开源社区中Issue解决过程的参与者推荐方法
2020-09-02刘晔晖赵海燕陈庆奎
刘晔晖,赵海燕,曹 健,陈庆奎
1(上海理工大学 光电信息与计算机工程学院 上海市现代光学系统重点实验室光学仪器与系统教育部工程研究中心,上海 200093)2(上海交通大学 计算机科学与技术系,上海 200030)
E-mail:1092778656@qq.com
1 概 述
互联网已经从内容发布发展到了用户创建内容的时代[1],出现了许多社交媒体包括博客、网络论坛、社交、照片和视频共享社区等.与此同时,出现了许多互助社区,如StackOverflow平台,在这样的社区上,用户之间可以互相帮助[2].在这些潮流的推动下,基于互联网进行开源软件开发得到了蓬勃发展,开源项目平台如Github上集聚了大量的开源项目.
问题追踪器已成为现代软件开发项目中必不可少的协作工具[3],它们可以用于注册和跟踪新功能请求、开发任务和错误等.在开源项目如Github中,每个人都可以在项目的问题跟踪器上打开一个新问题,而问题解决过程的参与者可能直接来自于项目的核心团队成员或者是对该项目感兴趣的外部贡献者.等待相应的人员来解决问题的过程并不总是迅速的,这将导致问题处理不够及时甚至长久得不到解决,因此出现了一系列研究[4-8]旨在推荐能够解决该问题的专家.一般来说,这些方法将过去类似问题的回答者作为推荐对象,因此,其推荐的质量依赖于所选择的衡量问题相似性或者相关性的属性.这种依据过去的直观经验进行推荐的方法在新问题上是无法奏效的.
将创建的问题分配给合适的解决者将使开源项目的开发进程加快,因此我们设计了参与者推荐系统,以便在Github中预测适当的参与者.我们的方法利用熵值法对开发者画像中的特征进行个性化权重计算,结合问题的文本语义和开发者的社交关系进行推荐.
我们的工作贡献如下:首先分析了影响开发者参与问题积极性的影响因素,根据这些影响因素构建开发者画像,提出一种混合评论者推荐方法,该方法同时结合基于社交网络和信息检索的方法.我们在Github上的五个流行项目验证了18215个问题.结果表明,我们的混合方法优于其他单独的方法.
2 相关工作
Github上,开源软件的开发过程由5个步骤组成的工作流[9]组成:
1)讨论问题:讨论项目的一个新功能,商定需要做什么,主要是许多开发人员就一个新的功能或需要修改的功能进行沟通,并最终确定要增加或修改什么样的功能;
2)指定事务:为讨论出的功能创建一个分支;
3)执行事务:在指定事务工作流中创建的分支上建立一个功能分支以使其工作;
4)审查事务:功能完成后推送到远程端,通过pull request进行代码审查;
5)问题解决后迭代:在审查中发现问题,进行问题讨论,直到问题被解决.代码合并到主分支.可以看出,问题讨论和解决在其中具有重要作用.
最近针对开源软件中的问题解决过程,很多学者进行了研究.HomwitZ等人证实朋友比陌生人更愿意也更有效地解答问题[10].Morris等人的研究发现,在小规模的研讨中,很多参与者的问题都是被关系紧密的朋友解决的,而且友谊的紧密程度是对回答问题的一种激励因子,每种亲密程度的人群都会乐意回答问题[11,12].Tian等人提出了一种基于多种属性推荐评论者的方法,将用户的活跃度与文本相似度等元素考虑进去,发现用户活跃度是评论者推荐最重要的属性[13].de Lima Júnior 等人用不同的分类算法对请求合并的属性进行评估,发现请求的时间间隔、文本的相似度以及社交关系对推荐评论者的影响更大[14].Rath等人发现,基于代码的信息检索对开发人员有积极影响[15].Ponzanelli等人考虑了开发人员已经咨询或研究的内容,通过相似度计算为信息检索提供上下文支持[16].Adaji等人将社交网络用语Stack Overflow中,从而帮助社交网络开发人员建立有说服力的问答社区,并改善现有的社交平台[17].
我们先利用开源社区问题解决过程人员参与积极性的影响因素对开发者构建画像,利用熵值法计算不同开发者对问题特征的的个性化权重,然后结合信息检索和社交网络对问题进行建模.问题的标题以及描述信息能够直接体现提问者的疑问和主题,所以我们把训练集中的问题当做历史文本信息,测试集中的问题的标题和描述作为查询,构建推荐系统.
3 问题解决参与者推荐算法
3.1 基于信息检索的问题解决参与者推荐
基于信息检索的方法是当前一种流行的bug分配算法,旨在匹配开发人员的技术焦点.首先我们根据标题和描述信息生成每个问题的核心内容.通过删除在此过程之前预定义的停用词,我们获得了每个问题的核心关键字,并形成一个语料库.其次,我们根据TF-IDF算法(公式(1))生成每个问题的问题向量.
