面向音频信号的可迁移的稀疏表示字典学习方法
2020-06-28高畅,孙杰
高 畅,孙 杰
(燕山大学 信息科学与工程学院,河北 秦皇岛 066004)
通过字典对信号进行稀疏表示,可以获取信号的简洁表示,有利于信号的后续处理,并降低信号处理的成本,这已成为信号处理领域重要的方法[1],特别是在音频信号处理领域中已经有很广泛的应用,例如音频信号的压缩[2]、去噪[3]和分类[4-5]等.
音频数据采集场景(包括话者、话者情感以及话者所处环境、状态等)的不同会造成数据分布有很大不同[6-8],从而对基于字典的音频信号稀疏表示的泛化能力造成较大影响.例如,由疾病引起的声音变异与正常声音信号的数据分布差别很大,在基于稀疏表示的处理方法中,通过正常声音信号得到的字典难以得到有效的稀疏表示结果,从而对后续的处理造成影响.因此,研究具有可迁移性以及具有更好效果和更高效率的稀疏表示字典对提升音频信号的稀疏表示性能具有重要意义.
最简单和直接的字典获取方式是通过预先定义的符合某类信号特性的1组过完备的基函数构成字典,如Gabor[9]和离散余弦变换(Discrete Cosine Transform, DCT)字典.此外,也可以将若干已存在的变换矩阵连接在一起,构成联合字典,也称为结构字典,如傅里叶变换和离散余弦变换等正交变换矩阵.这种字典的构造方法中,基函数的形式及参数是事先确定的.然而,信号的多变性使基函数无法与信号特性完全匹配时,基于这种字典的稀疏表示存在表示系数稀疏度高的问题.
为了使字典中的原子具有更好地表示信号特性的能力,可以通过从大量原始信号构成的训练数据中学习用来表示信号特性的原子,这种基于学习的方法得到的字典更符合信号固有的特性,信号的稀疏系数具有更低的稀疏度,如最优方向法(Method of Optimal Direction, MOD)[10]和KSVD(K-means Singular Value Decomposition)[11]法.这种方法学习的字典泛化能力较差,即当音频数据的采集场景发生变化时,需要重新学习字典,严重影响了实际应用.
本文提出可迁移的稀疏表示字典(Tansferable Sparse Representation Dictionary, TSRD)的学习方法,利用经验模态分解(Empirical Mode Decomposition, EMD)[12]得到的本征模态函数(Intrinsic Mode Function, IMF),与原始音频信号联合进行字典学习.由EMD分解得到的IMF,它本质上是1种信号内部固有的震荡模式,是信号最本质的特征[12],因此,学习到的TSRD可以实现稀疏表示的迁移;同时,IMF具有高效性、完备性、自适应性和近似正交性[12],从而使TSRD稀疏表示的效率更高,效果更好.
1 可迁移的稀疏表示字典学习方法
信号的稀疏表示就是对如下问题进行求解:
(1)
(2)
式中: ‖·‖0为l0范数,表示向量中非零值的个数;x为原始信号;D为稀疏表示字典;α为稀疏表示系数;ε为误差项.字典学习的目的是找到1个字典,基于这个字典可以通过求解式(1)和式(2)所示的问题对信号进行稀疏表示.
本文提出TSRD学习方法,首先,对信号进行分帧;然后,基于EMD方法对各帧进行分解,将分解得到的成分作为每帧信号的本质特征;对所有本质特征进行聚类,得到初始字典;在字典学习阶段,提出基于信号本质特征与原始音频信号的字典联合学习方法,由信号的本质特征学习得到的字典具有可迁移性,在此基础上,通过利用音频信号进一步对字典进行优化,提高TSRD的稀疏表示效果和效率.
1.1 基于EMD的信号本质特征的提取方法
音频信号本质上是由很多个不同的正弦波复合而成的,因此,这些正弦波可以被认为是音频信号的本质特征.然而,重构信号所需的正弦波往往数量十分巨大,实际应用中很难处理.本文提出基于EMD的音频信号本质特征的提取方法.EMD可以将信号分解成少量的IMF和余量信号的线性组合,如
(3)
式中:x(t)表示信号;S表示分解得到的IMF分量的个数;rS(t)为余量成分.
EMD提取IMF的过程是1个筛选的过程,具体流程如下所述.
