线性时不变系统PID–型迭代学习控制律的单调收敛形态
2020-10-12阮小娥
刘 艳,阮小娥
(西安交通大学数学与统计学院,陕西西安 710049)
1 引言
20世纪80年代初,日本学者S.Arimoto等人针对于机械手在某一有限时间区间内重复跟踪给定期望轨迹问题,提出了迭代学习控制(iterative learning con-trol,ILC)方法[1],该方法在机器人装配、机电一体化、港口集装箱自动装卸、间歇工业过程系统等领域引起了广泛的关注与应用[2–7].迭代学习控制的宗旨是针对特定类型的系统,设计适当的迭代学习控制律,并对其学习特性,如收敛性和鲁棒性进行评价.
迭代学习控制的基本学习机理是利用系统已有的跟踪误差信息,修正或补偿系统当前运行次的控制输入,得到系统下一运行次的控制输入,以使随着系统运行次的不断增加,系统输出越来越逼近于期望轨线.经典的迭代学习控制律类型包括D–型[1,8]、P–型[9–11]、PD–型、PID–型[12–14]、高阶PD–型[15–17],以及基于反馈的PD–型、PID–型[18–19]和组合型[20]等.传统的PID–型迭代学习控制律的构造对系统动力学知识要求甚少,但学习增益是根据经验选取的,不具有自适应性,因而学习机制是被动的.当然,当系统动力学信息可通过辨识或实验测试获取时,在某种性能指标最优意义下,可得最优或自适应迭代学习策略,以期获得良好的跟踪性能,此种学习机制是积极主动式的.诸如在离散系统中,已有的最优迭代学习控制策略包括H∞型、最速下降型、Newton-Raphson 型、Gauss-Newton型、范数最优型、参数最优型迭代学习控制机制[21–27]等.
纵观迭代学习控制的收敛性和鲁棒性研究,其研究对象和研究方法多种多样.对于离散时域迭代学习控制系统而言,得益于数据采样的有限性,采用提升向量技术,可将系统输入–输出关系表为代数形式,其收敛性可转化为沿着迭代方向系统的稳定性[28–30].相对于离散系统的输入–输出代数关系,连续系统的输入–输出关系是卷积形式,其收敛性分析面临诸多困难和挑战.如,很难将控制输入从卷积积分中提取出来,即不易于用跟踪误差对学习性能进行合理的评估.如早期文献中[12,31–32],主要方法是采用λ范数度量跟踪误差,证明了D–型、PD–型、PID–型迭代学习控制律的收敛性和鲁棒性,其中λ范数的负指数函数形式巧妙地消减了对卷积积分进行估计的困难.但仔细观察λ范数度量意义下的PD–型和PID–型迭代学习控制律的收敛性和鲁棒性论证过程,不难发现收敛性是在参数λ充分大的题设下得出的,而且只考量跟踪误差当迭代次趋向于无穷大时的渐近行为,而没有考量系统在初始迭代次的暂态学习性能.此外,如文献[33]所述,理论上,当参数λ的取值充分大且当迭代次充分大时,即使跟踪误差在λ范数形式下满足精度要求,但在实际度量如能量意义下,跟踪误差在初始迭代次会远远超出工程容许度,有时会导致系统崩溃.尽管如此,根据学习机理,学者们不断积极探索,坚信当比例、积分和导数补偿增益在适当条件下,可有效提高迭代学习控制的跟踪性能.已有结果表明,P–型迭代学习控制律对耗散系统是有效的[34];适当的积分补偿可改善系统的跟踪性能,但尚无严格论证[35];此外,文献[36]在sup–范数意义下,证明了PID–型迭代学习控制算法的跟踪误差在某一子区间上是指数单调收敛的,其子区间的上界依赖于系统的状态矩阵、输入和输出矩阵以及比例和导数学习增益,这意味着比例、积分和导数补偿均可影响系统的暂态和渐近学习性能.由于sup–范数度量意义下的单调收敛性只囿于某一子区间,不能保证在整个运行区间上成立,仍会出现跟踪误差超出容许度的情形;进一步研究中,文献[17]采用Lebesgue-p范数度量跟踪误差,得出线性时不变系统的一阶PD–型迭代学习控制律是单调收敛的,给出了收敛判据由系统动力学和学习增益表达的显式表示.特别地,跟踪误差Lebesgue-2范数即是跟踪误差的能量,但该结果并未涉及积分补偿行为对跟踪性能的影响.受上文所述的积分补偿积极作用的启发,本文针对线性连续时不变系统,将积分补偿嵌入PD–型迭代学习控制策略,在Lebesgue-p范数度量意义下,研究一阶和二阶PID–型迭代学习控制律的单调收敛形态.
