齐夫定律对《十九大报告》文本的适用性研究
2020-07-08秦克霄
秦克霄
(山西大学图书馆,山西太原,030006)
古代已有词语频次的观念,人们很早就发现了语言中词语使用的频次是有差异的.19世纪以来,随着语言学的发展以及文学风格和速记研究的需要,人们开始对语言的成分进行统计分析.德国语言学家F.W.Kaeding耗时七年编纂了Häufigkeitswörterbuch der Deutschen Sprache,这是世界上第一部频率词典,是第一次现代意义上的以统计调查方法完成的词汇研究工作.美国教育学家兼心理学家E.L.Thorndike,在20 世纪初先后编写了Teacher’s Word Book of 20,000 Words和 Teacher’s World Book of 30,000 Words,做了大量关于英语词汇的频率统计工作.由于有了大量不同语言中词频资料的积累,关于词语频次的特征不断得到了揭示,人们开始从理论上思考词频差异这种现象.频率词典实际上就是一种词表,包含两个最基本的数据就是词的出现频次和词的等级,二者反映了一个词在词表中的地位和性质,因此这两个基本数据间的相互关系成为了人们要首先着重研究的,并试图在一定的篇章范围内总结出语言成分出现频次所满足的严格的数学原理.如艾思杜、贡东、朱斯和芒代尔布罗等学者先后对这个问题进行了大量的研究.
美国哈佛大学语言学教授齐夫(G.K.Zipf)在前人研究的基础上,收集了大量的文本语料,并进行了系统的分析,正式创立了词频分布定律,验证下面的公式:若把一篇较长的文章中每个词出现的频次从高到低进行递减排列,某个词在文中出现的频率次数f(词频)与它的排列序号数r(词序)的乘积为一个常数c,即所谓的齐夫第一定律
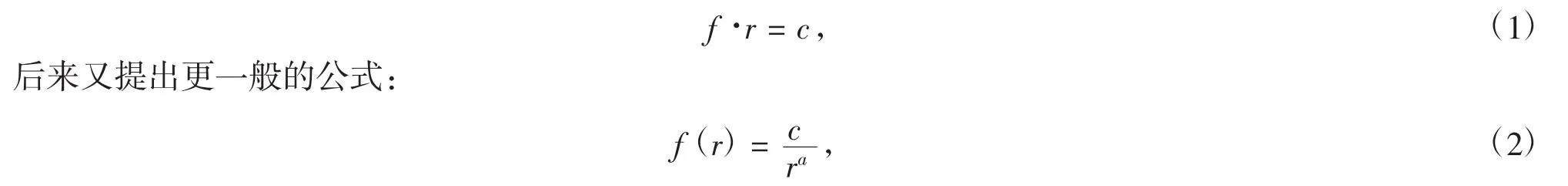
齐夫定律表明,在自然语言文本中,文档中词汇的频次与其排序等级呈现反比例关系,即两者乘积保持为一常数.对上式两边取自然对数可得:lnf+alnr=lnc.对统计数据结果绘制lnf与lnr的关系曲线,即可得到斜率-a与截距lnc.国内也有很多学者展开了对齐夫定律本身[1]及其应用[2~4]的研究.近来江南大学的研究者以诺贝尔文学奖得主莫言的《红高粱》《蛙》和《透明的红萝卜》为主要研究对象,统计莫言作品中字频、词频,发现都能满足齐夫定律.所得研究结果与包括英语、西班牙语、法语等在内的多种语言结果一致.这种研究结果从统计学角度提供了莫言可以成为中国大陆首位获诺贝尔文学奖得主的可能原因之一.在词语频次的统计中,主要采用以下两种方法确定词语等级:
1)随机法.齐夫第一定律在确立时,最先使用的就是随机法.随机法是指词级在确立的过程中,如果遇到同频词,则按照统计文本中词语的自然词序或随机词序排列确定词语的等级,这样每个词的词级就是它的自然或随机词序.例如词序为第 5~8的词是同频词,那么它们的词级随机排列则是 5,6,7,8.
2)并列法.徐文霞在《齐夫定律与中文词频分布机理》[5]一文中采用并列法来确定词级.并列法是指把遇到的同频词并列为一个词级,并延承上一个词级.例如词序为第5~8的词是同频词,那么它们的词级就是5;若词序为第9~12的词也是同频词,那么这些词的词级则要延承上一个词级成为6.
