ON-LSTM和自注意力机制的方面情感分析
2020-09-02张忠林李林川朱向其马海云
张忠林,李林川,朱向其,马海云
1(兰州交通大学 电子与信息工程学院,兰州730070)2(天水师范学院 电子信息与电气工程学院,甘肃 天水 741001)
E-mail:llc_1995@163.com
1 引 言
文本情感分析,又称意见挖掘(Opinion Mining)、倾向性分析,是对具有主观情绪色彩的文本信息进行分析、处理、归纳和研究的过程[1].随着大数据技术的快速发展,利用计算机技术对各大社交媒体或网络平台上的评论、留言等文本信息中蕴含的观点和舆论进行情感分析,越来越受到各大企业和研究人员的重视和关注.
文本情感分析最早是由Nasukawa[2]提出,用于判断句子所表达的情感极性.早期的文本情感分析更多的是关注句子整体的情感倾向,而随着研究的深入,研究者们将文本情感分析细分为文档粒度(document level)、句子粒度(sentence level)、方面粒度(aspect level)三种粒度.其中,与文档级和句子级的情感分析不同,方面情感分析(Aspect Based Sentiment Analysis,ABSA)同时考虑了目标词与情感信息的关系,通过给定句子和主题词,方面情感分析可以判断出主题词在句子中的情感倾向.同一个句子中针对不同的方面可能会有不同的情感倾向,例如,在句子“食物很好,但服务很差”中,“食物”方面的情感极性是积极的,而“服务”方面的情感极性则是消极的.因此,基于方面的情感分析能提供比一般情感分析更细粒度的信息,更具有研究价值和商业价值,是目前自然语言处理(Natural Language Processing,NLP)领域里最热门的研究方向之一.
Hochreiter和Schmidhuber[3]在1997年提出了长短时记忆(Long Short Term Memory,LSTM)神经网络模型,有效解决了循环神经网络(Recurrent Neural Network,RNN)在处理文本中上下文由于情感词的长期依赖而导致的梯度爆炸和梯度消失问题.随着神经网络在NLP领域的广泛应用,许多学者开始使用LSTM进行情感倾向分析.吴鹏等人[4]使用双向LSTM(Bidirectional Long Short Term Memory,Bi-LSTM)与CRF结合提出了一种网民负面情感识别模型EBiLSTM,用来判断网民负面情感和非负面情感的类别.孟仕林等人[5]词嵌入基础上增加情感向量,并采用BiLSTM获取文本的特征信息进行情感分类.Al-Smadi等人[6]使用两种LSTM神经网络实现阿拉伯酒店评论的方面情感分析.王文凯等人[7]通过在输出端融入Tree-LSTM提高了非连续词之间的关联性,在微博情感分析上表现良好.同时,也有许多学者通过改变LSTM内部门结构提高情感分类的准确率.Greff[8]在论文中探讨了基于Vanila LSTM[9]的8个变体,并比较了他们之间的性能差异.Cho等人[10]在2014年提出门循环单元(Gated Recurrent Unit,GRU),通过将LSTM中的遗忘门和输入门合成单一的更新门(update gate),并混合了细胞状态和隐藏状态,旨在解决LSTM计算开销较大的缺点,在小样本数据集中表现优异.
随后,Bahdanau等人[11]首次将Attention机制由计算视觉领域引入到NLP领域中,利用Attention机制在输入的文本信息中有选择性地学习重要信息并在模型输出时将其与输出序列相关联.Zhou等人[12]基于Attention机制和Bi-LSTM提出了基于特征方面的关系分类模型.Tang等人[13]针对目标依赖的细粒度文本情感分析任务提出了TC-LSTM、TD-LSTM两个模型,通过两个LSTM从左右两个方向获取情感词与上下文的关联,从而提升方面情感分析效果.Wang等人[14]提出了一种结合注意力机制的ATAE-LSTM模型,通过attention机制给予方面情感项不同的权重,使得模型能更好地分析情感极性.曾锋等人[15]提出一种基于双层注意力循环神经网络模型,通过双层注意力分别捕获不同单词的重要性.彭祝亮等人[16]提出一种结合双向长短记忆网络和方面注意力模块(BLSTM-AAM)的网络模型,利用方面注意力对不同的方面同时独立训练,充分提取特定方面的隐藏信息.
