基于深度BLSTM和分类元数据的自定义情感分类
2020-09-02杨春霞李欣栩秦家鹏
杨春霞,李欣栩,瞿 涛,秦家鹏
1(南京信息工程大学 自动化学院,南京210044)2(江苏省大数据分析技术重点实验室,南京210044)3(江苏省大气环境与装备技术协同创新中心,南京210044)
E-mail:y.cx@163.com;nuistlxx@163.com
1 引 言
文本情感分析通常是利用人们生成的文本对观点或情感进行分析,在自然语言处理和数据挖掘方面具有很重要的影响[1].近年来,随着如亚马逊、Yelp和IMDB等网站评论呈爆发式增长,情感分析受到各领域学者越来越多的关注.
文档级情感分类旨在预测文本的整体情感极性(如划分成1-5或者1-10类)[1],其关键在于提取文本特征,现如今虽然一些学者使用神经网络在自动学习文本特征方面取得了较好效果[2-5],但是如何挖掘文本更深层的特征和语义关联特征一直是研究的热点问题.另一方面,现有的网络大多数只考虑局部文本信息,忽略了用户信息和产品信息等分类元数据.Tang[6]等人将用户信息和产品信息融入到词嵌入层和池化层中,提高了分类效果,初步说明融合分类元数据对挖掘文本相关特征和语义关联有所帮助.但是在建模过程中融合分类元数据工作还有待加强.
本文的主要贡献如下:
1) 本文结合DBLSTM和self-attention网络层来捕捉文本深层特征和语义关系.输入的时序数据在DBLSTM的每一层进行训练,最后一层输出值通过self-attention进一步来提取重要特征和语义关系.
2) 考虑到分类元数据对分类结果的影响,本文结合分类元数据构建自定义分类器,该分类器通过上下文感知注意力为分类元数据配制特定的参数,与原始参数一起对提取到的文本特征进行处理和分类.
3) 本文在三个常见的数据集上进行实验,并与当前主流工作进行对比,实验结果表明本文提出的模型性能优于相关模型,本文提出的深度模型结合自注意力机制的特征提取方案能有效地提取文本特征,本文构建的分类器能进一步提高分类精度.
2 相关工作
传统的机器学习方法需要对文本进行大规模的数据预处理和特征工程,这通常耗费大量资源.深度学习模型因为能有效缓解对人工规则和特征工程的依赖而逐渐成为情感分类的主流.
Bengio等[7]首次将神经网络用于训练语言模型,将词在同一个向量空间上表示出来,该语言模型与one-hot相比维数大大减小,但存在参数较多、训练时间过长的问题.Mikolov等[8]和Pennington等[9]分别提出了word2vec和Glove词分布表示方法,均能缩短训练时间,同时也能进一步减少词向量维度.
RNN模型虽然能比较连贯的表示数据上下文,但是其存在梯度消失和梯度爆炸的问题,Hochreiter等[10]提出LSTM模型,该模型不仅可以弥补RNN的不足,还能提取长距离关联的语义特征.Cho等[11]提出的GRU模型比LSTM结构更简单,在某些问题上可以减少时间成本.然而LSTM和GRU模型只能处理单向信息流动而无法反映上下文语义关联.BLSTM/BGRU在LSTM/GRU基础上增加反向的LSTM/GRU,拼接两个方向上LSTM/GRU的结果从而获得上下文语义信息.曾蒸等[13]用DBLSTM来进行情感分类,通过实验验证DBLSTM能更有效的捕捉深层特征和语义关联,受其启发,本文尝试搭建基础的DBLSTM并结合其他特征提取层来进一步提高DBLSTM的效果.
注意力机制(Attention mechanism)最先用于图像处理领域,主要是模拟人眼性能来关注图片或者视频中的重要区域,Attention在NLP方面的应用被看作是一种信息加权,通过分析每一时刻输出信息的重要程度来对输出信息进行加权,这可以有效提高模型的学习效率,目前注意力机制常与神经网络联合建模来提高情感分类精度,Yang等[12]将注意力机制和神经网络结合来进行文本分类并取得了较好的实验效果.石磊等[14]将Tree-LSTM和attention-Tree-LSTM两种情感分类模型进行对比,结果表明引入注意力机制能有效的提高模型精度.韩虎等[15]分别在句子级别和篇章级别引入用户信息和产品信息等分类元数据,并通过注意力机制来计算不同文本特征的重要性,实验证明融入分类元数据的模型效果要优于不含分类元数据的模型,然而现存的模型主要关注分类元数据对编码层的影响,很少关注对分类层的影响.基于此,本文采用DBLSTM结合self-attention的结构来提取深层特征和语义关联并利用分类元数据自定义分类器来分类.
