基于CM-Q学习的自主移动机器人局部路径规划
2020-05-13李彩虹
张 宁,李彩虹,郭 娜,王 迪
(山东理工大学 计算机科学与技术学院, 山东 淄博 255049)
自主移动机器人的路径规划和避障反映的是其与环境的交互能力[1-2],它可以在给定环境执行操作时自行做出决定,这种行为已经在无人监督的任务中普及,机器人通过自主学习执行一系列动作以实现预定目标[3]。目前针对已知环境下的移动机器人避障和路径规划方法已经较为成熟,例如传统的栅格法[4-5]、人工势场法[6-7]等,或者遗传算法、蚁群算法、Q学习等强化学习算法[8],以及较复杂的混合优化算法、基于神经网络的深度优化算法[9]等。
针对未知环境下或者局部情景中的移动机器人路径规划和避障问题,由于移动机器人没有先验知识,对环境了解较少,无法确定所在运行环境中障碍物数量和具体位置,仅仅通过其自身携带的传感器进行环境探测,感知信息并进行局部路径规划,效果不理想。因此,移动机器人在未知的非结构化环境下进行路径规划时,缺乏适应能力和自主学习能力。学者采用强化Q学习算法对移动机器人局部路径规划进行研究。Q学习算法由Watkins等[10]较早提出,在强化学习中应用广泛,是不依赖于环境的先验模型,也是一种无模型的实时学习算法[11-13]。Q学习算法的迭代过程是对环境进行试错和搜索,多次尝试和学习可能的状态-动作对
目前采用Q学习算法进行局部路径规划,存在因先验知识缺乏而导致学习收敛速度慢的情况,学者提出了改进的Q学习算法,如胡俊等[16]在Q算法初始化时加入对环境的先验知识作为搜索启发信息,提出了基于先验知识的Q学习算法(Priori Knowledge-Q Learning),以滚动学习方法解决大规模环境下机器人视野域范围有限,以及因Q学习的状态空间增大而产生的维数灾难等问题。这种方法在一定程度上解决了算法初始阶段探索和学习的盲目性,但在局部规划过程中有限的先验知识只能引导机器人有目的地选择部分路径点,可能得不到局部最优路径。Low等[3]利用花授粉算法(Flower Pollination Algorithm)合理地初始化Q学习算法,并运用于移动机器人路径优化,加快了Q学习算法收敛速度,但只运用在简单的障碍物环境中,对于复杂多障碍物环境下的路径规划没有涉及。
