车内声品质主观评价模型及中频噪声优化*
2020-05-28王坤祥韩晨扬杨鄂川
张 勇,孟 天,王坤祥,韩晨扬,杨鄂川
(1.重庆理工大学车辆工程学院,重庆 400054; 2.重庆理工大学,汽车零部件先进制造技术教育部重点实验室,重庆 400054;3.重庆市车辆检测研究院有限公司,重庆 400054)
前言
随着汽车工业的发展,汽车NVH技术也发展得愈加成熟,车内噪声问题成为衡量汽车品质的重要指标[1]。特种车车内噪声会影响到驾乘人员的反应速度以及接受和识别各种信号的能力,因此对特种车车内噪声的研究有十分重要的意义。“声品质”的概念最早于20世纪80~90年代初提出,其定义为反映人对声音的主观感受。2007年,韩国仁荷大学Kim Sung Jong等[2]引入神经网络对客车车内声品质进行了研究,在试验的基础上利用人工神经网络建立了声品质主客观评价间的联系,从而实现了声品质的客观评价,从此神经网络与声品质的结合应用开始被广泛应用。对于车内中频噪声的预测,国内外学者主要采用有限元 统计能量混合(FE-SEA)方法。2011年 Qin Xiaolong等[3]使用混合 FESEA方法对车辆结构中频噪声进行分析,建立了车辆的混合FE-SEA模型在200~500 Hz范围内对车辆的声固耦合系统进行预测,并验证了该方法的正确性。2013年Xu Hongmei等[4]在搭建车辆的混合FE-SEA模型中简化前围板为FE子系统,并对前围板的中频声传递损失进行了预测。同年,Chen等[5]建立了轿车混合FE-SEA模型,完成了对车内中频噪声仿真预测,并通过对前风窗玻璃的材料属性进行修改,不仅使主驾驶员头部声腔的噪声降低,而且使整车质量更轻。本文中建立了某特种车车内噪声主观评价烦躁度和声品质客观参数间的Kriging模型,利用频段滤波结合Kriging模型分析了影响车内噪声主观烦躁度的主要频段,并采用FE-SEA的方法,建立特种车混合FE-SEA模型,对车内中频噪声进行分析,并提出降低车内噪声的改进措施。
1 声样本的采集、处理及主观评价实验
声样本的采集实验条件参照标准GB/T14365—1993《声学机动车辆定置噪声测量方法》[6]、GB/T18697—2002《声学汽车车内噪声测量方法》[7]。实验过程中,采用的主要仪器设备有LMS Test.lab数据采集系统、朗德人工头HMSIV0、三向加速度传感器和传声器。实验设备和部分测点位置如图1所示。样本采集实验中选取了3辆不同型号的特种车,实验工况包括空挡(750,1 350,2 000,2 500 r/min),2~4挡(30,40 km/h),4挡(50 km/h)和 4与5挡(60,70,80 km/h)。共有 17种工况,实验共得到68个有效噪声样本(尽量均匀包含了17个工况)。

图1 人工头HMSIV0和驾驶员处测点
声品质的主观评价是以评价实验的形式对评价对象进行描述,再通过统计学方法来获得合适的评价术语以描述主观感知特征,最终对声品质进行区分评价[8]。常用的有等级评分法、简单排序法、成对比较法和语义细分法等。本文中选择了等级评分法进行试验,以烦躁度作为声音属性,把等级分为了0~10的11个等级来进行主观评价,0分表示声样本非常好听,可接受度非常高,10分则表示难以接受,烦躁程度达到极限,如表1所示。

