基于GIOWA算子的我国碳排放量的组合预测研究
2020-07-15陆玉玲
陆玉玲
(安徽财经大学统计与应用数学学院,安徽蚌埠233030)
由于二氧化碳等温室气体的大量排放,气候变暖问题已经成为当今时代面临的一项重大挑战,它对社会的健康可持续发展产生了重大的威胁。目前,我国是世界上最大的二氧化碳排放国,对碳排放进行科学准确地预测,有助于政府制定合理的碳减排政策,对推动我国生态文明建设和经济高质量发展具有重要的作用。
针对碳排放预测研究,学者们主要采用两类模型进行建模分析,分别是单一预测模型和组合预测模型。(1)单一预测模型。赵息等学者基于中国1980—2009年的碳排放数据,运用离散二阶差分方程预测模型对碳排放进行预测[1];邓小乐和孙慧利用STIRPAT模型对西北五省区碳排放峰值进行了预测[2];何永贵和于江浩基于河北省2003—2014年碳排放数据,运用灰色GM(1,1)预测模型对河北省2015—2020年碳排放量进行预测[3];董聪等学者采用BP神经网络对我国碳排放量进行预测[4]。(2)组合预测模型。肖枝洪和王明浩采用ARIMA模型与BP神经网络集成的组合模型,对中国碳排放量进行预测研究,结果表明组合模型预测误差较小[5];Wang和Ye采用中国1953—2013年化石能源消费中的碳排放量数据,运用灰色模型、非线性灰色多变量模型和改进的非线性灰色多变量模型预测中国2020年的碳排放量,结果表明非线性灰色多变量模型具有最高的准确率[6];刘炳春等学者基于主成分分析(PCA)和支持向量回归(SVM)两种方法构建组合预测模型对中国2016—2021年碳排放量进行预测,结果表明PCA-SVR组合模型误差低于单项预测模型的误差[7]。
本文选取中国1989—2018年间的碳排放量数据,在多元线性回归、指数平滑和ARIMA(0,2,0)三种单项预测模型的基础上,构建广义诱导有序加权平均(GIOWA)组合预测模型对我国未来五年的碳排放量进行预测,为我国碳减排政策的制定提供一定的参考。本文的后续结构安排为:第一部分是建立单项预测模型对我国碳排放量进行预测;第二部分是建立基于GIOWA算子的组合预测模型对中国碳排放量进行预测;第三部分是根据单项预测模型和组合预测模型的碳排放量预测结果给出本文的结论。
1 全国碳排放量单项预测
1.1 多元线性回归模型
选取城镇化率(urbant/%:城镇常住人口占总人口的比重)、能源消费强度(eit/吨标准煤/万元:能源消费总量与国内生产总值GDP的比)、人均GDP(pgdpt/元/人)、产业结构(indt/%:第二产业增加值占GDP的比重)四个影响因素作为多元线性回归模型的自变量,全国碳排放量(yt/百万吨)作为模型的因变量,并将所有变量进行对数化处理以建立多元线性回归模型。考虑到通货膨胀因素的影响,GDP利用居民消费价格指数折算为1989年不变价。所有数据来源于《BP世界能源统计年鉴》、EPS全球统计数据库和国家统计局。
运用逐步回归法,得到如下多元线性回归模型:
lnyt=-3.8686+0.2606lnurbant+1.0537lneit+0.9722lnpgdpt+0.4898lnindt+εt
(-19.4554) (4.2840) (36.9728) (45.1510) (12.6002)
(1)
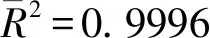
1.2 Hlot-Winters 非季节指数平滑预测
对我国碳排放量进行对数化处理,运用Hlot-Winters 非季节指数平滑法,使用Eviews 7软件计算得到阻尼因子为α=0.96和β=1,趋势项为0.0216,截距项为9.1511,而预测出2019—2023年间各年的二氧化碳排放量。Hlot-Winters 非季节指数平滑方法的预测公式为:
(2)
式(2)中,T是待估计样本的期末值[8],k为T期到预测期的间隔期数。
1.3 自回归移动平均ARIMA模型
首先,对中国碳排放量序列y进行对数化处理得到序列lny,经检验序列lny不平稳,然后,对lny进行差分处理,得到平稳的二阶差分序列记为z,其自相关函数、偏自相关函数图形如图1所示。

