一种结合压缩激发块和CNN的文本分类模型
2020-09-02陶永才刘亚培马建红李琳娜
陶永才,刘亚培,马建红,李琳娜,石 磊,卫 琳
1(郑州大学 信息工程学院,郑州 450001)2(郑州大学 软件学院,郑州 450002)3(中国科学技术信息研究所,北京 100038)
E-mail:liln@istic.ac.cn
1 引 言
网络的迅速发展,使得非结构化的数据成指数级增长,如何将非结构化的数据进行处理、分类、搜索与挖掘已经成为研究的热点与难点.文本作为非结构化数据类型之一,怎么将其正确、高效的分类,也是研究热点之一.文本分类是自然语言处理中一个比较基础的问题,它是信息检索、学习系统、文本挖掘、模式识别等发展的基础.目前文本分类常用的方法有两大类,一是基于传统机器学习的文本分类方法,二是基于深度学习的文本分类方法.
深度学习最早由Hinton等人[1]于2006年提出,其利用无监督预训练方法优化网络权值的初值,再进行权值微调的方法,来解决因传统的神经网络随机初始化网络中的权值,而导致网络易收敛到局部最小值的问题,由此开启了深度学习的研究热潮.相比传统的机器学习,深度学习可通过学习一种深层非线性网络结构,实现复杂函数逼近,表征输入数据分布式表示,且能在样本集很少的情况下去学习数据集的本质特征[2].
卷积神经网络(Convolutional Neural Networks,CNN)是深度学习中的一种监督学习的方法[2].CNN中卷积层的权值共享,使得网络中可训练的参数变少,网络模型复杂度降低,减少过拟合,从而获得了更好的泛化能力,其结构可拓展性强,可以用很深的层数来增强其表达能力以处理更复杂的分类问题[3,4].CNN最早应用于图形图像,并在图像处理、图像分类等方面取得了很好的效果.2013年Mikolov等人[5]提出词向量模型之后,使大规模的词嵌入训练成为可能,为CNN广泛应用于自然语言处理,奠定了基础.
随着自然语言处理研究领域的不断发展,将深度学习方法应用于文本分类处理已经成为一个不可忽视的研究趋势.但是单一的卷积神经网络容易忽视局部与整体之间关联性的问题,现有论文中以增加卷积网络深度或与其他神经网络进行结合,来解决上述问题.本文试图在卷积神经网络的结构中引入新的网络结构单元—压缩-激发块(Squeeze-and-Excitation block,SE block),以此来建模卷积特性通道之间的相互依赖关系来提高网络模型的表达能力,增强局部与整体之间关联性.并引入多头注意力机制(Multi-Head Attention)来提升网络的性能,提高文本分类的准确性.
2 相关工作
自词嵌入出现以来,神经网络在文本处理方面迅速发展.2014年Kim Y等人[6]在预处理的词向量训练卷积神经网络(CNN)进行句子级分类任务,在多个基准上取得了很好的效果.2015年Zhang X等人[7]使用字符级卷积网络(ConvNets)对文章进行分类,在其建造的大型数据集上实现了最好的实验结果.2016年Kim Y等人[8]通过使用字符级的输入来代替传统的word embedding,避免了大规模的embedding计算和低频词的问题,其实验结果表明,在许多语言中,字符输入足以进行语言建模.刘坤[9]研究了中文字符级嵌入,并提出将汉字的字符嵌入向量与词语级别的嵌入向量结合,能提升汉字嵌入向量的质量.
