基于k-means++的高炉铁水硅含量数据优选方法
2020-08-19尹林子关羽吟蒋朝辉许雪梅
尹林子,关羽吟,蒋朝辉,许雪梅
(1 中南大学物理与电子学院,湖南长沙410012; 2 中南大学自动化学院,湖南长沙410083)
引 言
铁水硅含量预测是高炉优化控制的关键之一,吸引了大量研究者的关注,目前研究者们多采用数据驱动的思想[1-2],建立高炉铁水硅含量预测模型,常见的方法包括支持向量机[3-5]、神经网络[6-10]、非线性时间序列[11-12]、极限学习机[13-15]等。这些模型对训练数据集质量均有较高的要求,然而,由于高炉数据采集环境恶劣,部分参数现场取样离线化验等原因,获得的历史数据,尤其是硅含量数据中,存在严重的异常、缺失、不均衡等问题,导致预测模型训练困难,预测结果易于出现过拟合或不稳定现象。因此,历史数据的优化预处理,是铁水硅含量预测建模的首要问题。
由于高炉冶炼的多尺度特征,不同参数的采集周期并不一致,需要锚定周期(本文称为样本周期)才能建立输入变量与硅含量之间的映射关系,以便于训练模型。然而受工艺限制,硅含量数据的取样以及化验均需要人工处理,导致每个样本周期内的硅含量数据并不均衡且噪声严重,具体表现为:在部分样本周期内,硅含量数据可能会比较多且波动较大。此时,难以合理确定输入变量与硅含量之间的关联。
传统的数据预处理主要包括异常值检测与缺失值补全。其中,异常值检测方法有马氏距离[16-17]、3σ准则[18]、箱型图[19]等;缺失值补全方法有均值插补法[20]、回归拟合[21-22]、多重插补[23-24]等。由于高炉数据具有多采样率特征,因此,现有的研究大都使用插补法或者回归拟合的方式进行处理[25-26]。宋菁华[27]和Chu 等[28]使用了包样分析法,在出铁过程中依次采集两个硅含量值,取其算术平均值;刘敏[29]对各输入量以30 min 为采样间隔时间段对数据进行融合,即计算30 min内数据的算术平均值。吴金花[21]采用不等时距灰色模型用于拟合整点数据。赵哲等[22]建立AR 模型对缺失值进行补值。虽然均值插补法对均匀采样的时间序列数据是有效的,但对于非均匀时间间隔的数据,其时间序列的数据量少而不宜采用[30]。此外,当样本周期内存在多个硅含量值且波动较大时,均值法较为保守,易受噪声干扰使硅含量偏离正确范围。回归拟合法容易人为增加线性关系,对后续的预测造成干扰。多重插补法期望缺失数据是随机缺失,因而在高炉数据中也鲜有应用。这些方法在异常和缺失问题的处理上各有优缺点,但并不足以解决所有高炉历史数据中存在的问题。
