汉语二语学习者推测词义的偏误及影响因素分析
2020-09-01汤明

摘要:通过书面测试和面谈的形式调查了29名中级汉语学习者在句子阅读和段落阅读中推测词义的偏误情况,并对偏误原因进行了深入探讨。结果显示汉语学习者在推测词义时会产生六大类偏误,包括语素层面的偏误、词语层面的偏误、句子层面的偏误、语境层面的偏误、母语层面的偏误以及与其他已有知识有关的偏误。这些偏误出现的频次会随着目标词的语义透明度、文本的语境强度以及学习者的母语背景的变化而发生变化,而导致学习者猜词偏误的原因可分为主观原因与客观原因,并根据这些原因为汉语教学提供了相关建议。
关键词:推测词义;偏误;语义透明度;语境;母语背景
作者简介:汤明,语言学博士,华侨大学华文学院讲师,主要研究方向:华文教育、第二语言习得(E-mail:2380853709@qq.com;福建厦门)。
基金项目:华侨大学高层次人才科研启动项目“汉语二语学习者在阅读中的猜词研究”(18SKBS207)
中图分类号:H19
文献标识码:A
文章编号:1006-1398(2020)04-0042-11
从阅读中习得词汇是语言学习者扩展词汇量的主要途径。为了确保阅读的顺利进行,学习者通常会采用推测词义的方式去处理在阅读中遇到的生词。因此,能否正确推测词义就成为附带习得词汇的必要条件,也是众多相关研究中衡量附带词汇习得效果的重要指标。近二十年来,随着附带词汇习得的研究成为二语教学领域的研究热点,对于词义推测的研究也引起了很多学者的关注。
然而目前多数关于在阅读中推测词义的研究基本上都是重点探讨学习者在推测词义时所使用的策略或知识源,包括猜词策略的种类、不同学习者策略使用的特点、影响策略使用的因素,以及策略使用与学习效果的关系,却很少有人从推测的结果人手去分析二语学习者的猜词偏误。事实上,研究表明二语学习者从阅读中附带习得词汇的习得率并不高,由此可以推知学习者在推测词义时一定产生了大量的偏误。如果能对此类偏误进行分析无疑可以帮助研究者探求二语学习者从阅读中附带习得词汇过程中的问题和不足,并据此为语言教学提供相应的建议。然而,在现有研究中只有张江丽专门对汉语二语学习者的词义推测的结果进行了偏误分析,指出汉语二语学习者在推测词义的过程中会出现五种类型的偏误并讨论了学习者成功的猜词策略和失败的猜词策略。另外,朱湘燕、周健在研究汉语二语学习者在篇章阅读中推测词义的情况时也曾用部分篇幅探讨了引起猜词偏误的可能原因。他们的研究对我们了解学习者的猜词偏误很有帮助。然而,张江丽的研究是在无语境的条件下进行的,朱、周二人的研究是在篇章阅读的条件下进行的,目前还没有研究在句子和段落阅读的条件下对猜词结果进行偏误分析。因此,汉语二语学习者在句子阅读和段落阅读中推测词义会出现哪些偏误便成为本研究要回答的第一个研究问题。另外,张江丽和朱、周二人的研究都是通过分析学习者对目标词的书面释义去推测偏误产生的原因,由于缺少与学习者的面谈环节,这样的原因推测可能会不够准确。而对于偏误分析来说,研究的难点不在于对偏误类型的归纳总结,而在于对导致偏误的原因的探讨分析。因此为了准确探知导致偏误的原因,本研究的所有被试都参与了书面测试和个人面谈,以便从学习者对目标词的书面释义以及学习者的推测过程两个方面人手来回答第二个研究问题:导致汉语二语学习者在句子阅读和段落阅读中的猜词偏误的原因是什么?最后,前人研究证明目标词的语义透明度和文本的语境强度是影响阅读中附带词汇习得效果的主要因素,而学习者是否具有汉字文化圈的母语背景也被证明对其汉语学习颇有影响,但是已有的附带词汇习得研究多是研究这些因素对于猜测正确率的影响,没有更进一步地去分析这些因素对具体偏误的影响。因此,本研究要提出的第三个研究问题便是:目标词的语义透明度、文本的语境强度以及学习者的母语背景的差异是否会导致不同类型的偏误出现?
