面向社区问答匹配的混合神经网络模型
2020-09-03张衍坤陈羽中刘漳辉
张衍坤,陈羽中,刘漳辉
(福州大学 数学与计算机科学学院,福州 350116) (福建省网络计算与智能信息处理重点实验室,福州 350116)
E-mail:zhliu@163.com
1 引 言
近年来,社区问答网站越来越受到人们的欢迎,人们可以在问答社区上提问,同时也能够回答其他人的提问.对于一个问题可以由多个社区成员进行回答,用户通过他人的回答来得到正确的答案,随着社区问答的发展,大量的问题和答案形成了特定的知识库,自动为问题匹配正确的答案也成为智能问答的一个重要的任务.
表1展示了一个CQA问答的经典例子,答案C1和C2是好的答案,都对提问者有帮助,C3是对C1和C2的回复,表达了对这两个回答者的感谢.C4是对C1的进一步补充回答,C5表达了对C4答案的认同,C5和C3有助于确定之前的答案是好答案、坏答案或潜在有帮助的答案,但本身不包含对问题有用的信息,因此被视为坏答案.除此之外,问题和答案的文本长度较短,且由不规范,非正式的句子组成.可以看出,CQA问答具有序列上下文相关,且问答对匹配较为复杂的特点.
对于社区问答中的问答匹配,现有方法大都通过问答之间的语义进行匹配.较早的工作主要是通过特征工程对候选答案进行匹配,工作量较大,也难以适应不同的问题领域.
随着深度学习的发展,目前有许多研究工作利用深度学习来进行问题和答案对间的匹配.一些方法基于CNN来抽取问答对的语义进行问答匹配[1,2].另外一些方法在通过CNN学习问答对的语义的基础上,利用LSTM学习问答序列的上下文相关性[3,4].除此之外,一些方法引入注意力机制来对问答对进行匹配[5,6].与特征工程方法相比,深度学习方法无需进行复杂的特征选择工作.
先前的研究工作在社区问答中的问答匹配问题上取得了一定的效果,但是问答匹配仍然是一件具有挑战性的任务,其原因主要在于:1)问题和答案之间存在词汇鸿沟,数据具有稀疏性;2)答案质量不一,并且有些回答是用户之间的讨论,上下文具有相关性.3)不同回答者更可能对擅长的领域提供高质量的答案,分析用户所擅长领域,有助于减轻数据的稀疏性问题,提升问答匹配的效果.