为此,本文提出一种基于k-means++的高炉铁水硅含量数据优选方法,并通过建立基于多层感知器和LSTM 深度学习模型来验证数据集优选效果。该方法首先利用k-means++算法将样本聚类,用于表示不同炉况特征;然后统计各簇样本对应的硅含量的出现频次,获得频数直方图;在此基础上,确定高频区间,为样本遴选与之关联的最优硅含量值,实现样本与硅含量的关联并减少噪声干扰。为验证本文所提方法的有效性,分别建立基于多层感知器和LSTM 深度学习模型来验证数据集优选效果。
1 高炉数据分析
高炉冶炼过程中的数据主要分为两类,一类为众多传感器的实时采集数据,因采集周期不同,可归于整点时刻记录;另一类为硅含量数据,由检测人员现场采集并离线化验。
在数据采集过程中,硅含量的记录易受人工影响,由于换班、某些时段铁水未及时取样或者化验人员未到岗等因素,常积压大量样本在后续时段集中化验;或因管理不善、化验人员疏忽职守等因素,导致硅含量值缺失、测量误差较大等。由于上述人为因素干扰,硅含量历史数据出现缺失、不均衡现象,且在部分样本周期内噪声较大,引起硅含量值大幅波动。
针对实例中全体硅含量数据进行统计分析。
(1)硅含量数据不均衡问题如表1 所示。同周期内含有两个及以上硅含量值的样本在总体中占比为64.47%,还有10.63%的周期内没有对应的硅含量数据。由此可见,历史硅含量数据存在严重的不均衡现象,这对于输入变量与硅含量的关联造成了极大的阻碍。
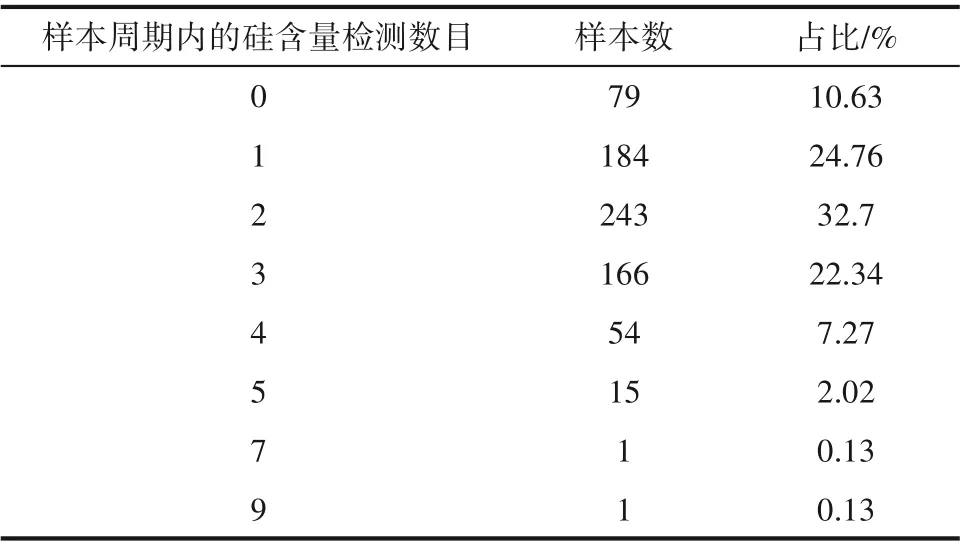
表1 样本周期内不同硅含量值数量在总体中的占比Table 1 The proportion of different silicon contents during the sample period
(2)硅含量的波动情况如图1所示,其中横坐标为样本周期,纵坐标为硅含量的均方差,从图中可以看出,在总计744个样本周期中,均方差最大值可达0.18,平均值为0.03。

图1 各样本周期内硅含量值均方差Fig.1 MSE of silicon content for each sample period
当样本周期内数值波动较大时,均值法易使不明显噪声混入结果,所得关联硅含量值不准确,影响模型预测效果。
为解决上述问题的影响,本文提出了一种“kmeans++优选法”数据优选方法。由于输入变量与硅含量均是炉况的反映,相同炉况下的样本,应该具有相似的输入变量参数和硅含量值,因此,可通过聚类方法实现炉况的分割,并通过统计不同炉况下的硅含量范围,确定其高频区间,从而选取更合理的关联硅含量值。
2 k-means++简介