表1 声品质烦躁度等级
本次主观评价实验选取了35名评价人员,身体状况健康且听力正常。男女人数分别为30和5名;有声学评价经验者10名;有驾驶经验者23名。每个声音重复听3次,间隔时间为3 s,之后有10 s的时间对该声音文件进行评价。由于多种干扰因素和评价者主观评价的差异存在,致使所得结果值不完全准确可靠,为获得有效的结果值,需要进行有关的数据检验与剔除,表2为实验得到的部分主观评价值。
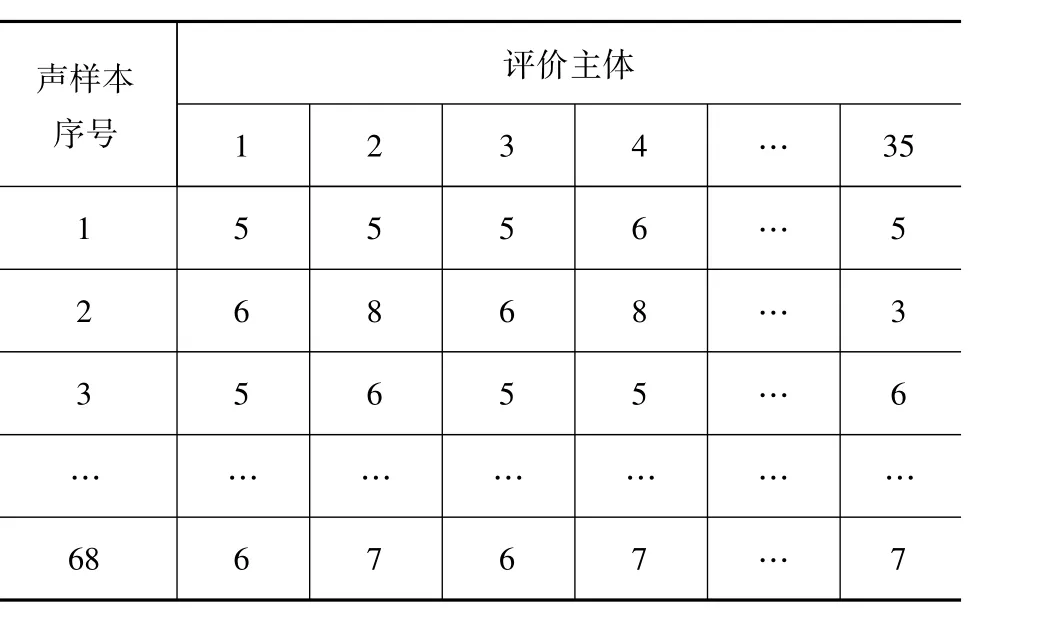
表2 部分主观评价值
在获得的35份评价数据中进行数据检验,使用Spearman相关系数为标准,剔除掉不稳定的评价人员序号,保留相关系数较高的18位评价主体。为保证结果的可靠性,对剩下的评价主体进行了K-均值聚类分析,把评价者分为4类。表3为聚类分析的结果,剔除评价者最少的第3组。对剩下的评价主体的结果进行算术平均,最终得到烦躁度主观评价等级值。

表3 聚类分析分类
使用Head Acoustics公司的ArtimiS软件对68个声样本进行5种心理声学客观参数的计算。分别为总响度(Zwicker响度)、粗糙度、尖锐度、响度和AI指数。最终得到特种车车内声样本的客观参数值和烦躁度主观评价值,如表4所示。

表4 客观参数与主观评价值
2 Kriging模型的建立与检验
Kriging近似模型是用于估计方差最小的无偏最优估计模型,由局部偏差与全局模型组合而成。统计学上,此模型的基础是变量的变异性和相关性,是一种在一定的区间内对变量值进行无偏估计的方法。Kriging近似模型有如下表达式:
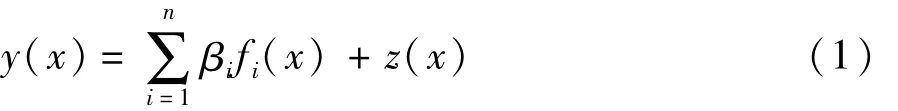
式中:fi(x)为第 i个已知回归函数,一般取定值;βi为回归模型的权重系数;z(x)为近似模型产生的偏差,为服从(0,σ2)标准正态分布的一个随机过程。z(x)的协方差为
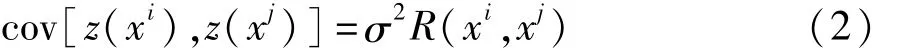
式中:xi和xj为任意两个采样点;σ2为过程方差;R(xi,xj)为相关函数;i=1,2,…,n,j=1,2,…,n(n为样本点数)。常用的 R(xi,xj)为高斯函数,表示为
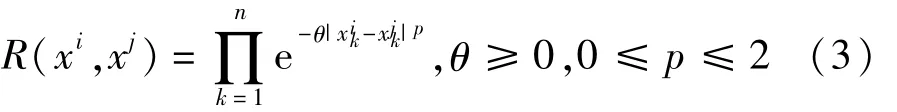
式中:k为空间维度;θ为相关函数值随|xik-xjk|的变化程度;p为模型平滑度。
为方便公式表示,有如下定义:
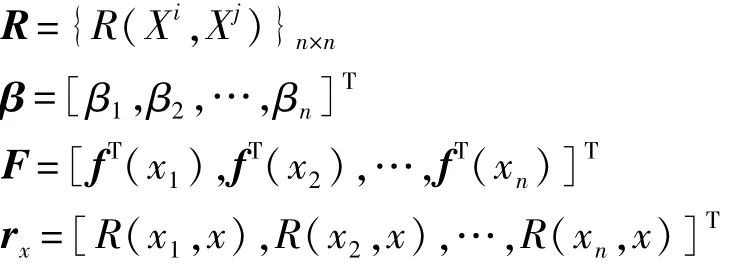
对未知点x处响应值y(x)的最佳线性估计表示为
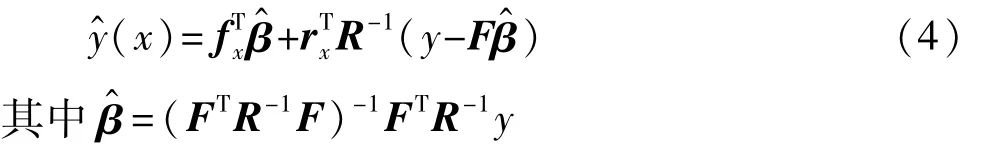
根据表4建立5种心理声学客观参数与主观评价值之间的Kriging近似模型。通常模型的预测精度用复相关系数R2(R-Square)、均方根误差RMSE(root mean square error)和最大绝对误差 MAPE(maximum absolute percentage error)进行评估。利用交叉验证方法进行误差分析,得到该模型的R2=0.984,MAPE=0.09,RMSE=0.042,满足模型精度要求,主观评价值的预测值与实际值误差散点图如图2所示。

