中国粮食供需研究及预测
——以小麦为例
2020-07-09庞碧玉冯爱芬曹振雪胡启帆王琰
庞碧玉,冯爱芬,曹振雪,胡启帆,王琰
(河南科技大学数学与统计学院,河南洛阳471023)
粮食问题是关系民生的问题,也对农业经济发展有重要的影响.随着农业经济的发展,关于粮食供需的数据越来越多,有效地预测粮食的供应和需求可以使农业生产者了解信息,及时调整生产过程中可能出现的供需矛盾,使粮食产品市场平稳运行.
目前国内用于粮食产量预测的方法主要有无偏灰色马尔可夫模型、BP神经网络模型、多元线性回归模型、支持向量机、灰色GM(1,1)模型等.尹邦华等[1]改进了无偏灰色马尔可夫模型,周永生等[2]采用BP神经网络模型,王启平[3]利用多元线性回归分析方法,赵桂芝等[4]基于混沌-AVM-PSO的模型,杨克磊等[5]应用灰色GM(1,1)模型,他们通过建立粮食产量预测模型,对我国粮食产量进行预测,但均有一定程度的地域局限性和适应条件.国外对产量预测的研究方法主要采用气象产量预测法、遥感技术、统计动力学模拟法.这3种方法预测误差通常在5%~10%,预测精度不高[6-8].考虑到中国小麦生产是一个复杂的动态系统,小麦供需数据具有趋势性、波动性的特点,故从宏观角度和数据本身出发,消除地域限制建立预测模型.
本文采用ARIMA模型构建计量经济学模型进行多维度分析讨论,排除出口量、区域性差异、季节等周期性因素的影响,对产量、进口量和需求量进行预测,并以中国粮食中的主要农作物小麦为例进行分析.
1 ARIMA模型
ARMA模型是平稳时间序列模型,而粮食产量、进口量和需求量趋势变化具有波动性、不确定性,是一种非平稳随机过程,所以本文引入了差分算子I(可使原不平稳的时间序列经d阶差分后改进为平稳时间序列),建立粮食产量、进口量和需求量趋势预测ARIMA模型.
差分整合移动平均自回归模型(Auto-regressive integrated movingaveragemodel,ARIMA)是平稳时间序列预测分析模型之一.ARIMA模型考虑研究对象本身的历史数据随时间的变化而变化的规律,并以此预测未来值.即以时间代替各种影响因素,探寻分析事件的变化特征和发展趋势[9-10].ARIMA模型由自回归模型(AR模型)、移动平均模型(MA模型)与差分算子I(d)组成.
1.1 AR模型
AR模型的参数p代表预测模型中采用的时序数据本身的滞后数.其p阶AR模型表达式为

式(1)中:θi(i=1,2,…,p)为AR模型系数,et为随机干扰项,c1为常数.
定义B为后移算子,B满足条件

式(1)和式(2)联立得到

1.2 MA模型
MA模型参数q代表预测模型中采用的预测误差的滞后数.其q阶MA模型的数学表达式为

式(4)中:Wj(j=1,2,…,q)为MA模型系数,et为随机干扰项,c2为常数.
1.3 差分算子I
差分算子可使不平稳的时间序列经d阶差分后改进为平稳时间序列
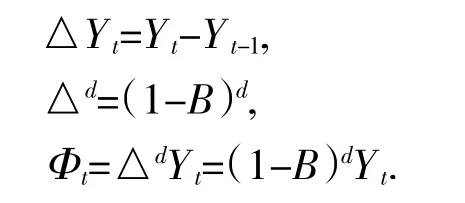
综上,ARIMA模型的数学表达式为

式(5)中:Θp(B)和Wq(B)是特征多项式,et为随机干扰项,c为常数.即得到可用于粮食供需预测的ARIMA时间预测模型.
2 中国小麦产量ARIMA模型
2.1 数据准备与处理
本文提取《中国统计年鉴》及“中华人民共和国农业农村部”网站1979—2018年中国小麦产量,以万t为产量单位,以年为时间单位观察数据.
对样本数据进行处理,剔除异常数据,使预测值尽量准确.数据显示,1949—1978这30 a中,数据缺失现象严重,在时间序列模型中,这段时间样本不具有分析意义,删除样本数据.
2.2 数据平稳性检验
根据上述数据准备与处理原则,做出原始产量时间序列图,见图1.
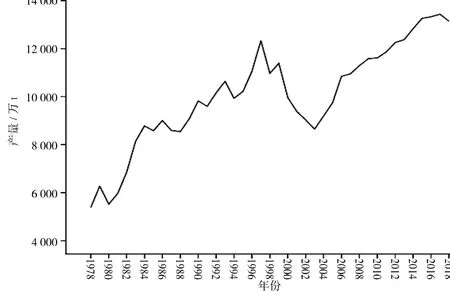
图1 原始产量时间序列Fig.1 Original yield timeseriesdiagram
由图1可知,原始数据趋势图不具有平稳性,对原始数据进行一阶差分处理,处理后产量时间序列见图2.