(1)
其中,t代表一个特定的关键字,freq(t,issue)表示在Issue文档中issue出现关键字t的次数,Tissue′表示issue中的所有关键字.
当测试集中出现一个问题时,我们使用余弦相似度计算每个问题之间的关系(公式(2)).每个问题的向量由整个语料库中的关键字形成.
(2)
根据公式(1)和公式(2)我们总结了开发人员之前参与过的问题与目标问题之间的关系(公式(3)).
relation(d,issue)=∑issue′∈Issuedsimilarity(issue,issue′)
(3)
其中d代表开发者,Issued表示开发人员之前参与过的问题集.
因此,当目标问题出现时,计算每个开发者和目标问题之间的关系,然后按降序对结果进行排名,并推荐top-N个结果.
3.2 基于评论网络的问题解决参与者推荐
我们认为同一个项目中开发人员具有相同的兴趣,因此我们在研究的项目中建立了一个评论网络.在给定项目中,评论关系的结构是多对多模型,一个问题可以被多个开发人员评论.
我们将评论网络定义为一个带权重的有向图Gcn=〈V,E,W〉,其中定点V表示开发者集合,节点之间的关系集合用边E表示,如果节点vj至少评论了vi提出的一个问题,那么从vi到vj就会有一条边eij.权重集合W反映了边的重要程度,边eij的权重wij可以通过公式(4)来评估.
(4)
其中,k是由vi提交的问题的总数,并且w(ij,q)是与某个问题q相关的权重.Qc是一个经验值(设置为1.0),用于评估每个评论对问题的影响,并且m是由vj在相同的问题中提交的评论的总和.当评论者vj在同一问题中发表多个评论(m≠1)时,他的影响因子又衰减因子λ(设定为0.8)控制.元素t(ij,q,n)是对应评论的时间敏感因子,计算如下:
(5)
其中timestamp(ij,q,n)是评论者vj在问题q中评论的日期,starttime和endtime分别表示一个问题提出的时间和最终被关闭的时间.

图1 评论网络示例Fig.1 An example of the comment network
图1显示了关于jasmine项目中评论网络中的一部分示例.v1提交的两个不同的问题(issue1和issue2)被v2和v3评论过,因此从v1到v2和v1到v3有两条边.issue1的starttime为2019-03-11T01:06:18Z,endtime为2019-03-12T01:24:46Z;issue2的starttime为2018-07-07T20:52:04Z,endtime为2019-01-23T01:48:24Z.评估v1和v2之间的关系时,因为v2只评论了issue2,所以公式(4)中的k值为1,w12≈0.742.评估v1和v3之间的关系时,因为v3两个问题都评论过,所以公式(4)中的k值为2.对于issue1,w(13,2)≈0.988.对于issue2,v3评论过4次,因此m设置为4.第一个时间2018-07-20T00:54:24Z的时间敏感因子可以通过公式4计算得出t(13,2,1)≈0.061,因为一个用户在相同的问题中的影响越来越小,所以其他的时间敏感因子由λ(=0.8)控制,则w(13,2)可以计算为:Qc×(t(13,2,1)+λ2-1×t(13,2,2)+λ3-1×t(13,2,3))+λ4-1×t(13,2,4)≈1.012.类似的,权重w13=w(13,1)+w(13,2)=2.0.因此,根据相应边的权重的量化,我们可以预测,与v2相比,开发人员v3与问题提问者v1共享更多的兴趣.
我们提出的评论网络具有如下优点:
·引入时间敏感因子t以保证最近的评论对于边的权重比旧的评论更有价值
·引入衰减因子λ以保证评论多个问题和值对单个问题评论多次之间的差异值.例如,如果开发人员vj评论了vi提交的5个问题,同时vk评论了vi提出的某一个问题5次,则wij的权重大于wik.
3.3 基于开发者画像的问题回答者推荐
根据之前研究,开发人员会有偏好的参与一些问题的解决.问题的文本长度(textLen)、是否含有代码(code)、问题提问者是否是项目贡献者(role)都会对问题解决的参与积极性有影响.因此在构建开发者画像前,需要先建立问题特征向量,开发者参与过的多个问题特征向量组成开发者画像.
熵值法可以用于判断一个事件的随机性和无序程度,常被研究人员用来评估事件的关联性.Lee等人采用熵值法对用户评分物品的相似性进行度量[18,19].Deldjoo等人使用熵值法去判断用户对特征属性的敏感程度,从而计算推荐系统的公平性[20].Yi等人对用户浏览过的网页文本提取特征词,通过熵值法计算相应的权重,提出了基于信息熵的二次聚类推荐算法[21].所以在衡量开发者对问题某一特征的偏好程度时,我们采用熵值法计算不同开发者对问题特征的偏好程度,从而避免人为分配的主观性带来的偏差,同时可以根据不同开发者对特征的偏好权重更好的实现个性化推荐.其基本原理是:熵是对信息不确定性的一种度量,熵值越小,所蕴含的信息越大.所以当每个特征属性的熵值越小,则开发者对该属性的偏好越强,就应赋予较大的权重.
