基于Inception V3的图像状态分类技术
2020-05-11王旖旎
王旖旎
(重庆商务职业学院,重庆 401331)
1 引 言
图像分类是计算机视觉各种应用的基础。从人脸表情识别到人体姿势识别,图像分类随处可见。在过去几年中,随着机器学习和深度学习的进展,图像分类邻域已经发生了深刻变化,陆续涌现了很多有效的算法,例如支持向量机、卷积神经网络等[1-2]。深度学习已被证明是最有效的机器学习技术之一,其核心思路是构建多层神经元来训练网络。所有训练网络都使用数十个层,在网络中构建上千个参数,但是由于层级过深导致了较高的计算复杂度和过度拟合。对象状态分类在机器人、医疗、天文、游戏等领域的各种应用中非常有价值,例如识别物体的状态在人工智能技术中就很重要。在机器人领域,操作处于不同状态的物体需要不同的抓取动作,这需要在机器人的抓取动作中进行不同的行为。
识别物体状态问题的一种典型方法是使用形状匹配算法[3],这类方法是从对象-对象-交互信息的三元组中获取对象状态来实现图像分类。这种方法可以连接和模拟同一帧中物体的运动和特征,训练过程由标记了的视频序列完成。这类算法通常基于贝叶斯网络,主要用对象特征、人类行为和对象反应作为参数[4]。刘成颖等利用PSO优化了LS-SVM模型,实现了道具磨损状态的识别[5]。杨昌其利用BP神经网络建立模型[6],并对空中管制员的疲劳进行分类,用来评估空中交通管制员的疲劳状态。但是上述算法的神经网络深度较浅,优化的目标太过复杂,导致其只适合对状态分类较简单的情况进行识别,识别率不高。
2 基于Inception V3的图像识别算法
2.1 图像预处理
深度学习使用具有数百个隐藏层的神经网络,并且需要大量的训练数据。构建良好的神经网络模型需要仔细考虑网络的体系结构以及输入数据格式。数据收集和预处理是深度学习[7]的重要组成部分。预处理的第一步是将数据分区为训练和测试数据集。本文对数据集中的图像执行多种预处理技术,分别是图像恢复、图像插值放大、图像增强和归一化。
数据划分:将数据划分为训练和测试数据集,在分类之前先用随机算法将数据进行随机混合,以便每个训练和验证集都没有任何特殊性。对于此项目,数据分类以9∶1的比例完成。 90%的数据用于训练,剩余的10%用于测试训练结果。在划分完成之后,输入数据到图像预处理器中,对图像进行恢复和扩充等预处理,生成批量的规范化和增强数据。
图像缩放:本文在不同的图像大小和不同的epoch数量上训练模型。如果图像尺寸较大,则模型需要更多的epoch才能达到良好的准确度。为了让训练的时间复杂度更加稳定,本文对输入图像最终确定了图像尺寸256× 256。重新缩放图像会按给定的缩放系数调整大小,由于重新缩放可能会严重影响精度,为了尽量不丢失图像的信息,本文利用Cubic-convolution插值算法对图像进行有理插值[8]。
规范化图像输入:规范化可确保每个输入参数具有相似的数据分布,利用这一特性,规范化操作可以让训练时网络的收敛更快。本文通过从每个像素中减去平均值并将该结果除以标准偏差来完成数据的标准化。在本文的实验中,图像像素值在[0,255]范围内归一化。
数据扩充:如果在小型数据集上训练深度神经网络,可能导致过度拟合或者可能在测试数据上表现不佳,数据扩充通过增加数据集的大小防止过度拟合[9]。由于本文主要针对食物的数据进行处理,而这类数据集本身比较小,因此利用数据扩充作为预处理技术的最后一步。本文的数据扩充主要利用生成对抗网络 (Generative Adversarial Networks, GAN)来实现[10],该网络可以不断学习图像特征,利用生成器不断生成伪造图片,利用判别器不断判断生成图片的真伪,最终达到纳什均衡,从而生成出逼真的图片。扩充后数据集的总大小约为30 000个图像。
