结合注意力机制与双向切片GRU的情感分类模型
2020-09-02高波涌陈莲娜
陈 虎,高波涌,陈莲娜,余 翠
(中国计量大学 信息工程学院 浙江省电磁波信息技术与计量检测重点实验室,杭州 310018)
E-mail:gaoby@cjlu.edu.cn
1 引 言
情感分析又称为意见挖掘,从书面语言分析人们的观点、情感、评价、态度,它是自然语言处理中最活跃的研究领域之一[1].在这个互联网和社交媒体快速发展的时代,通过在线大量数据的收集、跟踪得到公众意见的信息,这些信息数据可用于商业,经济甚至政治目的,这使得情绪分析成为极其重要的反馈机制.随着过去几年深度学习的日益普及、计算机硬件设备的不断完善,再加上标记数据的日益增大,深度学习[2]模型已经取代了许多解决各种自然语言处理和计算机视觉任务的经典技术.基于深度学习的模型已经能够在若干任务中实现最先进的性能,包括情绪分析,问题回答,机器翻译,单词嵌入和命名实体识别,以及图像计算机视觉中的分类,物体检测,图像分割,图像生成和无监督特征学习[3-6].
在自然语言处理领域,深度学习方法能够在一定程度上自动捕获文本中的语法和语义特征,而不再需要特征工程.由于CNN擅长捕获空间局部特征及其结构模型的可并行性而被广泛应用于图像处理领域,一些学者将其引入自然语言处理任务,在特定数据上取得了良好的效果,但CNN不能够充分捕获文本序列时序信息,从而无法充分学习文本上下文信息.RNN适合处理序列数据,但是标准的RNN结构无法摆脱时间步骤上的依赖关系,造成训练时间过长,Yu等人[7]创新性地改进RNN网络层次结构,提出切片循环神经网络(SRNN),使得RNN能够实现并行计算.它将输入序列进行多次切片处理,形成多个长度相等的最小子序列.因此,循环单元可以在每个层上同时处理每个子序列,实现并行计算,然后通过多层网络进行信息传递.由于RNN存在梯度消失和梯度爆炸的问题[8,9],在具体任务中,SRNN大多采用标准循环神经网络的变体如LSTM,GRU等作为循环单元.但是SRNN切片操作无法避免在网络的低层造成长期依赖性的损失,同时其单向结构无法充分利用上下文的语义信息,限制了模型准确性.
针对以上网络模型设计存在的问题,在本文研究中,我们利用GRU作为简化RNN的改进版本,提出一种Bi-SGRU-Attention模型网络,将文本切片为多个子序列,在每个子序列上独立进行双向RNN特征提取,增强语义提取深度,实现了训练的并行,减少了训练时间.并通过在每个子序列上加入注意力层,突出文本的关键信息和文本序列关键信息,用以弥补切片导致的低层网络依赖性的损失.Bi-SGRU-Attention模型在公开数据集IMDB上进行实验,与一些经典模型和同类型模型进行比较,本文模型在准确率、损失、F1值和训练时间上取得了较好的效果,在中文酒店评论数据集上也验证了模型的通用性.证明了Bi-SGRU-Attention模型在文本情感分类上的有效性.
2 相关研究
从2014年开始,注意力机制在机器翻译任务中取得优越表现,随后被广泛运用到其他NLP任务中,并在文本分类任务中成为近年来的研究热点.Yang等人[10]提出分层注意网络(HAN)用于文档分类任务,模型在词语和句子级别上应用了两个级别的注意力机制,使得模型能够在构建文档表示时差别对待不同文本信息.王伟等人[11]提出BiGRU-Attention网络模型进行文本情感分类,通过双向GRU对输入文本进行隐含表示,利用Attention机制提取出关键特征.郭宝震等人[12],采用不同的算法得到两种词向量,并将它们输入双路卷积神经网络,并结合注意力机制计算词语权重分布,最终将两种特征进行融合,得到了更加丰富的文本信息,以提高句子分类的准确率.关鹏飞等人[13]通过对输入词向量直接进行Attention权重分布,以学习到增强分类效果的信息,同时使用双向LSTM对输入的词向量进行特征学习,将语义特征与重点词特征融合,进行情感极性分析.Wang等人[14]提出了一种基于注意机制的长短期记忆网络,用于方面级别的情感分类.