图1 zt序列的样本自相关函数图与偏相关函数图
该序列在5%的显著性水平下接近于一个白噪声,因此可建立零阶MA(0)模型[9]:
zt=εt
(3)
则对中国碳排放量对数序列lnyt可建立ARIMA(0,2,0)模型,即
lnyt=2lnyt-1-lnyt-2+εt
(4)
表1列出了多元线性回归、Hlot-Winters 非季节指数平滑和ARIMA(0,2,0)三种单项预测模型的预测值和精度。由表1可知,同一单项预测模型在不同时点上的预测精高低是不相同的,因此有必要使用广义诱导有序加权平均(GIOWA)的组合预测模型。
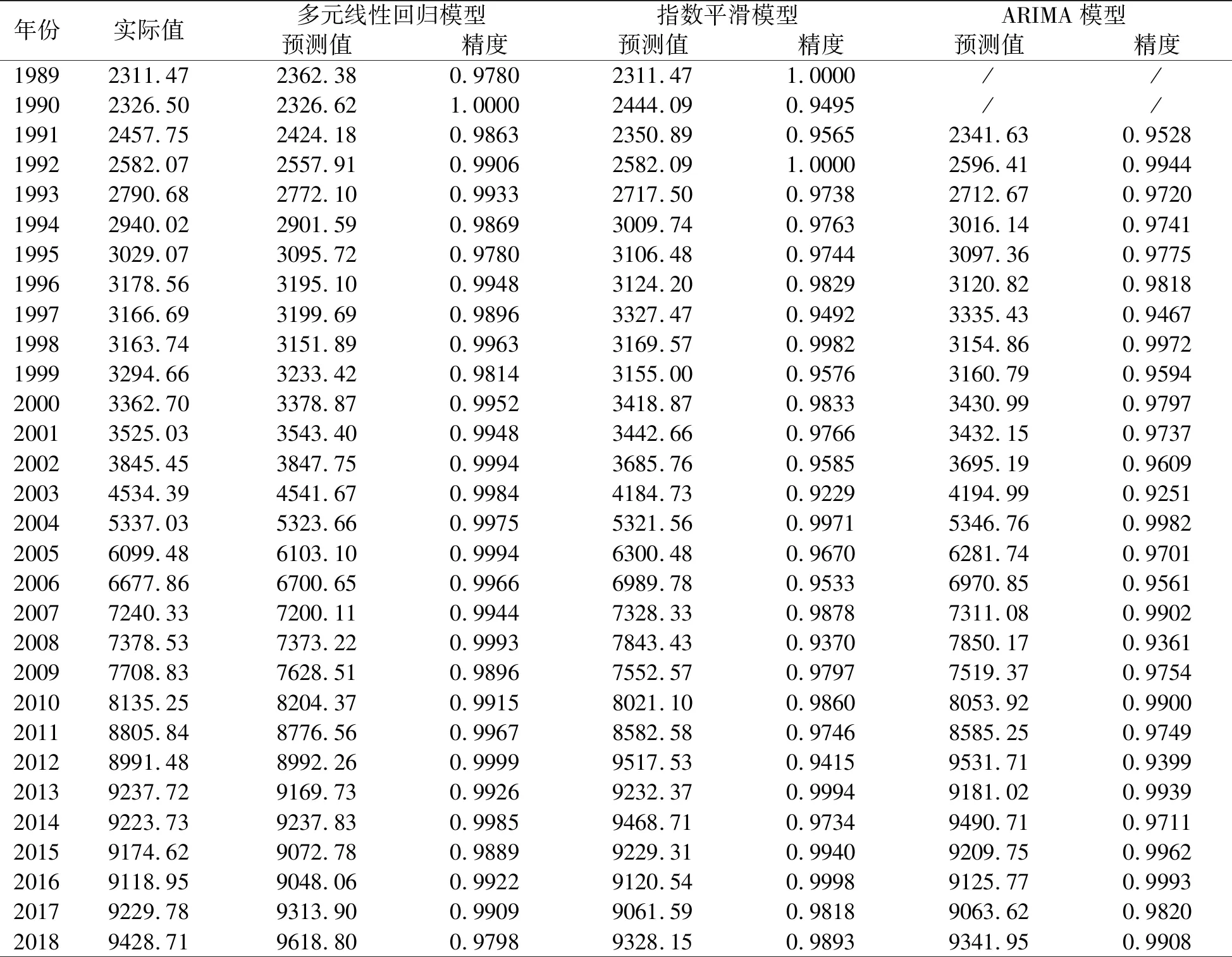
表1 1989—2018年全国碳排放量3种单项预测值和精度
2 基于GIOWA算子的全国碳排放量组合预测模型
2.1 GIOWA组合预测模型的建立
对于碳排放观测值序列yt>0(t=1,2,…,28),本文使用多元线性回归模型、Hlot-Winters 非季节指数平滑和ARIMA三种单项预测模型对其进行预测,设yit为第i种预测方法在第t期预测值,本文将预测值的诱导值设定为预测精度αit,且第i种预测方法第t期的预测精度计算公式为:
(i=1,2,3;t=1,2,…,28)
(5)
将3种单项预测方法在期的预测精度与其对应的预测值可以看做3个二维向量:<α1t,y1t>,<α2t,y2t>,<α3t,y3t> ,将3种单项预测方法在t时刻的预测精度序列α1t,α2t,α3t按照从小到大的顺序进行排列,则诱导有序第i种预测模型第t期λ次幂误差为:
(i=1,2,3;t=1,2,…,28)
(6)
其中,α-index(it)表示诱导有序第i种预测方法的预测精度的下标。
计算样本期内GIOWA组合预测模型第t期组合预测的λ次幂误差,公式为:
(7)
其中,w1≥0,w2≥0,w3≥0,w1+w2+w3=1。
计算样本期内GIOWA组合预测次幂误差平方和,公式为:
(8)