表1 社区问答案例Table 1 Example of CQA
针对上述问题,基于社区问答的问答匹配方法应从问题/答案的语义相关性、答案序列的上下文相关性、用户-问题的相关性三个方面入手.因此,本文提出了一种面向社区问答匹配的混合神经网络模型HNNMA(Hybrid Neural Network with Multi-dimensional Attention),工作的主要贡献可归纳如下:
·融合CNN和LSTM,更加准确地学习问答对的语义信息和上下文相关性.
·对用户历史回答进行建模,通过注意力机制分析问题与用户历史回答之间的相关性,提升问答匹配的效果.
·在SemEval-2015CQA官方数据集上与多个现有的模型进行了实验对比,验证了HNNMA模型的有效性.
2 相关工作
问答匹配是社区问答的一项关键性任务,通常可被认为是分类或者排序任务.早期的问答匹配研究多基于特征工程的、语言工具和外部资源等方法.文献[7]利用线索级特征来改进问答匹配分类的性能.文献[8]提取词匹配特征,非文本特征等5组特征后,使用SVM对答案质量进行预测.文献[9]提出了层次分类的方法,其使用集成学习以先将答案分成好坏两类,再对坏答案进行细分的方式来进行问答匹配.文献[10]使用基于树编辑的特征,构造一个线性链条件随机场,将社区问答的问答匹配看作答案序列标注问题.文献[11]结合句法和浅层语义信息,使用SVM进行训练,实验表明两者在问答匹配上具有一定的贡献.上述方法往往需要手工进行特征构造,工作量大,并且对领域知识有一定的要求,也难以处理多语言的问答匹配问题.
近年来深度学习在包括社区问答在内的很多领域获得了应用.文献[1]基于CNN来计算语义,不需要额外的语义分析工具,而是引入问答对词之间的相关程度作为特征附加到词向量矩阵,输入CNN中来得到问答对匹配分数.文献[2]提出了结合全局句子语义信息和局部特征的CNN模型进行问答匹配.文献[12]使用LSTM与2D神经网络等深度学习模型进行语义特征提取,并与传统的NLP特征相融合来进行问答匹配.在提取问答对语义信息的同时,问答序列的上下文相关性也得到了关注.文献[3]将问答匹配看作序列标注问题,使用CNN学习问题和答案的语义表示,使用LSTM学习答案序列的上下文相关性.文献[4]在文献[3]的基础上设计了一个双阶段策略来提高上下文相关性的学习能力,并结合线索特征来进行问答匹配.
除此之外,一些研究在问答匹配模型中引入了注意力机制.文献[5]在LSTM上使用注意力机制来增强对问答序列的上下文相关性的学习,并结合条件随机场来进行问答匹配.文献[6]结合RNN与CNN,并加入注意力机制来学习问答对的语义匹配关系以进行问答匹配.文献[13]认为问题主题和问题主体具有相似性和差异性,使用多重注意力机制[14]学习问答对的语义相似度.文献[15]使用混合注意力机制学习句子中的局部相关性和句子间的相关性,进行问答对匹配,并利用CNN学习用户的历史回答,从而对用户建模.文献[16]使用transformer network[17]的多头注意力机制来对词向量间的依赖关系建模,再输入LSTM来获取问题或者答案句中的全局信息和序列特征,最后通过加权平均池化,最大池化,注意力池化三种聚合策略来产生句子的向量从而进行问答对匹配.
上述方法虽然考虑到问答序列的上下文相关性,但抽取文本的长距离信息的能力较差,本文的HNNMA模型引入类似文献[18]的CNN架构,能够抽取更长距离语义信息,更加准确的抽取问答对的语义,以便于问答对的语义匹配和上下文相关性学习.用户的历史回答在一定程度上反应了用户的兴趣点和擅长领域,也是用户权威度的体现.文献[15]虽然有对用户进行建模,但是只是简单的通过卷积网络得到用户的向量表示,没有实际与问题交互.文献[14]提出了多维注意力机制,其与传统注意力机制不同之处在于计算的注意力分数是一个特征向量,而不是一个张量,能够学习到更多维度的语义特征.文献[13]采用了多维度注意力机制,但是只是在问答对之间进行交互.本文的HNNMA模型使用多维度注意力机制分析问题和用户历史回答的相关性,判断用户擅长领域和当前问题的相关性,从而得到更加准确的用户表示.最后通过用户表示和问答对表示的融合提升问答匹配的精度.
3 模 型
本文将社区问答中的问答匹配作为分类任务.模型的总体架构如图1所示,其中模型包括以下组件:词向量层,问答对语义层,问答序列上下文相关性层,用户模型层,特征融合和归一化层.