近年来,Bert语言模型[15]的提出,刷新了多项自然语言处理领域任务记录,但是由于Bert语言模型的庞大性,可复现性较差,许多学者大多使用预训练好的Bert模型进行微调用于下游任务中,然而预训练模型对输入长度的又有一定的限制,大量的模型参数也无法避免微调过程时间过长.Yu等人[7]提出了切片循环神经网络,突破RNN时间依赖性的瓶颈,并通过多层网络进行信息传递,在长文本情感分析中取得最高效的解决方案.针对该模型切片导致低层网络的长期依赖性损失,Li等人[16]提出了一种断点信息丰富机制,在不影响并行化的前提下增强子序列间的长期依赖关系用于情感分析中.
本文算法模型在以往的研究成果的基础上,主要贡献如下:
1)基于单向SRNN网络结构与传统双向RNN改进了双向GRU传统的连接结构,实现双向GRU网络结构的并行计算,提高双向GRU网络在做文本情感分类任务中的训练速度.
2)基于改进后形成的Bi-SGRU网络结构,针对切片导致的低层网络长期依赖性的损失,结合注意力机制实现特有的句子序列级别的局部特征关注,并在网络层的传递过程中弥补上述损失,这使得网络能够更深层次的理解句子文本,提高文本特征提取的效果,实现分类精度的提升.
3)通过可视化注意力层权重进一步验证注意力层对弥补低层网络长期依赖性损失的有效性.
3 相关技术介绍
3.1 标准RNN连接结构
循环神经网络(RNN)被广泛应用于NLP任务,一个标准的RNN由输入层、隐藏层、输出层三部分构成.将一个多输入、单输出的循环神经网络按照时间线展开,其连接结构如图1所示.
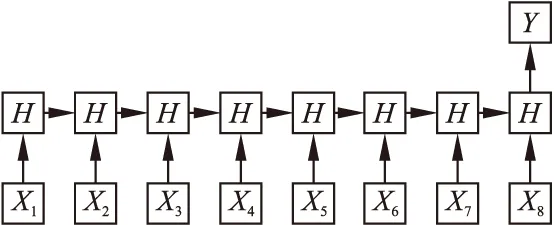
图1 标准RNN连接结构Fig.1 Standard RNN connection structure
假设输入长度为8,那么序列(x1,x2,…,x8)输入RNN模型,当前步骤等待前一步骤计算完成,每一步骤的计算由循环单元H完成,并使用最后一个隐藏状态Y表示整个序列.
3.2 切片循环神经网络(SRNN)结构
由于传统RNN的连接方式在计算当前隐藏状态时需要使用上一时刻隐藏状态,因此造成RNN不可并行性,当输入序列过长,计算时间也随之延长.
Yu等人[7]通过改进RNN网络层次结构使RNN能够实现并行计算,提出了切片循环神经网络,它将输入序列进行多次切片处理,形成多个长度相等的最小子序列.因此,循环单元可以在每个层上同时处理每个子序列,实现并行计算,然后通过多层网络进行信息传递.同时,Yu等人也经过推理计算,认为标准RNN是SRNN的一种特殊情况,SRNN能够比标准RNN获取到更多的信息,SRNN结构如图2所示.
SRNN通过将输入序列划分成多个长度相等的最小子序列,循环单元可以在每一层同时处理每个子序列,信息通过层与层之间进行传递.设输入的序列X长度为T,输入序列可以表示为:
X=[x1,x2,…,xT]
(1)
其中xi为i时刻的输入,它可以有多个维度,例如′Word Embeddings′.将X分割为n个等长的子序列,那么每个子序列N的长度t为:
(2)
n为切片的个数,那么X可以表示为:
X=[N1,N2,…,Nn]
(3)
每个子序列可以表示为:
Nm=[x(m-1)*t+1,x(m-1)*t+2,…,xm*t]
(4)
同样的,对于每个子序列N,又可以被切片为n个子序列,重复切片操作k次直到达到最底层的最小子序列长度(如图2所示的第0层),通过k次切片操作,共可以得到k+1层

图2 SRNN结构Fig.2 SRNN structure
网络结构,同时第0层的最小子序列长度l0和第0层的最小子序列个数p0分别为:
(5)
p0=nk
(6)
由于在第m层(m>0)的每个父序列被切片为n块,因此第m层的子序列个数pm和第m层子序列长度lm分别为:
pm=nk-m
(7)
lm=n
(8)
如图2所示,输入序列长度T为8,进行k为2次切片操作,每一层切片数n=2,经过两次切片操作后,在第0层得到4个最小子序列,每个最小子序列长度为2.