本文通过书面测试和个人面谈的形式对这些研究问题进行了深入的探讨,力求从一个不同的角度去了解学习者在阅读中习得词汇的情况,并进而对语言教学提供相应的建议。
一 研究方法
(一)被试
在中国内地大学学习汉语的29名留学生参与了本项研究。所有被试都已在中国学习汉语20个月左右,经所在大学的考试和授课老师的判定,所有被试的中文能力都在中级水平。其中15名学生来自属于汉字文化圈的日本和韩国,14名学生来自非汉字文化圈的欧美和中亚国家。所有被试在参加本次研究时都是全职在中国学习汉语的学生身份,被试年龄在18-36岁之间,其中男生15人,女生14人。
(二)目标词
邀请20名汉语母语者用李克特五点量表对100个候选词的语义透明度进行评分,1代表完全不透明,5代表完全透明。平均得分为4-5分的归为透明词,2.5-3.5分的为半透明词,1-2分的为不透明词。为了确保目标词都是被试不认识的词,研究者请2名高级汉语学习者帮忙查看词表,凡是高級学习者认识的词语都被删除。此步骤的原理是高级汉语学习者不认识的词,中级水平的学习者也很可能不认识。被试的授课老师也查看了词表并帮助删除了被试可能学过的词语。另外,为了排除母语的影响,1名从未学过汉语的日本人和2名从未学过汉语的韩国人帮助删除了普通日韩母语者可能认识的词语。最后,研究者确定了17个目标词。这些目标词全都是双音复合词,包括6个透明词,6个半透明词,和5个不透明词,所有的词都是汉语中传达日常生活概念的实词,且都是《汉语水平词汇与汉字等级大纲》中的丙级、丁级词或者超纲词。组成这些词的字都是《汉语水平词汇与汉字等级大纲》中的甲级或者乙级字,并且经过授课老师确认都是被试学过的字。
(三)阅读材料
4名汉语母语者(分别具有高中、本科、硕士、博士学历)帮助检查了阅读材料以保证语料自然流畅,符合汉语表达习惯。被试的中文授课老师则负责检查阅读材料的难度是否合适,凡是授课老师认为对被试而言太难或太容易的语料都被删除。为了考察学习者在不同语境强度的文本阅读中推测具有不同语义透明度的目标词时所产生的偏误有何不同,本研究提供给被试的阅读材料包括句子和段落两个部分。句子阅读部分由彼此独立的单个句子组成。段落阅读部分由彼此独立的段落组成,每个段落都包含3至4个句子。选定的17个目标词在句子和段落中各出现一次,每个目标词都用黑体和下划线加以标识。且句子文本所表达的主题思想和段落文本所表达的主题思想基本一致。段落文本和句子文本之间的主要差别是所有的段落中都增添了为促进理解目标词而设计的新的语境线索。例如:
句子:他一肚子墨水呢!
段落:你知道王文吗?这个问题还是去问问他吧,他一肚子墨水,知道的很多呢!