针对上述研究的不足,本文在栅格地图的基础上提出了一种基于CM-Q的移动机器人局部路径规划算法。该算法利用Q学习算法学习最佳状态-动作对,并引入栅格地图中障碍物的坐标变量,利用CM算法进行坐标匹配,以解决移动机器人运行过程中的避障问题,提高移动机器人运行效率,同时规划出局部最优或次优路径,增加算法收敛速度。
1 栅格地图
本文使用栅格地图作为移动机器人路径规划的环境。将移动机器人的实际运行环境量化为栅格,每个栅格表示一个坐标点,并与移动机器人大小相同,起点和终点分别占据一个栅格位置,移动机器人每移动一步的步距大小为一个栅格。
移动机器人的任务是在建立的栅格地图中,利用给定的起点和终点,通过对环境的探测学习,寻找到一条从起点到终点、安全避开障碍物的路径,同时使规划的路径最短。如图1所建立的栅格地图中,移动机器人通过在栅格中自由行走,学习避障,最终要规划出一条从起点Start到终点End的最优或次优无碰撞路径。规定栅格地图边界为障碍区域,移动机器人不能越界,越界视为与障碍物发生碰撞。
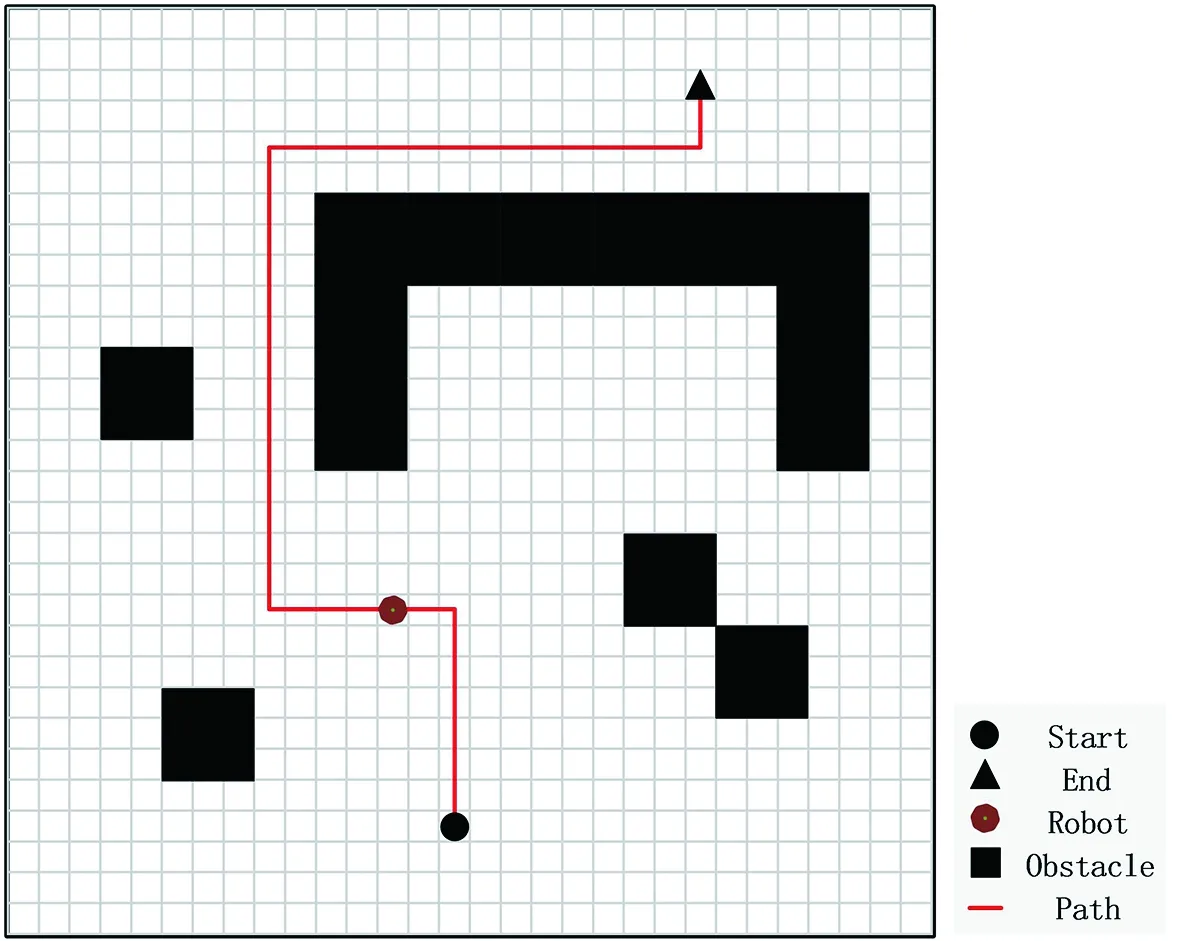
图1 栅格地图Fig.1 Grid map
将栅格地图记为ΩEN,它是一个未知的有界静态环境,它的大小为ΩEN=XLim×YLim,且XLim、YLim为大于0的整数。记ΩEN中移动机器人的起始位置和目标位置分别为Ωstart和Ωend,并且Ωstart≠Ωend,Ωstart∈ΩEN,Ωend∈ΩEN。
ΩEN中分布着有限个静态障碍物ob1、ob2、···、obn。建立与ΩEN大小相同的Ωtable表作为栅格环境二维表,记录所检测到的栅格环境中的障碍物位置。Ωtable表中的行、列分别表示组成障碍物obi的各横、纵坐标。
规定栅格环境二维表Ωtable中每个最小单位障碍物obi由9个坐标构成,每个坐标由单个障碍物obi的对角线交点的横纵坐标及其相应形式表示,记为Ob_bn。组成obi的各坐标为Ob_os,表示为
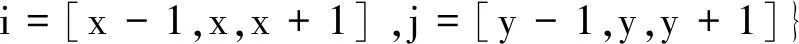
(1)
单个方形障碍物坐标位置示意如图2所示。
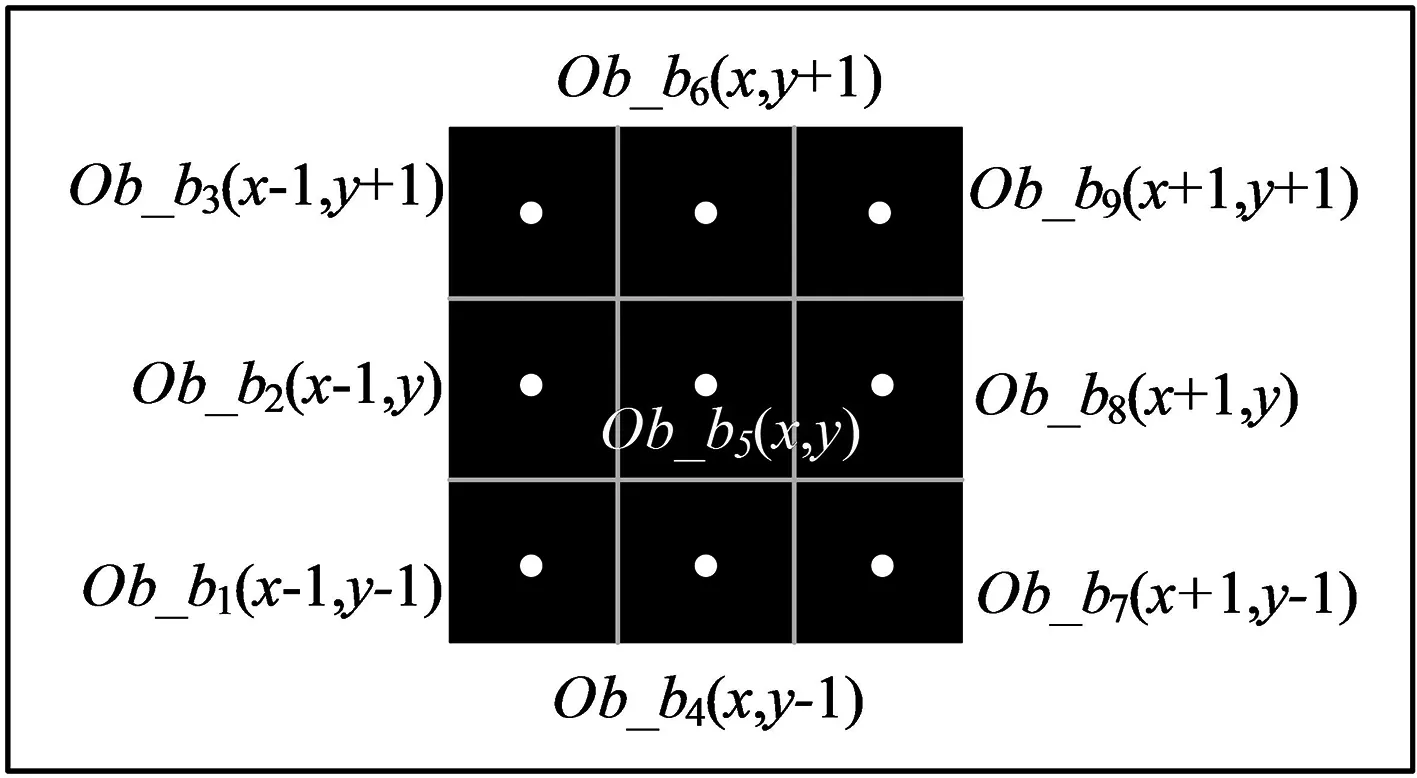
图2 单个方形障碍物各顶点坐标示意Fig.2 The coordinates of each vertex of a single square obstacle
