修正KMV模型对上市企业财务信用风险度量的适用性
2020-04-16彭美红
彭美红
(福州外语外贸学院,福建 福州 350202)
KMV模型主要适用于上市公司,其主要思想是把企业与银行的借贷关系看成是一种期权关系。1997年,KMV公司创建一种对企业借款估计违约概率方法,即KMV模型。认为产生信用风险的因素,是在贷款中负债给定前提下,由债务人的资产市场价值因素决定。该资产在市场交易是虚拟的,并不是客观存在的,资产的市场价值很难检测,因此,该模型将银行贷款从所有者的借款企业角度考虑这一问题,(如还款问题),以及造成的后果。
一、KMV模型对上市企业信用风险的影响
信用风险是投资债劵中发生的一种风险,是借款人因一些原因,有不能及时归还的可能性。当发生违约时,债权人未能得到预期收益而承担的损失。
上市企业财务信用风险,即履约风险,指企业以信用为纽带的交易中,因流动性、权益、资金不够或债务拖欠等财务状况恶化,导致客户延期或拒绝支付的可能性,一方约定没法履行而可能给对方造成损失。作为交易方、借款人或债券发行人的上市企业,因违约,致交易对手、投资者或银行受损失。
上市企业的信用风险度量,即尽可能构造模型或制定统一标准量化风险,得到因风险因素存在所致的损失确定时的收益数额或在收益确定时损失数额。在对风险基础上,信用风险度量对风险识别分析、描述深化,把结果作为制定风险决策和管理的依据。
(一)KMV信用风险度量模型
KMV 模型以Merton(1974)的期权定价理论为基础,其创新之处在于,是以企业资本结构、资产收益率的市场价值和波动性为因素,采用经验的违约率,即预期违约率,对信用风险进行度量。
(二)KMV 模型的基本框架
作为于债券等级序数度量指标相似的违约距离,还不能从该指标得出企业违约的概率值,要把此指标延伸为基数或概率度量指标,违约距离与违约率间的关系映射应建立起来。
KMV 公司对违约公司的实证研究中得出,公司的资产价值=(流动负债加长期负债50%的和),违约概率发生最大,因此,则此临界点被定为违约点[1]。KMV公司认为,从资产价值的概率分布得出,违约概率值可用违约距离直接计算。违约概率此时在T期,图1为资产价值由VA降至违约点(DPT), DPT下面的阴影处即为违约概率。
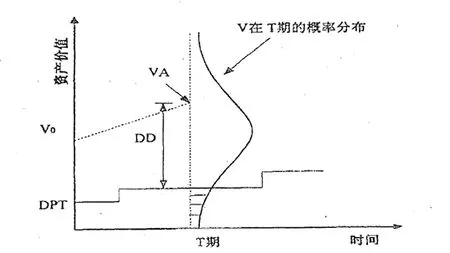
图1 违约点与至违约点的距离
(三)模型的假设
一是满足基本的Merton模型假设条件,即企业股票交易价格随机生成,并服从Ito Process的企业价值变化过程;二是借款人资本结构仅为长期和短期负债及所有者权益; 三是若借款人资产价值比债务价值大,借款人不违约,反之,则违约。
二、对KMV模型的修正
修正KMV 模型的三个参数:股权价值E为第一个参数。我国A 股分为两类:流通股和非流通股。流通股价值比非流通股价值高,且容易估算。若将流通股价格简单替代非流通股价格,会高估企业股权价值,因此,将非流通股价格以每股净资产替代,由此可得:股权价值=非流通股股数×每股净资产+流通股股数×流通股收盘价,其中,改革股权分置中限售的股份包含在非流通股股数中。股权价值波动率为第二个参数,设计了新的方法计算此参数。股票价格波动率计量,可分为静态和动态两类模型:静态模型一般收益率假定价格固定、稳定方差。但事实证明:股票价格、通货膨胀率、汇率等金融时序有不稳定群集波动特征,以及其价格于相当长的一段时间内,出现大幅度波动,又在一定的期间内保持稳定。这说明该金融时序常存有异方差现象,不符合关于静态模型假设。因此,实际研究金融变量波动率应该采用动态模型。
