基于全局注意力机制的语义分割方法研究
2020-07-31彭启伟冯杰吕进余磊程鼎
彭启伟 冯杰 吕进 余磊 程鼎

摘 要:如何捕获更长距离的上下文信息成为语义分割的一个研究热点,但已有的方法无法捕获到全局的上下文信息。为此,文章提出了一种全局注意力模块,其通过计算每个像素和其他像素之间的关系生成一个全局关系注意力谱,然后通过该全局注意力谱来对深层卷积特征进行重新聚合,加强其中的有用信息,抑制无用的噪声信息。在具有挑战性的Cityscapes和PASCAL VOC 2012数据集上验证了所提出的方法具有有效性其优于现有的方法。
关键词:语义分割;注意力机制;全局信息
中图分类号:TP391.41 文献标识码:A 文章编号:2096-4706(2020)04-0102-03
Abstract:How to capture the context information with longer distance has become a research hotspot of semantic segmentation,but the existing methods can not capture the global context information. This paper proposes a global attention module,which generates a global relation attention spectrum by calculating the relationship between each pixel and other pixels,and then reaggregates the deep convolution features through the global attention spectrum to strengthen the useful information and suppress the useless noise information. The validity of the proposed method is verified on the challenging Cityscape and PASCAL VOC 2012 datasets,which is superior to the existing methods.
Keywords:semantic segmentation;attention mechanism;global information
0 引 言
語义分割[1,2]是计算机视觉中的一个基础任务,需要对给定图片的每个像素分配一个类别标签。其可以应用在信息通信领域的多个任务上,如智能图片信息识别、自动驾驶中的信息识别等。由于需要在精细的像素级别上识别目标的类别,因此具有较大的难度,取得的性能也不是很理想。
针对以上问题,本文提出了一种基于全局注意力机制的语义分割方法,通过该方法可以获得高精度的语义分割结果,进而为本企业中的智能图片信息识别项目提供强力的技术保障。
传统的方法首先将待分割图像分成一些区域块,然后提取每个区域块的特征,如形状、颜色和纹理特征等,然后建立图像特征到高级语义之间的概率模型,得到语义分割模型。其关键点在于如何提取有用的关键特征用于分割模型的建立。传统方法多是基于手工特征进行提取,不仅耗时耗力,而且精度较低。
近来,随着深度卷积神经网络的兴起,越来越多的人关注于使用卷积神经网络进行语义分割。如前面所说,其关键点在于如何提取有用的关键特征。使用卷积神经网络提取特征,其卷积层和池化层的有效组合能够自动学习提取图像的关键特征,不仅避免了大量的人力消耗,而且提取的特征更有利于分割模型的建立。卷积层的作用从本质上来讲就是局部特征的提取,而池化层将语义上的相似特征进行组合。一般情况下,池化层计算特征图中的局部最大值或平均值等,这样做的好处在于可以提高数据的平移不变性并减少表达的维度。通过几个卷积层和池化层组合得到的网络,可以很好地提取图像的有用特征。在此基础上,基于全卷积网络的语义分割框架取得了显著的进展,但由于卷积核的感受野受限,其仅能聚合局部和短距离的上下文信息,无法捕获全局的上下文信息。