如上例所示,句子中没有有助于推测目标词“墨水”的直接线索。相比而言,段落中则包含了较直接的线索,“知道的很多呢”。
(四)数据收集过程
数据收集分为三个步骤。首先,被试阅读句子文本并用母语或汉语写出句子里目标词的意思。然后,被试阅读段落同样用母语或汉语写出段落里目标词的意思。最后,在书面测试完成后一周之內,研究者对全部被试进行了个人面谈,以探求导致被试猜词偏误的根本原因。在面谈中,研究者主要询问了被试两个问题,即“这个词是什么意思”和“你是怎么猜出词义的”。所有面谈都被录音并转写成文字。
二 数据分析
(一)猜词偏误类型
两名语言学专业毕业的经验丰富的汉语教师对被试的书面答案以及面谈文稿进行了评定归类。在评定过程中,如果有不一致的地方由两人讨论达成一致。经过评定,除去被试由于完全不能猜测而未填写的137处空白之外,共发现666例、6大类偏误,包括语素层面的偏误、词语层面的偏误、句子层面的偏误、语境层面的偏误、母语层面的偏误以及与其他已有知识有关的偏误。
1.语素层面的偏误
指由于学习者在语素方面知识的缺失而产生的偏误。(1)只根据一个语素来推测整词词义。具体表现为用单个语素来解释整词的词义,通常是由于学习者不熟悉目标词的所有构成语素,所以只能根据熟悉的语素来推测整词词义。例如:把“喜讯”解释为“喜欢”,是用“喜”这个单个语素去解释“喜讯”这个词的意义。把“认同”解释为“相同”,则是用“同”这个单个语素去解释整词的意义。(2)语素多义引起的偏误。由于汉语语素具有多义性,语素具体应该作何解释需要依据词语内部的语境来决定。学习者常常因为不熟悉多义语素的所有语素义而无法做出正确的判断。例如:把“败坏”解释为“失败”,就是因为不清楚“败”这个语素除了有“失败”的意义,还有“毁坏”的意义。(3)认错字形相似的语素。学习者混同了字形相似的语素因而造成偏误。例如:把“设想”解释为“没有想到的”,就是因为被试混同了“设”和“没”这两个字形相似的语素。把“从容”解释为“好客”,则是混同了“容”和“客”这两个语素。(4)过于依赖语境,没有利用语素。学习者仅根据文本语境推测词义,虽然所推测的词义在文本中意思也可以说通,但是却是错误的词义。例如:在读到“人们常常会根据你的谈吐来判断你的社会地位”这句话时,有的被试认为“谈吐”是“你留给别人的第一印象”。这个解释虽然很符合文本的语境,但是却不是正确的词义。如果学习者仔细看看目标词的语素,就会发现“谈”(有言字旁)和“吐”(有口字旁)都和说话有关,和“第一印象”却没有直接的关系。
2.词语层面的偏误
指由于学习者对汉语词语方面的知识掌握得不够牢靠而引起的偏误。
(1)不能正确推测词的比喻义。这种偏误有两种情况。一种是被试根本没有意识到目标词有比喻义,完全根据表面字义去解释。例如:在读了“他一肚子墨水,知道的很多呢!”这个句子以后,认为“墨水”是“一种水”。另一种情况是被试意识到目标词有比喻义,但是没有正确地推测出比喻义。例如:认为“墨水”的意思是“坏人”,因为被试觉得“墨水很黑,黑色有坏的意思”。
(2)错误地认为具有相同语素的词就是同义词。例如:一个被试在接受访谈时解释自己的推测时曾说,因为“宽容”和“从容”都有“容”,所以他认为“从容”的意思就是“宽容”。类似的还有认为“划算”和“计算”同义,“知趣”和“兴趣”同义等。