图2 误差散点图
3 滤波分析
将 24个频带划分成6段(0-2,2-5,5-9,9-13,13-18和18-24 Bark)分别进行带阻滤波同时计算上述5种心理声学参数,将参数矩阵作为Kriging模型的输入,得到主观评价预测值,如图3所示。由于进行的是带阻滤波,故滤波后主观评价值相差越大,说明该频段对主观评价值的影响越大。提取滤波前后主观评价值相差最大的3者,按差值由大到小排列,如表5所示。
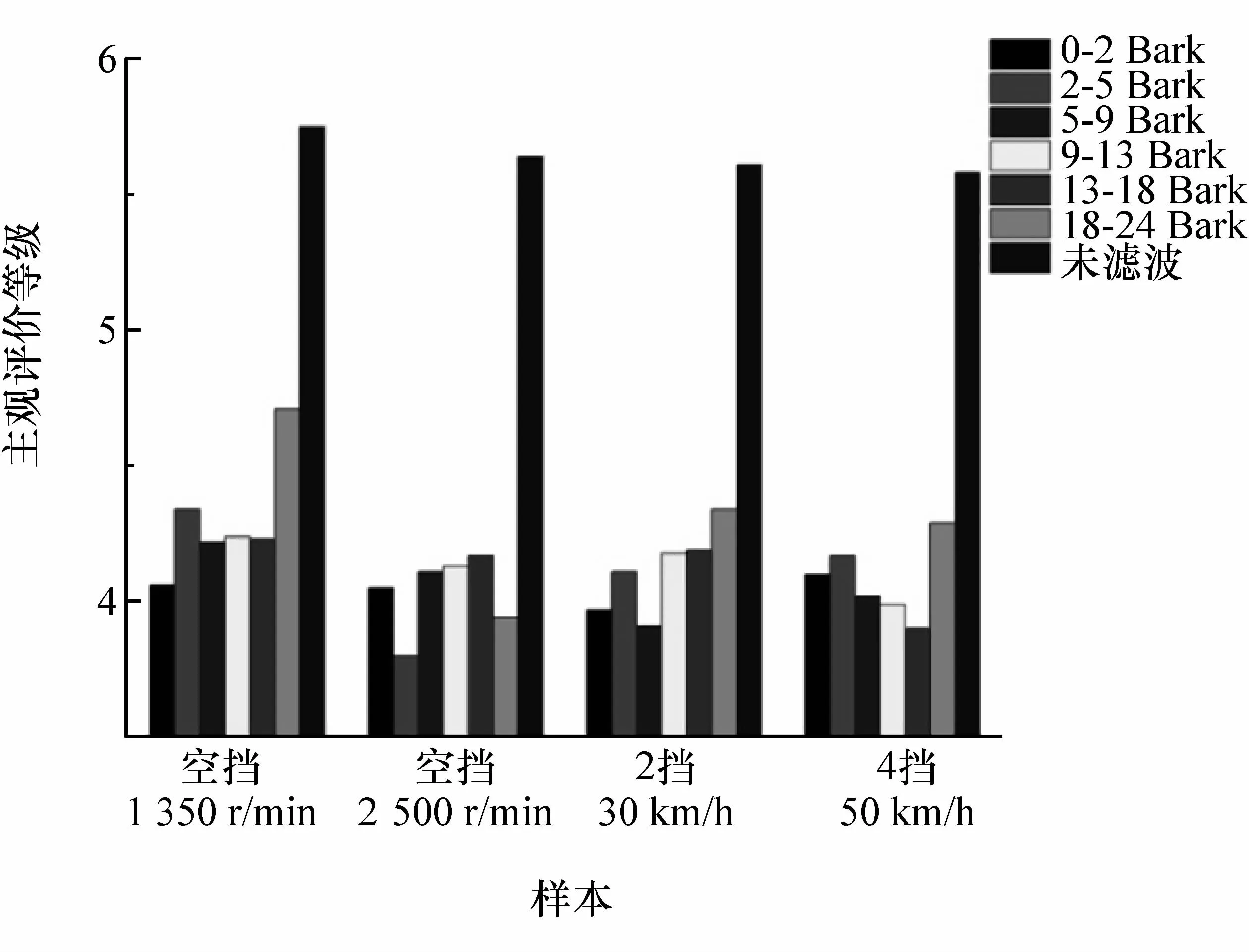
图3 不同工况频段滤波后主观评价预测图