1) 分别用光滑的3次样条函数连接信号x(t)的所有极大值点组成上包络xup(t),连接所有极小值点组成下包络xlow(t);
2) 计算差值d(t),即
d(t)=x(t)-(xup(t)+xlow(t))/2;
(4)
3) 重复执行步骤1)和2),直到满足初始设置的停止条件,即当前差值的过零值与极值相等或最多差1的情况连续出现指定的次数(本文中设为6),此时记d(t)为第1个IMF,记为c1(t),计算残差量r1(t),即
r1(t)=x(t)-c1(t);
(5)
4) 将r1(t)视为新的初始信号x(t),继续执行上面的筛选过程,直到所提取的IMF分量或残差分量绝对值的积分值太小.
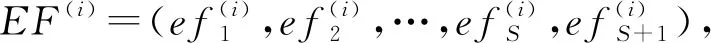
1.2 基于聚类的初始字典构造方法
为了使字典的原子之间具有更低的相干度,提升字典的稀疏表示性能,同时使字典学习过程可以更快地收敛,本文提出基于聚类的初始字典构造方法,通过c均值聚类方法对各帧本质特征组成的训练集(EF=(ef1,ef2,…,efP),其中P为训练集中本质特征的数量)进行聚类,从而形成初始字典.
首先,计算训练集中所有本质特征之间的相干度:
(6)

再次,假设学习字典的规模为D∈N×M,则将平均相干度最小的M个ef作为初始聚类中心,如果其中任意两个ef的相干度高于它们各自的平均相干度,则用剩余的ef中平均相干度最小的ef,代替其中平均相干度较大的ef,直到这些字典中原子之间的相干度都低于它们各自的平均相干度,或没有ef可供替换;
最后,以这些原子作为初始聚类中心,对所有ef进行聚类,将相干度作为相似性准则,最近邻准则为聚类准则.
将最终的聚类中心作为初始字典的原子,完成字典的初始化.
1.3 基于信号本质特征与原始信号的字典联合学习方法
在TSRD的学习过程中,本文提出1种字典联合学习方法,分为字典学习和字典优化两个阶段.在字典学习阶段,以信号的本质特征为训练集,学习对本质特征进行稀疏表示的字典,使字典具有可迁移性.在字典优化阶段,以原始音频信号为训练集,对字典进一步优化,使其更加适合对音频信号进行稀疏表示,从而提升TSRD字典的稀疏表示性能.
1.3.1 TSRD的字典学习
TSRD的字典学习是1个由稀疏表示与字典更新两个阶段组成的迭代过程,在稀疏表示阶段,字典保持固定,使用LASSO(Least Absolute Shrinkage and Selection Operator)算法对信号进行稀疏表示;在字典更新阶段,稀疏表示系数不变,通过奇异值分解(Singular Value Decomposition, SVD)方法对字典进行更新.
1) 基于LASSO的稀疏表示方法
通过求解式(1)和式(2)所示的问题对训练集中的信号进行稀疏表示,而求解l0范数是1个NP难问题,本文通过LASSO算法,用l1范数代替l0范数,即绝对值之和小于某个常数的约束条件下,使残差平方和最小化,从而使信号的稀疏表示系数中绝大多数系数严格等于0.
LASSO算法主要是对问题
(7)
进行求解,其中:u是稀疏表示的可行解;u*是使式(7)最小的u,即最终的稀疏表示系数;DEF表示以信号本质特征为训练集学习到的字典.
LASSO算法使式(1)和式(2)的求解问题变成1个凸问题,从而可以在全局优化的基础上对信号进行稀疏表示,因此,这种方法得到的稀疏表示系数具有更高的重构精度.
由于篇幅所限,LASSO算法具体执行过程请参考文献[13].
2) 基于SVD的字典的更新方法
通过对字典的更新,使其对训练集内的信号既要有尽量小的重构误差,又要保证稀疏表示的稀疏度满足约束条件.因此,本文基于SVD的方法对原始信号与重构信号之间的误差进行分解,从而实现对字典中的原子进行更新.
在SVD方法中,对重构误差的计算如下所示:
(8)
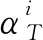
(9)
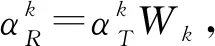
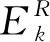
最后需要对字典中的每个原子进行归一化,以防止由于原子被选中的原因使幅值过大,从而使该原子与当前信号的内积最大,而不是与当前信号最相关.
