心音识别的机遇与挑战: 深圳心音数据库简介
2020-06-28董逢泉戴振宇博雅恩
钱 昆,董逢泉,任 昭,戴振宇,董 博,博雅恩,5
(1. 东京大学 身体教育学实验室,日本 东京 113-0033; 2. 深圳大学总医院 心血管内科,广东 深圳 518055;3. 奥格斯堡大学 嵌入式智能保健医疗与社会福祉实验室,德国 奥格斯堡 86159;4. 温州医科大学附属第一医院 心内科,浙江 温州 325035;5. 帝国理工大学 语言音频与音乐课题组,英国 伦敦 SW72AZ)
心血管疾病(Cardiovascular Disease, CVD)是人类致死率最高的疾病之一.根据欧洲心脏网络(European Heart Network, EHN)最新公布的调查报告显示: 由心血管疾病导致的死亡人数占到年病死人数的45%[1].另外,结构性心脏病的诊断和治疗经历了漫长的探索过程,随着介入治疗领域许多新的手段与方法的不断涌现,结构性心脏病的治疗取得了突飞猛进的发展.结构性心脏病是指解剖异常引起心脏结构的改变所造成心脏的病理生理变化.它包括: 1) 先天性心脏病异常,如室间隔缺损(Ventricular Septal Defect, VSD)、房间隔缺损(Atrial Septal Defect, ASD)、动脉导管未闭(Patent Ductus Arteriosus, PDA)等.2) 心脏瓣膜病(二尖瓣、主动脉瓣等).3) 心肌病(肥厚性心肌病、扩张型心肌病、致心律失常型右室心肌病等).4) 心肌梗死后室间隔穿孔、室壁瘤等.听诊器听音是心内科医生检查心脏状态最常见的手段之一,其便捷、快速、廉价的优势在临床诊断上得到充分体现.然而,研究表明: 大约只有不到20%的内科实习医生可以熟练使用听诊器去筛查心血管疾病[2].此外,培养1个可以熟练使用听诊器的内科医生需要大量的训练和临床经验的积累[3].随着心电图、心脏彩超等检查手段的普及,心脏听诊技能在医生中有进一步显著退化的趋势,在一些缺乏检查手段的农村,基层社区等地方,心脏听诊的缺失意味着病人冒着很高的心血管疾病和结构性心脏病的漏诊风险.近20年来,随着机器学习和信号处理技术的发展,开发基于机器听觉的自动听诊系统受到广泛关注[4].Ismail等[4]对基于机器听觉的心音识别工作进行了系统性的调研.前述工作中对于心音的识别主要集中在心音切割和心音识别两个方面.前者关注将整段的心音数据切割成若干组成部分: S1(由二尖瓣和三尖瓣关闭引起)、S2(由主动脉和肺动脉关闭引起)、杂音等.后者关注从心音数据的分析中判断受试者是否有心血管疾病.
相关工作取得了一定的成果,但心音识别领域依然处于亟待发展阶段.相关的研究存在以下4点不足.1) 标准化的数据库极度缺乏.表1对公开的心音数据库[5-6]与本文所介绍的深圳心音数据库(Heart Sounds Shenzhen, HSS)[7]进行了对比.可以看到,当前最大的公开心音数据库为PhysioNet心音数据库[5].然而,此数据库包含多个医学中心采集的数据,采集设备的配置、数据标记的方法、数据的预处理等方面都不一致.HSS是迄今为止公开的单一医学中心收集和标注的最大的心音数据库.2) 实验范式不统一.前述工作中,受试者独立性(subject independency)被很多学者忽略,这样极易造成结果的过分乐观.同时,多数工作采用交叉验证法(cross validation),这样不利于实验的可复现性.3) 模型的评价指标不一致.识别率、召回率、精确度被广泛使用,但是对于心音数据这类非均衡数据,这些指标的使用往往有局限性.4) 相关工作之间缺乏可比较性.由于数据库的标准化欠缺以及所用的模型评价指标不一致,不同学者之间的工作缺乏可直接比较性.这样也限制了心音识别领域的发展.