2 预备知识和迭代学习控制策略
考虑如下重复性单输入单输出线性时不变系统:
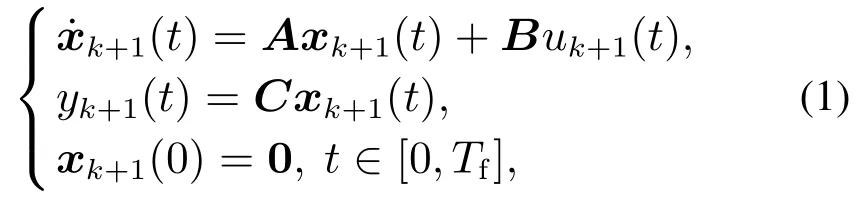
其中:[0,Tf]为系统的运行区间;k表示系统重复指标,即迭代次数;x(t)∈Rn,u(t)∈R,y(t)∈R分别表示n维状态向量、纯量控制输入和控制输出;矩阵A,B和C表示状态、输入、输出矩阵.在运行区间t ∈[0,Tf]上,假设yd(t)为系统(1)的期望轨线,且满足yd(0)=0,u1(t)为任意初次运行时的控制输入.利用初次跟踪误差,即e1(t)=yd(t)−y1(t)的比例、积分和导数值对当前运行的控制输入u1(t)进行补偿,产生系统下一次运行的控制输入u2(t),t ∈[0,Tf].依次类推,可迭代生成控制输入序列,即为传统的一阶PID–型迭代学习控制律,其数学表达式如下:
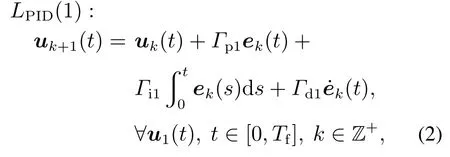
其中Γp1,Γi1和Γd1分别为比例、积分和导数学习增益.这里ek(t)=yd(t)−yk(t)表示期望轨线yd(t)与系统第k次迭代运行时由控制输入uk(t)产生的控制输出yk(t)之间的跟踪误差.值得注意的是,在学习控制律(2)中,下一次运行的控制输入uk+1(t)是由当前运行时的控制输入和跟踪误差信息组成的,算法(2)被称为一阶PID–型迭代学习控制更新律.
显然,当导数学习增益Γd1置为零时,PID–型迭代学习控制律LPID(1)或(2)就退化为PI–型迭代学习控制律LPI(1).类似地,通过设置学习增益Γp1,Γd1和(或)Γi1为零,可得到相应的D–型和P–型迭代学习控制算法.