以上的模型都只考虑了方面情感项在模型输入层或隐藏层处理过程中的结合,并没有体现出文本的层级结构信息.为解决以上问题,本文提出了一种方面情感分析模型,在隐藏层加入了有序神经元(Ordered Neurons),使得模型能无监督地学习句子的句法结构,并在连接层采用自注意力(Self-Attention)机制,让模型更容易获取到方面情感词在句子中的情感极性.本文提出的模型不仅提高了方面情感分析的准确率,而且在神经网络中融合了层级结构,使得模型更容易判断句子中的方面情感倾向.
2 相关工作
2.1 ELMo预训练模型
ELMo(Embeddings from Language Models)是由Peters等人[17]提出的一种动态预训练模型.常用的Word2Vec方法[18]本质上是一种静态模型,使用Word2Vec训练完的词汇不会跟随上下文的场景变化而发生变化.例如,针对“苹果”这一词汇,文本序列“我买了三斤苹果”中的“苹果”表示一种水果;“我买了一个苹果8”中的“苹果”表示一种手机品牌,但在Word2Vec中使用的是同一个词向量进行表示.这导致在多义词情况下使用Word2Vec预训练时会得到一个混合多语义的固定向量表示,降低了预训练效果.相比较Word2Vec,ELMo模型很好地解决了这一问题.
ELMo基于双层LSTM(Bidirectional Long Short Term Me-mory,Bi-LSTM),主要做法是经过先训练一个完整的语言模型(Language Model,LM),再利用语言模型处理需要训练的文本,依据上下文生成能改变语义的词嵌入向量.它是由前向语言模型和后向语言模型两部分组成,其计算过程如式(1)、式(2)所示:
(1)
(2)
其中,(t1,t2,…,tN)表示N个单词的序列.
双层语言模型(Bidirectional Language Models,BiLM)整合了上面的两种语言模型,目标函数为前后向语言模型的联合对数似然函数,如式(3)所示:
(3)
其中,Θx表示输入的标记嵌入(token embedding),Θs表示输出的softmax层参数.
ELMo的模型结构如图1所示.
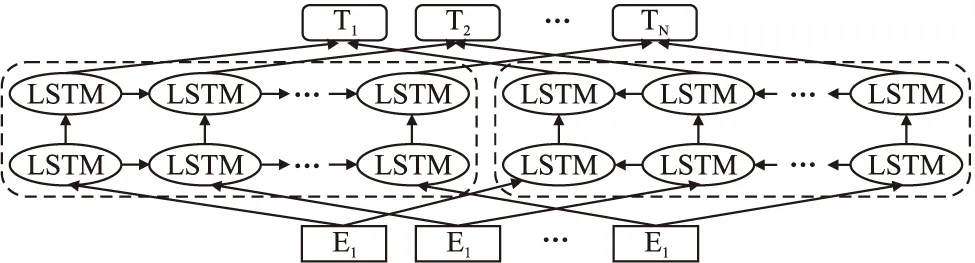
图1 ELMo模型结构图Fig.1 Model structure of ELMo
ELMo模型在解决很多NLP下游任务中表现得十分优秀,通常采用与初始词向量或隐藏层输出向量拼接,在SNLI、SQuAD等多个数据集上的性能都有所提升.
2.2 ON-LSTM模型
有序神经元长短时记忆网络(Ordered Neurons Long Short-Term Memory,ON-LSTM)通过对神经元进行特定排序将层级结构(树结构)整合到传统的LSTM中,使得LSTM神经元自动学习到层级结构信息[19].
传统的LSTM模型主要解决长距离依赖所产生的梯度消失和梯度爆炸问题,其更新过程如式(4)-式(9):
ft=σ(Wfxt+Ufht-1+bf)
(4)
it=σ(Wixt+Uiht-1+bi)
(5)
ot=σ(Woxt+Uoht-1+bo)
(6)
(7)
(8)
ht=ot∘tanh(ct)
(9)
其中,ft,it,ot分别代表LSTM模型中的遗忘门、输入门和输出门,xt和ht-1表示当前信息和历史信息,σ表示sigmoid函数,tanh是双曲正切函数.