表5 频段对主观评价值影响程度表
由表5可知:1 350 r/min工况时0-200 Hz频段对主观评价值影响最大;2 500 r/min工况时200-500 Hz频段对主观评价值影响最大;2挡30 km/h工况时500-1 000 Hz对主观评价值影响最大;4挡50 km/h工况时2 000-4 000 Hz对主观评价值影响最大。总结发现,在空挡工况下对车内声品质的主观评价值影响较大的频段主要是中低频阶段,并且随着速度的提升影响主观评价值的主要频段转向中频及中高频。因此下文主要针对车内中频噪声(200-1 000 Hz)进行分析和降噪。
4 车内中频噪声分析与降噪改进
有限元 统计能量混合法即FE-SEA法,是中频噪声分析的主要方法。采用VA One软件的FE-SEA方法,建立整车FE-SEA模型,对车内中频段噪声进行仿真分析,并提出车内噪声优化方案。
4.1 FE-SEA方法原理与模型建立
混合FE-SEA法中子系统分成确定子系统(FE子系统)和非确定性子系统(SEA子系统)两类,对确定性子系统采用有限元法分析,对非确定子系统采用统计能量法进行计算。其中,分别用q1和q2表示确定性子系统和非确定性子系统的位移响应;用来表示子系统包含的所有自由度。FE子系统的非耦合运动方程为

式中:Dd为边界连接处FE子系统的动刚度矩阵;fd为作用在q的外部激励向量。
则第k个子系统的非耦合运动方程表达式为


式中:fext为外部激励作用于耦合系统上的载荷向量;N为混合系统中SEA子系统的总数;Dtot为FE子系统的总体动态刚度矩阵。整理式(7)成系统的平均互谱形式:

式中:〈.〉为整体的平均;D-Htot为矩阵共轭转置求逆的运算;〈Sff〉为互谱力的期望。〈Sff〉的计算公式为
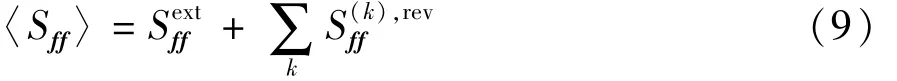
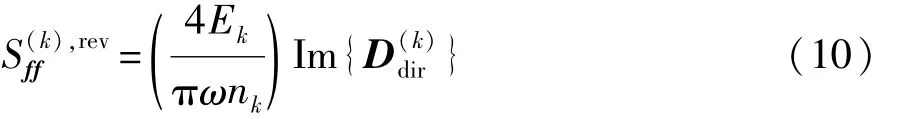
整理式(7)~式(10),可得
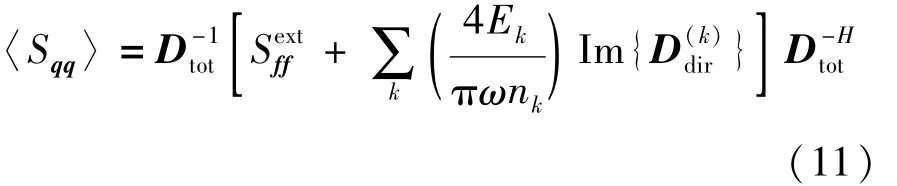
式中:Ek为子系统k的总能量;nk为子系统k的模态密度。
第k个混响场的功率平衡方程为