为了捕获长距离的上下文信息,具有更大感受野的空洞卷积被提出。带有金字塔池化模块的PSPNet也进一步被提出,用于捕获更长距离的上下文信息。然而,基于空洞卷积的方法虽然能扩大感受野,但实际上无法生成密集的上下文信息,基于金字塔池化的PSPNet也在一定程度上无法满足不同像素对不同上下文信息的要求。
为了最大程度地利用全局的上下文信息,本文提出了一种全新的注意力模块。其通过计算每个像素和其他所有像素之间的关系生成一个全局的注意力谱,然后基于全局注意力谱来对深层特征进行聚合,从而对有用信息进行加强,对噪声信息进行抑制。并在Cityscapes数据集和PASCAL VOC 2012数据集上验证所提出方法的有效性,证明其优于现有的方法。
1 方法的总体结构
图1为提出方法的总体结构。输入图像首先经过卷积神经网络提取图像的深层特征,其大小为H×W×C,该特征图一方面经过本文提出的全局注意力模块得到HW×HW的全局注意力谱,另一方面经过变形操作,得到C×HW的特征图。之后使用全局注意力谱与变形的特征图进行矩阵相乘,得到C×HW的特征图,然后再将该特征图变形得到H×W×C的特征图。该特征图即为通过全局注意力模块重新聚合之后的特征,相对于卷积神经网络输出的H×W×C的特征图,该特征图能够增强有用的特征信息,抑制无用的噪声信息。最后,将聚合重组之后的H×W×C特征图通过上采样进行分割,即可得到最后的语义分割结果。
图2为本文提出的全局注意力模块,输入大小为H× W×C的特征图,分别通过两个结构相似但参数不一样的平行分支。第一个分支经过一个小的卷积神经网络φ1得到一个大小为H×W×C的重组特征图1,经过形变操作,得到大小为HW×C的变形特征图1。与之类似,第二个分支经过一个小的卷积神经网络φ2和变形操作,得到一个大小为C×HW的变形特征图2。之后变形特征图1和变形特征图2经过矩阵相乘,即可得到一个大小为HW×HW的全局注意力谱。该谱刻画的是输入特征的每一个通道位置的像素和其他通道位置之间的关系,是一个基于全局的逐像素对之间的信息。
2 实验过程
2.1 实验设置
数据集:我们在Cityscapes数据集和PASCAL VOC 2012数据集上进行实验。
Cityscapes是用于城市语义分割的一个数据集,其包含从50个不同城市捕获的5 000张高质量像素级精细标注的图像和20 000张粗略标注的图像。每张图像的大小为1 024×2 048,共有19个类别。我们在实验中仅使用5 000张精细标注的图像,其分别有2 975、500、1 525张训练集、验证集、测试集。
PASCAL VOC 2012数据集是语义分割任务中常用的基准数据集之一,和其他方法一样,我们使用其增强数据集用于语义分割,因此训练集、验证集和测试集分别为10 582、1 449和1 456张。
2.2 实施细节
我们所有的实验均在深度学习框架PyTorch上运行,GPU为一张Titan XP,骨干网络我们采用由ImageNet预训练的ResNet-101,优化器为SGD,mini-batch size设置为2,初始学习率为1e-2,使用多元学习策略,即学习率为初始学习率乘以1-,iter为此时的迭代次数,max_iter为训练的最大迭代次数,power是一个超参数,本文设置为0.9。weight decay设置为0.000 5,momentum设置为0.99,共训练30个epoch。
2.3 实验结果对比
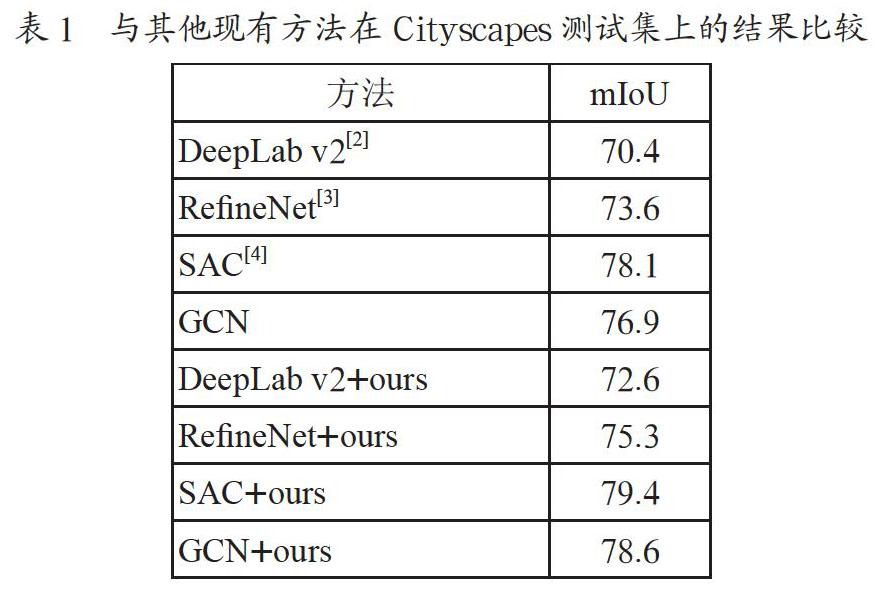