ft=σ(Wfxt+Ufht-1+bf)
(10)
it=σ(Wixt+Uiht-1+bi)
(11)
ot=σ(Woxt+Uoht-1+bo)
(12)
(13)
(14)
(15)
(16)
(17)
ht=ot∘tanh(ct)
(18)
ON-LSTM的模型结构如图2所示.

图2 ON-LSTM模型结构图Fig.2 Model structure of ON-LSTM
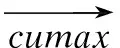
(19)
(20)
2.3 自注意力机制
自注意力机制在文献[20]中首次提出,是一种注意力机制的特殊情况,主要用于关注句子本身从而抽取出相关信息.
注意力机制最早在计算机视觉图像领域被提出,通过模仿人眼快速扫描事物,并将聚焦点设置到关注的目标区域.随后Bahdanau等人[11]将其应用到NLP领域并取得不错的效果.其本质为一个查询(Query)到一系列键值对(Key-Value)的映射,具体做法为采用Encoder-Decoder框架,将Query和每个Key进行相似度计算得到权重,然后使用softmax函数进行归一化,最后将权重和相应的键值Value进行加权求和得到最终的Attention.其基本模型如图3所示.

图3 注意力基本模型Fig.3 Attention model
其公式如式(21)所示:
(21)
其中,Q∈n×dk,K∈m×dk,V∈m×dv,当Q(Query)、K(Key)、V(Value)三个矩阵均来自于同一输入,即Q=K=V时,则模型变为自注意力机制.
3 ON-LSTM-SA模型
本文在以上理论基础上提出了基于ON-LSTM和自注意力模型的方面情感分析模型(Ordered Neurons Long Short-Term Memory-based and Self-Attention Mechanism-based Aspect Sentiment Analysis Model,ON-LSTM-SA),模型主要按照以下三个方面进行构建:
1)对于预训练的词向量部分,通过引入ELMo模型获得语义信息,提高训练效果;
2)针对target-dependent情感任务,模型加入target vector与context vector进行拼接,并作为输入端信息;
3)将数据集送入ON-LSTM-SA模型中,通过分层结构获取神经元的有序信息,获得方面情感.
4)在输出端通过Self-Attention机制学习句子内部的词依赖关系,捕获句子的内部结构.
ON-LSTM-SA模型结构如图4所示.

图4 ON-LSTM-SA模型结构图Fig.4 Model structure of ON-LSTM-SA
3.1 预训练
本文在原始语料库上通过GloVe分词得到初始词向量,然后将词向量送入ELMo模型中进行预训练.与其他预训练模型不同,ELMo模型使用所有层输出值的线性组合作为word embedding值.对于某一个单词序列,一个L层的BiLM需要由2L+1个向量表示,其计算公式如式(22):
(22)

ELMo模型将多层LSTM的输出Rk整合为一个向量,低层的Bi-LSTM负责捕捉语料中的句法信息,高层Bi-LSTM负责捕捉语料中的语义信息,并将向量正则化后输入到softmax层,作为学到的一组权重.其计算过程如式(23)所示:
(23)
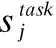
在此基础上,将ELMo词向量与初始词向量通过残差连接(residual connection)架构衔接起来,形成具有上下文语义的词向量,其计算过程如式(24)所示:
(24)
3.2 输入层
针对方面情感分析任务,模型在输入层的预训练词向量基础上添加了target vector,具体做法是将预训练好的词向量wk和target words拼接起来做word embedding,然后将向量求平均值,得到vtarget,最后将vtarget和vcontext拼接起来作为输入层.其计算过程如式(25)-式(26)所示:
vtarget=avg(embedding([wk,wtarget]))
(25)
input=[vtarget,vcontext]
(26)
3.3 隐藏层
一个自然句子通常可以通过树状结构表示成一些层级结构,这些抽象出来的结构就是语法信息,而LSTM以及普通的神经网络中的神经元通常是无序的,无法获取有序信息.ON-LSTM则试图通过建立层级关系来获取这种信息,层级越低代表语言中颗粒度较小的结构,对应的编码区间则越小,传输距离也越短,更容易被遗忘门过滤掉;层级越高代表语言中颗粒度较大的结构,对应的编码区间越大,意味着层级信息在对应的编码区间内保留时间更久.其原理示意图如图5所示.

图5 ON-LSTM原理示意图Fig.5 Schematic diagram of ON-LSTM
其中,图5(a)展示了ON-LSTM的一系列tokenS=(x1,x2,x3)对应的解析树形式.图5(b)将图5(a)的解析树转换为层级结构,可以发现S和VP节点都跨越了一个以上的时间长度.图5(c)将图5(b)的层级结构进行矩阵化,最终形成ON-LSTM隐藏层神经元的细胞状态.其中,在每个时间步骤中,给定一系列输入字符,神经元首先将其完全更新,而由于三组神经元更新频率不同,最上层的组更新频率较低,最下层的组则频繁更新.图5中(c)以颜色深浅表示更新频率,颜色程度越深代表更新频率更快,而颜色越浅代表信息更新越慢,以此划分出层级结构.
在隐藏层中,本文根据target words的前后上下文建模,给定输入序列{xt},在每次更新ct之前,首先预测历史信息ht-1的层级df:
df=F1(xt,ht-1)
(27)