3 模型实现
本文遵循网络结构设计通用原则,通过目前开源的深度学习框架搭建序贯模型(sequential),DB-A-CC模型整体上呈编码——解码结构,如图1所示,主要包括4部分:

图1 基于DB-A-CC的情感分类模型Fig.1 Sentiment classification model based on DB-A-CC
1)词向量:将本文用到的Yelp2013、Yelp2014、IMDB等三个公开数据集进行文本预处理,将文本通过词嵌入转换成DBLSTM可以直接识别处理的词向量矩阵.
2)编码输出:将词向量通过DBLSTM进行处理,该网络有多个隐层,后一层的输入是前一层的输出,最终获得每个时间步长上的隐层状态和句子的整体表示.
3)注意力层特征筛选:文本中的单词对文本的贡献度不同,通过self-attention机制既可以提取重要特征,也起到挖掘文本更深层信息和语义关联的作用,最终得到文本级注意力机制矩阵.
4)自定义分类器模块:本文结合分类元数据自定义分类器,目的是在考虑分类元数据特征的影响下将提取到的文本特征进行处理并输出文本在各个类别下的概率.
3.1 任务定义
本文的情感分类任务是结合分类元数据来对输入句子的情感极性作判断.Tang等[6]提出用户情感持续性和产品情感持续性理论:相同的用户在面对不同的产品时总倾向于给出相似的评级;质量好的产品大概率会比质量差的产品获得相对高的评级.所以在建模时考量分类元信息是很有必要的.我们将文本集定义为T,将全部用户信息定义为U,全部产品信息定义为P,全部评论信息定义为D.每个文本t(t∈T)中仅含一个用户和一个产品,具体关系描述为:在文t(t∈T)本中用户u(u∈U)针对产品p(p∈P)发表了评论d(d∈D).
3.2 词向量
本文中t(t∈T)采用{u,p,d}的结构,将u(u∈U)和p(p∈P)按照均匀分布随机初始化为词向量u*和p*.将评论d并按照符号分割成n个单词,其中d={w1,w2,w3,…,wn},通过预训练的Glove[9]将单词转化为词向量,若D中单词词频小于5则将该单词设置为UNK对应的词向量.将d(d∈D)中单词数用零补成D中最长文本单词数l(n≤l),最后d(d∈D)表示成l×m的词向量矩阵d*,其中m是词向量的维数,如公式(1)所示,最后将t(t∈T)表示为{u*,p*,d*}.
(1)
3.3 编码输出
LSTM只能从前向后处理文本信息,这虽然合乎人们的阅读习惯,但一个词不但与它之后的文本存在联系,与其前面文本也有关联,BLSTM从文本的两端来处理文本信息,最后合并结果得到所需的文本特征,这更符合文本的语义结构.本文采用DBLSTM模型来进一步挖掘文本更深层特征和语义关联.
LSTM每个单元如公式(2)-公式(7)所示:
ft=σ(Wf·[htt-1,wt]+bf)
(2)
it=σ(Wi·[htt-1,wt]+bi)
(3)
(4)
(5)
ot=σ(Wo·[htt-1,wt]+bo)
(6)
htt=ot*tanh(ct)
(7)
式中ft,it,ot分别对应遗忘门,输入门以及输出门,wt是t时刻输入的单词向量,ct是t时刻单元的状态,htt表示t时刻LSTM的输出,htt-1是t-1时刻LSTM的输出.
BLSTM每个单元如公式(8)-公式(10)所示:
(8)
(9)
(10)
DBLSTM每个单元如公式(11)-公式(13)所示:
(11)
(12)
(13)
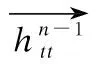
3.4 注意力层特征筛选
本文通过self-attention来捕捉对最终情感分类影响最大的文本特征.如公式(14)-公式(16)所示:
(14)
(15)
(16)
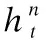
3.5 自定义分类器模块
该模块是网络的最后一层,主要任务是将文本向量映射到一个C类向量空间中,考量到文本向量与分类元数据的关联,在传统的逻辑回归分类器的基础上为文中每类分类元数据(即用户信息和产品信息)配置特定的权重和偏差,具体分类器模块如公式(17)和公式(18)所示:
(17)
y=softmax(y′)
(18)
传统的逻辑回归分类器用文本权重Wd和偏差bd来对文本特征d1进行处理,考虑到分类元数据对分类结果的影响,本文在此基础上添加分类元数据权重W*(包括用户权重Wu和产品权重Wp)和分类元数据偏差b*(包括用户偏差bu和产品偏差bp)来共同对d1进行处理.处理结果y′通过softmax层进行概率化得到最终分类结果y.W*和b*是由上下文感知注意力将分类元数据中与文本向量关联度高的部分通过加权的形式计算得出,以W*为例,具体如公式(19)-公式(21)所示:
(19)
(20)
(21)
其中q是全部用户向量u*(u*∈U)和全部产品向量p*(p*∈P)的连接向量(本文遵循先用户向量后产品向量的连接方式),结构为q=[U;P];h是权重向量,经随机初始化后在训练过程中随评论文本的输入进行调整,包含与评论文本相关的信息,又称它为上下文向量.由上下文感知注意力计算h和zi的相似度得到权重ai,B={b1,b2,…,bd}是在训练过程中可以调整的基向量.最终将W*表示成全部基向量B的加权和的形式.