所有单个障碍物坐标集Ob_os组成全部障碍物坐标集,用Ob_pos表示。在ΩEN中标记障碍物所在位置的坐标为
(2)
2 CM-Q学习算法
本文使用Q学习算法来学习最佳状态-动作对,利用坐标匹配的CM算法进行避障,以完成移动机器人的局部路径规划任务。
2.1 状态和动作描述
移动机器人从起点出发,不断探索未知环境,每次成功到达终点时所走过的路径由ΩEN中对应的坐标点联结成的轨迹表示。其中,移动机器人在其所在运行环境中的每个坐标点表示一个状态,记为st,坐标为Ωst。根据栅格地图模型的维数,共有XLim×YLim个状态,所有状态组成的状态集S为
S={st|st=Ωst(i,j),i∈XLim,j∈YLim}
(3)
每个状态下,移动机器人可以执行的动作记为ai。动作可根据当前所处的状态随机进行选择,这里规定移动机器人只能执行上、下、左、右4个动作,每个动作每次移动1个坐标(或1个栅格)位置,动作集A表示为A={ai,i=1,2,3,4}。
当前动作的选择影响下一个状态的表示,这里规定状态和动作之间以坐标进行转换。移动机器人执行4个动作时所对应状态的变化见表1。
表1 状态-动作关系表
Tab.1 The relationship between state and action

集合对应关系状态集S st+[0,1]st+[-1,0]st+[1,0]st+[0,-1]动作集Aa1(上)a2(左)a3(右)a4(下)
2.2 Q矩阵建立
Q矩阵是用来存储最佳状态-动作对Q值的有限二维表,它的大小由状态和动作决定,状态的大小为XLim×YLim,动作为4,所以Q矩阵的大小为XLim×YLim行、4列。Q矩阵表示为
QXLim×YLim×4=
(4)
Q矩阵中每个Q值为移动机器人学习过程中在st状态下,采取动作ai到达下一个状态时,所获得的最大奖励期望值。当Q矩阵中的每个Q值的变化率△Q(st,ai)小于给定的精确度时,Q矩阵收敛,每个Q值都趋于稳定。
由于每次从起点到终点的最优或次优路径可能不止一条,所以每当学习结束时所得到的最佳状态动作对
2.3 回报函数设计
回报函数是用来评价移动机器人避开障碍物并趋向目标行为的判断标准,最终使移动机器人学习规划的路径安全、最短。
将回报函数Rew(r)设计成奖励和惩罚两类。令r为奖惩情况种类,用来判断移动机器人当前所处状态,根据状态给予奖惩。r1表示没有碰到障碍物,奖励为0;r2表示到达终点,奖励100;r3表示碰撞障碍物,惩罚100。回报函数表示为