此外,利用最近相邻2次迭代跟踪误差联合补偿当前次控制输入,可得二阶PID–型迭代学习控制律,其数学表达式如下:
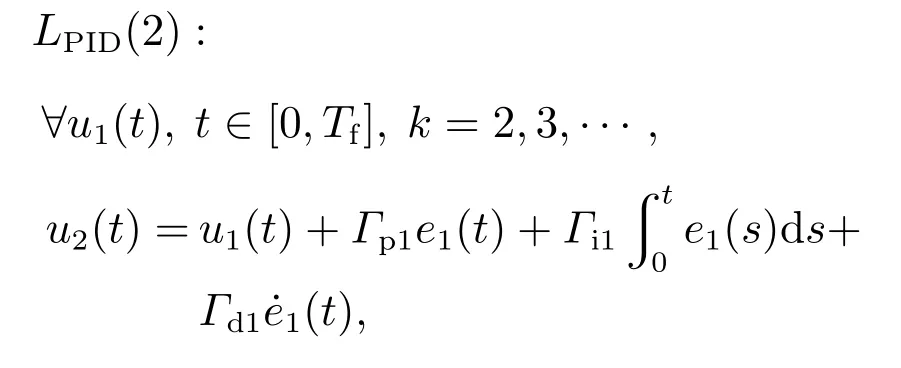
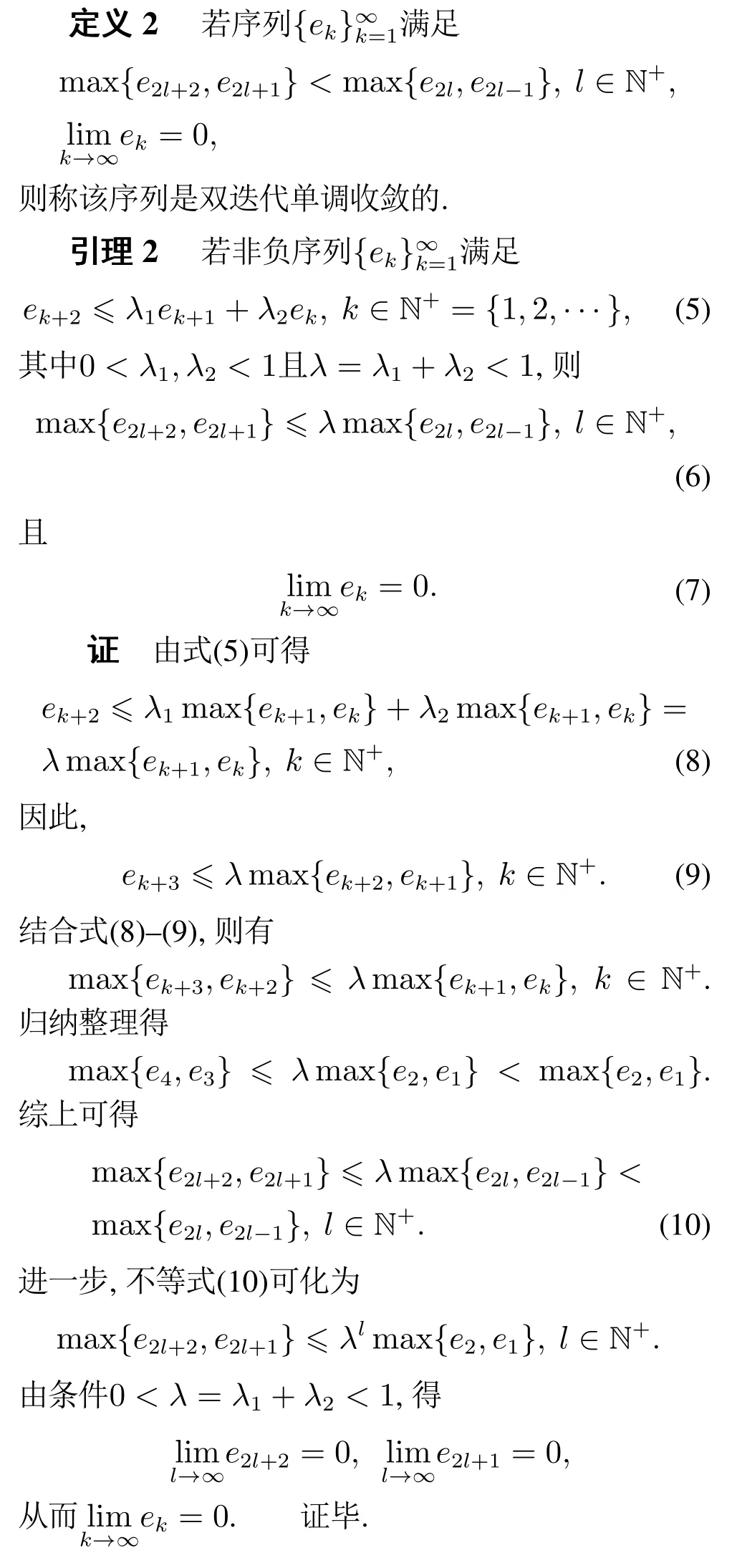
3 收敛性分析




注1类似于文献[17]中的讨论,通过适当选择学习增益,当σ2<时,可使二阶PID–型迭代学习控制律LPID(2)的收敛速度快于一阶PID–型迭代学习控制律LPID(1).