1.3.2 TSRD字典优化
为了在保留TSRD可迁移性的同时,使其更加适用于音频信号的稀疏表示,并进一步提升TSRD稀疏表示的效果和效率,本文提出在基于信号本质特征学习到的字典的基础上,通过原始音频信号构成的训练集,对TSRD进行优化,进一步提升字典的稀疏表示性能.
与信号一样,字典中的原子也可以通过1个基字典进行稀疏表示[14],即
D=ΦA,
(10)
式中:D为稀疏表示字典;Φ为基字典;A为D中原子在Φ上的稀疏表示.本文把通过信号本质特征学习到的字典DEF作为基字典,即Φ=DEF.为了保留DEF的可迁移性,可以只对A进行调整,增强其自适应性,从而对字典D进行优化,使其更加适用于音频信号,如下所示:
(11)
式中:X为原始音频信号构成的训练集;Z为X在字典D上的稀疏表示;t为信号稀疏度;p为稀疏表示字典中原子的稀疏度.
字典优化同样也是由稀疏表示和字典更新两个阶段组成的迭代过程,其中稀疏表示与字典学习一样采用基于LASSO的方法,区别在于这里是对原始音频信号组成的训练集进行稀疏表示,而字典更新阶段是通过对A的更新来实现字典中原子的更新,优化算法的具体过程如下所述.

Algorithm1 TSRD优化算法Input: 训练集X,字典DEF,原子稀疏度p,信号稀疏度t,循环迭代次数K;Output: 稀疏表示字典D;1: Φ=DEF;2: 初始化稀疏表示稀疏矩阵A;3: for k=1 to K do4: 计算训练集X中各帧的稀疏表示系数: yi=arg miny‖xi-ΦAy‖22 s.t. ‖y‖00≤t,1≤i≤P;5: for j=1 to M do6: aj=0;7: 对X稀疏表示时用到了A中第j列的信号帧的下标构成集合I;8: g=YTj,I,其中Yj,I表示稀疏表示系数矩阵Y的第j行;9: 对g归一化: g=g/‖g‖2;10: 计算残差: e=XIg-ΦAYIg;11: 令a=argmina‖e-Φa‖ s.t. ‖a‖00≤p;12: 对a归一化: a=a/‖Φa‖2;13: 更新aj: aj=a;14: 更新稀疏表示系数: Yj,I=(XTIΦa-(ΦAYI)TΦa)T;15: end for16: end for17: return D=ΦA.
2 实验结果与分析
为了验证TSRD的性能,本文从字典的可迁移性能、稀疏表示效果以及稀疏表示效率3个方面进行实验,并与通过基于K-SVD和ODL(Online Dictionary Learning)字典学习方法构建的字典在性能上进行比较.为了方便比较,各种方法在字典学习中和对信号进行稀疏表示时,稀疏度约束设为Round(M/50),其中M为字典中原子的个数.实验中,训练了原子数分别为512,768和1024的字典,稀疏度分别为11,16和21,并使用正交匹配追踪(Orthogonal Matching Pursuit, OMP)算法对信号进行稀疏表示.
2.1 实验数据描述
实验中使用的语料主要来自两个数据集: 哈尔滨工业大学语音处理实验室录制的DisEC(Discrete Emotional Corpus)情感语料库和CCTV新闻联播语料库.音频文件的格式均为wav,采样频率为16kHz,16bit量化,每帧256个采样点,帧间交叠为128个采样点.
DisEC情感语料库是1个采集自两位专业话者的公开的中等规模的表演型语料库,包括高兴、悲伤、愤怒和惊讶4种情感类型,共1256条语句,其中男性话者636句,女性话者620句.CCTV新闻联播语料库采集自不同时间的100个完整的新闻联播,包括4位播音员的语料大约30000句左右.两个语料库之间话者不同(而且语料库内部也存在不同的话者)、话者情感不同(前者中的语料富有更多的感情,而后者中的语料主要以中性情感为主)以及话者所处环境不同(前者的话者处于正常办公室环境,后者的话者处于安静的播音室环境),两个语料库属于典型的采集场景不同而导致数据分布不同的情况.
2.2 TSRD迁移性能的评价
为了验证本文提出的TSRD的迁移性能,实验中分别对不同话者之间和不同数据集之间TSRD稀疏表示效果进行评估,其中: 不同话者之间迁移性能评价在CCTV新闻联播语料库上进行;不同数据集之间迁移性能评价主要在DisEC情感语料库和CCTV新闻联播语料库上进行.