k-means 是一种经典的聚类算法,其算法思想为:给定包含X 个d 维数据的数据集M ={m1,m2,m3,…,mn}(mi∈Rd),若要将给定的数据集分成k个簇,则随机初始化k个不同的中心点。每个分组为一个簇Ci(1 <i <k),每个簇Ci都有一个中心Oi,迭代交换两个不同的步骤直到收敛。
改进的k-means++算法在选取聚类中心时,假定已经选取了i 个中心点,在选取第i+1 个中心点时,选择距离当前中心点Oi尽可能远的第i+1 个中心点Oi+1。在选取第一个中心点O1时同样通过随机初始化的方法。这使得不同的聚类中心点分布在相差较远的位置,从而降低簇间相似度,使算法收敛速度和聚类精度都得到提升[31]。
k-means++算法步骤如下:
(1)从样本U(x)中随机选取一个样本作为初始聚类中心O1;

(6)重复步骤(4)和步骤(5)直到聚类中心的位置不再变化。
总地来说,k-means++算法是从没有标注的输入中抽取信息,找出其中显著的模式、规律或集群,以指定的相似度标准将特征形态相同或近似的样本划分在一个类别中,而不相似的样本划分在不同的类别中。
3 基于k-means++的硅含量数据优选法
硅含量是高炉热状态的表征,而各输入变量综合反映高炉热状态,相同的炉况会对应相近的硅含量值波动范围[32]。因此,在铁水输入变量没有关联的硅含量值时,本文将通过k-means++算法聚类,实现炉况分类,进而关联合适的硅含量值。
3.1 “k-means++优选法”流程
“k-means++优选法”设计思路如图2 所示。输入变量样本数据集记为U(x)={x1, x2, …, xn},其中xi(1<i<n)为样本向量,ti表示样本xi的记录时间,硅含量数据集为V(y)={y1,y2, …,ym},sj(1<j<m)表示硅含量记录时间。当ti与sj相差低于一个样本周期时,认为xi与yj属于同一样本周期。
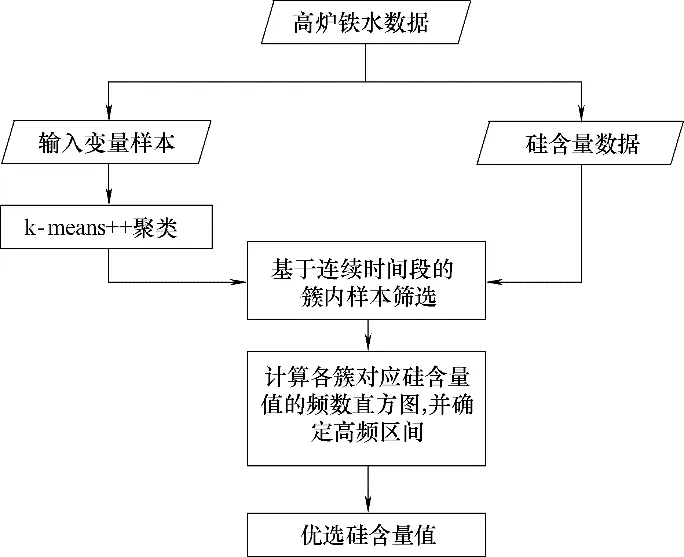
图2 “k-means++优选法”设计思路框图Fig.2 Flow chart of“k-means++optimal selecting method”
(1)k-means++聚类
基于k-means++算法聚类样本,以Euclidean Metric 作为距离度量聚类样本,将具有相似特征的样本聚为一簇,从而区分不同炉况,具体步骤为:
①采用k-means++算法对样本聚类U={C1,C2,…,Ck};
②若某一簇中包含样本数目小于总样本数的2%,则视为异常样本(即少量的离群簇),删除该异常簇,返回步骤①,否则,输出聚类结果。
