基于机器学习的个贷客户精准营销设计
2020-05-06李召蝶董如哲
李召蝶 董如哲


摘 要:随着国民经济的快速增加以及人们金融观念的转变,我国个人贷款需求呈现稳健上升的态势。如何从海量客户中精准识别目标客户,如何通过合适的途径将营销信息推送至客户,已经日益成为商业银行面临的重要问题之一。本文通过对某银行某次12万客户的营销活动数据分析,利用GBDT(梯度下降)+LR(逻辑回归)方法,根据营销渠道将数据分层训练,进行客户精准营销响应预测,大幅提高了营销效率。同时在固定成本约束下,实现营销效果最佳的资源配置最优解。
关键词:精准营销;GBDT+LR;最优化;营销策略
1.背景及意义
传统商业银行如何在信息时代通过精准营销,准确定位客户,提高产品覆盖度?依托大数据分析,可推动商业银行精准营销基础上的“客群化”经营,匹配客户特征直达C端,实现存量客户挖掘、睡眠客户唤醒、潜力客户提升转化,构建获客活客轻入口,提高营销效率,助力全量客户维护与拓展,增强个人业务可持续发展能力和市场竞争力。
本文依托某银行在2018年某月开展的个人贷款营销活动数据进行分析构建。通过机器学习建模过程,大幅提高了传统营销的效率,具有一定的现实意义。
营销活动数据基于电话、短信和邮件三种渠道(成本不同),对客户推送营销信息。
不同渠道营销效果,在response进行贷款的响应客户中,Phone Call(电话)渠道相比SMS(短信)和Email(邮件)效果最为明显,此渠道成功客户数占全部成功客户数的59%,其次为SMS和Email。
未接触客户 接触客户
2.分析流程图
Setp1:将数据集规约形成两个样本,训练数据集样本和测试数据集样本。
Setp2:对Step1形成的训练数据集预处理和特征工程、特征选择过程。具体包括缺失值处理、重复值处理、生成衍生特征、独热编码等。
Step3:利用Step2形成的已完成数据预处理的训练样本,使用GBDT+LR方法根据不同渠道分别建立客户响应模型,对建立好的模型进行解释与评价,利用测试训练集对模型进行诊断。
Step4:利用另一个目标变量是否触达客户建立GBDT预测模型,作为全量客户全渠道预测的数据基础。
Step5:根据Step4所形成的数据进行分析,依据不同标准对建立营销方案,并针对反馈效果监测、调整模型。
3.数据准备与预处理
3.1.数据清理
在数据建模过程中,数据的准备和预处理往往占据着最为重要的地位,同时也会消耗最大量的时间。在此,我们主要通过将少值域数据有序离散化、利用决策树算法进行数据分箱、利用业务知识将变量分组,结合分组情况对数据进行相关性检验与过抽样等创新性方法对数据进行了前期处理工作。
3.1.1.数据变换
首先将数据按照4:1的比例分成训练集与测试集,以下数据变换完全是基于训练集的。
(1)确定是否存在重复值
数据清理包括重复值的删除与缺失值的处理等工作。首先,观察数据中是否存在重复值,经过分析,数据中不存在完全重复的观测。
(2)数据重编码
对于数据中的字符型变量重编码,将所有的Y值替换为1,N值替换为0。此外对于营销渠道、性别、教育水平、工作类型,依次编码为1、2、3、4等。
(3)缺失值处理
随后,查看变量中的缺失值个数,决定如何对待缺失数据。统计发现,大部分变量缺失值在10%以下,但也有几个变量缺失值超过了70%。
首先,根据业务特征推测数据缺失原因,进而确定处理规则。经过筛选,大部分存在缺失值的变量不包含0值,如total_investment_bal (当前持有理财产品数额)等,可以推断这部分缺失值是由于客户无相关交易内容所致,故此部分缺失值可用0值填充。