2.2 优化的Inception V3
本文利用Inception V3进行转移学习。在实际应用中,有时可能存在没有足够数据来训练网络以获得有效结果的情况。在这种情况下,可以使用转移学习。用于预训练网络的训练可能仅对一个域是足够的,并且我们拥有的数据可能在不同的特征空间中。在这些情况下,应用学习转移方式赋予网络已训练好的参数信息,将大幅提高神经网络的学习性能。
创建的模型将在对数据集进行训练时在预训练模型上添加了一些图层。整个模型如图1所示。
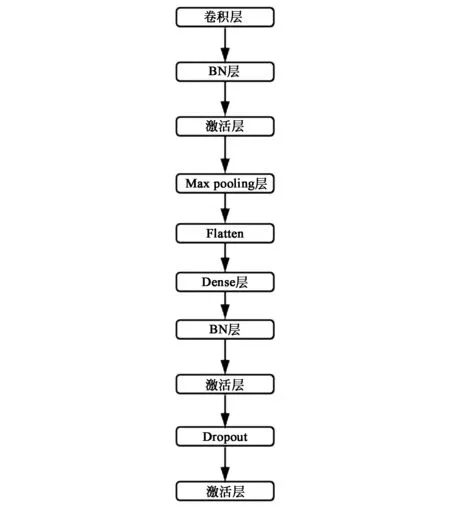
图1 本文提出的模型架构Fig.1 Model architecture presented in this paper
网络的第一层是卷积层。卷积层以张量阵列的形式生成输出[11-12]。
下一层是批量标准化层(BN层)。批量标准化提供了一种将输入逼近0或对输入数组中所有值求平均的方法。这可以在网络层的开始和中间使用,该技术有助于更快地学习并获得更高的准确性。在深度卷积神经网络中,随着数据进一步流动,权重和参数会调整它们的值。模型使用中间数据,会导致计算量太大而增加复杂度,通过规范每个小批量数据可以避免这个问题。
网络中的下一层是一个具有整流线性单元(ReLU)作为激活功能的激活层。 ReLU由于良好的收敛性被广泛应用在深度卷积神经网络,其中Tanh的性能最高,能将收敛性提高6倍[13]。 ReLU的数学公式见式(1)。
y=(ex-e-x)/(ex+e-x).
(1)
另一层是最大池化层。进行最大池化的目的是对数据进行下采样,这样可以通过减少数据的维度来避免过度拟合。最大池化的另一个好处是它通过减少参数数量来降低计算成本。在本文的模型中,将数据的维度从8× 8降到2个4×4,然后从4 × 4降低到2个2× 2。总体来说,在网络中使用两组卷积、批量标准化、激活和最大池化层可以获得更高的准确度。
下一层进行Flatten[14-16]操作。Flatten将前一层的二维输出转换为单个长连续线性向量,Flatten是在数据流进入全连接层之前的必要操作,全连接层只是一个人工神经网络(ANN)分类器,需要Flatten将输入数组转换为特征向量[17]。
再下一层是全连接层或稠密层。全连接层是完全连接的神经网络层,其中每个输入节点连接到每个输出节点。它将Flatten的向量作为输入,并将n维度张量作为输出。使用稠密层可以解决消失梯度问题,同时加强了特征传播,促进了特征重用,并大幅减少了参数的数量。
接来下是激活层,然后是Dropout层用于正则化。正则化有助于通过降低过度拟合的风险,从而更好地推广模型。如果数据集的大小与需要学习的参数数量相比太小,则存在过度拟合的风险。Dropout层随机删除网络中的某些节点及其连接。我们可以使用带有隐藏或输入图层的Dropout。通过使用Dropout,网络中的节点对其他节点的耦合性变得更加不敏感,这使得模型更加稳定。
网络中的最后一层是具有Softplus激活功能的激活层。 Softplus函数将输出收敛于0~1之间。通常最好在最后一层网络中使用Softplus来解决分类问题。它用于分类概率分布。 Softplus函数的数学公式见式(2)。
∂(x)=lg(1+ex).