注2因为PID–型迭代学习控制器的物理含义类似于传统的PID控制器,可借鉴PID控制器增益选取的经验,选取比例、导数和积分学习增益.
4 数值仿真
在微电子制造中,快速热处理是半导体加工中不可缺少的一道工序.在短时间内,硅片的温度必须加热至较高温度.在通常情况下,单晶反应釜由常规PID控制器调节,其暂态响应有时会出现响应速度慢、稳态时间过长、存在稳态误差或暂态响应超调等现象[39].从长远的生产过程来看,快速热加工可看作为多次重复的间歇过程,因此,可采用迭代学习控制方法改善其暂态性能.假设由PID控制器调整的反应釜的动力学模型为
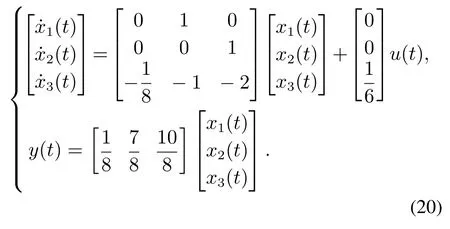
系统的运行区间设定为[0,20],初始状态为[x1(0)x2(0) x3(0)]T=0,期望轨迹线为
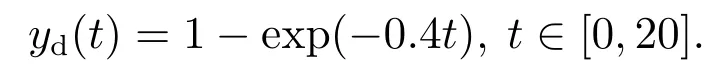
仿真中,误差的Lebesgue-2范数为