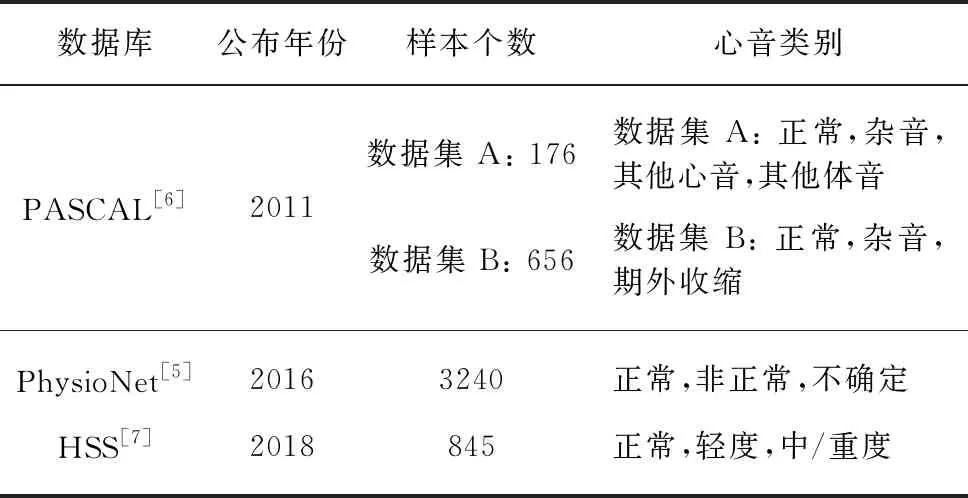
表1 HSS 与其他公开的心音数据库的比较Tab.1 Comparison between HSS and other released heart sound databases
为了解决上述问题,深圳大学总医院于2018年联合德国Schuller教授团队在INTERSPEECH ComParE挑战赛上公开了HSS数据库.本文向国内学者重点介绍此数据库以及Schuller团队提出的国际前沿的音频处理与识别技术,通过对方法的介绍和讨论,吸引国内同行的关注和展开后续的工作.
1 深圳心音数据库
由深圳大学总医院录制的全新心音数据库(HSS)在2018年的INTERSPEECH ComParE挑战赛上首次公布[7].作为标准化数据库,HSS从数据采集、标注,到后期归一化处理和划分都严格按照INTERSPEECH ComParE挑战赛的规定进行.心音数据采集工作得到了深圳大学总医院伦理委员会的批准,共采集到合计845个音频文件(总时长约423min,单个时长约30s),来自170位志愿者的心音数据(女性55人;男性115人,平均年龄为65.4岁,年龄标准差为±13.2岁,年龄范围在21~88岁).数据采集装置采用高品质电子听诊器(美国Eko CORE),配置蓝牙4.0无线传输数据功能,采样频率为4.0kHz.心音主要通过4个区域采集: 二尖瓣、三尖瓣、动脉瓣和肺动脉瓣.数据采集后,经心内科医师结合心脏彩超对数据进行标记,划分为3类,即正常、轻度和中/重度.
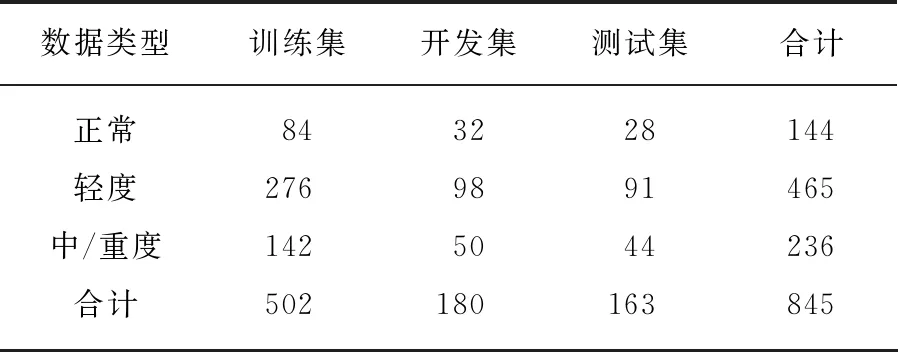
表2 HSS的数据集划分Tab.2 The data distribution of HSS
综合考虑性别、人数、数据类别,HSS将数据整体划分为训练集(train)、开发集(development)和测试集(test).相较于之前心音识别研究中多数工作未考虑受试者独立性,HSS严格确保单个志愿者提供的心音数据只出现在1个数据集中.在训练模型时,训练集和开发集的数据可以用来对模型的参数进行调整和优化,而测试集的数据只能用来最后进行1次测试,从而衡量系统的性能.HSS数据集的划分见表2.