(2)基于连续时间段的簇内样本筛选
由于各簇中的样本记录时间有间断,为避免聚类误差造成的影响,从中选择记录时间连续的样本,作为该簇的代表。因此,对于每一簇Ci,按如下步骤进行处理:
①排序簇Ci中所有样本的记录时间,获得该簇的样本时间序列T={t1,t2,…,tn};
②将序列T中的记录时间划分为不同的连续时间子序列,T={T1,T2,…,Tm},其中,Ti={tl,tl+1,…,tl+p},Ti的持续时间记为L(Ti)=tl+p-tl;

④若占比ρ <0.6,缩减持续时间标准,令α =α - 1 并返回步骤③,否则,将所有持续时间小于α的子序列从T 中删除,并输出T,T 中记录时间所指的样本即为筛选出的该簇代表样本。
(3)计算各簇对应硅含量值的频数直方图,并确定高频区间
分簇样本的同时,硅含量也间接地被划分为不同的类别,为了获取每簇硅含量值的波动范围,绘制硅含量的频数分布直方图,据此统计硅含量数值区间,将最高频数值区间称之为“高频区间”,具体实现步骤如下:
①从硅含量数据中,筛选出记录时间属于连续时间序列T 的硅含量,代表该簇样本对应的硅含量值,用D(y)表示,D(y)={yi∈V(y)|si∈T};
②绘制D(y)的频数分布直方图,统计其中频数最高的数据区间和频数次高的数据区间,分别定义为“第一高频区间”和“第二高频区间”。
(4)优选硅含量值
以“高频区间”作为参考,为每个样本选取最优硅含量值,即选择对应时段内属于或接近其高频区间的硅含量值;在遴选过程中遵循“不在先行周期内选择,不重复选择”的原则,即当某样本周期ti内硅含量缺失时,仅从后续样本周期ti+1内选择填补,而该填补值不再作为ti+1样本周期内的候选值。据此,实现输入变量与硅含量的关联与硅含量除噪。硅含量优选策略如下。
将与样本xi属于同一样本周期ti的硅含量yj的数目,记为a。
当a=0,则选择ti+1中属于高频区间的yj+1,用于补全缺失;
当a=1,yj与xi关联;
当a>1 且存在一个或多个yj均属于高频区间,则选择sj较小的yj与xi关联;
当a>1 且yj均不属于高频区间,则选择更接近该高频区间中点的yj值与xi关联。
3.2 “k-means++优选法”的应用
采用“k-means++优选法”处理历史数据。选取某钢铁厂2650 m3高炉,2017 年10 月1 日0 时至10月31 日23 时数据,样本周期为1 h,历史数据共有27 个输入变量,包括富氧量、鼓风动能、冷风流量、理论燃烧温度等,归于整点记录,共744个输入变量样本和1478个硅含量样本。