图2 一阶差分处理后产量时间序列Fig.2 Yield timeseries diagramafter first orderdifference treatment
由图2可知,数据在“0”上下浮动,初步判断一阶差分以后数据平稳.
2.3 模型确定
对一阶差分后的数据进行自相关与偏自相关检验,创建自相关图与偏自相关图,根据图片的截尾、拖尾情况估计p、q的数值.一阶差分后自相关与偏自相关图见图3.

图3 一阶差分后自相关图与偏相关图Fig.3 Autocorrelation and partial correlation after the first order difference
图3的ACF(自相关图)显示时间序列所有自相关函数都在置信区间内且数值趋向于0,因此一阶差分后其具有随机性与平稳性特征.进一步得知,图ACF、PACF均截尾,可得到备选模型ARIMA(1,1,1)、ARIMA(1,1,0).
对备选模型 ARIMA(1,1,1)、ARIMA(1,1,0)做参数p、d、q估计与假设检验,见表 1.

表1 参数估计与假设检验Tab.1 Parameter estimation and hypothesistesting
表 1显示,ARIMA(1,1,1)的P值 <0.05,ARIMA(1,1,0)的P值 >0.05,且由 BIC最优准则得,ARIMA(1,1,1)为最优模型.由表1得到产量预测模型

利用式(6)对2019和2020年的产量进行预测,得到预测产量分别为13 152.20万t、13 160.79万t.
2.4 模型检验与误差分析
将数据分成实验组1979—2016年与检验组2017—2018年,首先将实验组1979—2016年的数据带入ARIMA预测模型,得到实验组1979—2016年产量实际值与拟合值的误差,结果见表2.
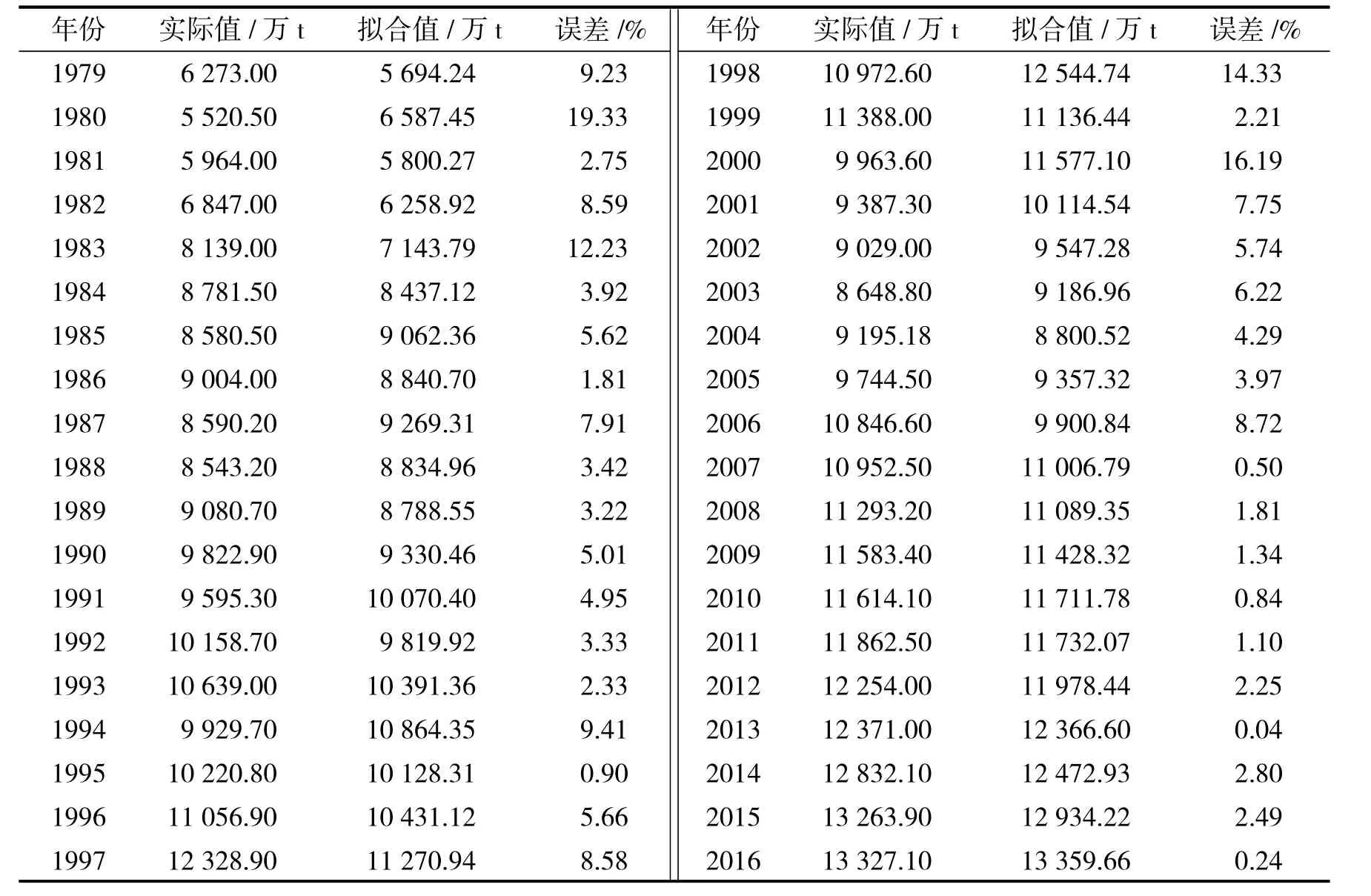
表2 实验组1979—2016年产量实际值与拟合值误差表Tab.2 Error tablebetween actual and fitting values of annual output in experimental group
由表2计算得小麦实验组1979—2016年实际值与拟合值平均误差为5.29%,误差较小,拟合程度较好,模型合适.观察发现,表2中1980年、1983年、1998年、2000年小麦产量实际值与拟合值差值较大,通过查阅资料并分析原因如下:1983年小麦产量实际值大于拟合值,该年种植面积无特别增减,但亩产量有明显提升,所以该年小麦总产量增加.而1980年、1998年、2000年小麦产量实际值小于拟合值,其中1980年与1998年因秋冬连续干旱,11月份突然降温,使小麦抗寒能力降低,而早春3—4月份的低温光照不足,又使小麦抽穗期延迟,灌浆期缩短,所以这两年产量减少;2000年干旱少雨,水资源紧张,种植面积减少,而且黄淮冬麦区小麦在收获期间遭受暴雨,无法及时收割及晾晒,小麦质量严重受损,所以2000年小麦产量也有所减少.
实验组数据的误差结果显示ARIMA(1,1,1)模型合适,故进一步分析检验组2017—2018年产量实际值与预测值的误差结果,见表3.

