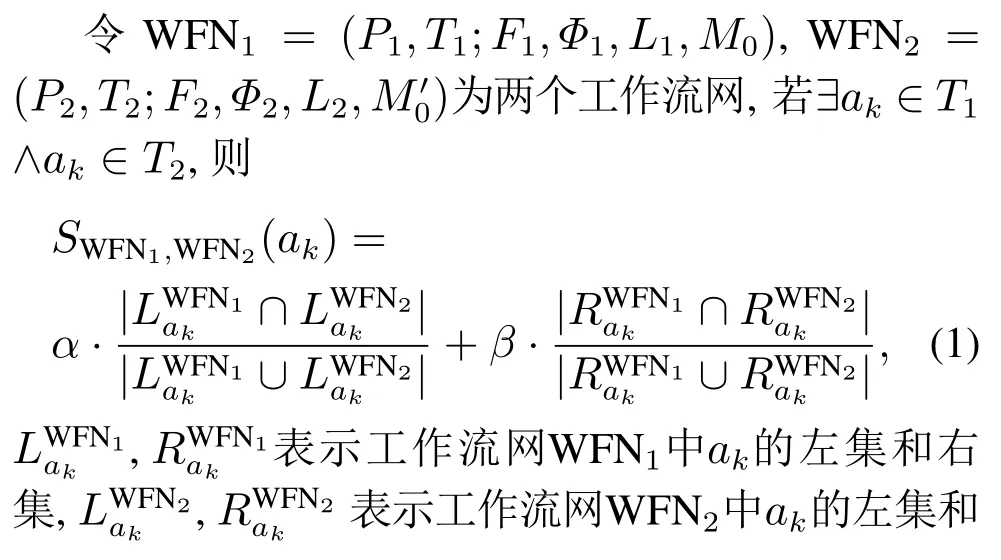


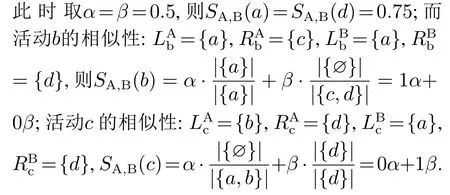
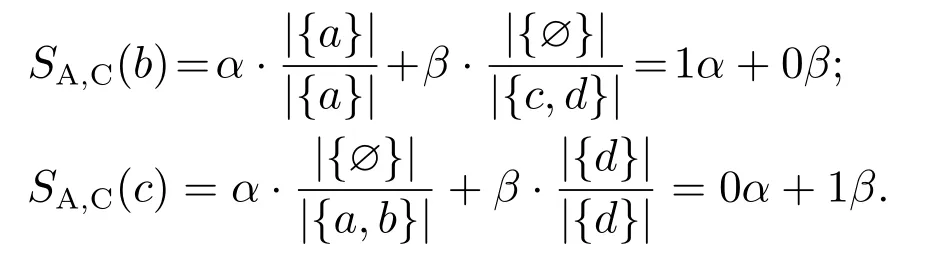
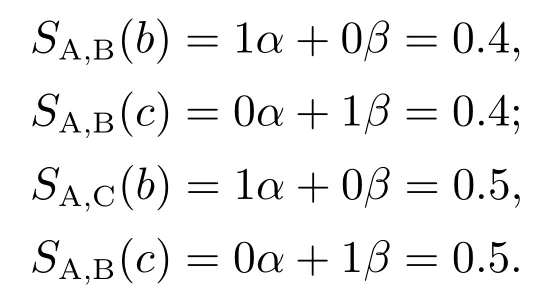
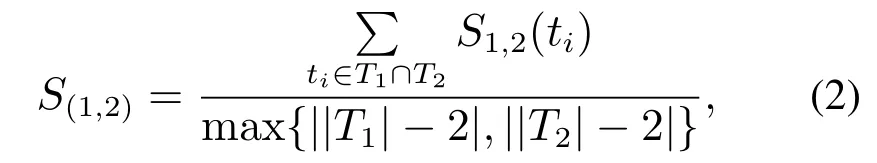
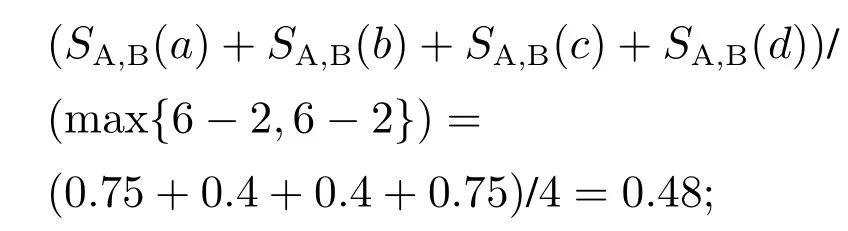
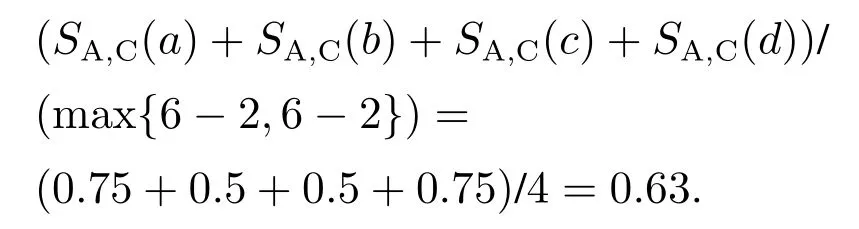
3.1 基于活动发生关系的流程相似性算法(AOR)