(3)不能区分目标词和其近义词之间的差异。被试用目标词的近义词来解释目标词。例如:把“抱负”解释为“目的”,虽然意思相近,但是不够准确,没能区分开一般的目的和远大的志向之间的差异。又如,被试把“周折”解释为“问题”。在面谈时,当研究者提醒被试是否解释为“困难”更为合适时,被试说:“我觉得‘问题和‘困难的意思是一样的”。
(4)由词的多义引起的偏误。现代汉语的词语常常有多个义项,有些被试不能结合文本语境推测出正确的义项。例如:在读完“他上学的时候就不检点,常常偷同学的东西”这个句子以后,有的被试认为“检点”是“查点”的意思。虽然“查点”也是“检点”的一个义项,但在这里正确的解释却是该词的另一个义项,“注意约束(自己的言语行为)”。
3.句子层面的偏误
是指学习者因为对句子的结构、成分以及语法功能不熟悉而产生的偏误。
(1)不清楚词在句中的词性和语法功能。由于被试在推测中只考虑了目标词的词义是否符合文本语境,没有考虑到目标词在句中所兼具的语法功能,所以有时会出现搞错目标词词性的偏误。例如:被试在读了“很多数据证实海水中含有黄金,所以有人就设想从海水里提取黄金”这个句子之后,认为“设想”(动词)的意思是“想法”(名词)。这个偏误就是把动词理解成为名词的偏误。
(2)由否定词引起的偏误。例如:把“一些父母可能会不认同这个观点”中的“认同”解释为“不同意”。产生这类偏误的被试实际上是理解目标词的意义的,但是因为句子的意思是说一些父母不同意这个观点,所以他们在解释目标词的意义时头脑中就保留了句子的意思,却没有把否定的意义去掉。这种类型的偏误虽说很大可能是由于粗心引起的,但是也从侧面反映了被试阅读汉语文本的技能还是不够熟练。
(3)由错误的句法知识引起的偏误。例如:在谈到如何推测“丢弃”(“如果姑娘把花丢弃,就表示拒绝”)的词义时,一位被试说:“丢是丢掉的意思,弃是放弃的意思,还有这个句子是把字句,所以我猜‘丢弃是‘掉下来的意思,因为把字句是表示主语不是故意去做某件事。”事实上,把字句强调的是动作发出者对宾语作出了某种处置,把字句的动作发出者一定是有意地去做某个动作的。很明显,这位被试记错了把字句的语法意义,从而导致了偏误。
4.语境层面的偏误
这里的语境是指目标词所处的上下文(包括相邻的字词、短语、句子和段落)所形成的语言环境。语境中含有的可以帮助学习者理解目标词意义的信息即为语境线索,而本文中的语境层面的偏误是指与语境线索有关的偏误。本研究发现被试在语境层面的偏误有三大类,一类是由于文本中的语境线索不足而产生的偏误,一类是被试没有利用语境线索而产生的偏误,第三类是被试没有正确利用语境线索而产生的偏误。
(1)语境线索不足而产生的偏误。例如:在读了“他现在已经没有什么抱负”这个句子之后,有的被试认为“抱负”的意思是“拥有的东西”。这个解释虽然不正确,但是放在文本中意思也是说得通的。很明显,这种偏误应该归因于文本中的线索不够充分。
(2)由于没有利用语境线索而产生的偏误。a.被试不能看出直接的语境线索。文本中明明有很直接的线索,被试却没有意识到,因而造成偏误。例如:“求职者面试时,除了注意说话的方式和用词外,态度一定要从容。不要紧张。”是段落文本中的一个句子。这段文本比相对应的句子文本多了一个推测目标词“从容”的直接线索——“不要紧张”。但是有的被试却没有注意到这个线索,认为“从容”应该解释为“认真”,因为他认为“人们应该认真对待求职”。b.被试过于依赖语素,没有利用语境线索。例如:推测“周折”(“经历了这么多的周折,老张终于和家人团聚了”)的意思是“周末降价”,就是完全依据语素的意义来推测,没有把目标词放到语境中去进行核实的结果。