3.1 词向量层
对问题、答案和用户历史回答的输入句子,用s=[w1,w2,…,wk]来表示,k表示输入句子长度,wk表示第k个单词对应的词向量,wk∈Rd,d是词向量的维度大小.
3.2 问答对语义层
对给定的问题和对应候选答案池中的每个答案,可以形成问答对(q,at),q表示问题,at表示第t个候选答案,使用CNN来对问答对的语义进行学习.CNN在自然语言处理任务中的文本分类广泛使用,并取得了不错的效果[18,19],其中文献[18]提出的深度金字塔卷积网络是严格意义上第一个单词级别上的深层文本分类卷积网络,文献[19]对文本的长距离依赖关系学习的能力较弱,但是文献[18]网络层数更深,所以可以学习到更长距离的文本依赖关系.因此使用类似文献[18]的CNN架构来学习问答对的语义表示,对于输入的问答对句子(q,at),使用并列的CNN架构来分别得到句子的语义表示.
对输入句子s,首先进行一维卷积,卷积核为3,过滤器数量为250,结果作为CNN架构最底层的输入向量,接着对向量进行两次的等长一维卷积操作,卷积大小为3,过滤器数量为250.同时,为了避免梯度弥散问题,使用文献[20]的shortcut方法对区域向量和两次卷积后的向量连接.使用大小为3,步长为2的最大池化对向量序列进行处理,增加网络能够感知到的文本片段,再进行两次的等长卷积操作,重复两次池化卷积操作.最后得到语义表示vq和va.对于输入问答对(q,at),
vq=CNNq(q,Wq)
(1)
va=CNNa(at,Wa)
(2)
其中,vq,va分别是问答对经过CNN后学习到的语义表示,Wq,Wa分别是CNN模型的参数.
为了学习到问题和答案对(q,at)的融合语义表示,将vq,va连接,vqa=[vq,va]输入到隐藏层获得联合语义表示st.
st=σ(Whvqa+bh)
(3)
其中Wh,bh是隐藏层的参数,σ是relu激活函数.
3.3 问答序列上下文相关性层
在社区问答中,对回答者的答案并没有严格的要求,因此答案有可能是提问者经过实践后对上一个回答者的答案表示认同或者感谢.也可能是回答者对问题的一系列讨论,如当一个答案内容不详细或者不正确时,其他回答者有可能对这个答案进行补充或者反驳.因此社区问答的问题和答案序列间存在着一定且关键的上下文关系.
LSTM被广泛应用于对文本上下文关系的学习.LSTM包括输入门it,遗忘门ft,输出门ot和记忆单元ct.对一个问题答案对序列R,使用问题答案对的语义序列进行表示.R=[s1,…,st,…,sn],st表示第t个问答对的语义表示,n表示问题答案对的语义序列长度.将每个问答对语义表示作为一个时间步输入到Bi-LSTM中进行学习.则对第t个时间步st有:
it=σ(Wsist+Whiht-1+bi)
(4)
ft=σ(Wsfst+Whfht-1+bf)
(5)
ct=ftct-1+ittanh(Wscst+Whcht-1+bc
(6)
ot=tanh(Wsost+Whoht-1+bo)
(7)
ht=ottanh(ct)
(8)
其中,Wsi,Whi,bi,Wsf,Whf,bf,Wsc,Whc,bc,Wso,Who,bo是可训练参数,σ是sigmoid激活函数.
3.4 用户建模
在社区问答匹配问题中,数据的稀疏性和词汇鸿沟是两个关键性的挑战,特别是当多数回答十分简短时.因此可以通过使用用户的历史回答来对用户建模.类似文献[13],本文采用多维度注意力机制来对用户建模,使用户历史回答和问题进行交互,从而更好地学习问题和用户历史回答文本间的相关性,如图2所示.

图2 基于多维注意力机制的用户建模结构Fig.2 User modeling structure based on multi-dimensional attention mechanism

qs=[s1,s2,…,sl]
(9)
qb=[b1,b2,…,bm]
(10)
(11)
(12)
其中qs是问题主题的词向量表示,si表示问题主题第i个词的向量化表示,qb是问题主体的词向量表示,bj表示问题主体第j个词的向量化表示.
通过全连接层计算多维注意力权重,激活函数为tanh函数,然后将获得的向量归一化计算,最后得到的输出是问题主体中的每个词向量乘上对问题主题的词向量注意力权重的乘积之和,计算公式如下:
(13)
(14)
(15)

获取问题的相似表征向量,计算公式如下:
Fp=σ(Wqfqs+WsfSap+bf)
(16)
Sp=FpΘqs+(1-Fp)ΘSap
(17)
其中Wqf,Wsf,bf是训练参数,σ是激活函数,Θ表示逐点相乘,得到问题的相似表征向量Sp,类似得到问题的差异表征向量So,将Sp和So和连接得到问题表征向量Qr.
将问题和用户历史回答对齐,计算问题表征Qr和用户历史回答表征Ua的注意力加权和,计算公式如下:
(18)
(19)
(20)
(21)
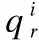
将问题和用户历史回答对齐,通过多维注意力机制得到问题表征qsum和用户历史回答表征向量usum,计算公式如下:
As=Watanh(WsaSai+bs)+bas
(22)
(23)
其中Wa,Wsa,bs,bas是可训练的参数,usum通过同样的方法得到.
最后将问题的表征向量和用户的历史表征回答向量连接,得到用户表征向量:
Ur=[qsum,usum]
(24)
3.5 特征融合以及输出层
对得到的问答对表征向量ht,t表示第t个问答对,和用户表示向量Ur,使用一个隐藏层来对特征学习以便于将特征融合.
h=tanh(Wqaht+WuUr)
(25)
其中Wqa,Wu是可训练的参数,h是最终的向量表示.
将得到的最终向量表示h输入到softmax进行归一化操作,计算答案属于各个类别的概率:
p(yi)=softmax(h)
(26)
其中,p(yi)为预测为类别i的概率,0≤p(yi)≤1,L为类别的总数.
3.6 模型训练
模型训练的目标是最小化损失函数,损失函数的计算公式如下:
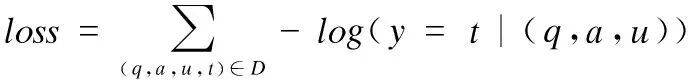
(27)
其中D为问答对训练集.t∈{0,1,2},0表示答案是好的,1表示答案是潜在有帮助的,2表示答案是坏的.通过梯度优化算法AdaGrad进行学习率更新以及利用反向传播迭代更新模型参数,以最小化损失函数来训练模型.
4 实 验
4.1 数据集和评估指标
本文实验采用SemEval-2015CQA数据集对提出的模型进行评估.在SemEval-2015CQA数据集中,每个问题有对应的候选答案池,对应若干个答案.数据集分为已标注的数据和未标注的数据.在已标注的数据中,每个答案被分为3类中的其中一类:好的,坏的,潜在有帮助的.数据集的统计信息如表2所示,数据集来自QatarLiving(1)https://www.qatarliving.com/forum论坛,且每个问题和答案包含用户id.实验采用Macro-F1、Macro-precision以及Macro-recall作为评估指标.