假定有n个样本m个属性,xij表示第i个样本的第j个属性的数值(i=1,2,…,n;j=1,2,…,m),熵值法的基本步骤如下:
(i)属性的归一化处理:异质指标同质化,由于各项指标的计量单位并不统一,因此在用它们计算综合指标前,先要对它们进行标准化处理,并令xij=|xij|.由于我们实验所用属性都为正向指标,所以其计算方法如公式(6)所示.
(6)
则x′ij为第i个样本的第j个属性的数值(i=1,2,…,n;j=1,2,…,m).
(ii)计算第j个属性下第i个样本占该指标的比重:
(7)
(iii)计算第j个s属性的熵值:
(8)
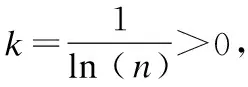
(iv)计算信息熵冗余度(差异):
dj=1-ej,j=1,…,m
(9)
(vi)计算各项指标的权重:
(10)
根据公式(6)-公式(10)可以计算得到某一开发者对问题特征的偏好权重,将目标问题向量化得到的问题向量与开发者的偏好权重向量做点积,即可得到该开发者参与目标问题的得分,记为scoreentropy.
由于上述三种方法都侧重于问题的不同部分,为了获得更好的推荐结果,我们综合以上三种推荐算法进行混合推荐.首先通过scoreentropy给出排名前M个开发者作为候选集,候选集中每个开发者在信息检索和评论网络中的贡献结果根据(公式(11))计算得出.通过累加每种方法的不同结果得到开发者的最终得分,按降序对结果进行排序后,取Top-N作为推荐结果.开发者的得分计算如公式(12)所示.
(11)
scorehybrid(d,issue)=scoreIR(d,issue)+scoreCN(d,issue)
(12)
4 数据及实验
4.1 问题及评论的数据
我们在Github上选择了5个流行仓库(jasmine,realm-cocoa,elixir,metabase和istio),作为我们的研究的基础.我们获得了这些仓库所有的issue信息,包括issue的描述、标题、代码段以及所有参与该问题的开发者信息等.通过爬虫我们从项目中获得了5个项目共18215条issue以及78583条评论,数据集见表1.

表1 jasmine,istio,realm-cocoa,elixir和matabase数据集Table 1 Dataset in jasmine,istio,realm-cocoa,elixir and metabase
4.2 评测指标
为了验证我们算法的性能,我们采用召回率作为评价指标,计算方式如公式(13)所示.
(13)
其中,Issues表示问题的测试集,R(i)表示根据开发者在训练集上的行为做出的Top-N推荐列表,T(i)表示实际问题中的用户列表.
4.3 推荐结果
根据我们的统计,75%的问题最多有两个人参与讨论,假设我们将推荐列表长度约束在10人以内,将覆盖90%以上的问题,所以我们比较了三种方法在推荐Top-2,Top-4,Top-6,Top-8和Top-10个开发人员时哪种推荐性能更好,结果如表2所示.
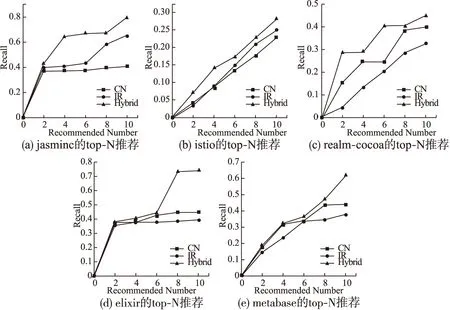
图2 不同算法下参与者推荐Recall比较Fig.2 Recall comparison of differrnt method about Q&A recommendation
为了更直观的看出推荐性能的不同,我们将表2转化成图2的形式.从图2(a)可以看出,当推荐2、5、10个评论者时,jasmine基于开发者画像的混合推荐召回率与其他两种方法相比是最好的,性能从42.63%到79.49%,类似的结果可以从图2(b)、图2(c)、图2(d)和图2(e)得出,也就是说混合方法可以弥补其他两种方法的不足并达到最佳效果.
5 总结和展望
本文旨在深入分析已有问题的参与者推荐方法,并提出一种有效的改进算法.我们详细描述了用到的模型,并在Github上选择热门的项目进行了对比实验.结果表明,基于开发者画像的混合推荐可以有效的推荐参与者.同时我们的推荐模型加强了个性化推荐效果,这意味着对于不同的问题,我们的模型可以推荐不同类型的开发人员来解决问题.由于之前我们分析了开源社区解决过程人员参与积极性的影响因素,所以选取的特征促使推荐性能更好.
本文的模型中考虑了问题的某些特征对参与者积极性的影响,但是一些其他特征可能也影响参与者的积极性,例如问题的类别对开发者参与积极性也有影响,每个类别之间存在的差异都会体现技术相关的过程,推荐对该类问题更具有专业知识的开发人员更有助于问题的解决.对于未来的工作,我们计划基于机器学习分类器为开源项目开发一个细粒度的问答者推荐模型.