(5)
2.4 CM避障设计
移动机器人在移动的过程中要进行避障,采用CM避障设计方法,即移动机器人每执行一次动作后的坐标与栅格地图中障碍物所在位置坐标进行匹配,快速判断移动机器人当前运行方向是否存在障碍物,提高其路径搜索效率和避障能力。CM避障方法分为障碍物避障和边界避障两部分。
2.4.1 障碍物避障
根据移动机器人局部避障规则,建立图3所示的局部避障模型示意图。
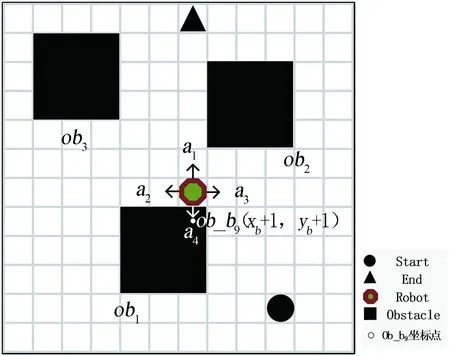
图3 移动机器人局部避障模型Fig.3 Local obstacle avoidance model of mobile robot
设当前移动机器人的坐标为R(xr,yr),令障碍物ob1中心点的坐标为Ob_b5(xb,yb),根据式(1)和图2所示,障碍物ob1右上角Ob_b9坐标等于(xb+1,yb+1)。移动机器人在栅格环境中进行探索学习过程中,执行动作a4后,移动机器人会与障碍物ob1的右上角发生碰撞,此时移动机器人的坐标为R(xr,yr)+(0,-1)=R(xr,yr-1),将R与组成障碍物ob1的各个坐标进行匹配,找到碰撞点的坐标,即R(xr,yr-1)=Ob_b9(xb+1,yb+1),如果xr=xb+1且yr-1=yb+1,说明移动机器人在学习过程中执行动作a4后,碰撞了障碍物。
根据回报函数奖惩规则,发生碰撞对应的表示关系为r3,则Rew(r3)=-100,移动机器人在学习过程中受到惩罚,当下一次遇到类似情况时,移动机器人将不会执行动作a4而执行其他动作。
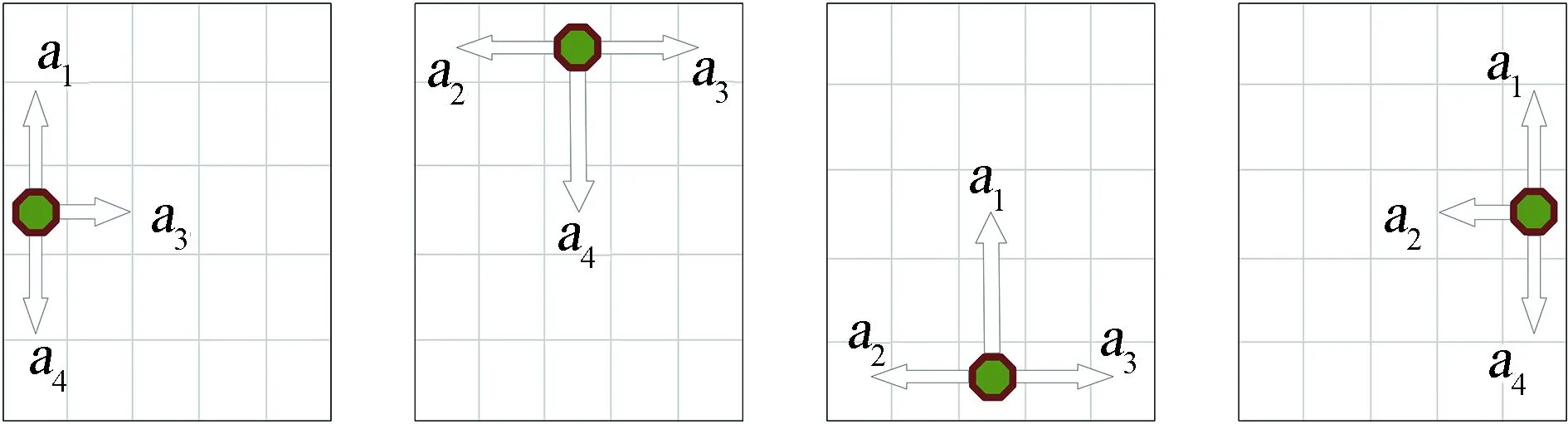
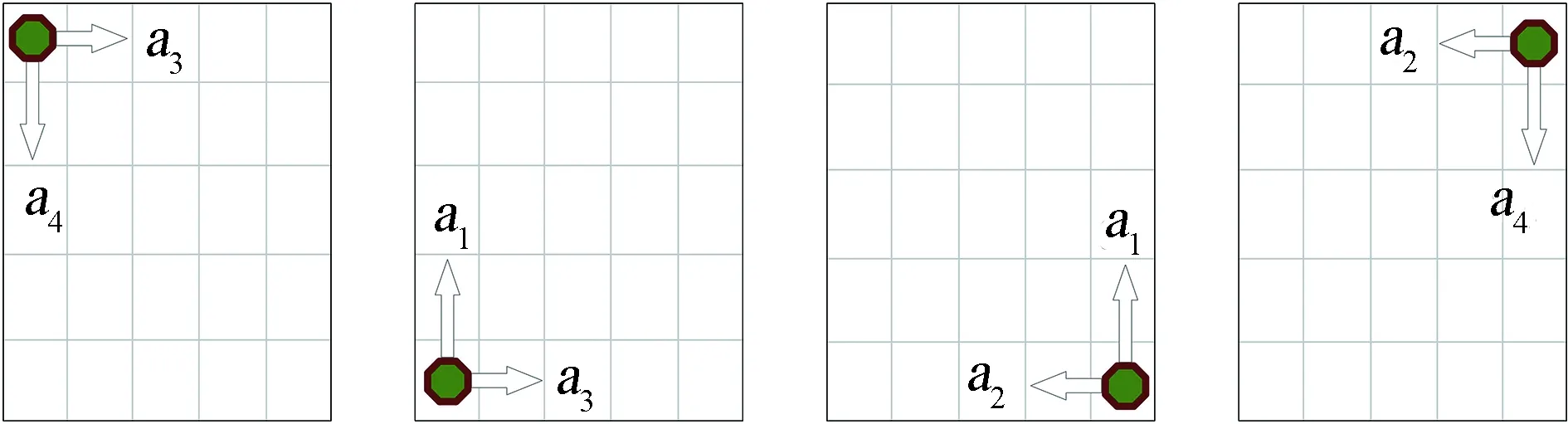
2.4.2 边界避障
移动机器人在栅格环境边缘的行为情况分为两类8种,即左、上、下、右4种侧边界动作情形和左上、左下、右下、右上4种角边界动作情形。移动机器人在侧边界和角边界能够执行的动作分别如图4(a)和图4(b)所示。
(a)侧边界动作示意
(b)角边界动作示意图4 栅格侧边界和角边界动作执行示意图Fig.4 Schematic motion execution diagram of grid side boundary and corner boundary