因此,本文在λ次幂误差平方和最小的准则下,建立组合预测优化模型:
(9)
计算样本期间内组合预测模型的预测值,公式为:
(10)
2.2 实证结果与分析
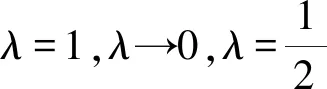
(1)λ=1时广义诱导有序加权平均(GIOWA)组合预测模型
对应的诱导有序误差信息矩阵为:

(11)
使预测误差平方和最小的IOWA组合预测模型为:
(12)
使用LINGO10.0软件求得权重:w1=0.9660,w2=0,w3=0.0340
得IOWA组合预测模型为:
(13)
样本期内组合预测误差平方和:Q=42236.14。
(2)λ→0时广义诱导有序加权平均(GIOWA)组合预测模型
对应的诱导有序对数误差信息矩阵为:

(14)
使得对数误差平方和最小的IOWGA组合预测模型为:
(15)
使用LINGO10.0软件求得权重:w1=1,w2=0,w3=0
得IOWGA组合预测模型为:
(16)
样本期内组合预测对数误差平方和为1.848×10-3。

(17)
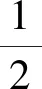
(18)
使用LINGO10.0软件求得权重:w1=0.9832,w2=0,w3=0.0168
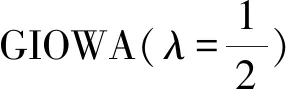
(19)
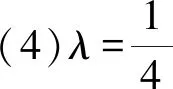
(20)

(21)
使用LINGO10.0软件求得权重:w1=0.9944,w2=0,w3=0.0056
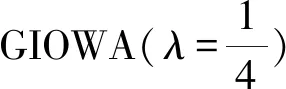
(22)
表2给出了λ取不同值时情况下的广义诱导有序加权平均组合预测模型的预测值。