3.6 模型训练
模型训练的目标就是通过不断减小损失函数来调优模型参数,本文采用最小交叉熵损失函数,损失函数如公式(22)所示,其中N是总文本数,C是分类类别数,pj为实际类别,yj为预测类别,λ‖Θ‖2为正则化项.
(22)
4 实 验
4.1 实验数据与实验平台
本文实验基于Facebook的Pytorch深度学习框架,它计算图是动态的,用户可以实时调整计算图,同时Pytorch中集成了多种神经网络模型,这些模型中的参数是自动求导的,可以轻松实现反向传播.本文将相关实验配置列于表1所示.

表1 实验平台设置Table 1 Experimental platform settings
本文选用Tang等[6]在2015年公开的三个数据集,其中Yelp2013和Yelp2014是点评网站数据集中2013年和2014年的餐厅数据,IMDB是电影网的影评数据集.其中评分越高则情感越趋于积极,反之情感则趋于消极.数据集中训练集、验证集、测试集比例为8:1:1,其他信息列于表2.

表2 Yelp2013、Yelp2014和IMDB数据集信息Table 2 Yelp2013、Yelp2014 and IMDB dataset information
4.2 实验参数与评价指标
表3是实验相关参数的说明,本文将DBLSTM每层单元数设置为256,词向量维数设置成300,分类元数据维数设置成64,训练过程采用Adam来更新参数,为防止过拟合,在训练过程中使用Dropout和Early stopping正则化方法.为了防止梯度爆炸,使用梯度裁剪(gradient clipping)来控制训练进程.

表3 实验参数设置Table 3 Experimental parameter settings
为了验证模型的有效性,实验中采用精确率(Accuracy)和均方误差(RMSE)作为衡量指标.Accuracy是对模型正确分类能力的评估,准确度越高效果越好.如公式(23)所示,其中N是样本集总文本数,T是全部预测正确的文本数.RMSE是对真实值和预测值之间差异的衡量指标,其值越小效果越好.如公式(24)所示,N是样本集总文本数,gdi是实际情感极性,pri是预测情感极性.
(23)
(24)
4.3 基线模型
1)Majority:统计训练集的情感类别,将其中概率最大的情感类别视作测试集的情感类别.
2)SSWE[16]:用特别训练的词向量作为输入特征,用SVM分类器进行分类.
3)Trigram:使用unigrams和trigrams作为特征,SVM作为分类器进行训练.
4)PV[17]:将PVDM算法应用于情感分类中.
5)UPNN[6]:利用CNN来对词向量进行进一步的特征提取,在词嵌入层和池化层加入用户信息和产品信息作为特征来进行文本情感分类.
6)NSC+UPA[18]:利用分层LSTM提取文本特征,在每层LSTM中间加入注意力机制计算文本特征与用户信息和产品信息的相关度,最后进行分类.
7)DUPMN[19]:由双层LSTM对文本进行处理,由双记忆网络对用户信息和产品信息分别进行处理,最后结合处理后得到的用户信息和产品信息进行分类.
4.4 实验结果与分析
为了验证本文模型的效果,本节首先列出本文模型与基线模型的对比结果,其次对本文模型部分替换来进行对比.