3.3 注意力机制(Attention Mechanism)
对于判定一条语句的情感倾向时,我们知道并非所有词汇对句子含义的表示都有同等作用.同时,对于切片操作造成低层网络的长期依赖性损失,通过注意力机制对每个序列的靠前段部分以及靠后段部分予以更大的权重,当信息传递到下一层时,能够在一定程度上弥补低层网络长期依赖性损失.同时,引入注意机制能够提取对句子含义重要的词,并汇总这些信息词的表示用以表示句子向量.本文采用Yang等人[10]使用的单词级别的注意力权重计算方式,具体实现步骤:
uij=tanh(Wwhij+bw)
(9)
(10)
(11)
其中,i表示第i个最小子序列,j表示最小子序列i的第j个词汇,hij表示输入,uij表示hij在词注意力层的隐含表示;uw表示一个初始化用以表示上下文的向量,αij表示第i最小子序列中第j个词汇的权重,si表示每一个子序列的新的表示.
4 Bi-SGRU-Attention情感分类模型
在当前情感分类研究中,采用传统双向RNN与注意力机制结合使用能够取得良好的效果,为了提高双向RNN网络模型的训练速度,并加强局部关注度,我们提出可并行的双向切片GRU与注意力机制结合,构建Bi-SGRU-Attention情感分类模型,为了清晰展示模型思想,我们还是使用输入长度为8,最小子序列为2示例,模型结构如图3所示.
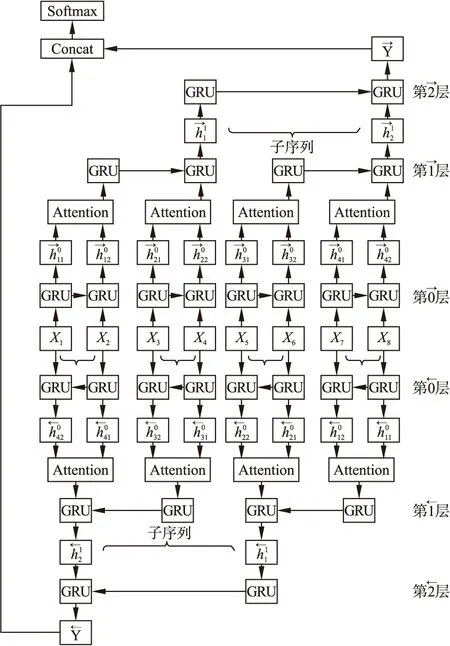
图3 Bi-SGRU-Attention情感分类模型(以输入长度为8,最小子序列为2示例)Fig.3 Bi-SGRU-Attention sentiment classification model
接下来详细介绍每一层的具体操作:
1)输入层
对如输入序列的构成,我们采用Word2Vec方法先对文本进行预训练生成词向量并通过查表的方式形成句子向量,具体操作如下:
首先我们将所有的文本语料Xi,i∈[1,Q],Q为总的文本语料数量,进行预处理包括去除特殊字符、分词.然后采用Word2Vec方法生成词向量xm,xm的维度为100,m∈[1,M],M为文本中所有不重复词汇个数.此处Word2Vec方法采用Skip-Gram模型实现.最后,用xij表示文本Xi的第j个词的词向量j∈[1,MaxLen],我们将每个句子的长度固定为MaxLen个词向量构成,则句向量Xi可以表示为:
Xi=xi1⊕xi2⊕…⊕xij
(12)

对于输入序列,我们在两个方向上分别进行处理:
(13)
(14)
i,j分别表示处理方向上的第i个最小子序列的第j个输入.