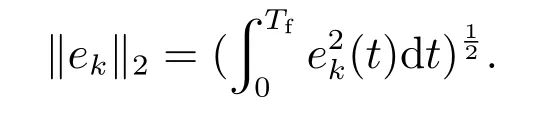
比较1一阶PID–型和PD–型迭代学习控制律的单调收敛性:为了便于对照,一阶PID–型和相对应的PD–型迭代学习控制律的比例和导数学习增益设置相同,取Γp1=1.1, Γd1=1.2, Γi1=0.05.可验证PID–型控制律的收敛因子ρ1=0.75817<1,PD–型控制律的收敛因子=0.75073<1,满足定理1的收敛条件.
图1显示PID–型和PD–型迭代学习控制律在第15次迭代时的跟踪行为,其中:实线表示期望轨线、虚线表示PID–型控制律的输出曲线、点划线表示PD–型控制律的输出曲线.图2是两种控制律的跟踪误差的2 范数曲线,其中k表示系统迭代次数.从图1和图2可以看出,一阶PID–型控制律的跟踪误差的2范数小于相应的PD–型控制律的跟踪误差的2范数,且能消除系统的稳态误差.
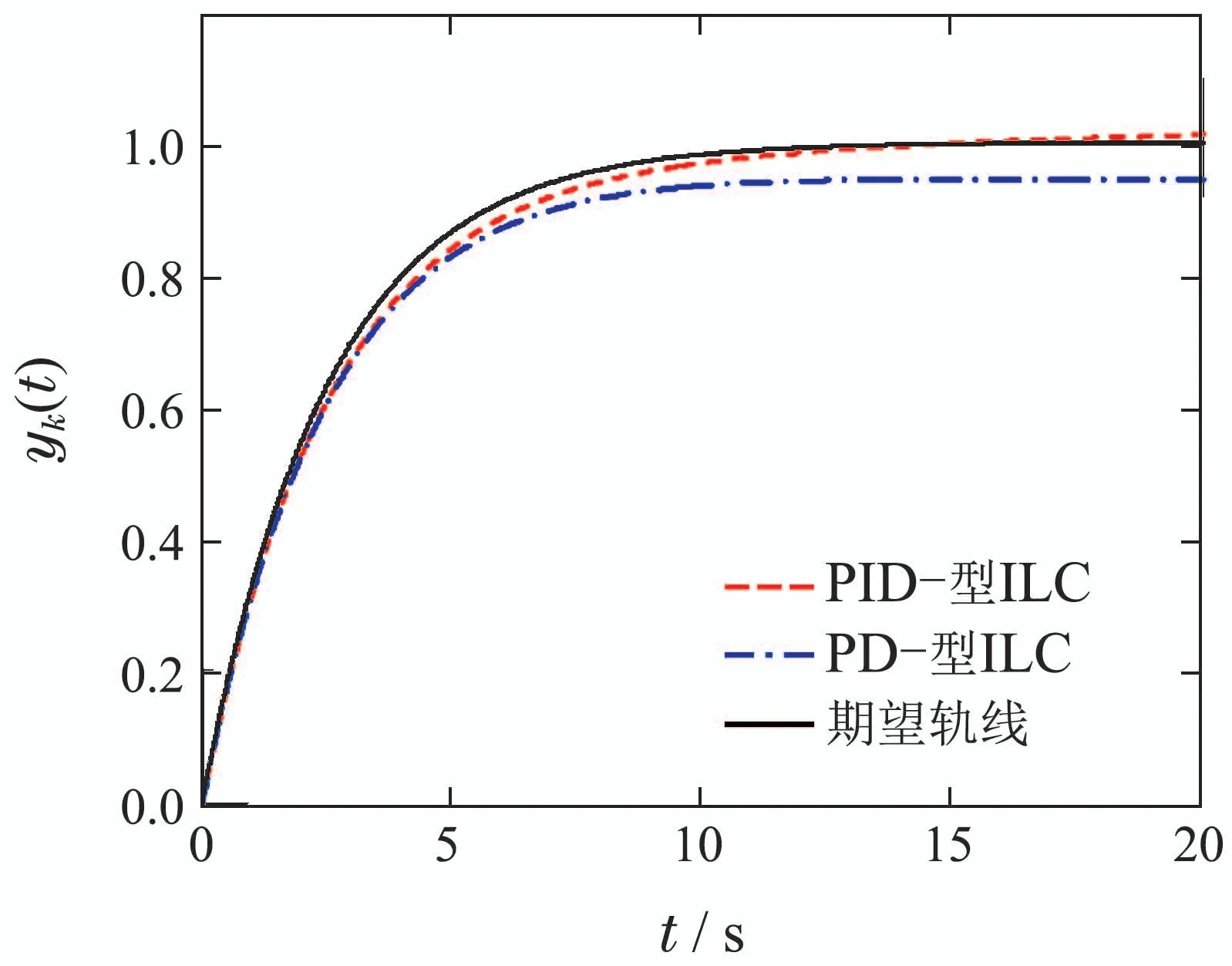