将底边界、左边界、上边界、右边界坐标分别表示为(x,0)、(0,y)、(x,YLim)、(XLim,y),移动机器人按照CM算法进行避障时,如果其坐标R(xr,yr)等于任意一个边界坐标,则与边界发生碰撞,根据奖惩规则,Rew(r3)=-100,移动机器人受到惩罚,通过不断学习,最终移动机器人不再碰撞边界。
2.5 基于栅格地图的CM-Q算法
基于所建立的栅格地图,运用CM-Q学习避障和路径规划的步骤如下:
(1)清空二维环境表EN和障碍物坐标集Ob_pos,给定移动机器人起点Ωstart和终点Ωend,给定障碍物obi。
建立short_best线性表,存储从起点到终点的历史最佳状态-动作对
初始化移动机器人即时回报Rew0=0,目标点回报值Rewend=100,学习次数初值0,最大学习次数Nmax。
用贪婪策略确定学习率α的公式为
(6)
式中:fix()为取整函数;通常0≤α<1。当给定初始α0值、LearnN、Nmax时,α值可以决定Q值更新速率。
(2)初始化历史最短路径长度shortbest_size=Nmax,迭代计数器初值count=0,清空当前最短路径记录表short_list。
(3)移动机器人对所处状态进行判断,对于∀st∈S,若Ωst∈Ob_pos,则发生碰撞,利用CM-Q算法进行避障,令st+1=st并转到第(4)步;否则根据式(7)选择当前状态st下Q值最大的动作ai执行。
(7)
执行动作ai后,移动机器人转为状态st+1,count=count+1,此时若Ωst=Ωend,则转至第(5)步,否则转至第(7)步。
(4)计算当前环境回报值,用式(5)对移动机器人当前状态-动作执行情况给予奖惩,求出回报函数的值Rew(r)。若移动机器人受到奖赏,则转到第(6)步;若移动机器人受到惩罚,则退回上一状态并转至第(3)步。
(5)当前状态为目标状态,记下当前迭代计数器count的值、历史最短路径short_best及其长度shortbest_size,以及当前最短路径short_list,并转至第(2)步。
(6)当前状态下的强化Q值按式(8)进行更新:
(8)
式中γ为折扣因子,0≤γ<1,通常选择较大的γ使移动机器人获得未来回报的机会更大。在极端情况,当γ=0时机器人只考虑行动的当前回报;当γ接近1时,未来的回报在采取最优行动时变得更为重要。