(1)聚类:首先确定聚类数目,簇内对象分散程度越小,簇间的距离越大,聚类效果越好[33],但簇数过少会影响聚类效果,簇数过多将难以区分类别,将样本聚类成k簇,多次实验,计算其聚类结果的轮廓系数,最终选取轮廓系数较大的k=5 进行聚类。对输入变量样本首次聚类得到图3(横纵坐标为多维样本映射在二维空间中的位置坐标)所示结果,显然存在少量的离群值,通过反复剔除离群值和重新聚类,得到图4所示的样本聚类结果。

图3 输入变量首次k-means++聚类Fig.3 Clusters of input variables by k-means++for the first time
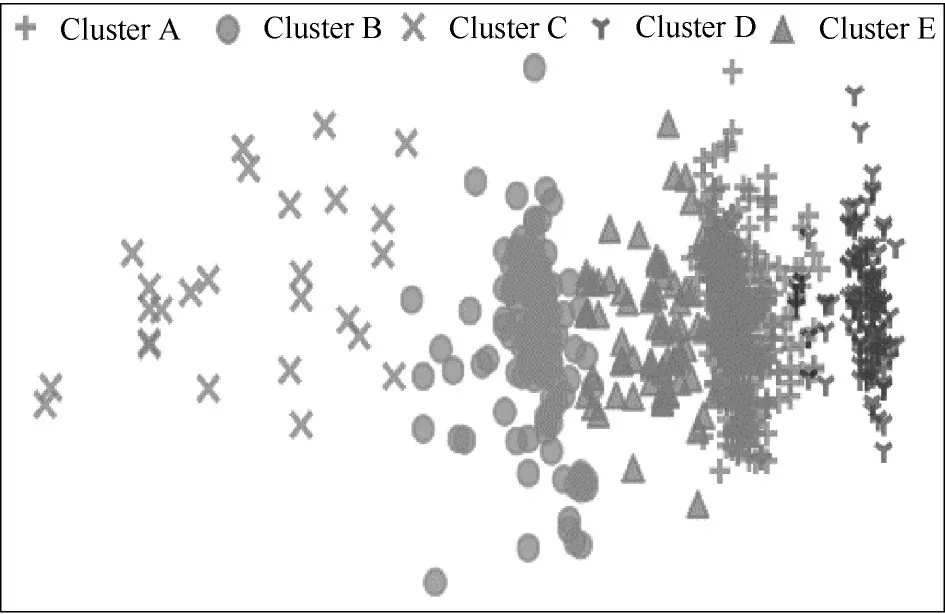
图4 剔除异常簇k-means++聚类Fig.4 k-means++results after removing abnormal clusters
(2)统计各簇代表时间段:将聚类结果分别标记 为Cluster A、Cluster B、Cluster C、Cluster D 和Cluster E,依次统计各簇样本连续时间序列,统计结果如表2所示。
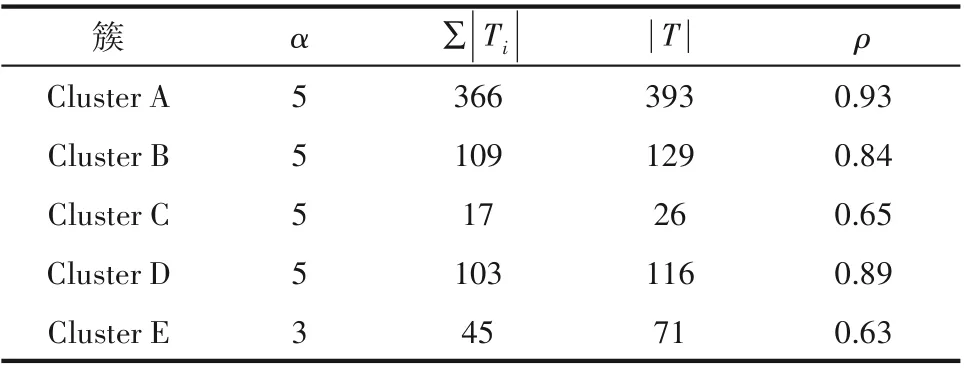
表2 各簇统计数据Table 2 Statistics of each cluster
(3)定位高频区间:分析各簇代表时段内的硅含量值,分别绘制频数直方图,如图5 所示,其中纵坐标为频数,横坐标为硅含量值。各簇的“高频区间”依次为([0.536,0.605],[0.467,0.536]),([0.516,0.58],[0.452,0.516]),([0.301,0.342],[0.342,0.383]),([0.49,0.528],[0.414,0.452]),([0.458,0.534],[0.382,0.458])。
(4)匹配唯一硅含量值:表3所示为各簇样本周期内不同硅含量值数量在各簇总样本数的占比,依照样本的记录时间顺序,为其匹配对应硅含量值。
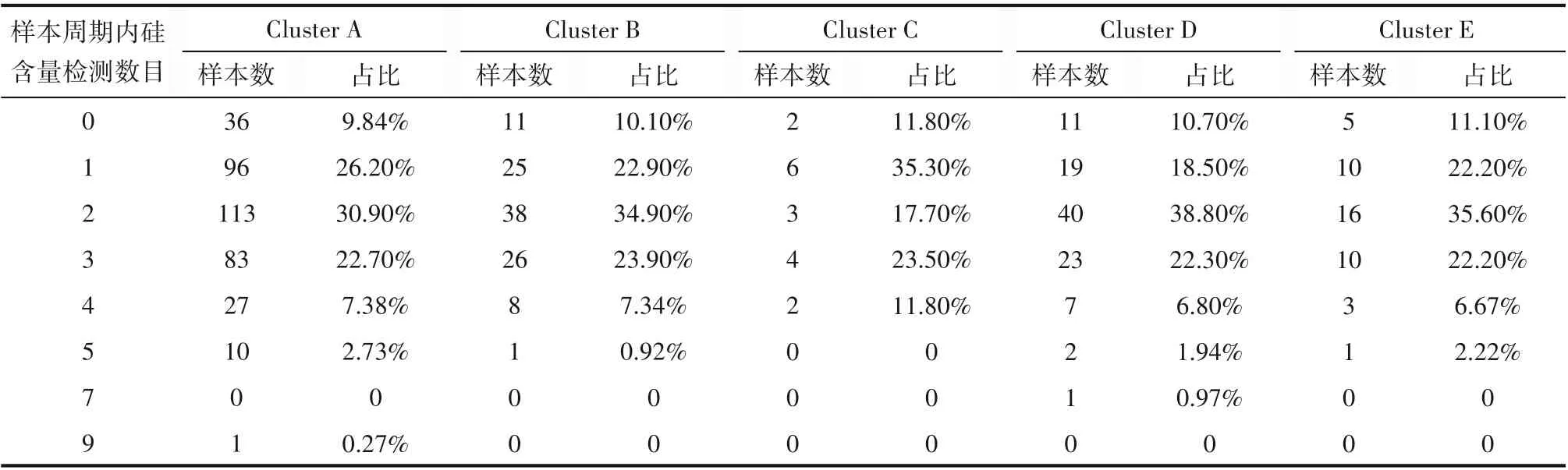
表3 各簇不同样本周期内硅含量数量在簇内总样本数的占比Table 3 Proportion of silicon content of each cluster in different sample periods