(2)
2.3 训练过程
模型的训练分两步完成。首先,仅在给定数据集上利用本文的模型进行训练。训练完成之后,通过训练顶部4层基础模型并保持底层的其余部分不参与训练来完成微调。实验在2个优化器上完成:RMSprop和随机梯度下降(Stochastic Gradient Descent, SGD)。首先,使用优化器RMSprop编译模型,仅训练新层并保持基层不可训练。 RMSprop通过将学习率除以指数衰减的平方梯度平均值来完成优化[18],本文中 RMSprop的学习率设置为0.002。模型的目标函数是交叉熵损失函数(Categorical crossentropy loss),该目标函数通常用在数据集中存在。通过将epoch保持为20,50,100,同时保持batch大小为32来进行实验。为了避免过度拟合,第一轮训练的batch大小(32)选得相对较小。在训练期间保存了最佳模型参数(在验证损失和准确性方面),以便可以在第二步中继续优化。在训练的第二步,通过使用给定数据集训练前4层基础模型来完成微调,同时冻结剩余的下面几层。在该过程中使用在训练第一步中获得的最佳模型,通过训练前2层和前4层基础模型进行实验,并且训练前4层给出最佳结果。此步骤中使用的优化器是SGD。添加前4层的Inception会导致学习参数数量增加,从而增加过度拟合的可能性。因此采用SGD优化器,其收敛速度较慢,可以降低过度拟合的情况。学习率0.000 2,衰减=e-6和momentum= 0.5。第一阶段的训练消耗了150个epoch,同时保存了每个epoch产生的所有模型。因为模型有可能随着时间的推移而停止前进,从而产生过度拟合的模型,因此选择最佳模型时本文综合考虑了损失函数和最短运行时间。
3 实验和结果分析
本文算法在Tensorflow平台完成编程,并在GTX1080Ti的GPU、32 G内存、Xeon-E3 CPU、windows平台下进行实验。