记录当前状态的最短路径short_list并转至第(3)步。
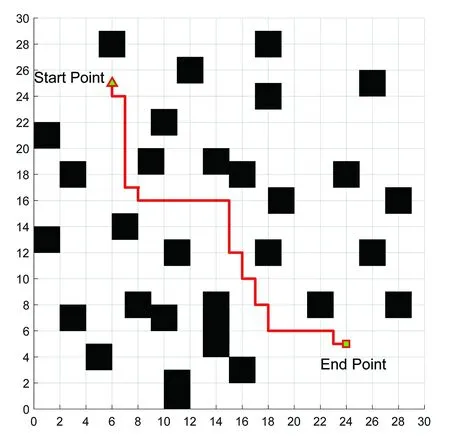
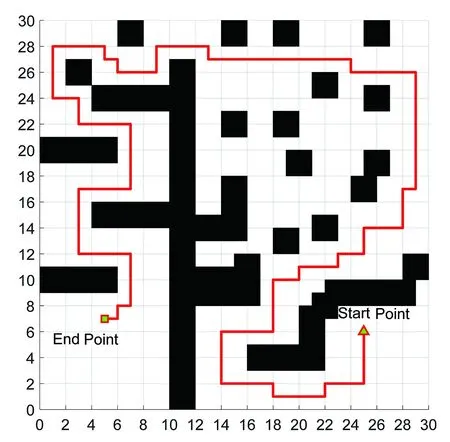
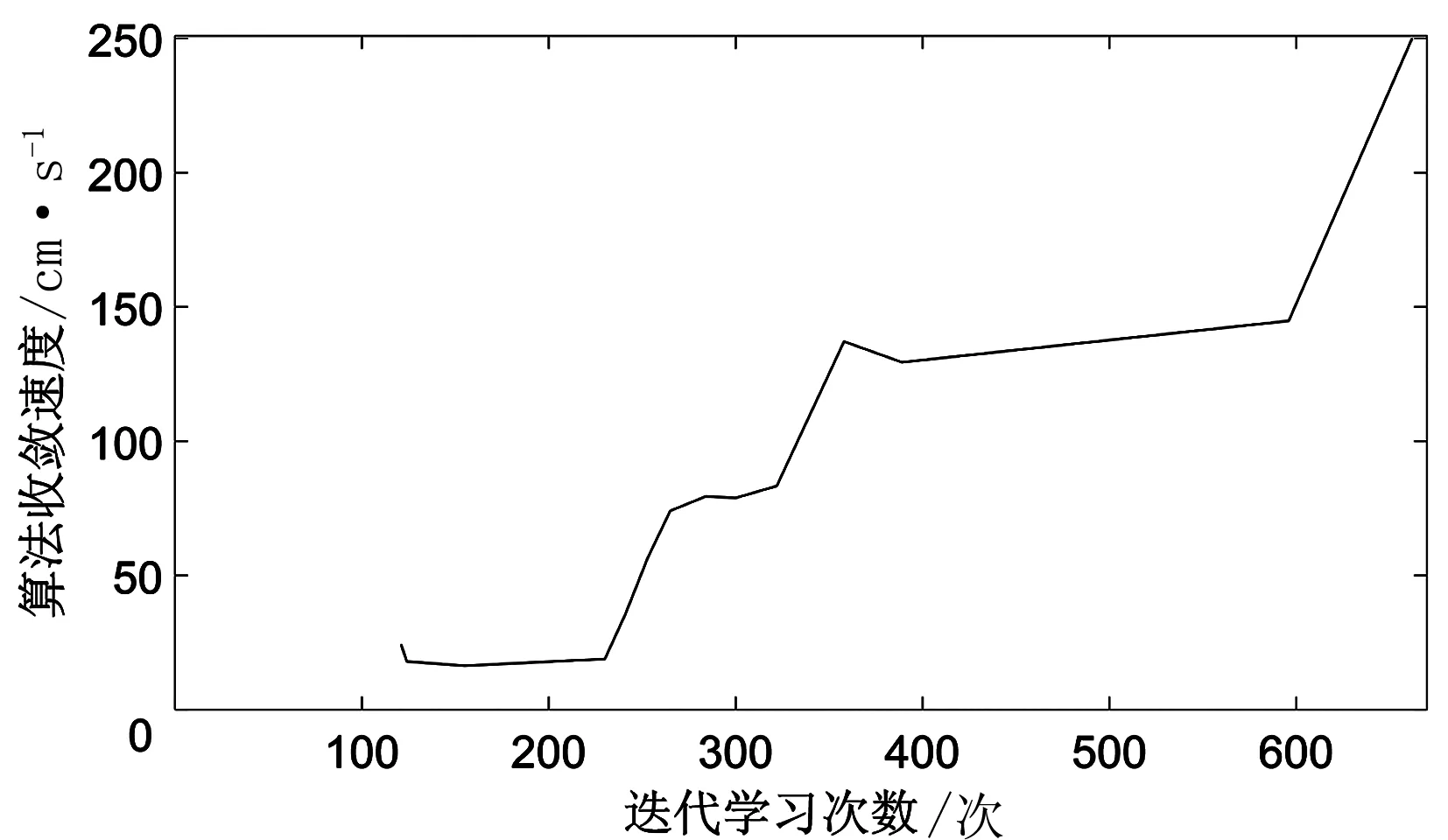
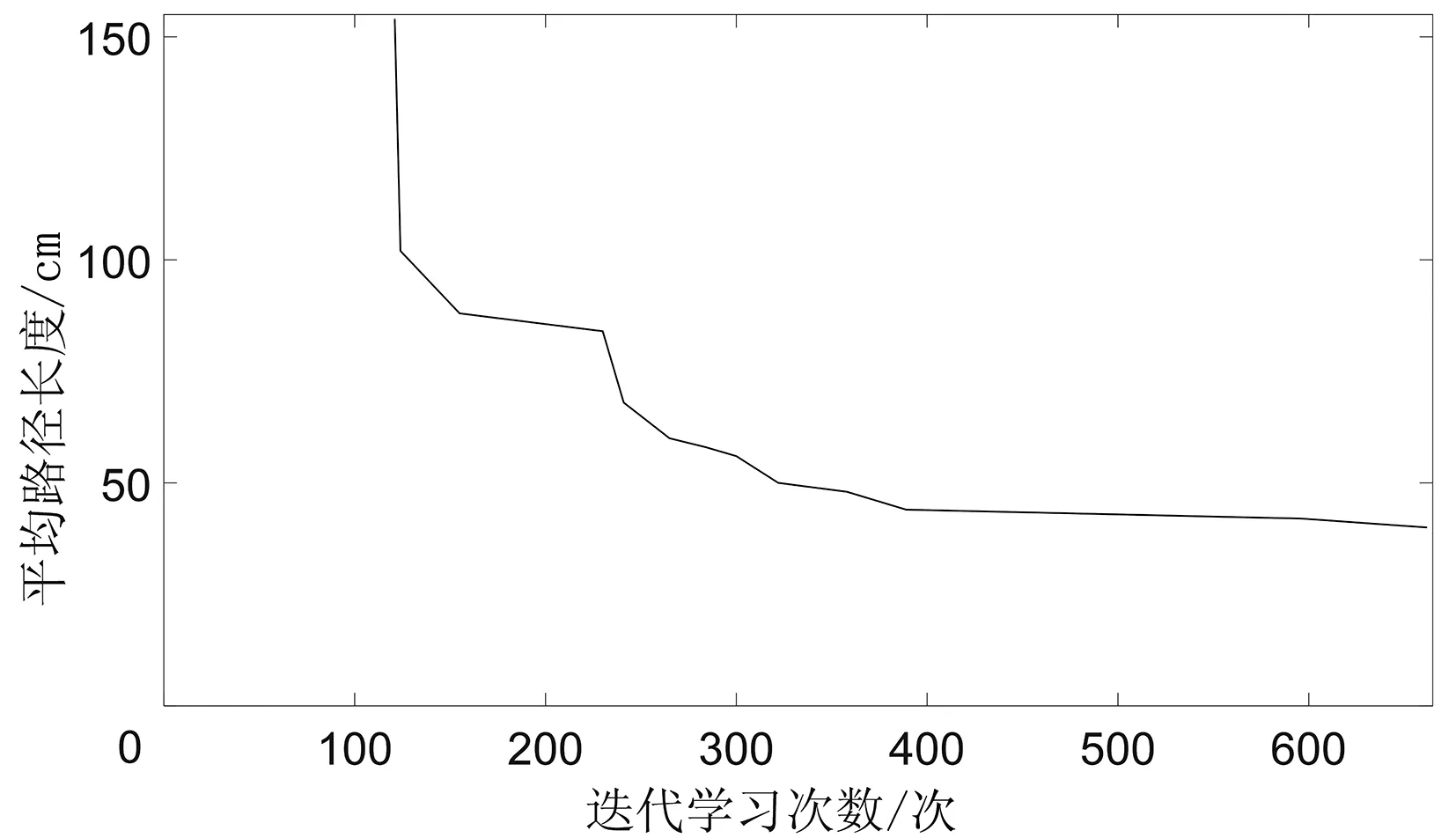
(7)若LearnN 实验环境为windows7,Intel(R)Core(TM)i5-2400CPU3.1GHz,6GB内存,仿真工具为matlabR2016a。在仿真环境下对本文所提CM-Q算法进行测试,验证算法有效性,并将结果与文献[3,17]的进行冗余度比较。 实验均在大小为30×30的栅格环境下进行,运行环境中的起点、终点和障碍物随机设置。进行多次实验后,根据式(4)和式(8),Q值变化率△Q(st,ai)小于给定精确度时,Q矩阵收敛。Q值中包含了式(5)的趋向于最优或次优路径的评价指标Rew(r),则Q矩阵收敛后获得的路径即为最优或次优路径。 未知简单障碍物环境下的移动机器人学习之后的路径规划仿真结果如图5所示。图5中设置的起点为(6,25),终点为(24,5)。移动机器人各次学习情况见表2。 图5 未知简单环境下路径规划Fig.5 Path planning under unknown simple environment 表2 简单环境下CM-Q算法学习测试 实验次数平均学习次数平均路径长度/cm平均用时/s106624638.28205904436.94306904039.88406803837.25506333835.12606323834.97706333835.10806333835.08 在未知简单障碍物栅格环境中加入类似迷宫的障碍物,组成混合复杂障碍物环境,路径规划结果如图6所示。起点和终点分别设置为(25,6)、(5,7),CM-Q算法所用参数设置不变。移动机器人各次学习情况见表3。算法收敛速度与迭代学习次数关系如图7所示。移动机器人到达目标时的平均路径长度与迭代学习次数的关系如图8所示。 