式中:P(k)in,dir为第k个SEA子系统的直接场功率输入;P(k)out,rev为混响场的功率输出;Pdiss,k为在第k个子系统中的功率损耗。

将式(16)展开,以矩阵的形式表示混响场整体平均响应:
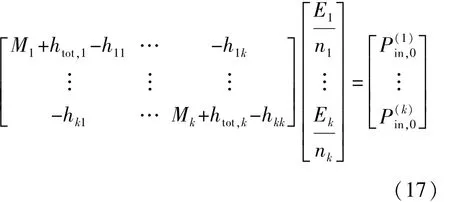
在整车混合 FE-SEA模型中,结合相关准则[9-11]和方法,对整车的子系统进行了详细的划分最终建立出整车的混合模型,如图4所示。
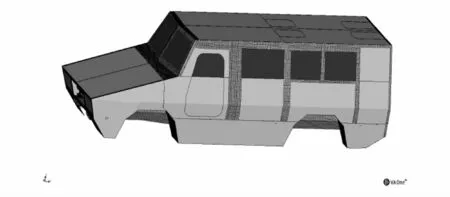
图4 整车的混合FE-SEA模型
由于工况较多,本文中对车内噪声的预测主要是针对怠速2 500 r/min工况,减少了路面不平度的激励和车辆行驶时空气的脉动压力对车内噪声的影响,只考虑了发动机4个悬置处的激励、分动箱2个悬置处的激励和发动机舱与分动箱的声辐射激励,计算得到200-1 000 Hz范围内噪声的1/3倍频程声压级响应,驾驶员和副驾驶员头部声腔声压级仿真值与实验值对比如图5所示。
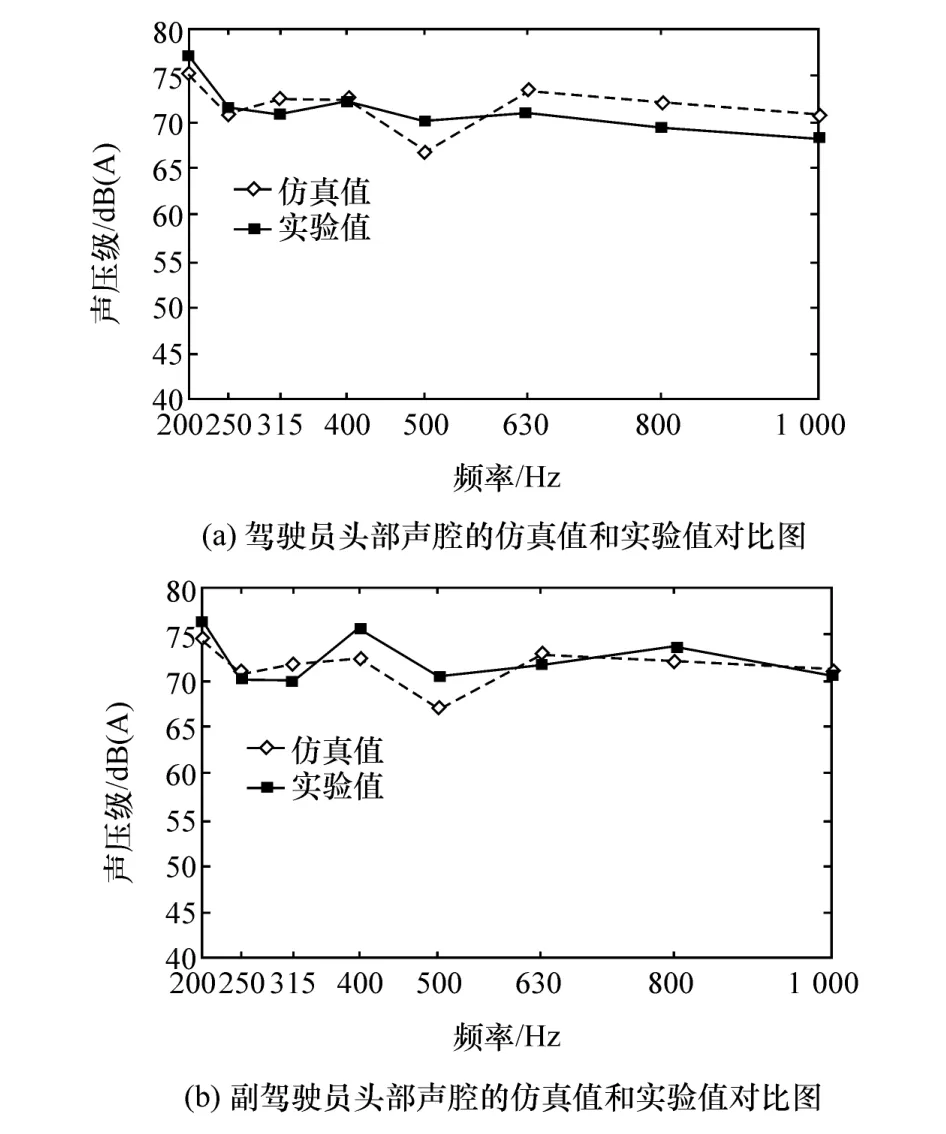
图5 仿真值与实验值对比
由图5可知,在200-1 000 Hz频率范围内,驾驶员和副驾驶员头部声腔的声压级仿真值与实验值,虽然存在一定误差但变化趋势整体一致。计算两声腔各中心频率处仿真值与实验值的绝对误差百分比,得出各中心频率处的误差均小于5%,该工况下驾驶员和副驾驶员头部声腔的总声压级对比如表6所示。由表6可知,驾驶员和副驾驶员头部声腔的总声压级的仿真值与实验值的绝对误差百分比均小于3%。参考相关文献可知[12],该误差百分比能够满足模型的预测精度。