此外,仅变量 “信用卡当前还款期内账单额”同时存在空值与0值。经观察发现,此变量取空值时,对应变量“当前信用卡额度”也为空值,故这部分空值是为无信用卡导致的无交易额。因此,可创造一个衍生变量“是否持有信用卡”来标识这部分空值。自此,缺失值处理完成。
3.2.变量筛选与属性构造
通过对客户前六个月历史数据进行分析,发现很多数据具有较强相关性(相关系数超过了0.8),不能够直接进入模型,需要對数据进行变量筛选。基本原则为:6月份的数据全部进入模型,同时基于1-6月的数据,构造近三个月/六个月数据指标,代替1-5月的数据进入模型,以降低变量中的自相关性。具体方法如下:
(1)开户时间、受教育水平、性别、工作类别等四项变量
选择6月的数据进入模型,其他月份的数据删除。
(2)当前是否持有房贷,是否持有保险产品等两项变量
选择6月数据,此外构造新变量:房贷(保险)持有类型,分为:
(3)9个数值型流量数据变量
当前存款数量、持有理财产品数额、信用卡当前还款期内账单额、当前信用卡额度、信用卡上一个还款期账单额、账户本月取款或者转出数值、通过ATM取款或者转出数额、本月取款或者转出次数、本月账户存款或者转入次数等9个数值型流量数据,构造近三个月、六个月均值指标和偏离度指标。其中,三个月存款余额偏离度=6月存款/(4、5、6三个月存款均值)。偏离度指标用来衡量该变量的变化趋势。公式如下:
(4)信用卡额度使用率和ATM渠道偏好等两个经验指标
根据业务经验,信用卡额度使用率是一个衡量贷款意愿和提款金额的重要指标,定义为:额度使用率= 信用卡当前还款期内账单额/当前信用卡额度,并构造三个月、六个月额度使用偏离度指标。同时,设置ATM渠道偏好指标,定义为:六个月通过ATM取款或者转出数额总数/六个月账户取款或者转出数值总数。
3.3.数据变换
3.3.1.CART决策树分箱
在对变量进行了筛选和重新构造后,我们对连续变量进行了基于决策树的变量分箱处理。CART是二叉树分类算法,每次仅进行二元分类。对于连续性变量,方法是:依次计算相邻两元素值的中位数,将数据集一分为二,计算该点作为切割点时,分割前后,基尼值的下降程度。每次切分时,选择基尼值下降程度最大的点为最优切分点,再将切分后的数据集按同样原则切分,直至终止条件。
其中,我们将最大分级限定为12级,同时,一个叶节点所需的最小样本数定为5%,防止在分箱阶段出现过拟合。
3.4.变量选择
3.4.1.依据相关系数粗筛变量
我们依据变量与分析目标的相关性,对变量进行进一步的筛选。其中,除了本身包含字符型数据的分类变量外,我们将值域小于等于20的变量全部视为离散型变量,其他则视为连续变量。对于连续变量,使用方差分析(ANOVA)筛选出显著变量,其中显著性水平设为5%。对于离散变量,使用列联分析方法,同样以显著性水平5%为标准。最终,共筛选出50条连续变量与 13条离散变量。
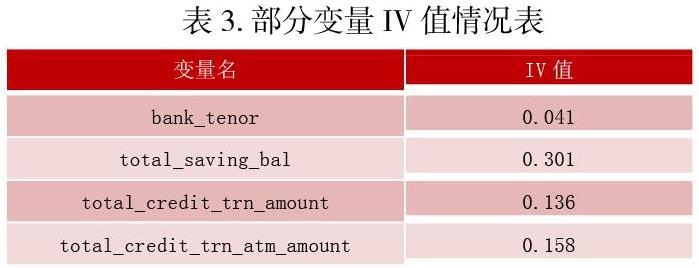
3.4.2.IV值筛选
IV定义:IV值(Information Value),即信息价值指标,衡量了某个特征对目标的影响程度,其基本思想是根据该特征所命中黑白样本的比率与总黑白样本的比率,来对比和计算其关联程度,计算公式如下:
通过计算我们筛选出IV值大于0.02的变量进入模型,生成的部分IV值如下表所示。
3.4.3.变量聚类
从全部的相关系数矩阵中可以看出,目前变量之间依然存在较强相关性,可能导致模型出现多重共线性问题。因此,通过变量聚类算法,筛选最终进入模型的变量特征,筛选原则为:
4.个人贷款营销响应预测模型
4.1.GBDT+LR模型的设计与训练
4.1.1.模型设计思路
根据业务经验分析:
首先,客户是否贷款与客户是否具有资金需求有着直接的关系,所以针对响应客户(response = 1),对其相关信息建模可以得到客户的贷款倾向概率;
其次,建模的目的是为了最大化响应客户人数或者金额。对样本数据的响应客户进行分析,我们发现,采取不同的营销渠道,客户的贷款金额没有显著差别。业务上来讲,客户的贷款金额应该与客户本身的资金需求量有关,而与客户获取贷款信息的渠道无显著相关性。因此贷款金额最大化问题的求解可等效转化为贷款人数最大化问题的求解,即响应客户数量的最大化。
营销渠道的选择决定了贷款信息能否发送至客户,而营销数据能否触达客户对于营销成功率有着显著影响。但是,之前的营销活动是随机选择营销渠道,没有考虑到不同客户的渠道偏好。例如,对于一些客户,电话营销往往会被当作电信诈骗直接挂掉,于是耗费了大量成本但是没有产生收益;而对于一些老年客户,邮件发送往往根本无法触及,诸如此类。通过不同营销渠道向客户传递贷款信息,客户的选择可能截然不同,因此确定合适的营销渠道也是至关重要的。但是,目前的数据中,单个客户仅有一种营销渠道,若该渠道无法触及客户,我们无从确定更换另两种营销渠道,客户的响应情况是否有所变化。
于是,我们的模型将分为两大部分来进行:首先根据原始数据的营销渠道(电话、短信、email)将数据分成三个部分,在第一层模型,根据是否触达(contact_ind)变量对三组数据分别训练,形成三个不同渠道下的客户触达模型;随后,在第二层模型通過对客户响应情况(response)与相关信息建模分析,得到三组客户相应模型;最后,对全量客户数据分别使用这三个模型,以确定客户的最大响应概率。
于是,我们得到了三组模型,每一组模型即为客户在该营销渠道的响应概率。随后,我们将全部数据分别带入这三组模型,最终可以得到全部客户在所有渠道的响应概率。客户的最高响应概率所对应的模型即为应采用的营销渠道,最终达到全局最优解。
因此,此模型结构的实质其实是三个以一个GBDT模型作为某重要变量数据生成器的GBDT+LR双层结构模型。同时,该模型会根据营销渠道的不同进行三类并行计算,以输出概率最大的模型作为渠道选择的依据。具体模型结构如下图所示:
4.1.2.关于GBDT+LR
本质上GBDT+LR是一种具有stacking思想的二分类器模型,因此可以用来解决二分类问题。这个方法出自于Facebook 2014年的论文 Practical Lessons from Predicting Clicks on Ads at Facebook。综合使用GBDT与Logist模型,既提高了模型的精准度,又兼顾了模型的解释性,Logist模型也可以控制GBDT的过拟合倾向。具体结构见图:
在本文的模型设计中,一共三组33个变量作为第一层模型的输入,通过sklearn.preprocessing模块的OneHotEncoder进行定性特征值数量为50的转化后,可将特征进一步提升到1600维用于分类。
4.1.3.模型效果
模型训练结果的验证是基于占全部数据20%的测试数据集进行的。效果评判标准包括ROC曲线、AUC(ROC曲线下方面积)以及正类F1得分。
(1)模型参数调优
为进一步挖掘模型的潜力,本文使用GridSearchCV,根据贪婪算法,进行具备最优化调优。通过参数配置分别对GBDT模型、LR模型、双层混合模型进行了性能调优,。