分词原则:
(一)采用计算机自动分词统计时,以齐夫定律理论为基础,根据汉语自身的语言特点,参考《现代汉语词典》条目所列出的词语形态,把保留词语语义的完整性作为前提.
(二)地名、人名等这些专有名词要作为独立的词来进行划分.
(三)标点符号等非汉字书写符号在统计时不计入内.
根据文献《十九大报告》中出现的词频(字频)与等级序号的统计数据,我们建立一个直角坐标系,其横坐标表示词的等级序号r,纵坐标表示相应的频次f,描绘出这些点得到一条曲线,即齐夫分布曲线,类似双曲线的一支.再将等级序号r与频次f都取对数坐标,则上述齐夫规律变成一线性关系,即齐夫分布对数曲线.若满足这种类型的分布,就叫做齐夫分布.我们选用《十九大报告》文本作为研究分析的语料库,此文本共有32384个书写符号,其中汉字共有29255个,累计总词数3082个,不同频次71个.
1 数据统计结果(部分)(见表1)
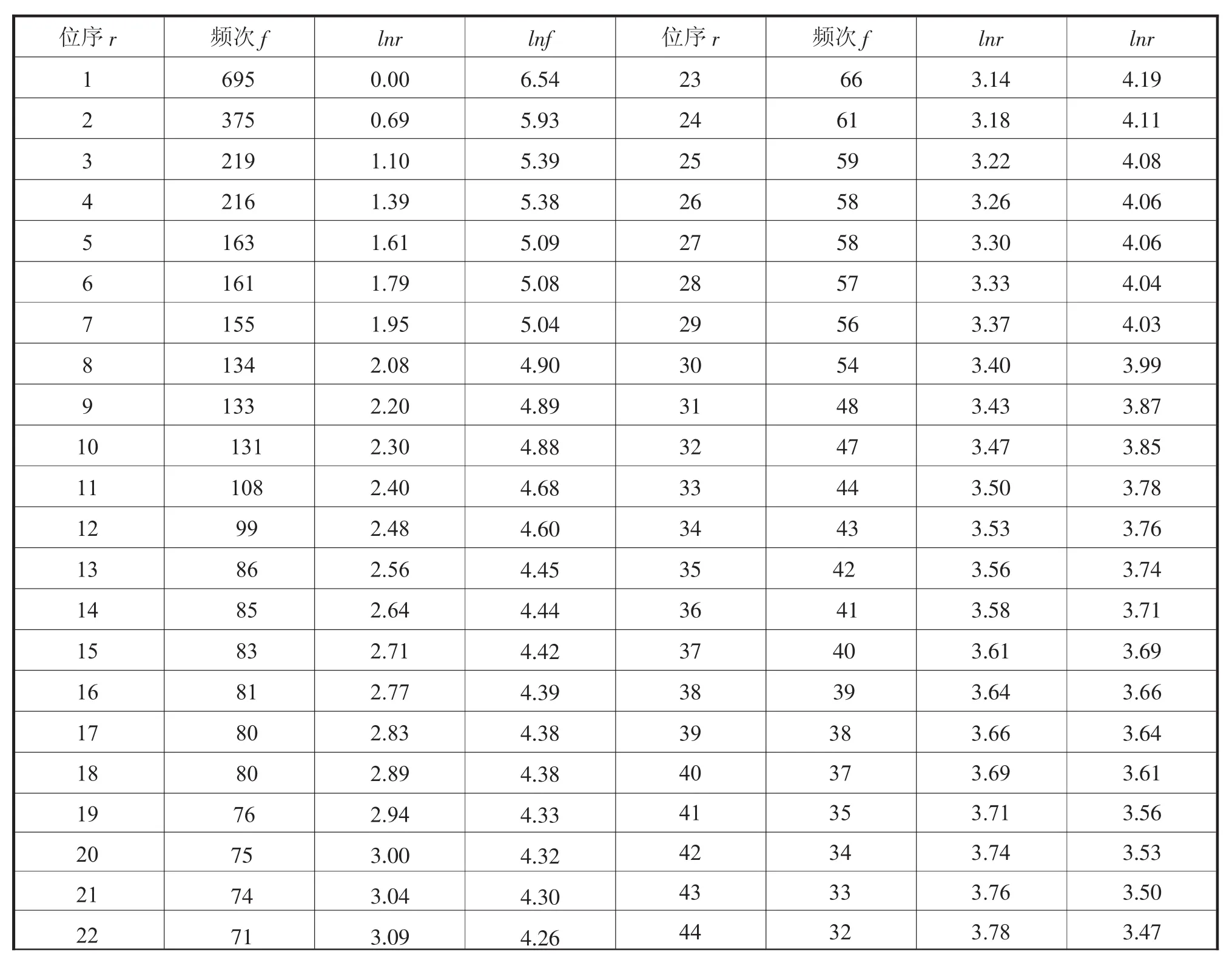
表1 十九大报告文本统计结果
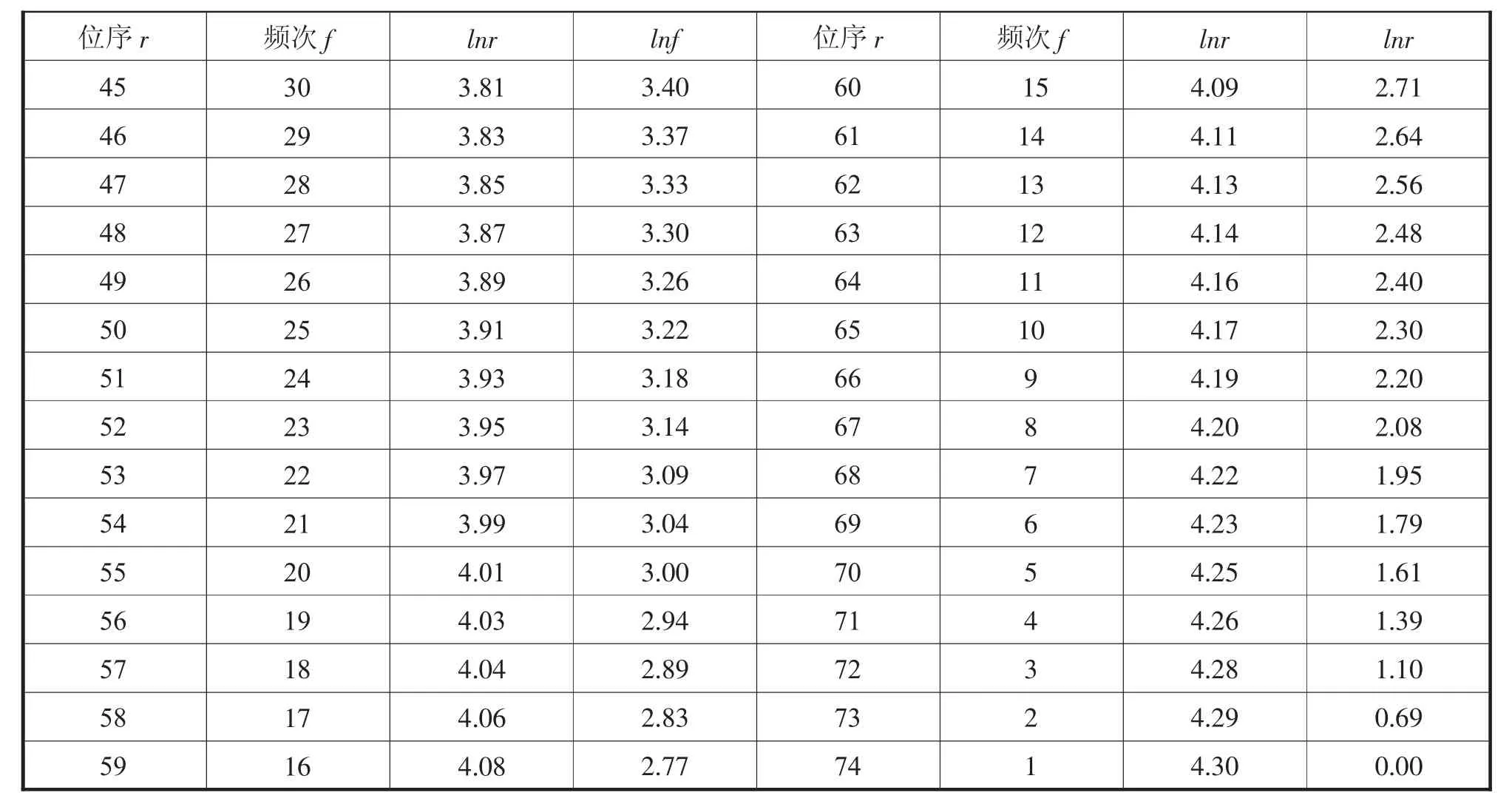
续表
2 随机法
2.1 频次与词级图
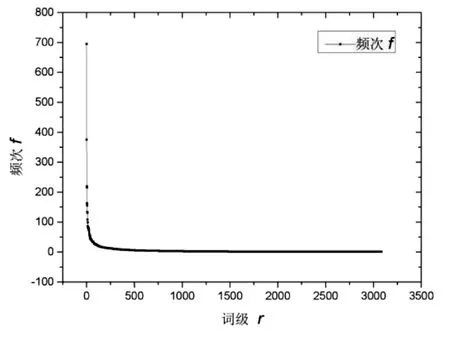