pf=softmax(Wfxt+Ufht-1+bf)
(28)
得到历史信息的层级计算公式:
(29)
其中,pf(k)表示指向向量pf的第k个元素.这样,我们就能使用序列
(30)
来表示输入序列的层级变化.有了这个层级序列后,按照贪心算法输出对应的层级序列{df,t},找出层级序列中最大值所在的下标,然后将输入序列分区为[xt
输入:苹果的颜色是什么
输出:
{
{
{
苹果
的
},
{
颜色
是
}
},
{
什么
}
}
模型使用两个ON-LSTM模型从左往右和从右往左分别训练模型,期间前一个神经元的有序信息传递给下一个神经元进行分层处理,直至目标词,最后输出隐藏层词向量.
在Self-Attention层中,分别将左右两个hidden vector利用公式做Self-Attention计算来学习文本内部的词依赖关系.最后,将左Self-Attention和右Self-Attention拼接传入softmax层转换为概率输出,具体见式(31)-式(34):
hi=ON-LSTML([vi,vtarget]),i=1,2,…,r-1
(31)
hj=ON- LSTMR([vj,vtarget]),j=l+1,…,n
(32)
(33)
(34)
其中,l表示方面情感的类别数.
4 实验与分析
4.1 实验环境
本文采用流行的深度学习框架Keras完成实验,采用GPU加速,分词工具采用GloVe,实验环境配置具体如表1所示.

表1 实验环境配置Table 1 Experimental environment configuration
4.2 实验数据集和评价指标
本文采用SemEval2014 Task 4、SemEval2017 Task4数据集进行实验,该数据集主要用于细粒度情感分析,分为训练集和测试集,其中包含laptop、restaurant和twitter三个不同领域的用户评论数据,每一条评论包括评论内容、方面项和对应的方面情感极性,数据样本的情感极性分为Positive、Negative和Neural.本文利用NLTK工具库将数据集中的训练集按照9:1比例切分成训练集和验证集,该数据集的主要数据统计信息如表2所示.
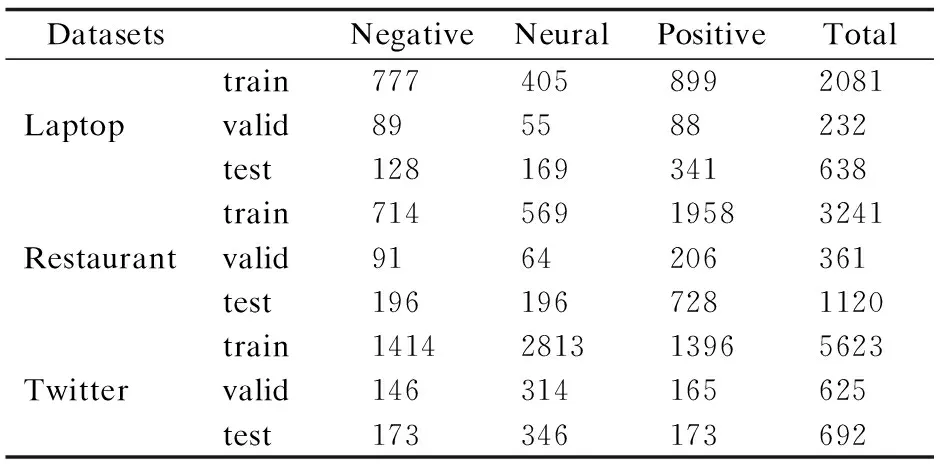
表2 实验使用数据统计Table 2 Experimental data statistics
本文采用准确率(Accuracy)和F1值作为方面情感分析的评价标准,具体计算公式分别见式(35)和式(36).
(35)
(36)
其中,T表示预测正确的样本数,N为样本总数,准确率通常使用百分比表示;F1值计算公式中recall代表召回率,precision代表正确率.
4.3 参数设置与训练
本文首先使用Glove分词工具对数据集中的文本进行分词,然后使用Word2Vec工具将分词后的文本转换为词向量,从而进行无监督的词向量学习.实验结合Keras和TensorFlow框架,参数设置方面,将词向量维度大小设置为300维,全连接层大小为128维,ON-LSTM输入维度300维,树结构层级为5层.
模型训练方面,实验采用随机梯度下降方法,通过设置批量样本大小为64进行模型训练,并采用Adam优化算法,初始化学习率为0.001,为防止过拟合加入了Dropout机制,Dropout参数设置为0.2.详细参数设置如表3所示.
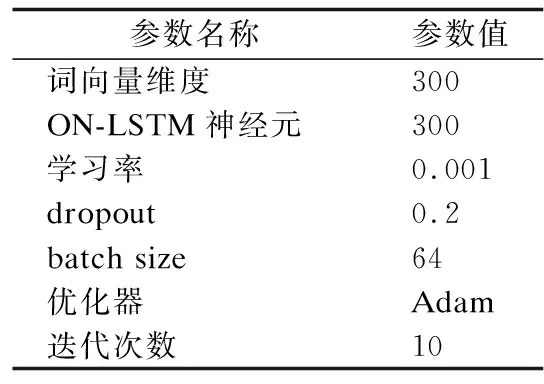
表3 模型参数设置Table 3 Model parameter settings
4.4 对比实验与结果分析
将本文提出的ON-LSTM-SA模型与以下模型进行对比实验:
1)LSTM:采用标准LSTM神经网络进行方面情感分析.
2)TD-LSTM:采用两个LSTM,围绕target word进行上下文建模,使得左右两个方向的上下文都可以用作情感分类的特征表示.
3)TC-LSTM:在TD-LSTM模型的基础上增加了target vector,并跟输入词向量拼接以后作为输入向量,整合了target word与context word的相互关联信息.
4)AE-LSTM:主要是将LSTM隐藏层与aspect embedding层结合起来,区分出对特定aspect更重要的上下文信息.
5)ATAE-LSTM:在AE-LSTM的基础上,将情感嵌入(aspect embedding)和词嵌入(word embedding)进行拼接,共同组成模型的输入端,更充分利用了方面信息.
所有模型都采用相同数据集进行实验,并尽量参考原论文中的超参数,以达到模型理论准确率.实验结果如表4所示.