表3 检验组2017-2018年产量实际值与预测值误差Tab.3 Error between actual annual output and predicted value of test group
由表3可知,检验组2017—2018年产量实际值与预测值平均误差为1.65%.
综上所述,ARIMA(1,1,1)模型的实验组与检验组的结果显示,拟合与预测的误差较小,拟合效果较好,模型合适且支持应用于粮食产量预测.
2.5 白噪声检验
若残差序列通过白噪声检验[11],说明产量数据中的有用信息已经被提取完毕,此时建模可以终止,ARIMA最优模型可用来预测产量.ARIMA(1,1,1)模型残差序列的自相关与偏自相关图见图4.

图4 残差序列的自相关与偏自相关图Fig.4 Autocorrelation and partical autocorrelation of residual sequence
由图4可知,残差序列的自相关函数和偏自相关函数基本都在95%的置信区间内,说明残差序列不存在自相关.该模型通过白噪声检验,可以用来预测短期中国小麦的产量.
3 中国小麦供需预测
3.1 进口量预测
在多个样本数据中,进口量在供给量占一定比重,具有分析意义,所以我们考虑进口量的影响,并进行预测.从《中国统计年鉴》中选取1999—2018年中国小麦进口量、年需求量与人口数,见表4.

表4 1999—2018年中国年小麦进口量、年需求量与人口Tab.4 Annual wheat import,annual consumption and population in China,1999—2018
利用上述同样ARIMA方法,代入表4中进口量数据,建立ARIMA(3,2,3)进口量预测模型,得到关系式

通过式(7)对2019和2020年的进口量进行预测,得到进口量实际值与拟合值趋势图,见图5.

图5 进口量实际值与拟合值趋势Fig.5 Trend chart of actual and fitting values of import volume
由图5可知,2019年和2020年中国小麦进口量预计分别为210.98万t和121.15万t.
供给量=产量+进口量
计算可得,2019年和2020年小麦供给量分别为13 363.18万t和13 281.94万t.
3.2 需求量预测
利用同样ARIMA方法,代入表4中的需求量,建立ARIMA(3,2,2)需求预测模型,得到关系式
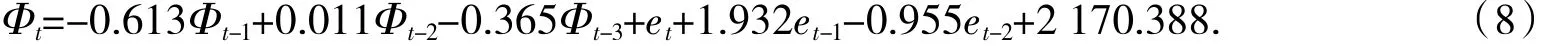
通过式(8)对2019和2020年的需求量进行预测,得到1999—2019需求量的实际值与拟合值,见表5.

表5 1999—2019需求量的实际值与拟合值Tab.5 Actual and fittingvalues of thedemand in 1999—2019
由表5可知,2019年和2020年需求量预测结果分别为12 683.65万t和13 030.17万t.
4 小结
本文建立了中国粮食供应和需求预测模型,得到的预测值和观测值在95%的置信区间内拟合很好.然而,ARIMA模型也具有一定的局限性,它是依靠历史的统计数据建立的数学模型,并未考虑国家重大政策改变和调整、环境变化、区域性差异等外部因素的影响.因此ARIMA模型仅适用于短期结果预测,预测未来2~3年的趋势是可行的.预测时间过长会增大预测误差,影响预测精度.因此需要及时了解市场行情、重大气候变化,更新观测值,重新拟合,确保预测的精度,或在此模型基础上进行优化,继而得到适应新情况的模型.
从中国小麦的供需数据与预测值来看,我国小麦供需接近平衡.长远来看,应该提高小麦亩产量,增加本国粮食生产总量,实现粮食安全,维护社会稳定.