首先确定各样本所属的簇,以该簇的“高频区间”作为标准,遵循“不在先行周期内选择,不重复选择”的原则,优选每个样本对应的硅含量值。经统计,在1478 个硅含量值中,共有731 个值处于高频区间中,为去异常后的735个样本匹配硅含量,统计结果如表4 所示,由表可知ClusterD 中样本可完全实现匹配。
在历史数据中,往往由于料批的差异导致的数据波动,使某一时段内硅含量均处于区间外,因此,其余样本周期内硅含量值均不属于高频区间的样本,则优选更接近“高频区间”的值。匹配完成后,生成新的数据样本,作为后续预测工作的数据集。
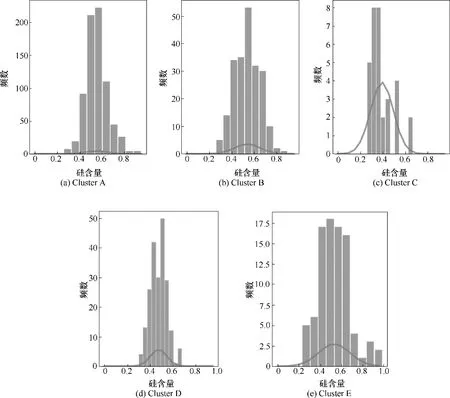
图5 各簇频数直方图Fig.5 Frequency histogram of each cluster
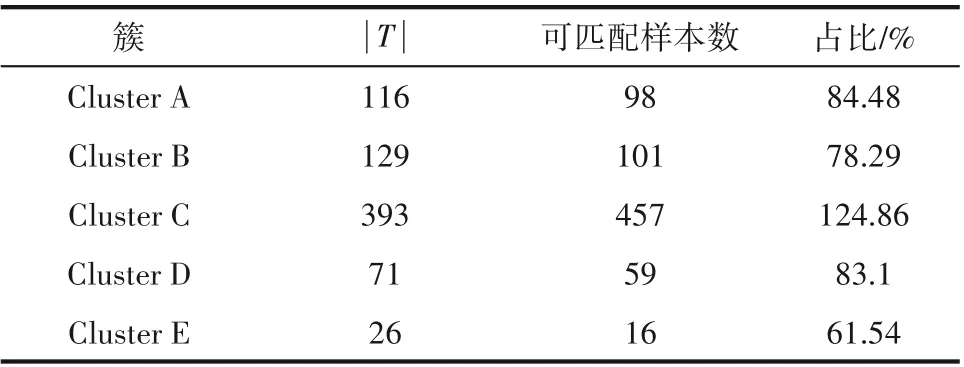
表4 各簇高频区间内硅含量可匹配样本数统计Table 4 Statistics of samples which can be matched by the silicon content in the high-frequency interval
4 实验结果及分析
本文分别建立基于多层感知器和LSTM 网络的深度学习预测模型。多层感知器是一种经典的多隐层全连接前馈神经网络,具有高度的并行性且应用广泛;LSTM 网络在近两年被引入高炉铁水硅含量预测领域,在时间序列领域有很好的表现。因此,本文采用这两种方法分别建模以验证所提硅含量数据优选法的有效性。
优选后的数据样本共735 个,以8∶2 的比例划分训练集和预测集。将训练集作为输入用于模型训练,预测集用于验证模型训练结果。
使用训练好的网络在预测集上生成预测结果,计算预测值与真实值的均方误差,并绘制可视化图形,观察模型效果。采用均方误差(MSE)、绝对误差在threshold 以内(threshold 为0.05%和0.1%)的命中率(HR)、趋势准确率(TAR)作为衡量指标,即:
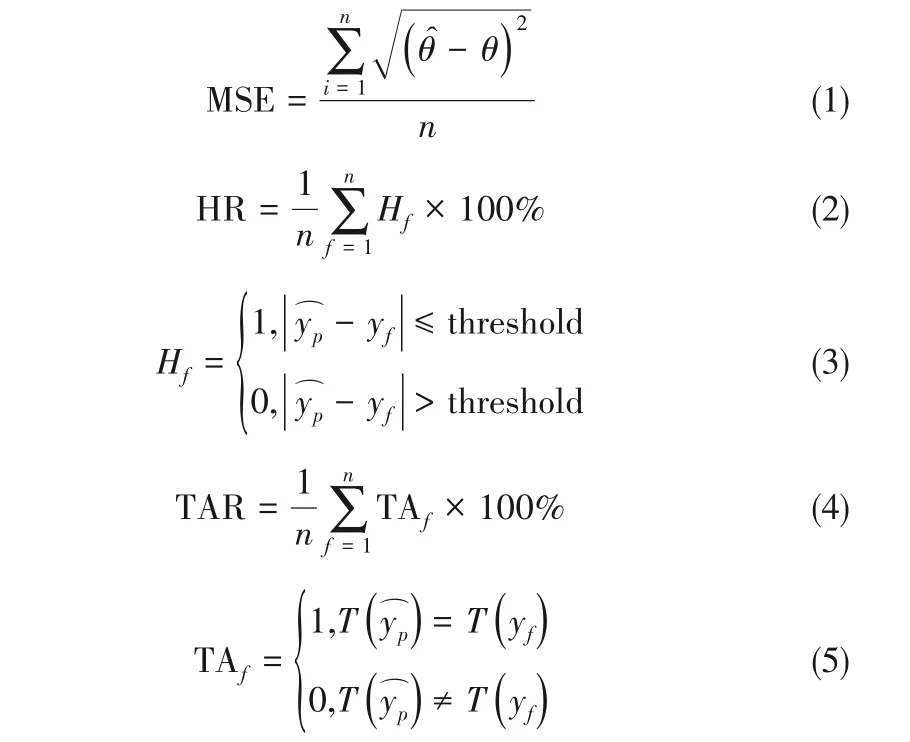
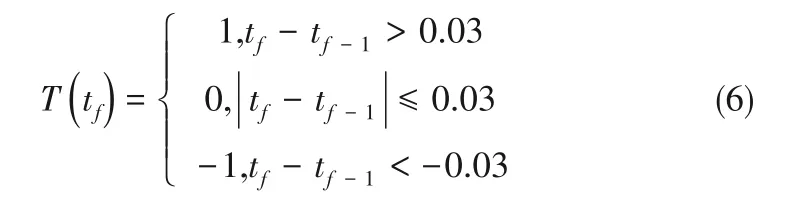
MSE 用于衡量预测效果的稳定程度;HR 是预测误差的绝对值在threshold内的样本数占总样本数的比率,衡量预测模型的准确程度;TAR 用于衡量预测趋势变化的准确程度,是当前值与上一时刻值的变化在历史数据与预测数据上趋势一致的样本与总样本数的比率,共包含三种趋势,当变化量绝对值小于等于0.03 视为平稳,变化量大于0.03 视为上升,变化量小于-0.03视为下降。由于数据集不同优化方式导致数据范围存在差别,趋势预报准确率能够更好地体现不同数据的预测效果。