在不同话者之间迁移性能的评价实验中,我们从CCTV新闻联播语料库中每次选取1名不同话者的大约50句左右的语料,构成20000帧的训练集进行字典的学习,其中M=1024,学习迭代次数为100.分别从4位话者的语料中随机选取20条语料,构成含有5000帧的测试集,对测试集中的音频帧进行稀疏表示并重构,计算原始信号与重构信号之间的信噪比λSNR,即
(12)
式中:x为原始信号;y为重构信号.
对训练集和测试集为相同话者的原始信号与重构信号的平均信噪比与训练集和测试集为不同话者的原始信号与重构信号的平均信噪比之间的差别程度进行比较,对不同方法学习到的字典的迁移性能进行评价,结果如图1所示.
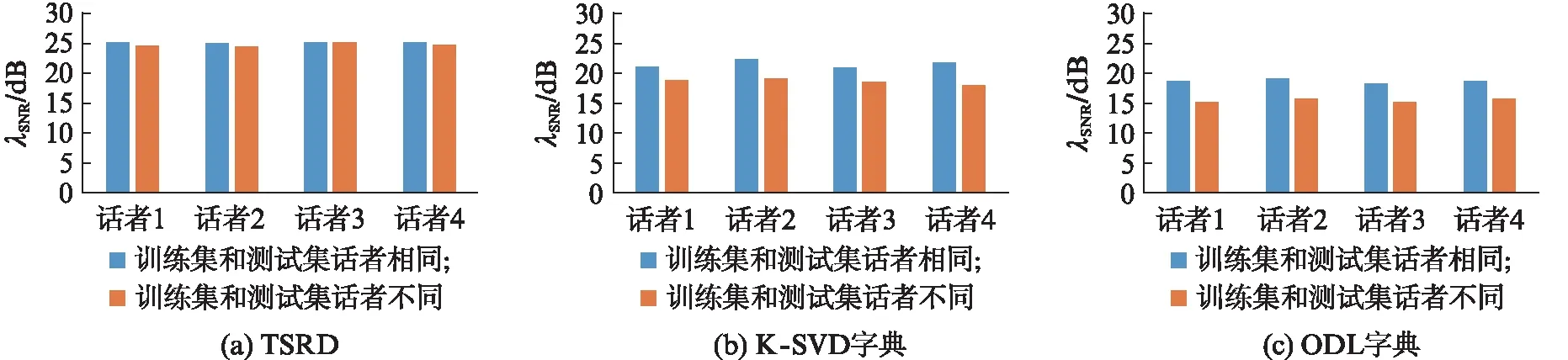
图1 不同话者间字典的迁移性能比较Fig.1 Comparison of the transfer performance of dictionaries between different speakers
从图1可以看出,基于TSRD对信号进行稀疏表示并重构,训练集和测试集为不同话者时,原始信号与重构信号的信噪比与话者相同时的信噪比相比较,约有0.5dB左右的下降,而基于K-SVD和ODL字典时,信噪比约有2.8dB和3.2dB左右的下降.TSRD学习过程中用到了信号的本质特征,它的提取是自适应的,反映的是信号内部固有的震荡模式,与话者无关,因此,TSRD具有更好的可迁移性.
本文还对TSRD跨数据集稀疏表示的迁移效果进行了评价.实验中,从DisEC语料库和CCTV新闻联播语料库各随机选取60句语料,分别构成20000帧的训练集进行字典学习,其中M=1024,学习迭代次数为100.同时,各随机选取25句语料,分别构成5000帧的测试集.同样通过对原始信号和重构信号的信噪比的差别程度进行比较来评价不同字典学习方法跨数据集的可迁移性能,结果如图2所示.