表6 仿真值与实验值的总声压级对比
4.2 车内中频噪声贡献度分析及优化
在VA One中的板块贡献度可由功率流分析的方法获得。借助功率流分析可对各个SEA子系统的输入功率进行排序,进而得到对车内中频噪声贡献较大的SEA子系统。该工况下的车内驾驶员头部声腔和下部声腔的功率输入如图6和图7所示。
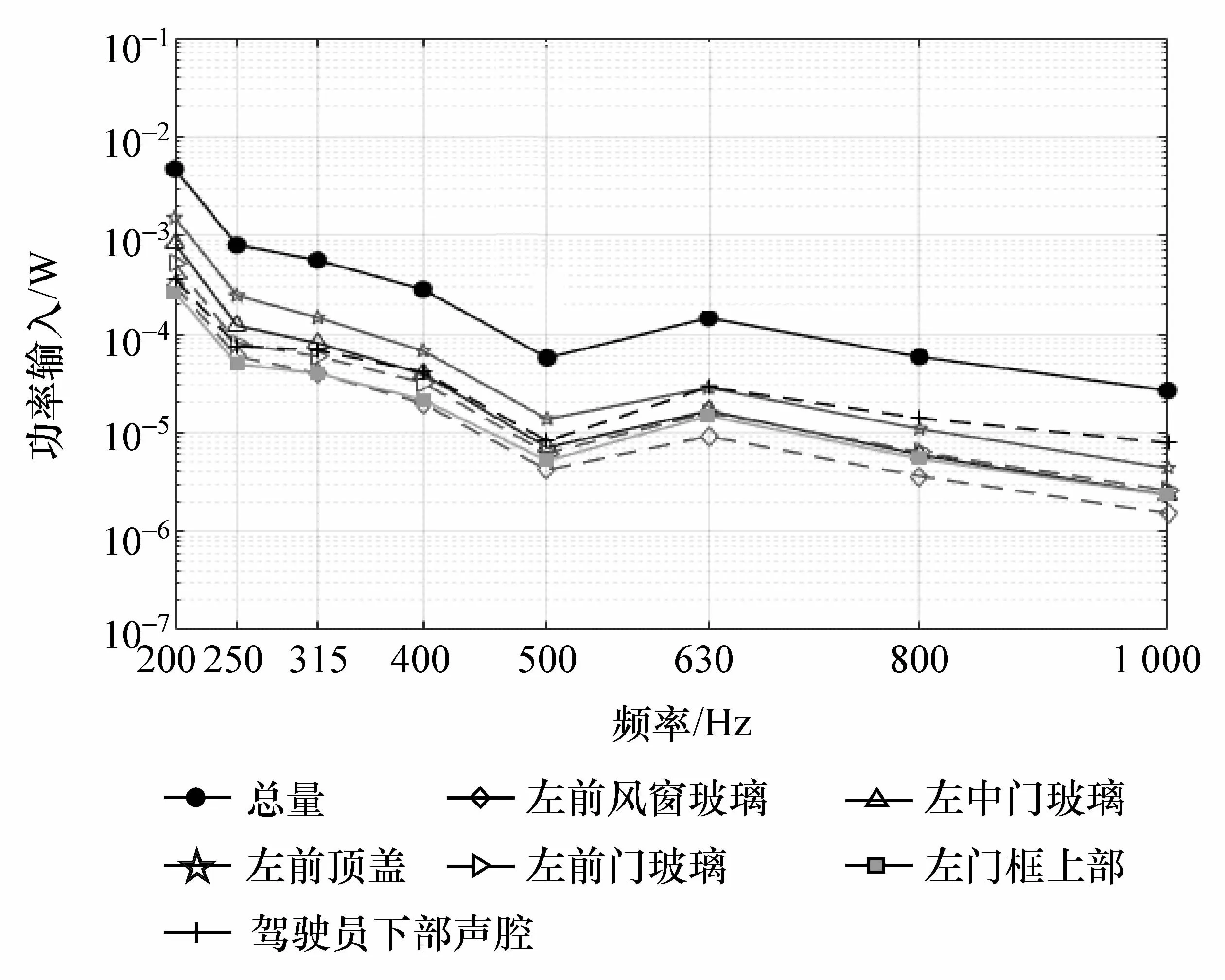
图6 驾驶员头部声腔功率输入