表2 SemEval-2015社区问答数据集的统计Table 2 Statistics of SemEval-2015 dataset
4.2 实验设置
首先对数据集包含的问答对进行预处理,词向量使用预训练的Glove词向量,通过300维的Glove词向量将所有的词进行词向量化,对于未登录词使用全0的词向量表示.将问题、答案和用户历史回答的长度分别设为100,100,400的固定值,当文本长度小于设定长度时用0填充,大于设定长度时截断.在卷积网络中,过滤器的宽度设为3,过滤器的大小设为250.在长短时记忆网络中,记忆单元的数量设为360.L2系数设为0.01.
实验包含以下部分:1)模型HNNMA和对比算法在SemEval-2015CQA数据集上的实验性能对比.2)模型HNNMA和对比算法在好的、坏的和潜在有用的3个类别上的性能对比,评估指标为Macro-F1.3)不同词向量对模型HNNMA的实验性能的影响.4)各个子模型对模型HNNMA性能的贡献分析.
4.3 对比算法
实验所对比的算法包括基于特征工程的JAIST[8]、HITSZ[9],以及基于深度学习的F-RCNN[3]、B-RCNN+[4]以及A-ARC[5]等算法.
·JAIST:将特征分为5组,如词匹配特征组,非文本特征组,基于词向量的特征等.然后使用SVM-regression模型来对特征进行学习从而对答案质量进行预测.
·HITSZ:对答案使用两级层次分类,先分成两类再对第一级分类进行细分.除此之外,使用多个分类器同时进行学习,选择前N个分类器投票作为最终的结果.
·F-RCNN:结合CNN和前向RNN来对问答对序列进行处理.首先使用CNN分别对问答对句子语义进行学习,然后使用前向RNN对问答对语义序列上下文相关性进行学习,最后使用softmax来对答案进行分类.
·B-RCNN+:相比F-RCNN,在CNN上使用了双向RNN,并且添加了额外的外部特征向量,在双向RNN训练时进行微调的操作.用B-RCNN表示未经过微调和添加外部特征的深度学习模型.
·A-ARC:提出了一个带有注意力机制的深度神经网络,在CNN对句子编码后,使用带有注意力机制的LSTM来对答案序列间相关性学习,然后输入条件随机场来进行学习问答匹配.
4.4 实验分析
表3是HNNMA模型和对比算法在SemEval-2015CQA数据集上的Macro-average分数对比结果.表4是HNNMA模型和对比算法在好的,坏的,潜在有帮助的这3个类别上的Macro-F1分数对比结果.从表3中可以看到,HNNMA取得了优于其他对比算法的结果,其中在Macro-P上优于最优对比算法0.15%,在Macro-R上优于最优对比算法0.63%,在Macro-F1上,HNNMA相对最优对比算法B-RCNN+提高0.69%.但是B-RCNN+在深度学习模型的基础上,引入了外部特征.在同样没有引入外部特征的情况下,HNNMA模型相对模型B-RCNN提高2.64%,相对于排名第二的对比算法A-ARC提高了1.11%,证明了HNNMA模型的有效性.