在GBDT树模型算法中,影响模型性能较大的参数主要有MAX_DEPTH、N_ESTIMATORS、max_features等。其中max_depth是指每棵的最大深度,n_estimators是指在GBDT中创建决策树的个数,learn_rate指每次学习的步长,通常与n_estimators共同调整,max_features是指每棵树所能使用特征的最大个数。因此,模型在以下参数范围内进行参数搜索,以找到使模型在训练集上表现最优的参数组合。
在逻辑回归模型的调优过程中,我们允许模型的class_weight参数在None默认值与balanced之间进行调整,允许模型在是否调整分类权重间进行选择,用以降低样本失衡的影响;允许模型通过solver参数选择包括'newton-cg','lbfgs','sag','liblinear'在内的更多优化算法进行拟合。
4.1.4.模型稳定性和模型选择
经过参数调优之后,我们将模型分别应用到验证数据集上用以最终确定流失预警模型的选择。在验证集中,AUC与训练集相差不到0.01,模型表现出了极大的稳定性。
通过比较各模型在ROC曲线,AUC指标和正类F1分值的表现,我们发现双层混合模型在各项指标中都居于首位。不仅如此,通过分析正类识别精准度和召回率,我们不难发现GBDT模型在历次测试中表现出较好的正类识别精准度,但是在正类召回率上表现上相对保守。与GBDT相比,LR模型在正类召回率方面的表现更好。经验证,双层混合模型较好地结合了逻辑回归与决策树模型的优点,表现出较好的识别效果和稳定的性能,因此最终被确定为客户响应预测模型。
4.2.新营销活动设计与评估
通过模型输出的输出结果:客户编号,三个渠道的响应概率P1P2P3,可以确定多个不同的最优化目标:第一种,最大化客户响应概率,使得响应客户的期望最大;第二种,在每个客户只能选择一种营销渠道的情况下,选择每个客户的最大概率,覆盖最多的客户。以下分别讨论这两种营销策略:
4.2.1.客户响应期望最大化
在这种情况下,允许使用多种渠道覆盖同一个用户,力求达到客户的响应概率的最大化。约束条件如下图所示:
在具体的营销执行的步骤中,可以对三种渠道按照E-MAIL、短信、电话的顺序分别部署,即先部署EMAIL渠道,若客户响应,且客户同时存在于后续的营销渠道名单中,则将客户剔除。一方面可以节约营销成本,同时避免对客户的过度打扰。
4.2.2.客户最大概率渠道选择
在这种情况下,同一个用户只使用一种营销渠道,因此,对客户在全部三种营销渠道的响应概率排序,选择其中最大的作为此客户的营销渠道。同时,约束条件如下图所示:
5.结束语
与原始营销活动相比,原始活动共消耗营销费用3.39万元,成功营销客户4306人,成功客户单客成本7.9元。根据模型预测,使用新的营销策略,第一方案客户响应期望6071人,覆盖客户20870人,派发信息37872人次,单客获客成本1.6元。与原始方案相比,新的营销活动的获客成本预计将降至原来的1/5左右,活动效率大大提升。
参考文献:
[1]李墦.银行数据挖掘的运用及效用研究[D]武汉大学,2012
[2]柳杨亮.基于客户交易行为的事件式精准营销在交通银行零售板块中的应用研究[D]华东理工大学,2013
[3]王文贤,金阳,陈道斌.基于RFM模型的个人客户忠诚度研究[J]金融论坛,2012
[4]蔚赵春,凌鸿.商业银行大数据应用的理论、实践与影响[J]上海金融,2013
[5]刘濤.建设银行枣庄分行精准营销系统设计与优化[D]天津大学,2012
[6]陈春安.零售大数据在商业银行的应用分析[D].西南财经大学,2016