随着深度学习的发展,大量的研究者在文本分类问题上,以卷积神经网络为基础进行模型的改进与创新.Johnson 和Zhang[10]提出了一种单词级别深度卷积神经网络结构DPCNN(deep pyramid CNN),有效地表示文本中的长距离关系,该模型增加网络深度而不增加太多的计算成本就可以获得最佳的准确性.Joulin等人[11]提出了一种简单高效的文本分类模型,简称fastText.该模型只有简单的三层:输入层、隐含层、输出层.输入层将词向量特征进行嵌入与平均,以形成隐藏变量,再使用softmax函数来计算预定义类的概率分布.fastText的浅层结构在文本分类任务中取得了与深度网络相媲美的精度,且在训练时间比深度网络更快.Zhao等[12]提出了一种基于胶囊网络的文本分类模型,该模型先用一个卷积层提取句子的局部语义表征,然后将卷积层提取的特征替换为向量输出胶囊,从而构建Primary Capsule层,之后利用改进的动态路由得到卷积胶囊层,继而将卷积胶囊层的所有胶囊压平成为一个list,输入到全连接网络,最后得到每个类别的概率.这是第一次将胶囊网络应用于分本分类,在其实验中取得了较好的结果.2018年Hu等人[13]在《Squeeze-and-Excitation Networks》一文中,通过研究通道之间的关系,引入了一种新的体系结构单元,称之为压缩-激发块(Squeeze-and-Excitation block,SE block),其目标是通过明确地建模卷积特性通道之间的相互依赖关系来提高网络模型的表达能力.这种新的网络结构单元已经用到了图像处理中.SE Block本身只是一个结构上的创新,并不能单独使用.但是因为其原理的简单性,它可以很容易被集成到不同的网络结构中,这里我们将其应用到文本分类处理的问题中,来处理序列数据.
神经网络中的注意力机制最初出现在图像领域[14].注意力机制可以使得神经网络具备专注于其输入(或特征)子集的能力.Yang等人[15]提出了一种用于文档分类的层次注意力机制网络(HAN),该网络分别在词汇和句子两个层次上使用注意力机制,捕捉不同层次的重要信息,这使得它在构建文档表征时,可以分别关注更重要和不太重要内容,从而提升了文本分类的性能和准确度.Vaswani等人[16]提出以放缩点积注意力(Scaled Dot-Product Attention)为基础,用多个平行运行的注意层组成多头注意力(Multi-Head Attention)取代了重复层最常用的编码器和解码器架构,提供了一种用Attention结构完全替代传统CNN和RNN结构的新思路,证明了注意力机制的有效性.刘月等人[17]引入注意力机制突出关键短语以优化特征提取的过程来进行新闻文本分类,在3个公开数据集上取得了不错的结果.赵亚南等人[18]采用多头自注意力机制学习序列内部的词依赖关系来捕获序列的内部结构,然后重利用浅层特征与多头自注意力特征融合,并结合深度学习卷积神经网络算法来进行文本情感极性分析.
在前人研究成果的基础上,本文构建了CCNN-2SE-mAtt模型,其利用字符级(Char-level)词向量作为卷积神经网络的输入,并引入新的网络结构单元——压缩-激发块(SE block),以此来建模卷积特性通道之间的相互依赖关系来提高网络模型的表达能力,并引入多头注意力机制(Multi-Head Attention)对其权重进行更新计算,得到文本类别的特征向量矩阵,突出类别向量的重要程度,最后用softmax进行分类.上述模型用于 THUCNews数据集和搜狐数据集(SogouCS)的中文文本分类数据集中,具有一定的实用性与创新性.
3 模型实现
本文结合字符级词向量、压缩-激发块(SE block)和多头注意力机制,构建一个中文文本分类模型,具体工作如下.
3.1 字符级词向量
将词嵌入具体化时,实际上是具体化一个嵌入矩阵.在数据预处理阶段,将原始中文新闻文本按字符划分为单个汉字与符号,构建一个大小为m的字符表,使用one-hot编码对每个字符进行量化.然后根据输入的文本的序列,将其转化为对应的向量序列.输入长度超过l0的字符都忽略,空字符或不存在于字母表中的字符用零向量替代.最后,数据通过嵌入层成为卷积层的输入.本实验中字符表大小m为5000,最大文本序列长度l0为700.
3.2 压缩-激发块(Squeeze-and-Excitation block,SE block)
CNN对局部进行上下文建模,能自动抽取出一些高级特征,减少了特征工程的时间,但是其视野受限.加入压缩-激发块后可以对整个输入特征进行上下文建模,感受野可以覆盖到整个输入特征上,能对语义信息进行补充.

压缩-激发块(SE block)使用全局信息来显式地建模通道之间的动态、非线性依赖关系,可以简化学习过程,并显著增强网络的表示能力.
3.2.1 压缩(Squeeze)
利用全局平均池化(global average pooling,GAP)进行空间维度的特征压缩,将二维H×W特征压缩为一个实数,获得U的每个通道的全局信息嵌入(特征向量).即经过Fsq(·)(Squeeze操作)后,输入变成了一个 1×1×C的特征向量,特征向量的值由特征映射U确定.其计算如公式(1)所示.