表3 SemEval-2015数据集性能比较结果Table 3 Comparison on Semeval-2015 data set
表3中的JAIST和HITSZ需要大量的特征工程工作,而HNNMA是一个端到端的深度学习模型,通过训练能够自动得到特征向量,从而避免大量人工提取特征.从实验结果来看,HNNMA获得了远超JAIST与HTISZ的性能,表明其自动学到的特征向量更为有效.对比F-RCNN与A-ARC的结果发现,可以通过学习问答对语义和语义序列相关性提高问答匹配的效果.基于上述想法,使用类似文献[18]的架构来对问答对的语义进行学习,从而更好地学习问答对的上下文相关性.从表3可以看到实验结果得到提高,表明对问答对的语义和问答序列的上下文相关性学习性能得到改善.
从表4可以发现,HNNMA在3个分类上的都取得了较高的评分,在潜在有帮助的类别上,更是取得了24.30%的最高Macro-F1分数.潜在有帮助的类是中间类,也是最小的类,只有训练数据的10%是中间类.通过比较可以得到,HNNMA模型在其他类性能接近的情况下,能够更好地识别潜在有帮助的类.HNNMA在潜在答案上性能有所提高的原因在于能够更好地捕捉问题和答案序列的语义相关性,有利于识别潜在答案.因为潜在答案可能包含部分答案信息,或者是对好的答案的评论和补充.除此之外,用户建模也有所帮助,其原因是有经验或者对话题感兴趣的用户更能提供好的答案,其答案也更可能是潜在有用的.

表4 SemEval-2015数据集上的Macro-F1分数Table 4 Macro-F1 scores on Semeval-2015 data set
表5显示了不同词向量模型对HNNMA的影响.本文分别使用100、200、300维的Glove词向量以及word2vec词向量进行实验.从表5可以看出,Glove词向量能够取得优于word2vec的实验结果.在词向量的维度上,维度更多的Glove词向量能够取得更好的实验结果,其原因在于维度多的词向量包含更多的语义信息,更有利于识别出答案类别.

表5 HNNMA使用不同词向量模型的性能比较Table 5 Performance of HNNMA model on different word embedding
除此之外,本文对模型子结构对HNNMA的贡献进行对比实验,HNNMA(CRNN)相较完整的HNNMA模型没有使用多维注意力机制来对问题和用户历史回答进行交互,而是使用CNN学习问答对的语义表示后,输入Bi-LSTM对问答序列间序列相关性进行学习.HNNMA(UCNN)相较完整的HNNMA模型没有对问答序列间的上下文相关性进行学习,而是使用CNN对问答对语义进行学习,同时通过多注意力机制对用户建模.
表6是子模型在SemEval-2015CQA数据集上的Macro-average分数对比结果.表7是子模型在好的,坏的,潜在有帮助的这3个类别上的Macro-F1分数对比结果.表6中HNNMA(CRNN)的Macro-F1分数为57.78%,对比表3的B-RCNN的56.82%提高了0.96%,表明HNNMA模型能够更好的对问题和答案对的语义和问题和答案对间的语义序列相关性进行学习.HNNMA(UCNN)的Macro-F1分数为57.10%,实验结果同样较B-RCNN高,表明对用户历史回答建模有利于问答匹配.完整的HNNMA模型的Macro-F1分数相较两个子模型分别提高了1.68%和2.36%,表明两个模型子结构对HNNMA模型性能提高都有较大贡献.在表7可以看到,HNNMA(CRNN)和HNNMA(UCNN)与HNNMA相比,在好的和坏的这两类上取得了相近的精度.但是在潜在有帮助类上,HNNMA模型取得远高于两者的实验结果.实验表明这两个模型子结构有助于识别出潜在有帮助的类,能学习到有益于问答匹配的不同隐藏信息.

表6 子模型性能比较Table 6 Performance comparison of submodels

表7 子模型在3个类别上的Macor-F1分数Table 7 Macro-F1 scores of submodels on individual categories
5 总 结
本文提出了一种在社区问答的问答匹配的解决方案.首先使用CNN模型来对问题和答案对的语义信息进行抽取,再使用LSTM来对问题和答案对语义序列间的上下文相关性进行学习.同时,利用多维注意力机制来对用户历史回答和问题交互,从而对用户建模.通过结合问答对语义和问答对语义序列上下文相关性以及用户建模来对答案进行匹配.在SemEval-2015CQA数据集上进行的实验表明,HNNMA模型在性能上优于现有的系统和神经网络模型.HNNMA模型对问题和答案对的序列上下文相关性和用户建模的学习是有效的,能够改善问答匹配.在未来,我们将考虑旋转记忆单元[21]等模型对问答对的语义序列上下文相关性进行学习,进一步提升模型性能.