4.1 在多层感知器预测模型中的应用
多层感知器也称为深度全连接前馈网络,是最基本的深度学习网络。由若干层组成,每一层包含若干个神经元[34],通过逐层堆叠结构的神经网络模型,学习获得各层越来越有意义的表示。神经网络具有很强的非线性映射能力,并且具有收敛速度快,全局优化的特点。多层感知器网络结构如图6所示。
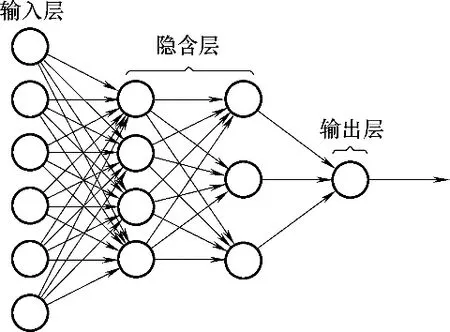
图6 多层感知器网络结构Fig.6 Multi-layer perceptron network structure
构建多层感知器时,Tanh 激活函数在数值预测上就有很好的表现,模型架构包括:三个中间层,每层设置50 个隐藏单元;输出层输出一个标量,预测当前的硅含量。在网络中以0.5 的比率引入Dropout,防止网络过拟合。
为验证本方法的有效性,和传统的均值法进行对比,“k-means 优选法”与“均值法”数据集在多层感知器预测模型下,预测结果如图7 所示,图7(a)为“k-means++优选法”所得数据集,图7(b)为传统“均值法”所得数据集。对预测结果进行评估,如表5所示,由表可知,“k-means++优选法”与“均值法”相比,均方差(MSE)下降48.57%,0.05%命中率提升31.77%,0.1%命中率提升11.78%,趋势准确率提升3.61%。

图7 多层感知器模型下预测值与真实值对比Fig.7 Comparison between the prediction and the actual value based on the multi-layer perceptron model

表5 “k-means++优选法”与“均值法”数据集在多层感知器预测模型下的结果对比Table 5 Comparison between the data sets of“kmeans++optimal selection method”and“averaging method”based on the multi-layer perceptron model
4.2 在LSTM网络模型中的应用
循环神经网络的改进算法长短期记忆(LSTM)网络是深度学习处理时间序列的基础。高炉铁水数据是一个动态的时间序列,当前炉况与历史炉况相互关联,LSTM 网络能够动态记忆历史信息,在学习信息的同时保持历史信息留存持久化,这一特性使得LSTM 网络在高炉数据预测上有着天然的优势[2]。LSTM网络结构如图8所示。

图8 LSTM网络结构Fig.8 LSTM network structure