2 标准化方法
为了符合成功举办了10届的INTERSPEECH ComParE挑战赛提倡的科学研究的广泛参与度和可复现性的要求,Schuller团队除了公开提供数据库以外,还会提供包含信号处理、机器学习前沿算法的公开工具包,为参赛者提供参考依据和作为改进其算法的基础.本节将为读者分别介绍针对HSS心音数据提供的几种算法框架.
2.1 openSMILE提取特征
openSMILE工具包[8-9]提供传统声学信号处理方法常用的特征,包括梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient, MFCC)、心理声学特征、频谱能量特征等.通过首先对音频信号提取低层次特征(Low-Level Descriptor, LLD),然后通过功能函数(functional)对基于帧的低层次特征进行统计学特征再提取,从而实现对1段时间的音频信号样本进行统计信息提取,并且摆脱样本时间长度不一致对静态机器学习模型(如支持向量机(Support Vector Machine, SVM))的限制.2018年的INTERSPEECH ComParE挑战赛选用了ComParE特征集,该特征集作为广泛使用的特征集,具有特征声学意义明确、鲁棒性强、性能稳定等特点,被广泛应用于除了语音和音乐外的其他声学识别领域,如鸟声识别[10]、鼾声识别[11]、声音场景识别[12]等.ComParE特征集包含了65个声学低层次特征[13],另还有相关功能函数被应用于再提取统计特征[13],共计提取6373维度特征.
2.2 openXBOW提取特征
openXBOW工具包[14]提供基于词包法(Bag-of-Words, BoW)的特征提取途径.词包法最早应用于自然语言处理(Natural Language Processing, NLP)[15].而“词包”的概念最早可以追溯到20世纪50年代[16],其基本思想可以简单概括为通过构建字典(codebook),从而统计1段信息中相应单词(words)出现的频率,从而得到可以描述信息的统计特征.对音频识别领域,首先,基于帧的低层次特征可以从音频信号中通过信号处理算法提取出来.然后,通过无监督的聚类方法(openXBOW默认采用K-means++算法[17])生成字典.最后,通过统计单词在样本出现的频率,即词频(Term Frequency, TF),得到可以用来构建分类器进行模式识别的特征.词包法的详细原理和openXBOW的工作原理可以参考文献[14].相比于传统的基于功能函数的特征提取方法,词包法的优势在于可以从训练数据全局出发,提取出更有统计信息的特征来描述数据样本.
2.3 auDeep提取特征
auDeep工具包[18]提供基于“序列到序列”(sequence to sequence learning)方法,从音频信号中自动提取具有时序信息的特征.首先,音频信号被转换成图像(语谱图).然后,通过基于自动编码器(autoencoders)和递归神经网络(Recurrent Neural Network, RNN)结合,在“序列到序列”的方法下进行高层次特征提取.最后,所提取的特征可以通过分类器,如支持向量机、多层感知器(Multilayer Perceptron, MLP)、随机森林(Random Forest, RF)等模型完成分类任务.此方法在特征学习阶段是完全无监督模式,同时通过递归神经网络可以学习到信号的动态时序信息.
2.4 End2You端到端框架
End2You工具包[19]提供基于“端到端框架”的模型,摆脱了传统学习中需要耗费大量时间和专业知识的人手动设计特征[20]的环节.原始的音频信号通过由卷积神网络(Convolutional Neural Network, CNN)和递归神经网络组成的深度学习(Deep Learning, DL)模型自动学习到特征,从而完成分类任务.在整个“端到端框架”中,不涉及任何需要人类专家知识去设计声学特征,而是通过深度学习技术[21]自动学习到信号的特征.
2.5 模型评价指标
如同很多医学信号,HSS在数据样本分布上体现了极度明显的非均衡特征(imbalanced characteristic).因此,采用传统的评价指标,如识别率(accuracy),将会导致对样本数量多的那类数据过于乐观和对样本数量少的那类数据过于悲观的情况出现.INTERSPEECH ComParE挑战赛沿用了之前使用的无加权平均召回率(Unweighted Average Recall, UAR)作为对模型的评价指标,其定义为每类数据样本召回率(recall)的平均值.