(1)
其中z∈RC.
3.2.2 激发(Excitation)
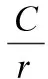
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(2)

(3)
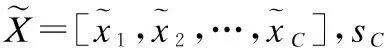
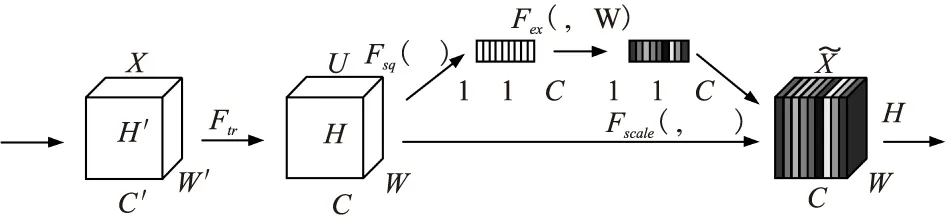
图1 压缩-激发块(SE block)Fig.1 Squeeze-and-Excitation block
3.3 多头注意力机制(Multi-Head Attention)
注意力函数可以描述为将query和一系列key-value对映射到output,其中query、keys、values和output都是向量.
输出计算为值的加权和,其中分配给每个值的权重由查询的兼容性函数和对应的键计算.本实验通过多个放缩点积注意力(Scaled Dot-Product Attention)操作来提取信息,拼接得到多头注意力(Multi-Head Attention)的值.

单个注意力计算输出如公式(4)所示.
(4)
在多头注意力操作之前,先将Q、K、V进行一次线性变换,之后将其映射到多个不同的子空间,利用h个放缩点积注意力来进行计算,以关注不同子空间的信息,最后,将h个子空间上的注意力输出拼接得到多头注意力的输出.多头注意力其架构如图 3所示.

多头注意力机制(Multi-Head Attention)如公式(5)所示.
MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
(5)
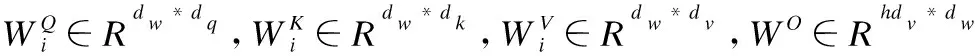
3.4 基于CCNN-2SE-mAtt文本分类模型
在以上模型的基础上,本文的所提出的CCNN-2SE-mAtt文本分类模型结构如图 4所示.
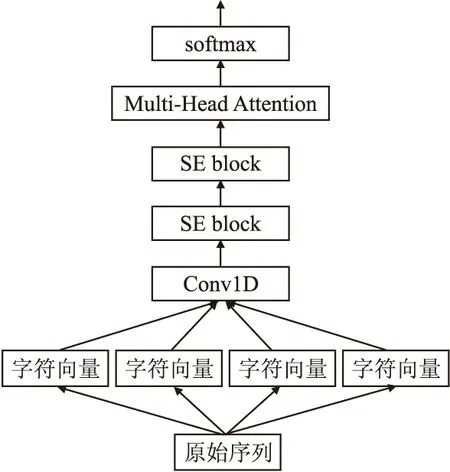
图4 CCNN-2SE-mAtt模型结构图Fig.4 CCNN-2SE-mAtt model structure
将原始序列文本按字符划分为单个汉字与符号,每个字符进行量化,根据输入的文本的序列,将其转化为对应的向量序列,输入到卷积层,经过两层压缩-激发块(SE block),对整个输入特征进行上下文建模,经特征重标定输出到一维卷积层,之后经过多头注意力在多个子空间计算其特征的重要性分布,并将其结果进行拼接,输入到softmax分类器中来预测文本类别.
4 实 验
本文实验配置如下:操作系统为Windows10,处理器为Intel(R)Core(TM)i7-8700,内存为16.0 GB,GPU为NVIDIA GTX1060 6GB,编程语言为Python 3.6,学习框架为Keras 2.2.4.
4.1 实验数据集
本文使用了THUCNews数据集和搜狐数据集(SogouCS)进行文本分类.THUCNews是由清华大学自然语言处理实验室推出的新闻文本数据集,包含74万篇新闻文档,分为14个候选新闻类别.本文使用其中的10个类别,每个类别包含5 000个训练样本,500个验证集样本和1000条测试样本.