图7 驾驶员下部声腔功率输入
由图6可知,对驾驶员头部声腔功率输入较大的SEA子系统有左前风窗玻璃、左中门玻璃、左前顶盖、左前门玻璃、左前门框上部和驾驶员下部声腔。
由图7可知,对驾驶员下部声腔功率输入较大的SEA子系统分别包括左前门框、防火墙下部、防火墙上部、左中门、地板左1、地板左2、左前门。同时由图6和图7可以看出,各子系统在不同的中心频率的功率输入也不相同,为更清晰地对比各SEA子系统在不同中心频率处对驾驶员头部和下部声腔的贡献量,列出了部分中心频率处各个子系统对驾驶员声腔的能量贡献量统计柱状图,如图8和图9所示。

图8 各子系统对驾驶员头部声腔的功率输入
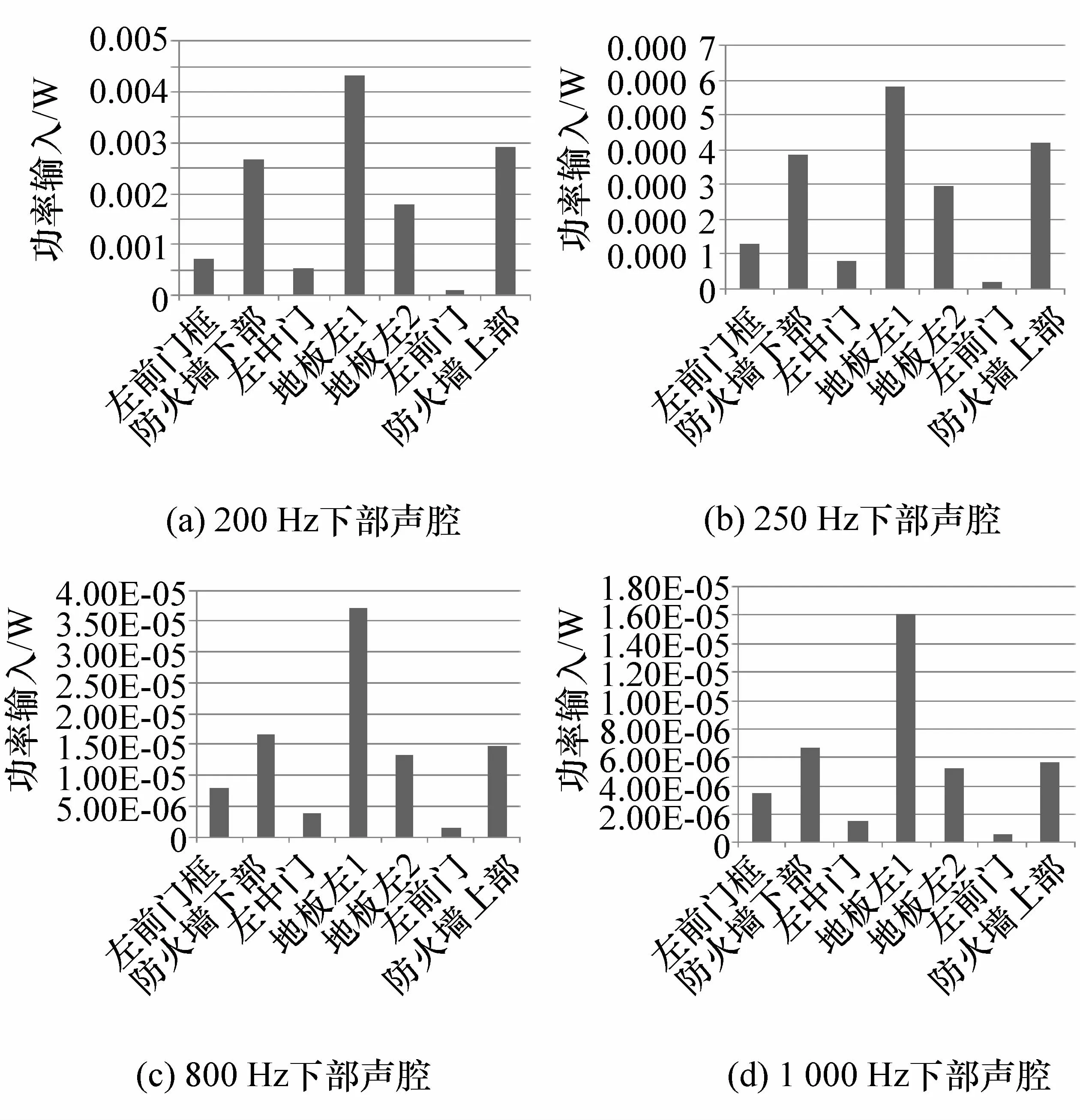
图9 各子系统对驾驶员下部声腔的功率输入
由图8和图9可知,贡献较大的板件包括左前顶盖、左前门玻璃挡框、地板左1、防火墙下部、防火墙上部、地板左2、左前门框、左中门、左前门。对车内中频噪声的优化主要考虑对以上各板件进行NCT处理。
多孔吸声材料具有大量的细微孔隙,当声波入射到材料表面时,一部分被表面反射,另外一部分则进入材料孔隙引起孔中空气和细小的纤维振动,由于空气的黏滞性和纤维的导热性,导致部分声能转换为热能,从而被吸收和耗散使得声能衰减。多孔吸声材料的吸声系数也会随着入射声波的频率而发生变化,随着频率的升高,空隙中的空气在单位时间内的振动次数也随之增加,对声能的效果也会越明显。故本文中对中频噪声的优化主要采用多孔吸声材料。针对防火墙的NCT处理分为防火墙内侧和外侧,对防火墙的外侧采用一层多孔吸声材料处理;防火墙内侧和左前顶盖、左前门玻璃挡框、地板左1、地板左2、左前门框、左中门、左前门采用多层多孔吸声材料处理。汽车内饰中敷设的多孔吸声材料的厚度直接影响到车内声压级响应,考虑到车内空间和使用的方便性,添加的噪声控制处理材料不能太厚且质量不宜过大。通过查阅资料和相关文献[13-14],采用树脂纤维对防火墙外侧进行处理,防火墙内侧、左前顶盖等指向声腔一侧的第1层用模压毡,第2层用PU泡沫进行处理。