3 讨 论
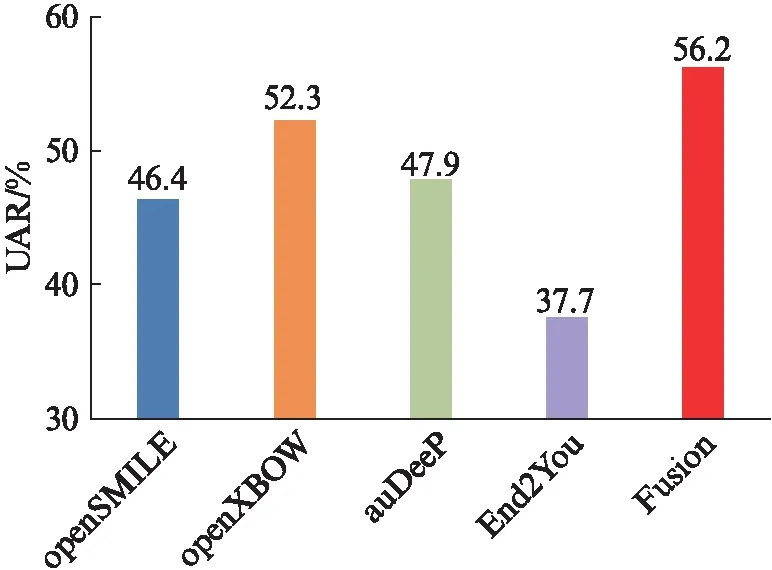
图1 官方公布的测试集上的最好结果[7]Fig.1 The best results achieved on the test set by released official baseline[7]
图1所示为官方公布的不同方法在测试集上的最好性能的对比.最好的结果是由两个独立训练的模型经过投票选择的融合后取得的(UAR: 56.2%)[7].端到端框架模型在这组心音数据的表现上没有展现出很好的性能(UAR: 37.7%).其原因可能是由于数据规模有限,很难利用深度学习模型学习到鲁棒性强的心音高层特征.对于单个模型而言,词包法表现性能最为优越(UAR: 52.3%).在官方给出的基准实验中,基于openSMILE和基于openXBOW的特征都是通过对ComParE特征集中的低层次特征再提取得到,两者分别应用了功能函数和词频统计方法.官方的实验结果与Qian等[11]在鼾声识别中的研究有一致性,即相较于功能函数,词包法提取的特征更具有全局的统计意义,从而表现出比功能函数特征更好的性能.值得注意的是,基于auDeep提取的特征表现性能良好(UAR: 47.9%).该方法在特征提取阶段采用无监督方法训练,能有效学习心音信号的时间序列信息,由于直接从语谱图中提取特征,因此也摆脱了需要手工设计特征的环节,大量减少了人类专家的工作量.并且,结合了auDeep提取特征训练和openXBOW提取特征训练的模型可以提升系统的性能,因此,多特征、多模型融合技术是未来值得关注的方向.
需要指出的是,3个表现性能最优的单个模型,即openSMILE、openXBOW和auDeep提取特征训练的模型,都是通过传统的短时傅里叶变换(Short-Time Fourier Transformation, STFT)[22]取得的.尽管此方法成功应用于语音、音乐和其他音频领域,鲁棒性也较强,但依然无法克服短时傅里叶变换由于类似海森堡不确定性原理所带来的无法在时域和频域都取得优良分辨率的缺陷[23].心音信号既属于音频信号,也属于生理医学信号,对于生理医学信号,小波变换(Wavelet Transformation, WT)[24-25]提供了不同于傅里叶变换的另一种分析方法.小波变换的多分辨率的特性已经在鼾声识别[11,26-27]和声音场景识别[12,28-29]领域取得了一系列成功,因此,未来可以探索基于小波变换的心音特征的提取方法.同时,结合深度学习技术来提升模型的整体性能.
4 结 语
本文介绍了最新公布的标准化心音数据库(HSS)以及随INTERPEECH ComParE挑战赛提供的前沿的声音识别算法.当前官方基准实验取得了最高56.2%的UAR,传统的声学特征提取方法和前沿的方法都分别取得了良好性能.然而,现阶段心音识别的研究局限性仍然存在,如公开数据库较少、算法可复现性差、评价指标不统一、实验方法缺少标准化等.作为多学科交叉领域,心音识别方面的工作需要国内外同行的共同努力.