表1为本文方法和其他现有方法在Cityscapes数据集上的结果比较。我们将提出的全局注意力模块分别用到现有的方法中,如DeepLab v2[2],RefineNet[3],SAC[4],GCN[5]。前四行为不加本文提出的全局注意力模块的结果,其mIoU分别为70.4、73.6、78.1和76.9,后四行为加了本文提出的全局注意力模块,分别提升了2.2(70.4 VS 72.6)、1.7(73.6 VS 75.3)、1.3(78.1 VS 79.4)、1.7(76.9 VS 78.6)个点,充分表明了本文提出的全局注意力模块的有效性。
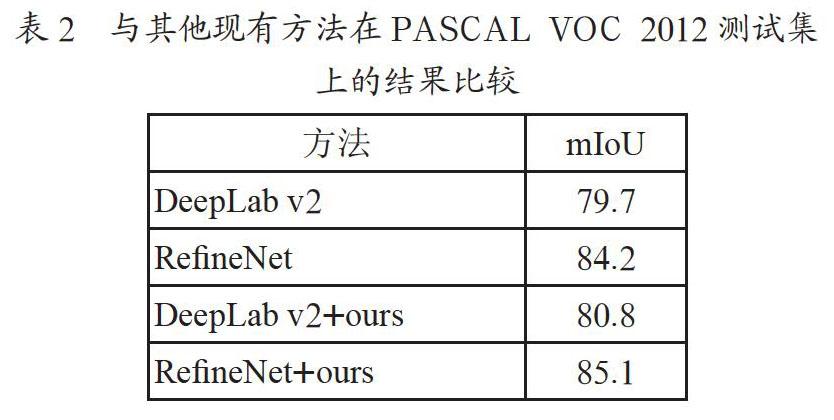
表2为本文方法和其他现有方法在PASCAL VOC 2012数据集上的结果比较。我们将提出的全局注意力模块分别用到现有的方法中,如DeepLab v2[2],RefineNet[3]。前两行为不加本文提出的全局注意力模块的结果,其mIoU分别为79.7和84.2,后两行为加了本文提出的全局注意力模块,分别提升了1.1(79.7 VS 80.8)和0.9(84.2 VS 85.1)个点,表明了本文提出的全局注意力模块的有效性。
3 结 论
为了在语义分割任务中充分利用深层特征的上下文信息,本文提出了一种全局注意力模块,通过计算每个像素和其他所有像素之间的关系生成一个全局注意力谱,然后以此注意力谱对深层特征进行重新聚合,從而加强深层特征的有用信息,抑制无用噪声信息。由于该模块充分利用了特征中的上下文信息,即全局信息,因此能有效提高语义分割性能。我们在Cityscapes和PASCAL VOC 2012数据集上验证了本文提出的方法有效性。
参考文献:
[1] LONG J,SHELHAMER E,DARRELL T.Fully convolutional networks for semantic segmentation [C]//Proceedings of the IEEE conference on computer vision and pattern recognition,2015:3431-3440.
[2] CHEN L C,PAPANDREOU G,KOKKINOS I,et al.Deeplab:Semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected crfs [J].IEEE transactions on pattern analysis and machine intelligence,2017,40(4):834-848.
[3] LIN G S,MILAN A,SHEN C H,et al.Refinenet:Multi-path refinement networks for high-resolution semantic segmentation [C]//Proceedings of the IEEE conference on computer vision and pattern recognition,2017.
[4] ZHANG R,TANG S,ZHANG Y,et al. Scale-Adaptive Convolutions for Scene Parsing [C]//2017 IEEE International Conference on Computer Vision (ICCV).IEEE,2017.
[5] PENG C,ZHANG X Y,YU G,et al.Large Kernel Matters——Improve Semantic Segmentation by Global Convolutional Network [C]//The IEEE Conference on Computer Vision and Pattern Recognition,2017.
作者简介:彭启伟(1984-),男,汉族,安徽六安人,高级工程师,硕士研究生,主要研究方向:视频处理。