图1 第15次运行时的跟踪行为Fig.1 Tracking behavior of the 15th iteration
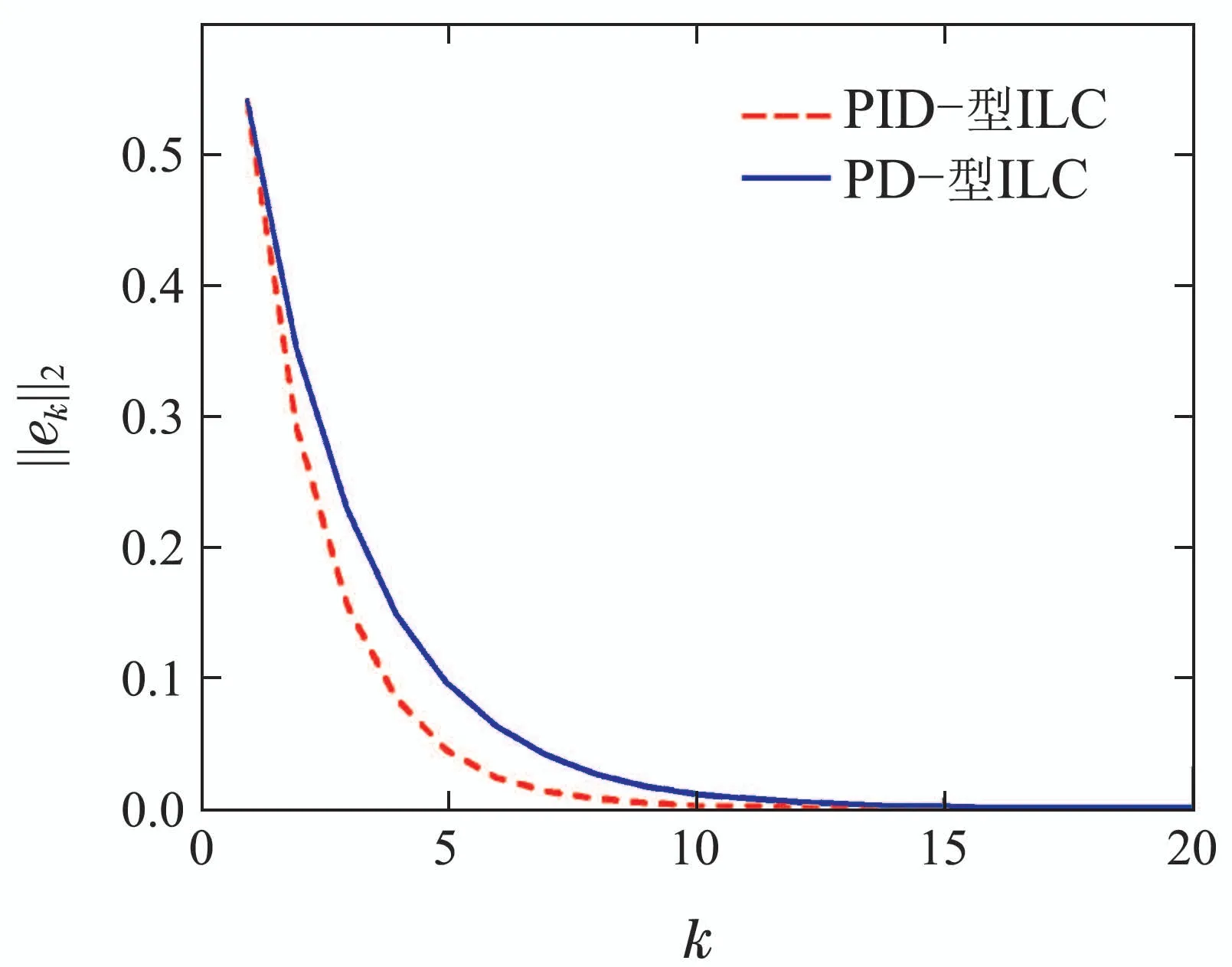
图2 跟踪误差的2范数的变化趋势Fig.2 Tracking error 2-norm tendency
比较2一阶和二阶PID–型迭代学习控制律LPID(2)的单调收敛性:在一阶和二阶PID–型迭代学习控制律中,选取学习增益分别为Γp1=1.1, Γd1=1.2, Γi1=0.03, Γp2=1.1, Γd2=1.2和Γi2=0.1,权重系数分别为ω1=0.9和ω2=0.1,通过计算可知=0.7987 < 1, σ1=0.9098 < 1和σ2=0.3978<1,满足定理2的收敛条件.图3为一阶和二阶PID–型迭代学习控制律在第10次迭代时的输出曲线.图4为2种迭代学习控制律的跟踪误差的2范数趋势,从图中可以看出一阶和二阶PID–型迭代学习控制律都具有较好的跟踪性能.