3.2 算法时间复杂度分析
4 案例分析
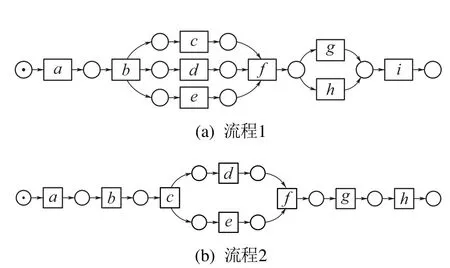
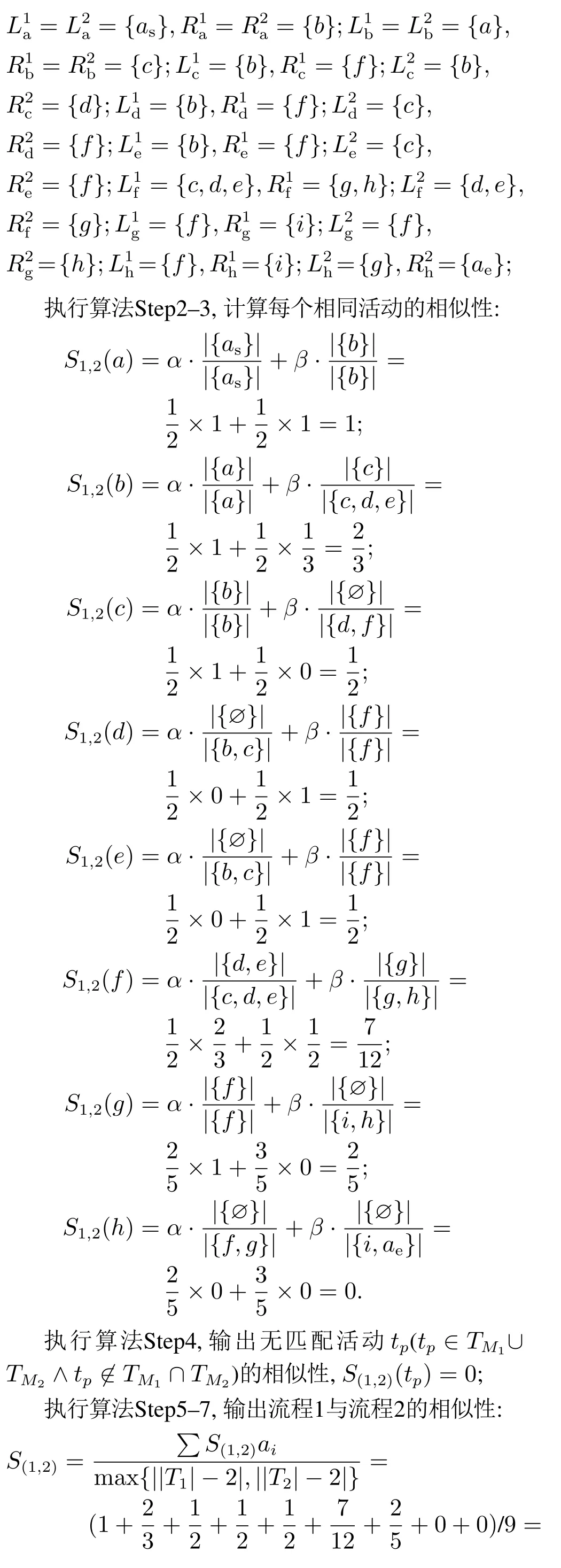
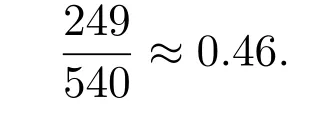
5 实验设计与仿真分析
5.1 实验设计
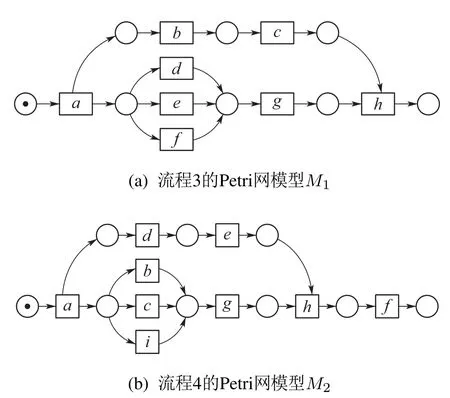
5.2 效果评估
5.3 性能评估

6 结语与展望