下面以中冠A来举例,说明收益率这种现象。此股票2007—2018年间价格走势如2图所示,在一定时期内股票价格有很大的起伏,因此,股票的收益率出现变化幅度大,而在其他期间内适度发生摆动,群集波动现象由此证明。金融时序中的此种波动性正是用 GARCH 模型来度量的。表1为选序列时间检验收益率平稳性,由表1可知,置信水平下的三个临界值平均大于统计量t,则原假设被推翻,平稳序列即为该时间序列。

图2 000018 *st中冠A
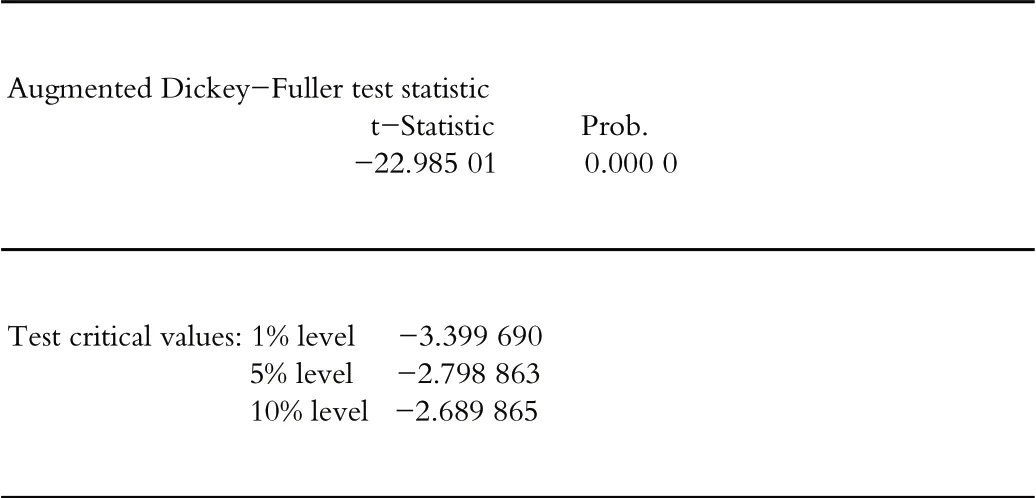
表1 中冠A(000018)对数收益率检验
波勒斯列夫(Bollerslev)最早提出了广义自回归条件异方差模型(GARCH)。GARCH(1,1)模型为最简单的 GARCH 模型:
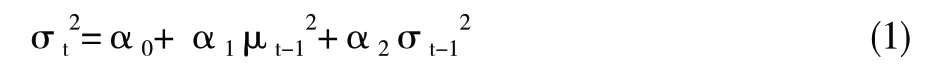
t在u时间的条件方差取决于上一时期的条件方差和误差项平方。推广该模型为GARCH(q,p),q为条件方差的阶滞后,p为误差项平方的阶滞后。股价的群集波动的描述GARCH(1,1)模型较适用。计算出交易日的股票收益率后,用 Eviews5 软件和GARCH(1,1)对股权价值的波动率计算。违约点(DPT)为第三个参数。KMV 公司认为,一般是企业违约,通常是债务账面价值小于资产价值的企业。违约时,企业资产价值位于总债务与短期债务间的某个值,用以下公式表达:

其中短期债务用CLD表示,违约点用D表示,长期债务用LL表示。
KMV 公司观察大量违约企业发现,k= 0.5时得到最常见的违约点,违约点变化时模型精确性可敏感预测出。此违约点经验值是基于美国企业的,未必适用于我国上市企业。设置违约点要考虑而本国信用及企业债务状况,违约点的设置是难点,先前违约点设置的研究,都基本于 KMV 公司类似。现有资料很少有对信用风险及违约点的研究。先提出了三个选择:k=0. 57、0.518、0.275,接下来在这三个数中选取,来进行比较该信用风险模型时的有效性,在我国上市企业运用是否恰当。
三、 KMV 模型的修正在中小板信用风险中的应用
除以上三个参数,再设两参数。第四个参数为债务期限T、第五个参数为无风险利率r。受限于数据信息的有效性,将期限1 年设置为计算时间,对下一年的信用风险进行预测、估量。将无风险利率设置为一年期定期存款利率。运用实证方法,综合分析KMV 模型预测效果和识别信用风险能力。
(一)样本的选取和数据处理
对企业选取样本,企业只在 A 股上市后,确保该样本分析时期是完整的、连续的。截至2014 年,符合中国现行的中小企业划分标准,选择企业的营业收入及企业总资产少于5 亿元人民币的中小企业。这段时期数据内完好无缺失,筛选之后符合本文要求的仅有 38 个样本。这些样本数据都发生于2010—2014 年,包含每日收盘价、股短期债务、净资产、长期债、流通股股份和非流通股股份等,且这些数据没有处理过。
Matlab 软件中用牛顿迭代法,求解KMV 模型参数 V,得出DD。设置违约点为D2、D1及D0。对KMV 模型用 Matlab迭代计算时, 用试错法查找合适的初始值。试错法计算显示,初值(1.0E+08,0.5)可迭代收敛且收敛较快,资产价值V就可得出,随即得出2010—2014年38 家企业的非 ST 公司及其余5 家 ST与*ST企业的DD。ST 公司通常是由于最近的一个会计年度的股东权益为负、或连续几年股东权益负,经过特别处理的公司。*ST公司是由公司连续两年亏损,或公司财务会计报告虚假,有重大差错。