表2 取不同值时情况下的GIOWA组合预测模型的预测值
2.3 预测效果评价
为了比较3种单项预测模型和4种GIOWA组合预测模型的有效性,选取以下五个误差指标作为判断标准:
(1)平方和误差(SSE):
(2)均方根误差(RMSE):
(3)平均绝对误差(MAE):
(4)平均相对误差(MAPE):
(5)均方根相对误差(RMSRE)
表3给出了所有预测模型的评价指标值以及其归一化处理结果,并给出了每个模型的平均精度。从表3可以看出,四种GIOWA组合预测模型的各项误差指标均低于三种单项预测模型,且组合预测模型的平均精度均达到99.4%,高于三种单项预测模型的平均精度,表明基于GIOWA 算子的组合预测模型能够提高我国碳排放量的预测精度。
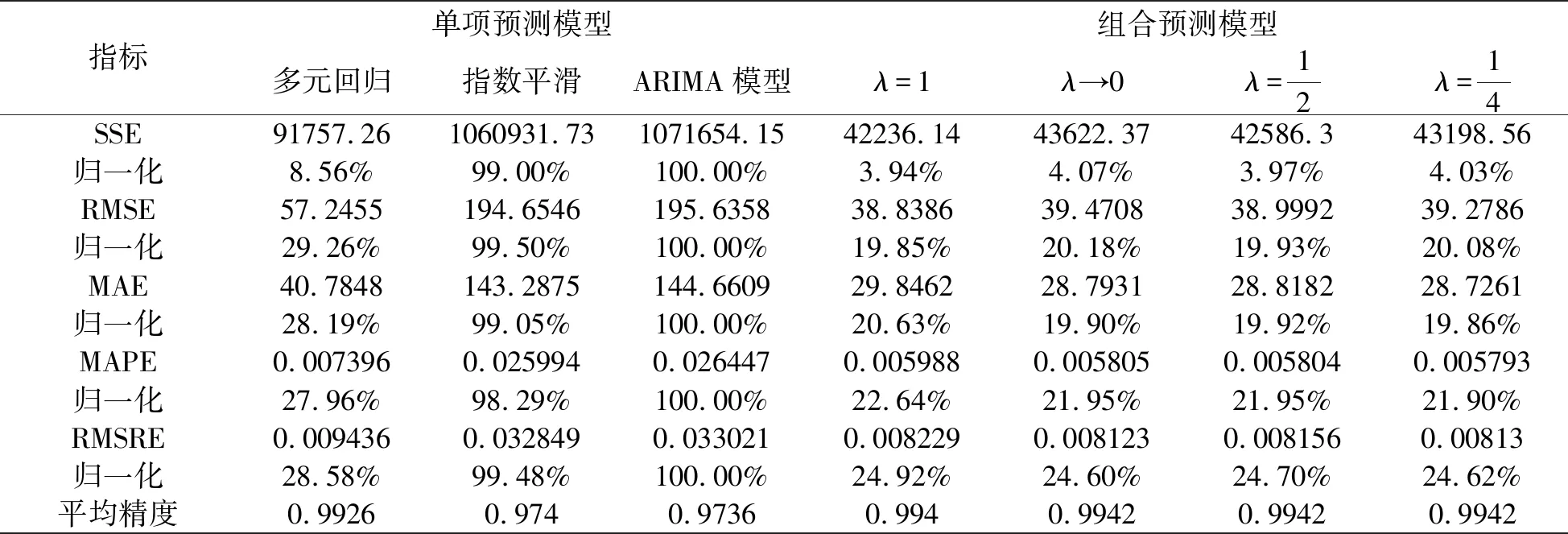
表3 预测效果评价指标体系
2.4 未来五年的碳排放量的预测值
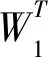
根据三种单项预测模型的权重可以计算我国在2019—2023年间各年的排放量的预测值,具体结果见表4。由表4可以看出,四种组合预测模型的预测结果非常接近,可见具有较高的预测精度。2019—2023年我国碳排放量稳步增长,年均增长速度分别为4.1066%、2.5782%、2.5788%、2.5793%、2.5799%。

表4 2019—2023年我国碳排放量的预测值(单位:百万吨)
使用Hlot-Winters 非季节指数平滑预测方法对我国2019—2023年间的GDP进行预测,根据GDP和碳排放量的预测值可以计算出我国碳排放强度。2019—2023年间我国碳排放强度呈下降趋势,年均下降速度分别为3.0996%、4.5222%、4.5217%、4.5212%、4.5207%。
3 结论
本文基于1989-2018年全国的二氧化碳排放量数据,首先,使用多元线性回归模型、Hlot-Winters 非季节指数平滑模型和ARIMA(0,2,0)三种单项预测模型对我国碳排放量进行预测,其次,以误差平方和最小为准则,建立基于GIOWA算子的我国碳排放量组合预测模型,并通过预测效果评价指标体系对单项预测模型和组合预测模型的有效性进行比较,研究结果表明:组合预测模型的平均预测精度高于三种单一的预测模型,有效克服了各单项预测模型的缺点;未来五年,我国碳排放总量处于增长趋势,但是碳排放强度呈下降趋势。
通过对我国碳排放量进行预测,可以看出我国节能减排任重而道远,因此,我国需要积极引进国外先进生产技术,加强科技创新,提高能源利用效率,促进清洁能源的开发和使用,从而减少碳排放和推动我国碳排放量在2030年达到峰值目标的实现。