3)Attention层
该层主要是为每个序列单词分配权重,首先,对于每个最小子序列,根据上一层输出hij,输入单层感知机MLP以此获得hij的隐含表示uij,接着使用uij和一个初始化用以表示上下文的向量uw的相似度来衡量单词的重要性,并通过softmax函数得到一个归一化的重要性权重矩阵αij.最后,通过词向量加权求和的方式得到每个最小子序列新的的表示si,实现句子序列级别的局部关键特征关注.
对于Attention层输出序列(s1,s2,…,sp0),同样也在两个方向上进行处理:
(15)
(16)
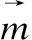
我们同样可以推算出第m层输出的隐含表示:
(17)
(18)
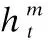
6)融合层和softmax层
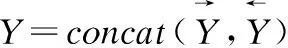
(19)
p=softmax(WYY+bY)
(20)
7)我们采用的损失函数为:
loss=-∑logpdj
(21)
其中,d表示每条文本语料,j表示标签.
5 实 验
5.1 实验数据集及实验环境
本实验所采用的数据是公开的IMDB影评数据集[17].数据集中训练集和测试集分别有25000条数据,训练集和测试集分别有2个类别,如表1所示.
本实验采用Python语言进行编程,使用Keras深度学习框架(以Tensorflow为底层),实验运行环境为Windows10、Anaconda软件,电脑硬件配置:I7处理器,8GB内存.
5.2 实验评估指标
实验采用的评估指标有准确率、损失、F1值和训练时间,准确率计算公式为:
(22)
其中,NT表示被正确分类的样本数目,NN表示样本总数.

表1 数据集Table 1 Dataset
损失值在每一随机批量训练过程中,按照损失公式,公式(21)计算得到,F1值兼顾模型查全率(Recall)与查准率(Precision),训练时间采用每次迭代过程平均所花费的时间.
5.3 模型参数
在本文的实验中,词嵌入维度设置为100,每个方向上隐藏层节点数设置为50.在这种情况下,Bi-SGRU为词汇提供了100个维度表示.Batch_size设置为32,采用优化器:Adam,共迭代10次.模型参数如表2所示.
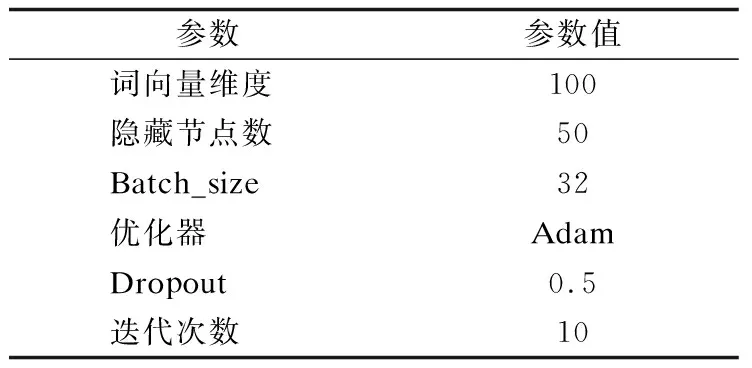
表2 实验模型参数Table 2 Experimental model parameters
5.4 实验过程
本文提出Bi-SGRU-Attention模型的具体实验步骤如下:
a)从Keras数据集中提取IMDB数据;
b)使用Word2Vec工具训练词向量;
c)将句子转换成索引表示,并固定长度;
d)每个索引对应一个词向量;
e)将词向量拼接成词矩阵,作为模型的嵌入层权重;
f)将训练文本测试文本分别进行切片处理作为Bi-SGRU-Attention模型的输入;
g)文本最小子序列索引表示输入嵌入层,再输入Bi-SGRU层,提取子序列文本层次特征;
h)将每个子序列经过Bi-SGRU提取到的特征输入到Attention层,分配相应的词向量权重;
i)经过多个网络层获取整个文本序列的特征表示;
j)采用测试集数据进行模型评估.
为了确定在IMDB数据集上SGRU(n,k)切片的最佳效果,我们采用四种切片方式进行实验:在MaxLen为125时1种切片方式:SGRU(5,2);在MaxLen为256时2种切片方式:SGRU(16,1)、SGRU(4,3);在MaxLen为512时一种切片方式:SGRU(8,2);实验结果如表3所示.