图1 词频f—词序r分布图
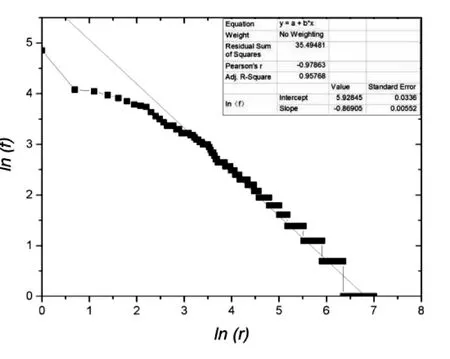
图2 词频—词序对数分布图以及线性回归
由图1、图2中齐夫分布曲线的反比例函数分布特性和齐夫对数分布的线性性可以看出,用随机法《十九大报告》文本中的词频与词级极好地满足齐夫分布定律(详见表2线性拟合结果).
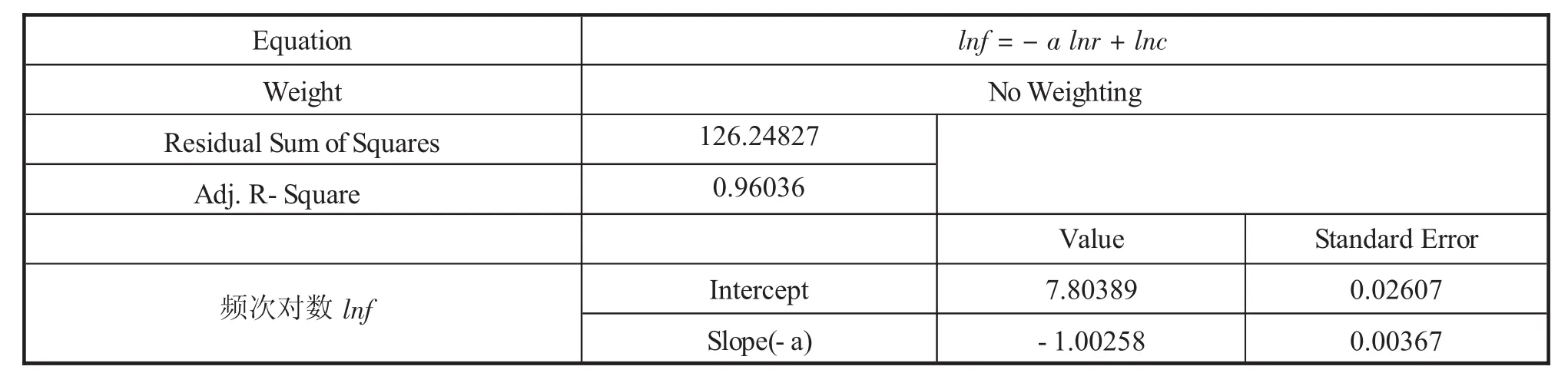
表2 图2的线性拟合分析
2.2 求斜率-a与lnc
由公式lnf+alnr=lnc所知,绘制lnf与lnr的关系曲线,并进行拟合,即可得到斜率-a与lnc.如图2.