搜狐新闻数据(SogouCS)是搜狐实验室推出的新闻数据集.本文使用其中12个类别,共21614条数据.每个类别包含大约2000个训练样本,500个验证集样本和500条测试样本.
4.2 实验评价指标
分类模型的评测指标主要包括Precision(精确率)、Recall(召回率)、F1-Score.Precision是指预测为正的样本中真正的正样本所占的比率.召回率是指样本中正例被预测正确的比率.F1-Score是综合评价指标.各评价指标的计算分别如公式(6)-公式(8)所示:
(6)
(7)
(8)
4.3 实验参数设置
在实验中,不同的参数设置会影响到实验的最终结果,这里列出部分参数,以此为基准进行实验.实验参数如表 1所示.
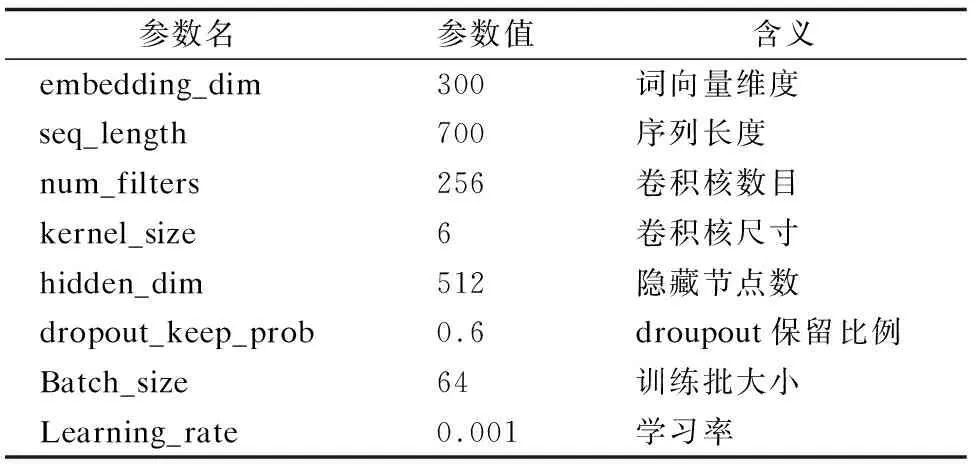
表1 模型参数设置Table 1 Model parameter setting
4.4 对比实验设置
1)CCNN模型.以字符级词向量输入卷积神经网络,然后进行文本分类,以此作为实验的基线.
2)CCNN模型,CCNN-SE模型,CCNN-2SE模型和CCNN-3SE 模型.将这四个模型进行实验对比,目的是为了证明在单一的字符卷积神经网络上,引入SE block模块后,卷积神经网络模型在中文文本分类任务上的性能得到提升,以及SE block模块的堆叠在一定程度上能增加文本分类的精确率、召回率以及F1-score值.
3)CCNN-SE模型和CCNN-SE-mAtt模型,CCNN-2SE 模型和CCNN-2SE-mAtt模型进行对比实验,证明多头注意力机制(Multi-Head Attention)在此模型中有助于文本分类.
4.5 实验结果分析
CCNN模型、CCNN-SE模型、CCNN-2SE模型和CCNN-3SE模型分别在THUCNews数据集和在搜狐数据集(SogouCS)上的Recall(召回率)对比结果如图 5所示.
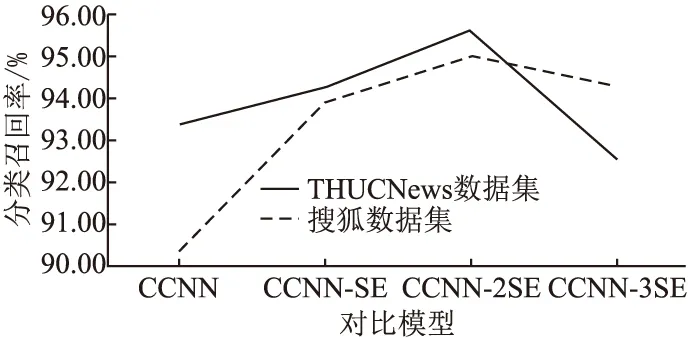
图5 有无SE block模型召回率对比Fig.5 Comparison of recall rate of model with and without SE block
由图5可知,在CCNN模型上分别增加1个、2个、3个压缩-激发块(SE block)之后,在两个数据集上的召回率趋势先增加后降低.在THUCNews数据集上,CCNN-SE模型和CCNN-2SE模型的召回率均比CCNN模型的高,但是CCNN-3SE模型的召回率比CCNN模型的低.在搜狐数据集上CCNN-SE模型、CCNN-2SE模型、CCNN-3SE模型的召回率均比CCNN模型的高.这证明了压缩-激发块有助于提升模型性能.其中,CCNN-2SE模型分别在THUCNews数据集和搜狐数据集的召回率比CCNN模型高2.21%、4.64%,并且,CCNN-2SE模型比其他含有不同个数的压缩-激发块模型表现更好.