本文依托Keras深度学习框架搭建包含50个神经元的LSTM 网络,其后接一层激活函数为Tanh 的全连接网络用于输出预测结果。
图9 所示为LSTM 模型下的预测结果,其中图9(a)为传统“均值法”预测结果,图9(b)为“k-means++优选法”预测结果。由图可看出“k-means++优选法”数据集相较于“均值法”,预测值命中率更高。
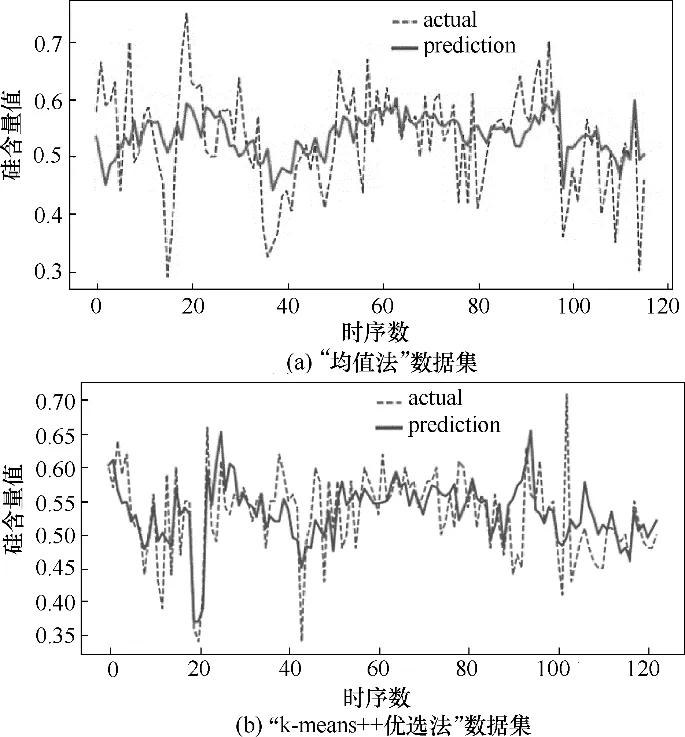
图9 LSTM模型下预测值与真实值对比Fig.9 Comparison between the prediction and the actual value based on the LSTM network structure
对预测结果进行评估,由表6 可知,LSTM 模型中“k-means++优选法”数据集较“均值法”数据集,均方差(MSE)下降59.09%,0.05 命中率提升36.94%,0.1命中率提升15.49%,趋势准确率提升4.56%。
4.3 结果分析
验证结果表明,采用本文提出的“k-means++优选法”解决高炉数据的关联问题,与传统均值法相比,在不同的预测模型上均降低了均方差,提高了模型的预测命中率和趋势准确率,尤其是在误差容限为0.05 的条件下,对预测效果有较大的改善,体现了该数据优选方案的有效性。此外,从表5 以及表6的对比可知,LSTM 预测模型的效果优于多层感知器预测模型。

表6 “k-means++优选法”与“均值法”数据集在LSTM预测模型下的结果对比Table 6 Comparison between the data sets of“kmeans++optimal selection method”and“averaging method”based on the LSTM network structure
5 结 论
本文提出了基于k-means聚类算法的数据优选方法“k-means++优选法”,能够解决历史数据输入变量与硅含量不关联的困难,减少了噪声干扰,用于训练模型后可以看出,优选数据集在多层感知器和LSTM 网络中均有更好的表现,能够提高预测命中率与趋势准确率,降低均方误差。
目前,数据优选方法尚处于探索阶段,还有很大的改进空间。从应用验证结果可以看出,“kmeans++优选法”数据优选方法在数据匹配方面优势明显,但历史数据中,部分输入变量对硅含量的影响具有不同程度的滞后,有望通过分析不同变量的滞后时间,在聚类时将滞后值作为当前的输入变量,以此减小由时滞导致的硅含量匹配误差,进一步提高可信度。