(二)实证结果及分析
1.验证模型有效性及分析不同违约点
一般认为,财务受损较严重的公司是ST与*ST 公司。与普通公司相比可能信用风险更高。可对这些数据分成两类:5 家ST和*ST公司为一类,38家非 ST 公司为第二类。从 2011— 2014 年比较两类样本违约距离的平均值。
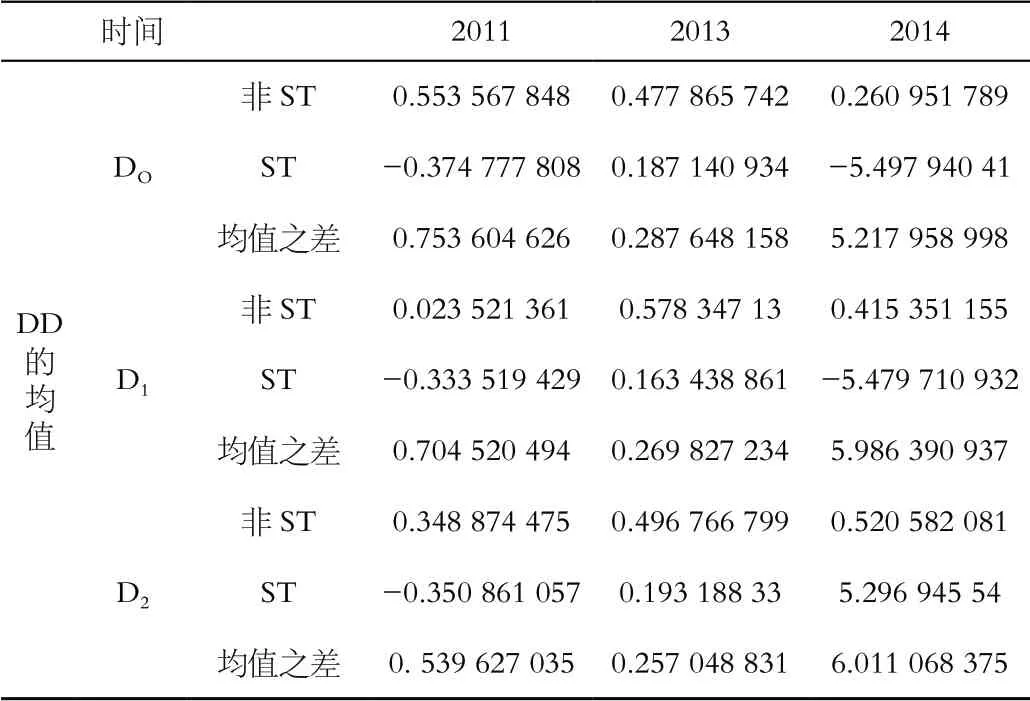
表2 三组违约点下DD的统计值
由表2可以看出,随违约点变化,KMV 模型有敏感的预测精确性。现以上年末的数据为例,选择违约点 DD来进行以下的分析。.发现非 ST比ST 公司的违约距离要大些,表明上市中小企业更容易违约。且能得出 ST与非ST公司间违约距离有较明显差异,即 KMV 模型对信用风险区分能力较好。与其他两组样本相比,说明中小板中非 ST 公司违约距离波动较小。可见ST 公司多年信用风险一直较高[2],特别是前后1—2年被划分为ST的期间。
通过ST 与非 ST 公司违约距离的分析,显示上市中小企业违约距离的统计特征,信用风险指标在样本期限里较集中。总的来说,DD在 0 至 0.75范围间有波动,由此可断定,资产规模与违约距离间并不存在显著的相关关系,例如,如果一大型企业,技术落后,经营不善,可能负债累累,则信用违约风险会很大;反之,资产规模较小的科技型的中小企业,如其有先进技术和创新力,反而信用风险小,并能发展壮大。KMV思想认为,企业违约否,取决于企业中资产价值与债务间相对大小。若企业中债务小于资产价值时,企业违约机率小,若企业债务高于资产价值,违约对企业有利,企业则会违约。这种企业中资产与负债间的相对大小关系,可用资产负债比率来体现。若资产小于负债,负债资产比大于 1,可能企业违约,违约距离相应的就越大,信用风险就较小,否则就有较大的信用风险,违约距离也会越小。可知,资产负债比率与违约距离间的关系是正相关,而此种关系还需大量数据验算其存在性,为此,以 2014 年末为例,在资产负债比与违约距离之间进行回归分析。
如果ST 或*ST公司遭受了财务困境,其信用风险则比普通公司更高。 KMV模型能够识别上市公司整体的信用风险变化趋势,是从2011—2014年ST公司及非ST公司违约距离在样本t结果检验中,发现在三种不同违约点值情况下,比较前1年与前2年,ST、非ST公司的违约距离的偏差=0.05%,在ST前3、4年,违约距离偏差显著呈现下降水平,并且是不显著统计。还发现ST公司的前4年,违约距离差距的均值趋势在增大;尤其是在被化分为ST的前2年,模型得出的违约距离表明ST公司信用状态有变坏的趋势,在ST前1年时,ST、非ST公司违约距离均值的差距最大为-0.764 2,违约距离均值是非ST公司远大于ST公司, ST 公司和非 ST 公司违约距离均值的差,在 2006—2010 年间呈下降趋势,到2010年后又陡然上升,这是因为金融危机后,ST和非 ST两类公司信用状况,也有很大差距。这一结果表明着对ST 公司和非 ST 公司来说,违约距离的差对违约点的变化是稳定的。