表4 模型准确率(Acc)对比Table 4 Comparison of model accuracy

表5 模型F1值(Macro-F1)对比Table 5 Comparison of the Marcro-F1 score ofmodel
从表4、表5中可以看出,相较于标准LSTM神经网络模型,其他5种模型都在一定程度上提高了方面情感分析的准确率和F1值.TD-LSTM和TC-LSTM都考虑了target word在上下文中的影响,对比LSTM效果提高了2%~3%,说明target word对方面情感分析输入方面具有提升作用.AE-LSTM、ATAE-LSTM在LSTM的隐藏层拼接了aspect embedding和word embedding,并通过增加Attention机制提高模型效果,同样也取得不错了效果.
在本文提出的模型中,ON-LSTM-SA模型在restaurant和twitter两个数据集上的实验效果明显比其他模型更好,准确率相较于标准LSTM分别提高了5.9%和6.5%,相较于TD-LSTM分别提高了2.9%和3.4%,F1值方面相较于标准LSMT分别提高了7.1%和6.8%,相较于TD-LSTM分别提高了4.7%和3.1%.
综上所述,本文提出的模型通过实验证明,对输入动态生成、添加层级结构、使用Self-Attention机制对方面情感分析具有提升作用.
5 结束语
传统的LSTM神经网络能够有效处理序列问题,而层级结构使得神经元能够获取有序信息.同时,Attention机制能使得模型获得对aspect word的权重大小,从而更好判断方面情感极性.在此基础上,本文提出了一种基于ON-LSTM和自注意力机制的ON-LSTM-SA模型,该模型在输入端融入了对词向量动态预训练的ELMo模型,同时在输入层整合了target word和context word,使得输入具有一定语义信息,然后在隐藏层中利用ON-LSTM的层级结构,使得神经元携带有序信息,根据词语粒度在区间上跨度的大小从两个方向获得情感关键词,再将信息传递给Self-Attention做进一步方面情感极性判断,最终生成对句子的方面情感分析.通过实验证实,本文提出的模型在多个数据集中效果优秀,具有一定的应用价值.
虽然ON-LSTM-SA模型在方面情感数据集上实验取得了较好的效果,但由于模型内部分层结构,以及前期需要通过ELMo动态预训练,因此训练时长比一般模型较长.下一步的工作将通过与更先进的预训练模型例如BERT、XLNet等进行结合,降低预训练时长,并进一步提升语义信息切分.