(3)由于没有正确利用语境线索而产生的偏误。a.被试注意到关键的语境线索,却不能正确猜测出词义。有的被试虽然注意到了关键的语境线索,但是却不认为这个线索是关键线索。例如:在读到段落文本中的句子,“经历了这么多的周折和不顺,老张终于和家人团聚了”时,有的被试注意到这个句子比相应的句子文本多了“不顺”,而且该被试也知道“不顺”的意思是“困难”,但是依然认为“周折”的意思是“和家人分开”。b.被试只提取部分语境线索来猜测。例如:“从200立方公里的海水中只能捞到1公斤黄金,很不划算”。如果要在这个句子中推测“划算”的意思,就必须要读懂“从200立方公里的海水中只能捞到1公斤黄金”所表达的意思。可是,有的被试却只看到“1公斤黄金”,继而猜测“划算”是贵的意思,因为该被试认为1公斤黄金非常贵重。c.被试提取了错误的语境线索。例如:“人们常常会根据你的谈吐、态度来判断你的能力、社会地位、受教育的程度。所以,求职者面试时,除了注意说话的方式和用词外,态度一定要从容。不要紧张。”在这个文本中,“说话的方式和用词”是有助于推测目标词“谈吐”的语境线索,但是被试却依据文中的“判断”一词而推测“谈吐”的意思是“意见、评价”。d.被试被语境线索误导。例如:“如果姑娘把花丢弃不要,就表示拒绝”。在这个句子里,“不要”是有助于推测目标词“丢弃”的语境线索。可是由于“就表示”这个结构常常在文本中承担解释的功能,因此产生了误导,使某些被试认为“丢弃”是拒绝的意思。
5.母语层面的偏误
母语层面的偏误是由于被试母语的负迁移而造成的偏误,本研究中几乎全部的母语层面的偏误都是来自日韩学生。
(1)受到母语中同形汉字词的负面影响。由于历史原因,日语和韩语受汉字的影响颇深,至今这两种语言还在使用某些与汉语同形的汉字词。这些词如果和汉语中的词同形同义,就会对日韩学生学习汉语形成正面积极的影响。但是如果只是同形却不同义,就极易造成日韩学生汉语学习中的负迁移。例如:“有的孩子的哭闹就有名堂——我一哭闹,你就得百事依我”,这个句子中的目标词“名堂”是至今仍在日语和韩语中使用的汉字词,意思分别是“有名的场所或寺庙”和“好地方”。对母语的依赖使很多日韩被试直接推测“名堂”的意思是“有名的场所”或“好地方”。相反,不能求助母语的非日韩被试经过多方努力反而能推测出比较正确的答案。
(2)认错近音词。韩语中还有很多与汉语词读音很相近的词语。例如:韩语中的“报复”的发音和汉语中的“抱负”非常相近,因此就有韩国被试推测“抱负”是报复的意思。这也是母语负迁移的表现。
6.与其他已有知识有关的偏误
(1)不准确的已有知识引起的偏误。例如:有一位被试觉得自己以前见过“抱负”这个词,记得好像是责任的意思,于是就推测“抱负”的词义是责任。还有一位被試觉得自己以前见过“败坏”,记得是腐败的意思,可惜他们的已有知识都不准确。
(2)错误套用自己的经验或文外知识。例如:在读了“小伙子知趣地离开了”这个句子之后,有的被试说,“我觉得知趣在这里是高兴的意思,因为我想自己在完成学业离开这里的时候会很高兴,我想他离开的时候也会很高兴”。因为句子文本没有为被试提供小伙子离开时的情境,被试便自己联想到毕业以后高高兴兴地回国这一熟悉的场景,从而推测“知趣”是高兴的意思。很明显,这位被试在这里错误地套用了自己的经验。