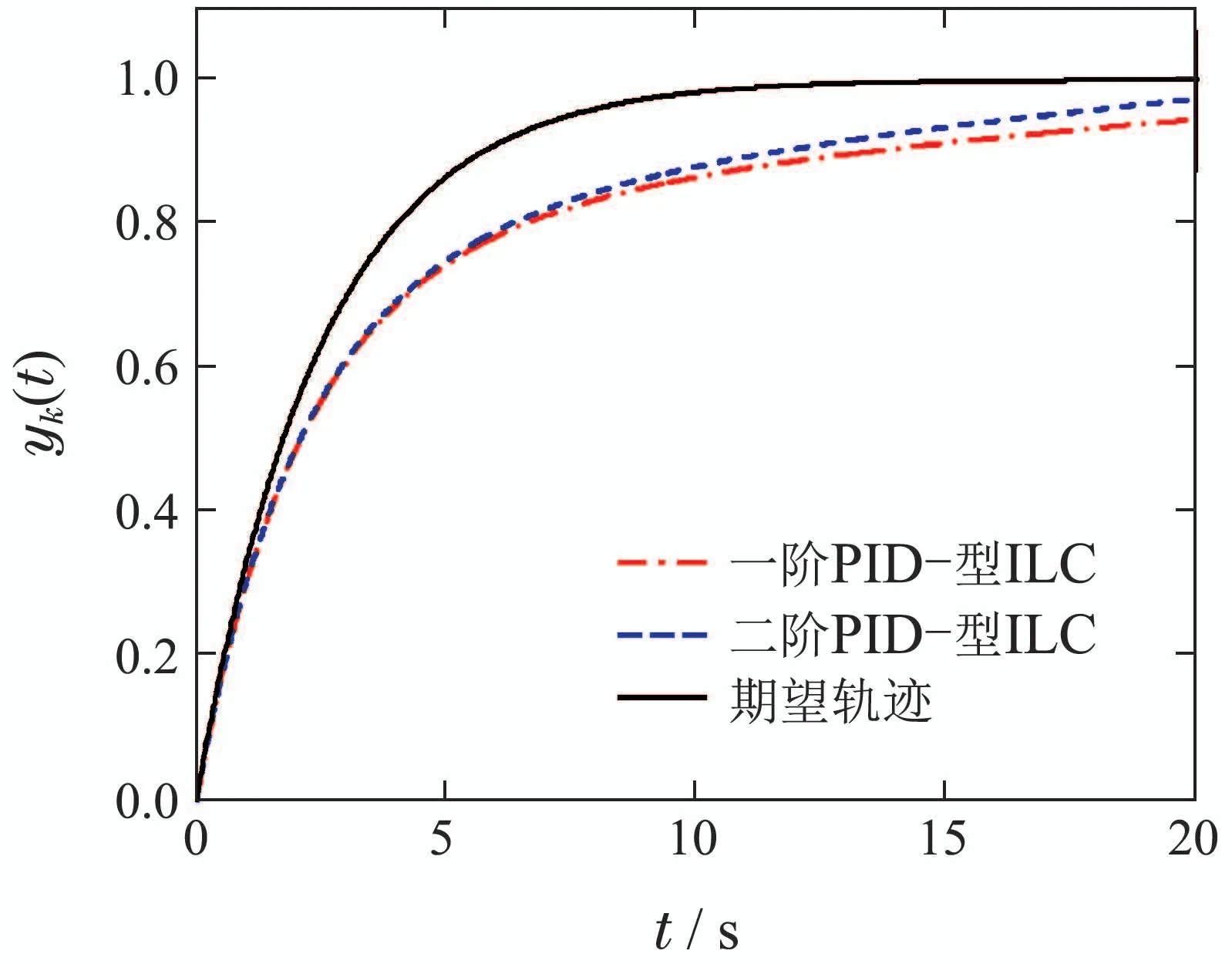
图3 第10次运行时的跟踪行为Fig.3 Tracking behavior of the 10th iteration
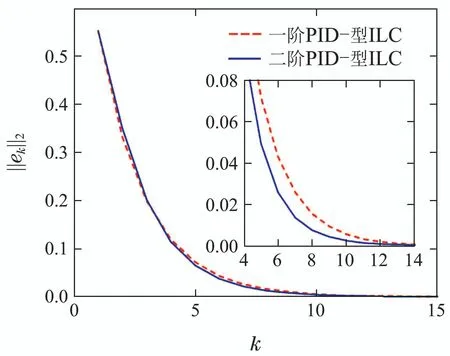
图4 跟踪误差的2范数的变化趋势Fig.4 Tracking error 2-norm tendency
4.1 结论
本文研究了一类线性时不变系统的一阶和二阶PID–型迭代学习控制律的收敛性态.在Lebesgue-p范数度量意义下,利用推广的卷积Young不等式,理论证明了控制律的单调收敛性.在证明过程中,采用范数的三角不等式对误差的2范数进行估计,这可能导致当积分补偿嵌入到PD–型迭代学习控制律中时,收敛条件较为保守.尽管如此,数值仿真表明适当选取积分学习增益,可进一步改善系统的跟踪性能;特别地,对于存在稳态误差系统,积分补偿可消除跟踪的稳态误差.由于迭代学习控制策略沿迭代方向是误差补偿方案的积累,也可看作是一种形式的积分,因此,积分增益的选择需谨慎,或可采取灵活的切换算法或自适应增益选取方法.