由表3我们可以发现当k为2,n为8时,即当输入序列长度为512,每次切片将序列切成8片,并进行2次切片操作时,效果较好.因此我们在进行双向操作并加入Attention机制进行实验的时候取k=2,n=8,MaxLen=512.
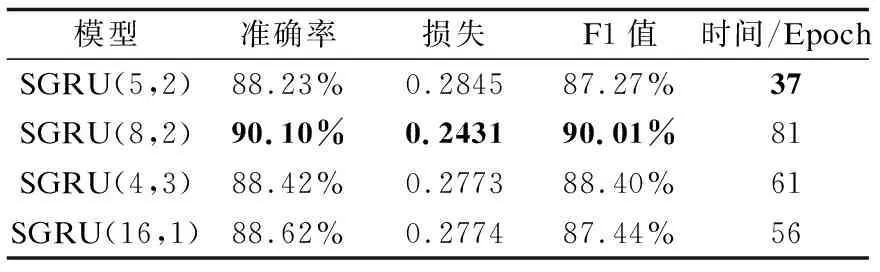
表3 SGRU不同切片实验结果Table 3 SGRU different slice experiment results
5.5 对比实验
将本文提出来的模型与以下7种模型进行比较.对比模型如下:
a)FastText模型.Joulin等人[18]提出的使用N元词袋模型引入词序信息,并将输入向量加权求平均整合为一,并通过softmax进行分类,实验采用1元词袋模型;
b)C-LSTM,Zhou等人[19]提出的用CNN对文本特征进行提取,将这些特征输入到LSTM中学习上下文依赖关系进行情感分析模型.本实验设置滤波器长度为5,池化长度为4;
c)S-BiLSTM模型,Lu等人[20]提出采用2层双向LSTM网络堆叠进行情感分析的模型;
d)BiLSTM-EMB-ATT模型.关鹏飞等人[13]提出直接在词向量上采用注意力机制计算每个词情感权重分布,并与BiLSTM学习的文本特征进行融合的模型;
e)BiGRU-Attention,王伟等人[11]提出使用双向GRU进行文本特征提取,并采用Attention机制计算单词情感权重分布,进行分类的模型;
f)BiLSTM-Attention,与上述BiGRU-Attention模型一样原理,只是采用了LSTM单元代替GRU;
g)Bi-SGRU模型,采用双向切片GRU;
h)SGRU-Attention模型,采用单向SGRU,并结合注意力机制的模型;
对比实验的具体实验步骤如下:
a)从Keras数据集中提取IMDB数据;
b)使用Word2Vec工具训练词向量;
c)将句子转换成索引表示,并固定长度;
d)每个索引对应一个词向量;
e)将词向量拼接成词矩阵,作为模型的嵌入层权重;
f)将训练文本测试文本输入到上述对比实验网络模型;
g)获取整个文本序列的特征表示;
h)采用测试集数据进行模型评估.
以上实验词向量维度均为100,输入维度为512.实验迭代次数均为10次,为了保证实验模型变量层的唯一性,保证实验可比性,除了模型的变量层功能不同,其他实验条件都相同.
5.6 实验结果以及实验分析
实验设置迭代次数设置为10次,各种模型在测试集上最高精度作为模型的准确率,及其对应的损失值作为模型损失,以及每次迭代所花费的时间如表4所示.
如表4所示,本文提出的模型在准确率、F1值与损失上取得了最优效果,与采用1-gram的FastText模型相比,FastText在训练模型上花费的时间最少,但在准确率、F1值和损失都要比Bi-SGRU-Attention效果差,我们认为采用将所有词向量加权取平均的操作不能够充分的体现词汇上下文依赖特征,采用N元词袋模型引入词序信息,当采用2元词袋模型实验时,参数量巨大,花费时间也将是巨大的,FastText在时间上的优势就没有那么明显.C-LSTM模型在所有的实验模型中,准确率最低,损失最高,我们认为在IMDB数据集上采用CNN与RNN串联的方式提取文本特征的效果略差.采用两层双向LSTM堆叠方式的S-BiLSTM模型,与Bi-SGRU-Attention模型相比较,双向LSTM堆叠的方式并不能够突出重要特征,与其他几种加入Attention机制的模型相比,它的准确率、F1值较低.采用堆叠的方式,在训练时间花费上也要多出很多.与以上几款经典的模型相比较,我们提出的模型更具有优势.