(二)数据统计和分析
通过上文的分析,可以看出汉语学习者在阅读中推测生词词义的偏误情况错综复杂。作者统计了所收集到的实例,总计发现偏误666例(表1)。其中语境层面的偏误最多,有275例,占比高达41.29%。语素层面的偏误254例,占比38.14%,词语层面的偏误55例(8.26%),句子层面的偏误43例(6.46%),与其他已有知识有关的偏误23例(3.45%),母语层面的偏误16例(2.4%)。在偏误次类型方面,偏误频次超过总频次10%的包括:只根据一个语素来推测整词词义132例(19.82%),语境线索不足而产生的偏误129例(19.37%),语素多义引起的偏误75例(11.26%),以及被试不能看出直接的语境线索69例(10.36%)。可以看出,偏误主要出现在语境层面和语素层面。
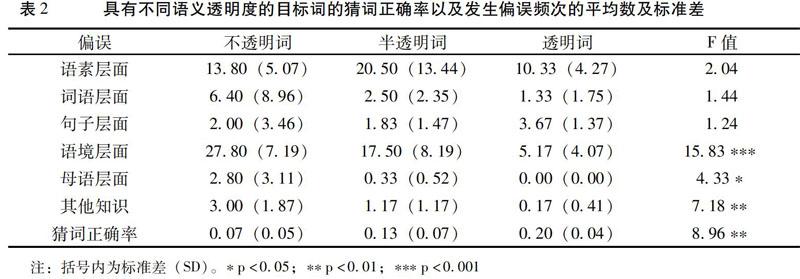
(三)偏误原因的透明度因素分析
根据目标词的语义透明度把目标词分为三组(不透明词,半透明词,透明词),利用SPSS25统计软件进行单因素方差分析(One-way ANOVA)的结果如表2所示:透明度显著影响到被试的猜词正确率(F(2,14)=8.96,p<0.01),即透明度越低的词越容易出现猜词偏误。而语境层面(F(2,14)=15.83,p<0.001)、母语层面(F(2,14)=4.33,p<0.05)以及与其他已有知识有关(F(2,14)=7.18,p<0.01)的偏误频次也都随着目标词语义透明度的下降而显著增多,也就是说被试在推测透明度较低的目标词词义时所发生的与语境、母语以及与其他已有知识有关的偏误显著高于透明度较高的目标词。说明被试在推测透明度较低的目标词时,由于来自词语内部的信息不足,所以更多地依赖语境、母语以及其他知识来推测词义并产生相应层面的偏误。与此同时,数据分析结果也显示被试在句子层面所产生的偏误频次并没有随着目标词语义透明度的下降而出现显著的变化,也就是说当被试更多地依赖语境去推测词义时,并没有相应显著地产生更多句子层面的偏误。这主要是因为本研究对于句子层面偏误的界定主要体现在语法功能方面,而对于语境层面偏误的界定则主要体现在语义方面。这个结果说明被试在推测词义时主要是从文本中提取语义方面的信息,而较少进行语法分析。另外,本研究采用的阅读材料都是与被试的汉语水平相适合的文本,文本中没有对被试而言太难的句法结构。这也是被试在句子层面出现偏误较少的原因之一。
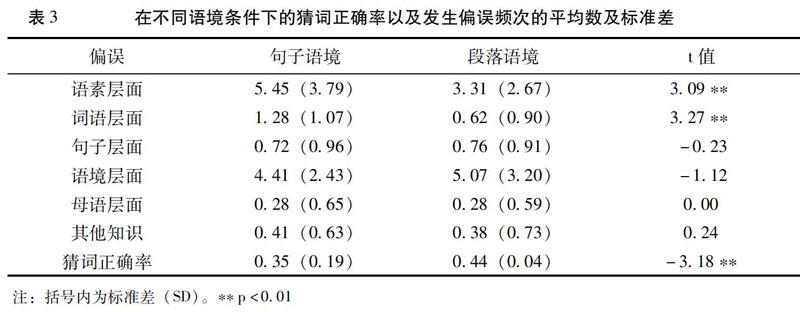
(四)偏误原因的语境因素分析
根据文本的语境强度把文本分为两组(句子语境,段落语境),利用SPSS 25统计软件进行配对样本t检验(paired samples t-test)的结果如表3所示:被试在段落语境条件下的猜词正确率显著高于在句子语境条件下的猜词正确率(t(28)=-3.18,p<0.01)。在偏误类型方面,被试在句子语境条件下所产生的语素层面的偏误(t(28)=3.09,p<0.01)和词语层面的偏误(t(28)=3.27,p<0.01)均显著多于段落语境条件下的同类偏误。说明被试在阅读句子文本时,由于语境线索的缺乏,更多依赖目标词本身的线索来推测词义并产生相应层面的偏误。