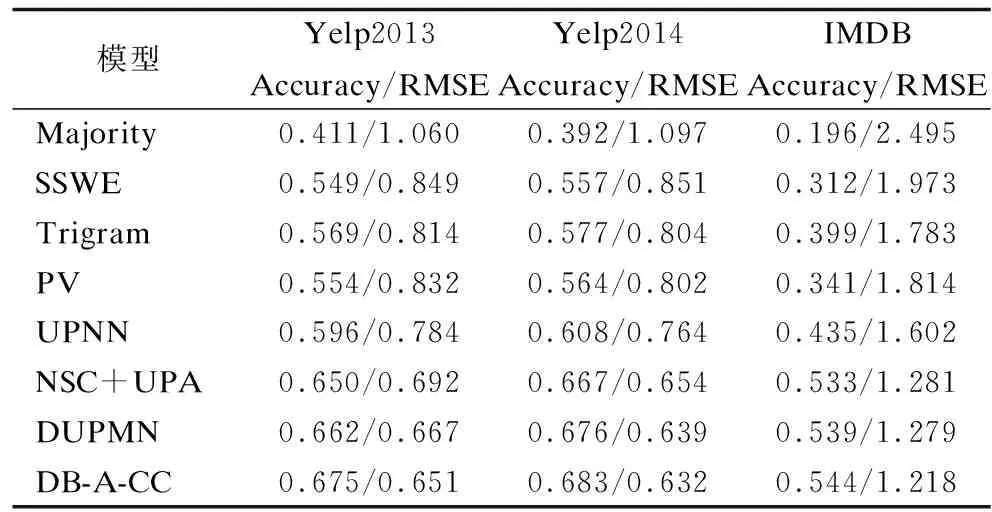
表4 不同模型的分类结果Table 4 Classification results of different models
由表4可以看出,大部分模型在Yelp2014上效果相对较好,Yelp2013次之,IMDB最差.这是因为Yelp2014和Yelp2013是五分类且Yelp2014数据量略多于Yelp2013,IMDB最小且为十分类.这符合分类规律,数据量越多则相对包含更多的文本特征,分类类别数越少越容易正确分类.在所有的对比模型中,Majority效果最差,因为这种方法基本不含文本特征,这也说明文本特征提取对情感分类有很大的影响.融合分类元数据的模型(UPNN、NSC+UPA、DUPMN)效果普遍优于传统的分类方法(Majority、PV、Trigam、SSWE),由此可以看出分类元数据对情感分类具有正面影响.本文的模型在三个数据集上都表现出比基线模型更好的效果,这说明本文的DB-A-CC模型中的DBLSTM结合self-attention的特征提取结构和融入分类元数据的自定义分类器结构有一定的可行性.
为了进一步说明本文的特征提取结构和自定义分类器模块的效果,以Yelp2014数据集为例,表5将DBLSTM分别替换成目前比较先进的GRU、LSTM、BLSTM等,并列出有无self-attention层时的模型效果,表6替换分类器模块来进行对比.

表5 不同编码网络的分类结果Table 5 Classification results of different coding networks
由表5每一列来看,(B)LSTM的性能略优于(B)GRU,这是因为(B)LSTM比(B)GRU多一个门结构,所以能关注更多的文本特征.双向网络结构效果要优于单向网络,因为双向网络能提取两个方向上的信息.而本文采用的DBLSTM要比单向网络高约2个百分点,比双向网络高约1个百分点,这初步验证了深度网络对特征和语义关系更强大的捕捉能力.

表6 不同分类器模块的分类结果Table 6 Classification results of different classifier modules
从每一行来看,包含self-attention层的模型要比不含self-attention层的模型准确度高约9个百分点,这说明self-attention层能令模型能获得更好的效果.由表6可以看出,不含任何分类元信息的DB-A模型效果最差,只在权重包含分类元信息的DB-A-W模型和只在偏差包含分类元信息的DB-A-B模型效果比DB-A模型准确度高约5个百分点,本文提出的在权重项及偏差项均融入分类元信息的分类器模块DB-A-CC比DB-A模型的准确度高约9个百分点,比DB-A-W和DB-A-B模型准确度高约4个百分点.这说明分类元数据对分析情感有一定作用,本文自定义的分类器模块对提高分类效果有一定的帮助.
5 结束语
为了进一步挖掘文本更深层特征和语义关联,本文提出了DB-A-CC模型,首先将词向量输入到DBLSTM网络中来挖掘其深层特征,然后由注意力层进一步对重要特征进行筛选,最后将文本特征通过自定义分类器来分类.本文没有将分类元数据直接作为特征与文本向量进行拼接,而是利用上下文感知注意力机制将分类元数据融入到分类器模块的参数中.通过相关实验验证,本文的模型与主流模型相比效果有所提高;本文引入的DBLSTM结合self-attention的网络和分类器模块均能够有效提高模型精度.下一步将继续探讨分类元数据对建模的影响和情感分类模型的应用场景.