图6 混合复杂障碍物环境下规划路径Fig.6 Path planning under complex and mixed environment 表3 混合环境下CM-Q算法学习测试 实验次数平均学习次数平均路径长度/cm平均用时/s101 874147113.74201 915132111.93301 987119118.62401 940111110.75502 000108105.36601 999108105.30702 001108105.39802 000108105.33 图7 算法收敛速度与迭代学习次数关系Fig.7 Relationship between algorithm convergence speed and iterative learning times 图8 平均路径长度与迭代学习次数关系Fig.8 Relationship between average path length and iterative learning times 由表2和表3可知,在相同实验设定下进行了不同次数的实验,随着实验次数的增加,平均路径长度减小,说明还有少数状态没有学习到。当进行了50次实验后,平均学习次数基本稳定,此时从起点到终点的所有状态都学习完毕,Q矩阵收敛,如果再进行更多次实验,平均路径长度不再变化。 图7中,算法收敛速度(cm/s)=迭代路径长度(cm)/间隔时间(s),其中迭代路径长度为迭代过程中每次找到的一条从起点到终点的可行路径长度,间隔时间为后一次找到可行路径用时与前一次找到可行路径用时之差。由图7可知,CM-Q算法收敛速度随着迭代次数增加而增大,开始时由于移动机器人需要大量探索环境,所以230次前Q矩阵变化不大,算法基本不收敛,后期算法收敛速度逐渐加快。 由图8可知,由于前期算法收敛较慢,所以移动机器人到达终点所走路径较长;后期算法收敛后,Q矩阵中各Q值基本稳定,移动机器人通过查找Q值表,选择最佳动作执行,很快到达了终点。 在未知连续障碍物环境下利用CM-Q算法进行了多次路径规划冗余度测试,并与文献中的算法进行冗余度对比。实验中起点和终点分别为(12,1)和(22,23),所规划路径如图9所示。 图9(a)展示了移动机器人利用CM-Q算法进行路径规划仿真实验的结果。图9(b)显示了移动机器人在相同的环境下利用文献[3]中的算法进行路径规划的仿真实验结果。图9(c)显示的是文献[17]中利用模糊控制策略和状态记忆规则进行路径规划的仿真实验结果。 (a)CM-Q算法路径规划 (b)文献[3]路径规划 (c)文献[17]路径规划图9 未知连续障碍物环境下的路径规划Fig.9 Path planning under unknown continuous obstacles environment 本文以路径长度和移动机器人转弯次数作为评判所规划路径冗余程度的标准,结果见表4。 表4 路径长度和转弯次数 算法平均路径长度/cm转弯次数/次CM-Q7211文献[3]7413 由表4可知,利用CM-Q算法规划路径的长度和移动机器人的转弯次数均比文献[3]中的小。由图9(c)可知,文献[17]路径较平滑,但是路径冗余度明显比CM-Q算法和文献[3]算法的路径长。基于以上实验结果可知,利用CM-Q算法进行移动机器人路径规划的效果较好,规划出的无碰路径冗余度较低。 针对移动机器人在未知、复杂环境下避障问题和路径规划过程中出现的路径冗余问题,本文提出了CM-Q学习算法。该算法基于移动机器人行走过程中当前位置的坐标与最邻近障碍物的坐标是否相等的判断,对移动机器人当前状态进行评价和奖惩,并在多障碍物的未知环境下进行最短路径学习。通过避障学习和奖惩措施,提高了最佳状态-动作对的搜索速度和环境适应能力,同时在基于栅格地图的复杂障碍物环境中成功地规划出一条最优或次优路径。仿真实验结果表明,该算法简单、有效可行,不受U型障碍物的死锁和震荡干扰。此算法有待于从时效性和动态障碍物实时避障方面进行改进。3 仿真实验及结果分析
3.1 CM-Q算法有效性验证
Tab.2 Test result of CM-Q learning algorithm under simple environment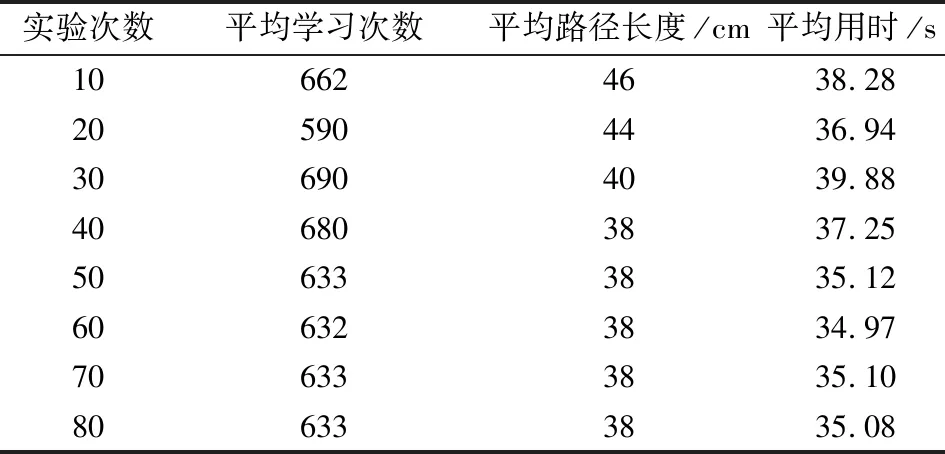
Tab.3 Test result of CM-Q learning algorithm under complex and mixed environments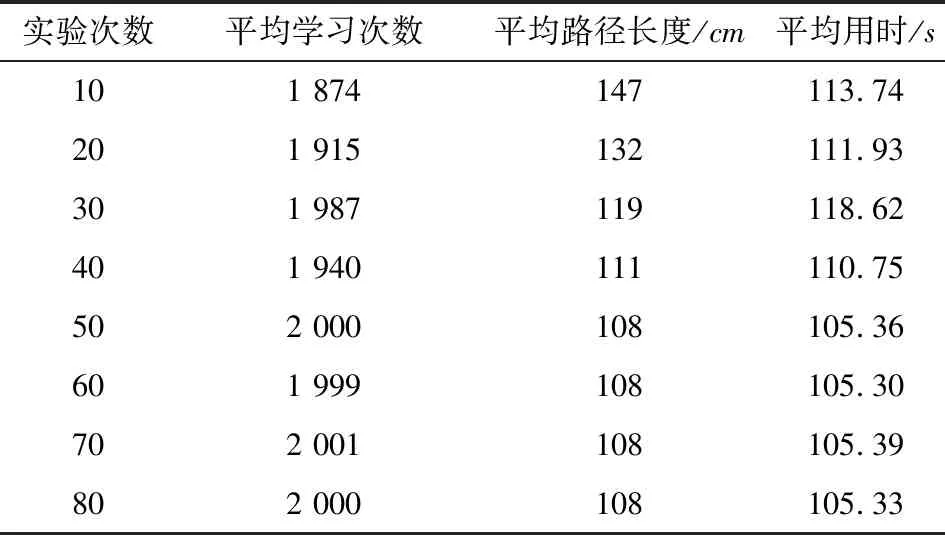
3.2 路径规划冗余度测试
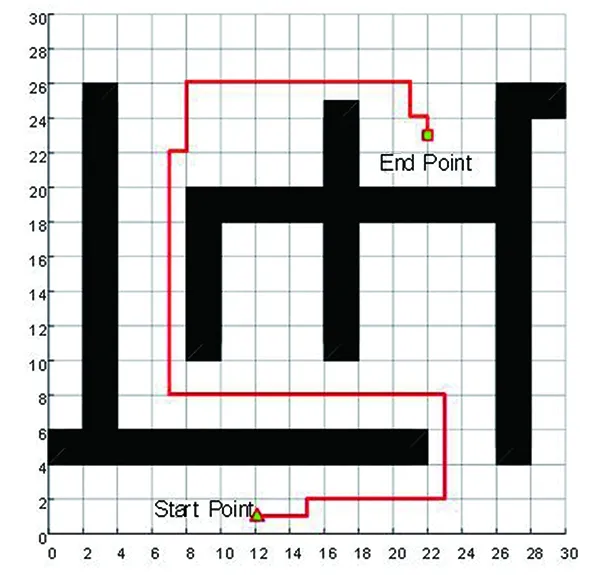
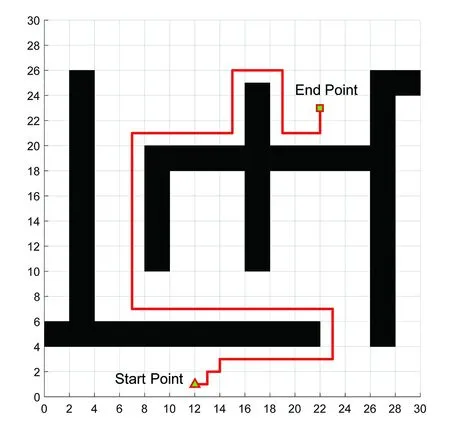
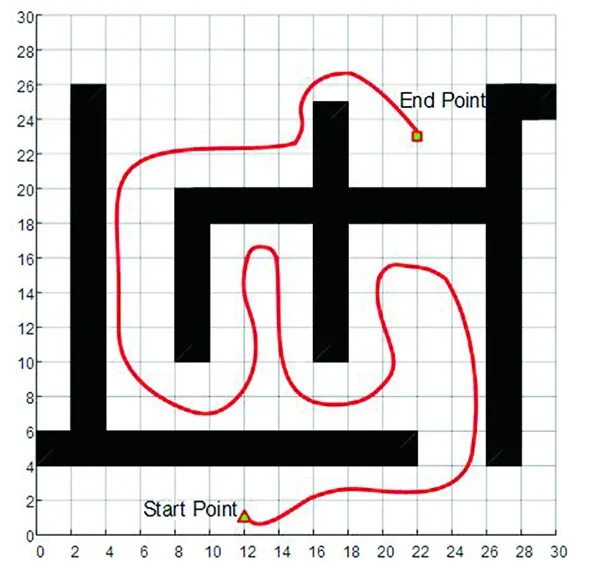
Tab.4 The path length and the turning times
4 结束语