(五)偏误原因的母语背景因素分析
根据被试的母语背景把被试分为两组(日韩被试,非日韩被试)。利用SPSS 25统计软件进行独立样本t检验(independent samples t test)的结果如表4所示:日韩组和非日韩组在猜词的正确率方面没有显著差异,两组被试所出现偏误的频次在多数层面上都大致相当,但是日韩组在母语层面出现的偏误远多于非日韩组(t(14.997)=2.41,p<0.05)。通过面谈,作者了解到所有的日韩被试都认为自己的母语对学习汉语很有帮助,并且他们在推测词义时都不同程度地运用了母语知识。日韩被试的母语知识在推测透明度高的目标词时多数起到了正面积极的作用,但是在推测透明度较低的目标词时就不太奏效并产生了母语层面的偏误。而非日韩被试则认为自己的母语对学习汉语没有什么帮助,与之相应,只有1名非日韩被试在推测词义时使用了1次母语知识。因此非日韩被试在母语层面的偏误几乎为零。
(六)引起偏误的原因
经过上文的分析,作者认为造成汉语二语学习者词语推测偏误的原因可以分为主观原因和客观原因两大类。
1.主观原因
首先,本研究的结果显示中级水平的汉语二语学习者在语素、词语、句子乃至段落方面的汉语能力都有欠缺。在语素方面,学习者对于已经学过的语素还不够熟悉,常常会混同字形相近的语素。例如把“设”和“没”混同,把“容”和“客”混同。在认错字的情况下,就不可避免地会出现词义推测的偏误。另外,学习者对于语素知识的掌握很不全面。常用的语素往往有多个语素义,但是很多学习者只知道一个语素义,比如只知道“喜”有喜欢的意思,却不知道“喜”还有高兴的意思。学习者词语方面的知识也很欠缺。部分学习者不能区分近义词之间的差异,把近义词与同义词相混同。还有部分学习者不能依据词的基本义去推测词的引申义和比喻义,从而导致偏误。在句子层面,有的学习者对于某些基本句式的掌握还不够牢靠,以致于犯了一些基础的错误,比如搞错把字句的语法功能,在推测词义时带入了句中的否定词等。还有部分学习者在推测词义时搞错了目标词的词性,这种偏误也是对句子结构和成分不够熟悉的表现。
其次,学习者不能充分地利用文本所提供的语境线索。多数学习者只能有效利用直接的线索、离目标词距离近的线索。线索的距离一旦与目标词相隔一个句子的距离就很可能被学习者所忽略。即使是很直接的线索,有时也不会被学习者捕捉到。总而言之,学习者利用文本线索的能力亟待提高。
另外,前人研究认为如果能把语素线索和语境线索结合使用就能有效提高猜词的正确率。但是很多学习者没能把两者结合使用。有的学习者只根据语素义推测词义,造成很多放在文本中根本说不通的偏误。有的学习者只依赖语境推测,虽然所推测的词义适合文本中的文义,却不是正确的词义。
最后,日韩学习者有时过于依赖母语,常常只根据母语中汉字的字义或词语的读音来推测目标词的词义,却不用文本语境进行验证,因而导致了一些偏误。
2.客观原因
首先,目标词的语义透明度是导致某些猜词偏误的客观原因之一。本研究发现目标词的语义透明度会显著影响猜词偏误的频次和种类。如果阅读文本中的目标词的透明度较低,学习者在推测词义时就会产生大量的偏误,而且学习者在推测透明度较低的目标词时更易产生语境、母语层面以及与其他已有知识有关的偏误。