在VA One软件中,在对应的各SEA子系统上进行相应的NCT处理,仿真计算出车内驾驶员头部声腔的各中心频段的声压级响应和总声压级。优化前后驾驶员头部声腔的声压级响应对比结果如图10所示,各中心频率处声压级对比如表7所示。
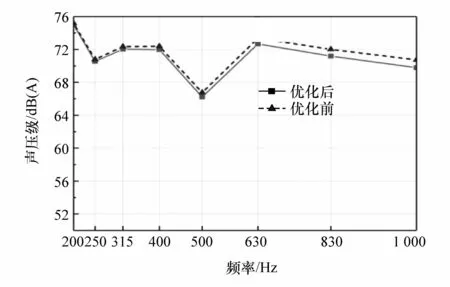
图10 优化前后驾驶员头部声压级响应对比
由图10和表7可知,优化后的驾驶员头部声腔声压级在各中心频率相比优化前均有降低,且在200-1 000 Hz范围内,随各中心频率升高减幅逐渐增大,在1 000 Hz中心频率处减幅最大,其值达到了0.9393dB(A)。最后对驾驶员头部声腔总声压级进行对比,优化前驾驶员头部声腔总声压级为81.251 9 dB(A),优化后驾驶员头部声腔总声压级为80.792 4 dB(A),总声压级降低0.459 5 dB(A)。

表7 优化前后驾驶员头部声压级响应对比
5 结论
本文中建立了主观评价烦躁度和声品质客观参数之间的Kriging模型,通过频段滤波分析可知,在空挡工况下对声品质主观评价等级影响较大的主要是中低频段,且随着速度升高影响主观评价等级的主要频段转向中频及中高频段。
建立了混合FE-SEA模型计算车内中频噪声,通过板件贡献度分析确定了对中频噪声贡献较大的板件,并对贡献量较大的板件进行优化处理。对比怠速2 500 r/min工况下声压级响应,在各中心频率均有所降低,在1 000 Hz中心频率处减幅达到了0.939 3 dB(A),优化后比优化前的车内中频噪声的总声压级降低了0.459 5 dB(A),有效降低了车内场点的中频噪声。