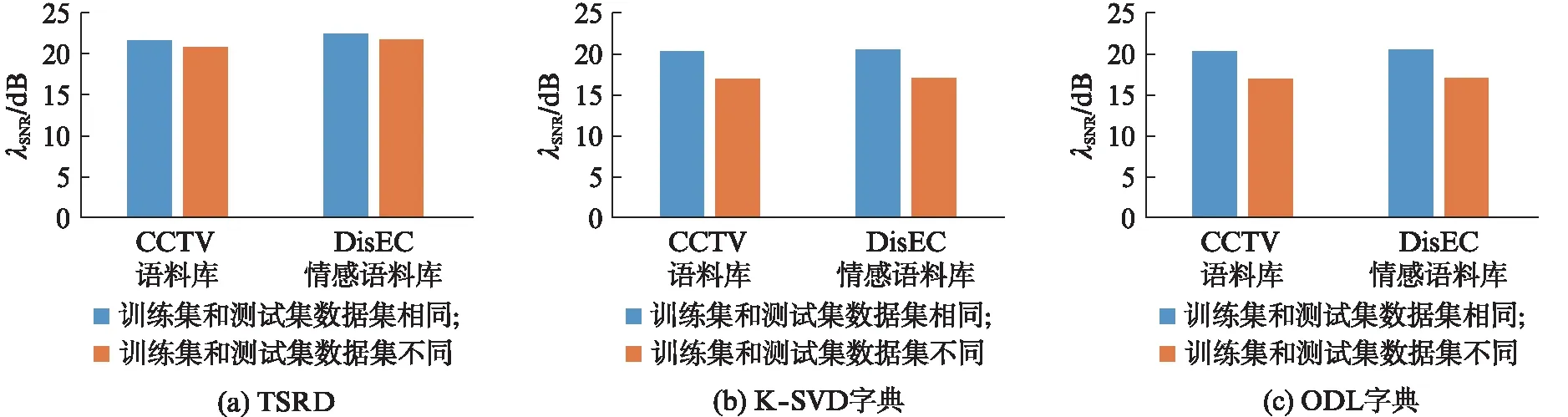
图2 不同数据集间字典的迁移性能比较Fig.2 Comparison of the transfer performance of dictionaries between different datasets
从图2可以看出,基于TSRD对信号进行稀疏表示并重构,训练集和测试集为不同数据集时,原始信号与重构信号的信噪比与训练集和测试集相同时的信噪比相比较,约有0.8dB左右的下降,而基于K-SVD和ODL字典,信噪比约有3.4dB和3.6dB左右的下降.因此,TSRD具有更好的可迁移性.
2.3 TSRD的稀疏表示性能评价
本文主要从稀疏表示的效率和效果两个方面对TSRD的稀疏表示性能进行评价.实验中,从CCTV新闻联播语料库中随机选取50条语料,构成20000帧的训练集,另外随机选取25条语料,构成5000帧的测试集,通过不同字典对测试集中的音频信号帧进行稀疏表示,计算重构信号与原始信号之间的信噪比,结果如图3所示.

图3 原子数不同时原始信号与重构信号的信噪比Fig.3 SNR of original signal and reconstructed signal with different atomic number
从图3中可以看出,基于TSRD对音频信号进行稀疏表示并重构,原始信号与重构信号之间的信噪比明显高于基于K-SVD和ODL字典的,在不同稀疏度的约束条件下,信噪比分别较K-SVD和ODL字典平均高约2.1dB和6.2dB.字典规模越大(原子数越大),信噪比越高,这是因为字典规模越大时,对音频信号稀疏表示时系数中非零值的数量也越多,即参与重构的原子数越多,因此,信噪比更高,稀疏表示效果更好.通常,在信噪比为20dB时,可以认为重构信号与原始信号已非常接近,TSRD在原子数为768时,原始信号与重构信号之间的信噪比便已达到20dB,而K-SVD字典在原子数为1024时才达到,ODL字典始终没有达到,因此,从效率的角度来看,本文提出的TSRD稀疏表示的效率更高,达到同样的信噪比时所使用的字典规模更小,字典规模相同时,达到相同信噪比所使用原子数量更少.
3 结 语
本文针对音频信号的稀疏表示问题,提出了1种可迁移的稀疏表示字典学习方法,给出了初始字典的选择方法,提出了基于音频信号本质特征与原始信号的字典联合学习方法,通过音频信号本质特征对字典进行学习,使字典具有可迁移性,并利用原始音频信号对字典进一步优化,使其更加适用于音频信号的稀疏表示,通过实验对本文方法学习的字典的可迁移性、稀疏表示效果和效率进行了评价.今后还需要对重构后信号的识别准确率进行评价,以验证学习字典在保持信号内容上的效果.此外,还会将本文方法用于其他信号,如脑电信号,从而扩展方法的适用性.