其次,本研究的结果显示在句子语境条件下出现的偏误显著多于段落语境,而且更易产生语素和词语层面的偏误。另外本研究发现有19.37%的偏误是因为语境线索不足引起的。这些都说明文本的语境强度也是导致某些偏误的客观原因之一。
四 对教学的启示
本研究尝试从偏误分析的角度考察汉语学习者在阅读中附带习得词汇的情况。为了更全面地反映实际情况,本研究收集了不同母语背景的学习者在不同文本语境条件下推测不同语义透明度的生词词义时所产生的偏误。根据研究结果,作者提出下列建议,希望可以对今后的语言教学有所助益。
首先,要在平时的字词教学中培养学生从广度和深度推测词义的能力。对于常用的语素要多介绍几种语素义并给出例词。比如,在教“喜欢”的“喜”的时候,可以同时给出“喜”的其他语素义,比如“高兴”“可庆贺的”等,让学生体会其中的差异和联系并进行组词的练习。由一词带出多词,这样可以增强学生在广度层面推测词义的能力。另一方面,对于具有引申义、比喻义的词语,教师可以先给出字词的基本义,然后引导学生自己去推导引申义、比喻义,并给出例句。这样就可以由词的一义带出多义,增强学生在深度层面推测词义的能力。与此同时,也要加强基本功的训练。在教学中对于字形相近的汉字、意义相近的词语要特别强调注意区分。对于基本常用的句式要反复操练并注意培养学生分析句子成分的能力。
其次,在阅读教学中多训练学生寻找语境线索的能力,不仅要能确定近距离的、直接的线索,还要培养学生利用远距离、间接线索的能力。比如,在教学中可以先让学生猜测词义,然后再由教师组织学生一起讨论是如何猜出词义的,最后由教师归纳总结并对学生指出线索与目标词在文本中的联系方式与特点。
再次,训练学生在推测词义时把多种方式结合使用,因为这样可以避免单方面过度依赖语素或语境,大大提高猜测的正确率。多种推测方式并用还可以有效防止日韩学生母语的负迁移,帮助验证那些基于母语的推测是否正确。
最后,应该尽量减少导致学生偏误的客观原因。比如,在编制初中级阅读材料时尽量为透明度低的生词设计一些较直接的语境线索,也可以对线索进行标注以帮助学习者正确提取线索从而顺利推测出词义。
五 本研究的不足之处
为了确保目标词的代表性,本研究实行了严格的选词步骤,经过汉语母语者、高级汉语学习者、授课老师、日韩母语者的层层筛选,最终选定了17个目标词,包括6个透明词,6个半透明词和5个不透明词。由于各类词的数量不是完全相等,在统计分析时可能会由于权重不同而对结果产生轻微影响。不过由于各类词数量相差不大(只有1个之差),影响应该在可控范围之内。
另外,为了充分利用样本数量并消除被试个体差异对结果的影响,本研究采用了重复测量设计,即要求所有参与者依次完成句子语境和段落语境中的词义推测测试。采用重复测量设计的一个潜在后果是顺序效应和重复效应可能会有助于被试在段落语境中取得更好表现,但是这种影响应该是有限的。因为本研究中针对目标词的测量不是阅读后对被试的突然测试,而是阅读时对目标词意义的推断。阅读后的突然测试通常是脱离阅读材料的词义测试,被试在做词义测试时不能再看阅读材料。在这种情形下,顺序效应和重复效应可能会对测试结果产生一定的影响。然而,在本研究中被試的阅读和推测词义是同步进行的,且被试在句子阅读阶段和段落阅读阶段都没有被限定时间,以确保被试可以在每个阶段都能最大限度地推测出更多、更准确的词义。因此,重复测量设计通常具有的顺序效应和重复效应在本研究中会比较有限。
【责任编辑 陈雷】