表4 各种模型实验结果Table 4 Various models experiment results
以上经典模型在模型设计上与我们提出的模型有很大的差异,为了使实验更具有说服力,我们对其他加入Attention机制模型进行实验结果分析:与BiLSTM- EMB-ATT模型相比,模型都是采用双向RNN进行特征提取,BiLSTM- EMB-ATT模型对输入序列同时进行双向RNN特征表示和利用Attention机制进行词向量权重分布表示,并将两者特征进行融合,而我们的先对划分的最小子序列进行两个方向RNN表示,再在每一个子序列隐含表示的基础上进行词向量权重分布表示,BiLSTM- EMB-ATT模型虽然对输入的文本增强了注意力表示,但是没有关注到词向量权重分布与RNN在提取文本特征之间的相互关系,使得模型效果略差.与BiLSTM-Attention模型和BiGRU-Attention模型相比较,这两个模型,都先对输入文本进行隐含表示,然后根据隐含表示计算词向量的权重分布,两者模型都没有摆脱标准RNN时间步的依赖性,无法实现并行,Bi-SGRU-Attention模型通过切片操作方式,将输入序列进行划分,实现了分类模型的可并行性,由表4可以得出结论,本文提出的模型训练所花费的时间远远小于这两种模型,当输入的文本序列更长的时候这种优势将更为明显.同时Bi-SGRU-Attention模型不仅没有损失BiLSTM-Attention模型和BiGRU-Attention模型提取文本特征的效果,由于将输入序列划分成多个子序列进行特征提取的操作方式,信息通过多个网络层传递,我们的模型还能够关注到句子之间的局部特征关系,使得模型能够捕获到更多的信息.因此在各项评估指标中优于BiLSTM-Attention模型和BiGRU-Attention模型.
同时,与Bi-SGRU模型作比较,说明了在每个最小子序列上加入Attention机制,能够对每个最小子序列的重点特征实现关注,弥补低层网络长期依赖性损失从而提升模型情感分析效果.与SGRU-Attention模型比较,单向的SGRU模型只能够使用过去的信息,采用双向SGRU能够结合过去和未来的信息,使得模型能够更好的理解上下文信息.
为了验证Attention机制的有效性,我们将Attention层的权重可视化.

图4 总输入序列的注意力权重图Fig.4 Attention weight map of the total input sequence
如图4所示,图上展示一条影评语料输入模型,对每个输入序列(512个输入片段)的关注度,通过观察发现Attention机制能够对语料的局部特征进行关注.前半段(图上区域①范围)为填充段,这些子序列的注意力层基本呈现相同的关注度.具体一个填充段的子序列注意力权重如图5所示.
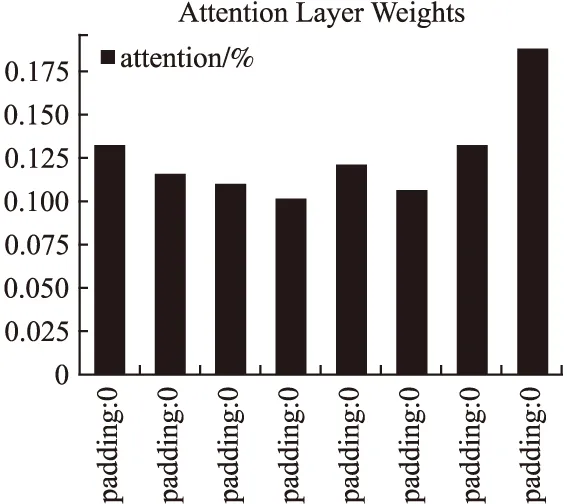
图5 填充段注意力权重图Fig.5 Padding segment attention weight map
对于第1个输入片段到第4个输入片段,注意力权重呈阶梯状递减,第6个输入片段到最后一个输入片段注意力权重呈阶梯状递增.间接反映了Attention机制能够对子序列的前半部分以及后半部分予以关注,这样通过层与层之间的信息传递,这些片段能够在下一层中提供更多的信息,并以此弥补低层网络的长期依赖性损失.