本文使用的数据是20种肉类和植物食物(苹果、西瓜、奶酪、牛肉、三文鱼等)的图像,具有6种不同的物理状态(完整、切块、切片、磨碎、糊状、榨汁)。原始训练数据集提供了大约6 231个图像,扩充后达到30 000个图像。图片实例如图2所示。

图2 测试数据集样例Fig.2 Data set of sample test
在训练期间进行了各种实验以产生最佳模型,同时利用GAN对图片进行扩张。在对比实验中,本文采用了基于SVM的图像分类器、BP神经网络、ResNet与本文算法进行对比。
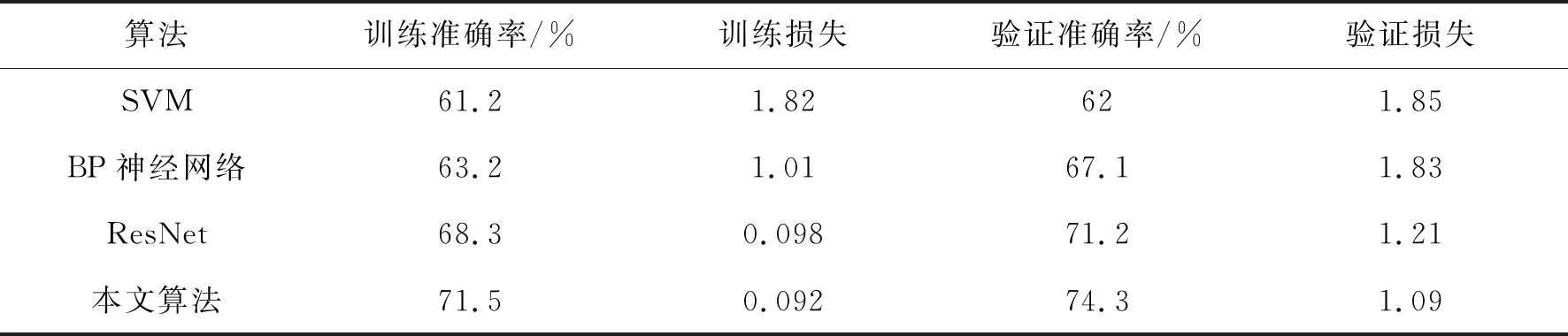
表1 算法结果对比Tab.1 Comparison of algorithm results
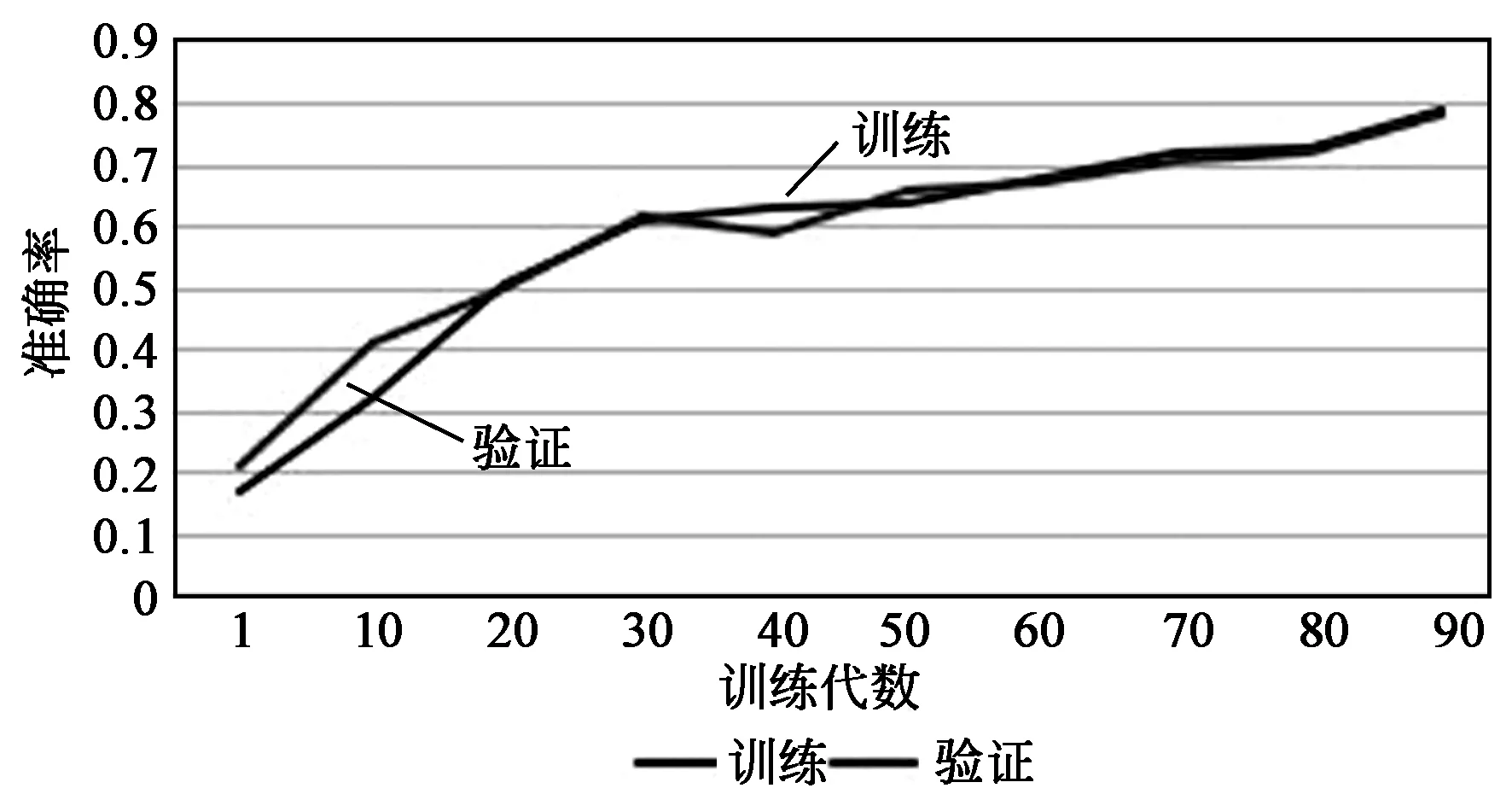
图3 训练和验证的准确率对比Fig.3 Comparison of accuracy of training and verification
这些实验可以添加更多层以改善分类结果。 在这种情况下,使用预训练网络(GoogLeNet)对这组图层进行微调可以获得最佳效果。使用之前的训练中选择的最佳模型进行微调,进一步改善了结果。图3显示了显示训练和验证准确率对比。
4 结 论
提出了一个基于Inception V3结构的神经网络食物状态识别算法,在识别前先对食物图像进行数据划分、图像缩放等预处理,再在原有Inception V3的基础上采用两阶段训练的方式提高了模型的准确度。在20个烹饪对象的对比实验中,选择了SVM、BP神经网络、ResNet进行参照。实验结果表明,本文算法能有效提高识别准确率,与对比实验中的次优算法相比,本文算法训练准确率提高了3.2%。通过不同epoch的训练结果和测试数据可以看出,本文算法在识别过程中具有较好的性能,可以满足图像分类的可靠性、稳定性等要求,为物体状态识别领域提供有益参考。