2.3 求a和lnc以及c
由表2可知,修正决定系数 Adj.R-Square=0.96036,反映了线性回归的良好.截距lnc=7.80389(标准误差 为0.02607),可知 c=2450.114409;斜率-a=-1.00258(标准误差为0.00367)近似等于齐夫第一定律标准值-1,表明《十九大报告》文本语料库采用随机法的统计方法,其结果完全符合齐夫第一定律[6].
3 并列法
3.1 频次与词级图
由图3、图4齐夫分布曲线的反比例函数分布特性和齐夫对数分布的线性性可以看出,采用并列法《十九大报告》文本中的词频与词级亦极好地满足齐夫分布定律(详见表3线性拟合结果).
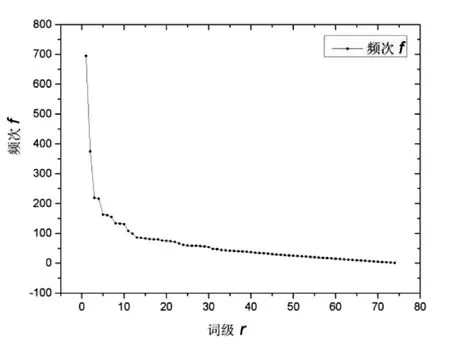
图3 词频f—词序r分布图
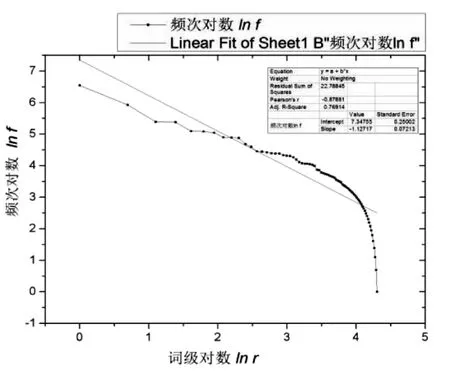
图4 词频—词序对数分布图以及线性回归
3.2 求斜率-a与lnc
由公式lnf+alnr=lnc所知,绘制lnf与lnr的关系曲线,并进行拟合,即可得到斜率-a与lnc.如图4.
3.3 求a和lnc以及c.

表3 图4的线性拟合分析
由表3可知,修正决定系数Adj.R-Square=0.76914反映了线性回归的良好,截距lnc=7.3475(标准误差为0.25002),可得c=1552.38851.斜率-a=-1.12717(标准误差为0.07213),十分接近标准值-1.从数据结果可知,采用并列法符合情况不如随机法好,但也基本符合齐夫分布和齐夫定律.
以上结果表明,随机法和并列法的齐夫对数分布曲线回归效果都很好,斜率-a的值都接近齐夫第一定律设定值-1,均符合齐夫第一定律.
4 总结
本文主要通过《十九大报告》文本中语料库的词频词序的统计和分析,对齐夫定律在汉语中的适用性进行了研究和验证.笔者分别采用随机法和并列法,对《十九大报告》文本语料库进行了数据的统计和分析,并依据散点分布图绘制出了齐夫分布曲线和齐夫对数分布曲线.利用数学软件拟合出散点分布图的线性回归趋势来进行分析.依据这些散点图,我们能看出齐夫分布曲线均呈现出了比较明显的双曲线特征,而齐夫对数分布曲线呈现线性关系,并且斜率值-a十分接近标准值-1,符合齐夫第一定律的设定.可见,统计结果中的词频分布呈现出较为明显的齐夫分布规律.在《十九大报告》文本中,频次出现最高的十个词依次为“的、和、党、发展、人民、建设、中国、社会主义、是、坚持 ”,此外,“新、特色、制度、体系、文化、政治、改革、创新、经济、安全”频次也比较高,这体现了中国过去五年的发展状况以及未来五年的发展趋势.可以看出,齐夫定律对中文报告类题材同样具有其普适性.齐夫定律已经在很多领域有了广泛的应用(如语言学、情报学、地理学、经济学、信息科学等),而且取得了可喜的成果.齐夫定律是描述词频分布规律的强大数学工具,作为经验定律,它仍然有待进一步完善.