通过对该条影评语料样本分析,我们选择其中两个关键序列进行注意力层权重输出,如图6和图7所示.
通过图6与图7分析发现,除了关键词得到一定的关注外(图6中的′majority′、′Knowles′和图7中的′stuck′与′basically′),序列的前小部分输入与后小部分同样也得到一定的关注,更加直观的表明Attention机制能够对子序列的前半部分以及后半部分予以关注,同样能够弥补切片操作造成的低层网络依赖性损失.
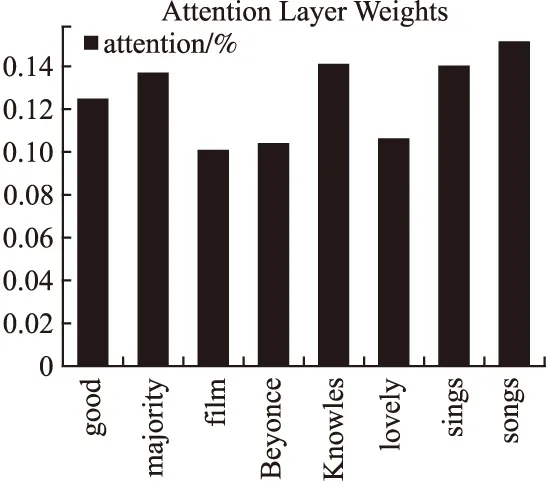
图6 关键序列1注意力权重图Fig.6 Key sequence 1 attention weight map

图7 关键序列2注意力权重图Fig.7 Key sequence 2 attention weight map
5.7 模型通用性实验
为了进一步验证模型的通用性,我们在谭松波中文酒店评论数据集ChnSentiCorp-Htl-ba-6000(1)http://download.csdn.net/download/lssc4205/9903298上进行测试,数据集具体说明,如表5所示.

表5 酒店评论数据集Table 5 Hotel reviews dataset
在中文酒店评论数据集上的实验步骤与在IMDB数据集上的实验步骤仅在数据预处理上有所差别,在加载完数据后,中文数据需分词处理,本实验采用结巴分词工具进行分词.实验环境、模型参数以及评估标准都保持不变.
为了确定在该数据集上SGRU(n,k)切片的最佳效果,我们采用与5.4节相同的四种切片方式进行实验,结果如表6所示.
由表6我们可以发现当k为2,n为8时,即当输入序列长度为512,每次切片将序列切成8片,并进行2次切片操作时,效果较好.因此我们在进行实验的时候取k=2,n=8,MaxLen=512.
本次实验为了验证模型的通用性,我们仅与王伟等人[11]提出BiGRU-Attention模型对比,实验结果如表7所示.

表6 不同切片实验结果Table 6 Different slice experiment results

表7 模型通用性实验结果Table 7 Model versatility experiment results
如表7所示,本文提出的Bi-SGRU-Attention模型在中文酒店评论数据集上依旧表现最好.模型Bi-SGRU与模型SGRU实验结果表明双向切片操作能够更加充分提取文本语义信息.模型Bi-SGRU-Attention与模型Bi-SGRU实验结果表明,加入Attention机制能够弥补低层网络长期以来损失.模型Bi-SGRU-Attention与模型BiGRU-Attention实验结果表明,双向切片循环神经网络能够获得比传统双向循环神经网络更深的文本语义信息.同时,充分表明本文所提模型的有效性及通用性.
6 结束语
本文提出的Bi-SGRU-Attention模型,比起广泛应用于情感分析的几款经典模型有着更高的准确率,在同种类型即RNN和Attention机制结合的模型中,本文模型有着更为稳定的效果,且实现了RNN在训练过程中并行性的可能,大大缩减了模型的训练时间,尤其对长文本情感语料进行分析时,有着更为明显的优势.总体上来看,本文所提出模型改变了传统双向RNN网络连接方式,在没有降低网络特征提取效果的前提下,有着更快更稳定的优势.但是本模型在子序列的特征提取的处理上还是采用标准的RNN处理方式,无法像CNN一样实现完全的并行,在速度上与CNN网络模型还是有着不小的差距.