同样可以这样描述,从ST公司前4年两类公司就已经拉开了距离,在后期ST公司与非ST公司违约距离中值差异在显著性增大,当时间接近被化分为ST公司时,违约距离中值的差异越明显。ST和非ST公司违约距离均值及中值的差异显著性,表明KMV模型在被化分为ST前4年,就能较强识别公司信用状态变化的能力。ST与非ST公司的违约距离差距逐渐拉开,差异显著, 反映出ST公司信用状态逐年恶化的全过程,即从ST公司与非ST公司来比较,信用风险在逐年增大,因此,在中国股票市场中, ST与非ST两类公司, 信用风险整体上差异显著。KMV模型能够提前4年识别出上市公司整体的信用风险变化趋势。
实证表明KMV模型不仅能在上市公司整体上的信用状况变化趋势上识别,还可识别趋势ST公司的前4年信用状况。较强的信用风险判别能力在上市公司和ST公司的前2年可以明确;并且流动负债等于违约点时,KMV模型对信用风险识别能力最强;模型的识别能力在其他违约点情形下时分接近。根据以上结论,我国证券市场就对KMV模型加以应用,对上市公司的信用风险加以识别,债权人、投资者、监管机构等相关部门和人员要对信用风险及时提供信息评价,提供有益的信用风险参考策略。此外,股票价格信息除能对公司历史状况加以反映,还能决策公司发展。因此,被投资者对低风险高收益的投资组合和参考模型的信用风险评价结果进行选择,最大限度地保障资金安全使信用风险得以化解,使收益实现最大化。
2.上市中小企业信用风险的进一步比较
将中小企业的信用风险与上市企业信用风险来进行比较,将会进一步讨论这一信用风险状况,(如中小企业的信用风险及上市企业的信用风险),为了将这一问题有效地开展,本文以 2014年年末的数据为例,将怎样选择违约点及违约点1D以及如何来开展做出了如下的分析。该分析是在三组样本基础上设置:第一组选取了ST 公司有代表性的5 家,第二组是之前探讨有代表性的38家非 ST 公司。第三组从沪深 A 股非 ST 公司中抽取了5 家恰恰被看好蓝筹股,通常认为蓝筹股能定期分派股息公司的股票,且有优良的业绩。参考样本以第三组设置,比较了三组违约距离得出:蓝筹股公司、非 ST 公司的违约距离要比 ST 公司大许多。可以说明在我国中小企业和上市企业,蓝筹股公司与非 ST 公司相比,非ST公司违约更大些。从蓝筹股公司、非 ST 公司间违约距离表明,差异很明显,由此得出:KMV 模型能较好区分信用风险能力,与另两组相比,中小企业非ST 公司的DD折线图更稳定平滑,说明非 ST 公司的违约距离波动小。推断出,维持较高信用风险的一直是ST 公司,在被划分为 ST 的前后尤其明显;上市中小企业违约距离的统计特征;信用风险指标于样本期限内集中;违约距离范围波动在 0 到 0.59范围内。
四、对KMV模型的评价和意见
优点:能更准切、更及时地反应现代金融企业信用风险。充分利用资本市场,输入的数据为各公司股票交易数据和财务报告数据,并大量依赖财务指标模型。
缺点:我国股票市场从1990年上海证劵交易所到现在上市公司进行股票交易已经有几十年了,有关违约方面的数据,波动大。缺少模型估计所必须的数据库。股票的变动,无论从整体还是从个体上看,不能正常反应风险和收益的对比性,这使 KMV 模型估计的结果带来了误差。
建议:本文所用的KMV 模型,资产负债比率是最主要变量之一,因此,仅考虑资产负债比率对信用风险的影响。为提高上市企业公司信息的质量,确保正确无误通过提高信息质量,确保样品真实,完整。所以,就要求各个上市企业,必须按照规章制度,监管部门要充分发挥作用,确保资本市场不断完善。