图6和图7分别展示了在CCNN-SE模型、CCNN-2SE模型增加了多头注意力机制(Multi-Head Attention)后,在两个数据集上的结果对比.

如图6所示,在CCNN-SE模型增加了多头注意力机制后,在THUCNews数据集的F1-score提高了0.76%,在搜狐数据集的F1-score提高了0.28%.如图7所示在CCNN-2SE模型增加了多头注意力机制后,在THUCNews数据集的F1-score提高了0.02%,在搜狐数据集的F1-score提高了0.25%.由此证多头注意力机制在一定程度上提高了模型的分类性能.
6个模型分别在THUCNews数据集和搜狐数据集上分类的精确率,如表 2所示.在清华数据集上CCNN-2SE-mAtt模型分类的精确率比CCNN模型的高2.29%,在搜狐数据集上CCNN-2SE-mAtt模型分类的精确率比CCNN模型的高4.75%.
实验结果表明,在中文新闻文本分类任务上,使用CCNN-2SE-mAtt模型比使用单一的卷积神经网络其分类效果要更好.
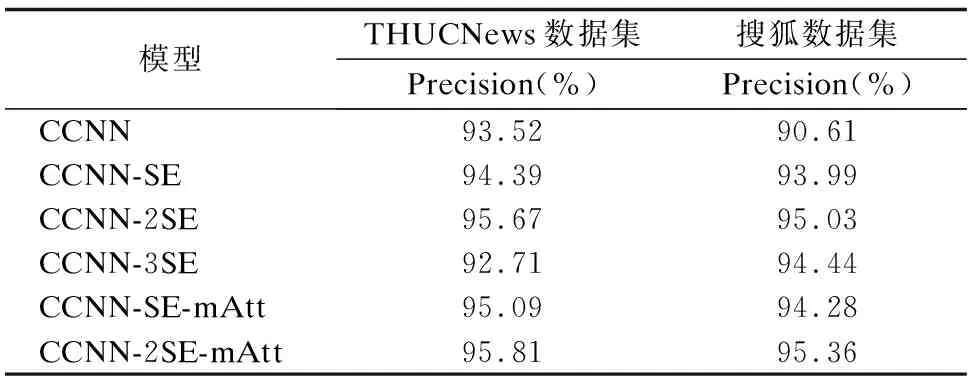
表2 模型分类精确率对比Table 2 Model classification accuracy rate comparison
5 结 论
本文在字符级卷积网络(Char-CNN)的基础上引入了新的网络单元——压缩-激发块(SE block),它使用全局信息来显式地建模通道之间的动态、非线性依赖关系,可以简化学习过程,能显著提高网络性能.最后引入多头注意力机制(Multi-Head Attention)以关注多个子空间信息,提升模型分类的性能.在THUCNews数据集和搜狐数据集(SogouCS)进行训练和测试,证明了在中文文本分类中,基于压缩激发块的字符级卷积网络(CCNN-2SE-mAtt)模型优于单一的卷积神经网络,其不仅提高了中文文本分类的精确率,更进一步证明了压缩-激发块(SE block)用于文本分类的可行性.在单一的卷积神经网络中引入压缩-激发块(SE block),并将此结构单元用于处理自然语言处理中的文本分类问题,是本文中一个比较大的创新.在接下来的研究中,将继续优化基于压缩-激发结构单元的卷积神经网络的网络结构,来验证能否在英文文本数据集上进行有效的文本分类实验.并研究引入压缩-激发块(SE block)的卷积神经网络能否适用于自然语言处理中的其他研究方向,如中文文本情感分析.
