势函数聚类的优化下采样SVM分类方法
2020-02-14贾冬顺陈德礼林元模
闻 辉, 贾冬顺,严 涛,陈德礼,林元模
(1.莆田学院 信息工程学院,福建 莆田 351100; 2.东方地球物理公司 辽河物探处,辽宁 盘锦 124010)
0 引言
支持向量机(Support Vector Machine,SVM)[1-4]是一种核机器学习算法,在工业诊断、图像识别、医疗诊断等领域均有非常广泛的应用。通过使用核技巧和边缘最大化准则, SVM可以建立最优的决策曲面,在解决小样本学习以及高维模式识别等方面表现出了优越的网络泛化性能。然而,由于SVM的训练是一个二次规划(Quadratic Program, QP)问题,其训练计算量与训练样本的个数呈指数关系,这导致其在大样本集下的训练过程非常耗时。
为改善大样本SVM的训练效率问题,Vapnik[5]提出基于分块的SVM优化算法,通过分解大规模的QP问题以逐次排除非支持向量,降低训练过程中的存储要求,然而当支持向量的个数较多时,分块的数据量也会增大,从而影响算法的训练速度。Osuna等[6]在分块SVM算法的基础上提出基于分解的SVM算法,通过迭代选取工作集的方式将QP问题分解成若干较小规模的QP问题,该算法所选取的工作集的优劣直接影响算法的收敛性能。序贯最小优化算法(Sequential Minimum Optimization, SMO)[7]所选取的工作集每次只有2个样本,通过启发式的嵌套循环来寻找待优化样本,但是在最优条件的判别上计算代价过高。刘等[8]提出将原始样本空间划分为不同子集后与并行SVM算法相结合,但不同的子集划分对SVM的泛化能力仍会产生一定影响。与以上方法不同,下采样SVM分类方法直接从训练样本集的角度出发,通过从原始样本集中抽取或聚类选择具有一定代表性的样本来降低训练样本的规模,从而提升SVM的训练效率。随机下采样SVM方法[9]与聚类SVM方法[10-12]是两种典型的下采样SVM方法,随机下采样SVM方法的不足在于当采样个数较少时,采样的随机性导致所获取的样本往往不能反映原始样本集的空间分布特征;聚类SVM方法将训练样本聚类所得的聚类中心作为SVM新的训练集,该方法的聚类个数需要预先确定,尽管可以极大程度降低训练样本集的规模,但是这些聚类中心往往会改变原始训练集合的空间结构分布,学习器的泛化能力也会受到影响。文献[13-15]提出的粒度SVM模型(Granular SVM, GSVM)将粒度计算和SVM相结合,通过粒划分的方式来获取具有代表性的信息粒,再在这些信息粒上进行学习,以获取最终的决策函数。该方法在SVM的训练效率方面有显著改善,但是所划分的数据粒可能导致数据分布的差异,降低了学习器的泛化能力。为改善这一不足,郭虎升等[16]提出基于粒度偏移因子的SVM(GSVM based on Shift parameter, S_GSVM)学习算法,通过在核空间中对映射所得样本进行粒划分,计算出不同的超平面偏移因子,以重新构造SVM的凸二次优化问题;程凤伟等[17]提出基于近邻传输的粒度SVM(GSVM based on Affinity Propagation,APG_SVM)算法,将k近邻算法用于筛选训练样本集,再结合粒样本混合度及粒中心到超平面的距离对训练集进行优化筛选,这些方法在有效改善SVM训练效率的同时,也在不同程度上改善了GSVM的泛化能力。
基于以上研究,本文提出一种势函数聚类的优化下采样SVM分类方法。与已有聚类SVM方法不同,本文所提势函数聚类方式所得的下采样集合直接来源于原始的训练集,并未改变原始样本集合的分布结构。通过对原始样本空间不同区域的样本进行密度度量,有效地将样本空间的全局分布信息利用起来,并建立不同参数的高斯核完成对样本空间不同区域的有效覆盖,每次覆盖增量生成一个采样样本,在样本空间的不同局部区域可以挑选出具有代表性的训练样本集合。相对于原始训练样本集合,所得样本集合规模极大降低。按照这种方式,所筛选出的训练样本集合可以根据样本空间的分布情况自适应确定,克服了随机采样SVM方法中样本采样不足导致的样本空间结构失真问题,可以以相对少量的训练样本来逼近原始样本空间结构分布。而且,该方式可以根据样本空间分布来自动确定聚类个数,克服了聚类SVM方法中的聚类个数需要手动调整和聚类子空间覆盖范围尺度不一致的问题。相对于GSVM,本文所提势函数聚类方式所得的下采样集合来源于原始样本空间的各个局部子区域,在生成下采样集合的过程中,将样本空间的全局分布信息和局部区域信息结合在一起,有效地克服了数据分布的差异性,从而保证了学习器的泛化能力。
但是,相对于原始样本集所直接训练出的SVM决策曲面,由于下采样特性引起的样本空间稀疏性问题,可能导致下采样训练所得的SVM分类边界仍然会有一定程度的偏离。为改善这一不足,本文将所提优化下采样方法所建立起的训练集用于初始的SVM训练,在以相对少数量的训练样本来逼近原始样本空间结构分布的前提下,通过下采样方法训练所得SVM的决策曲面上寻找原始训练集中边界附近的样本,以此作为二次训练样本集合,随后来训练出一个新的SVM分类器。
为验证本文所提方法的特性,分别在人工数据集及基准数据集上与其他方法进行了实验对比。实验表明,在大样本数据集分类问题上,本文方法在有效提升SVM训练效率的同时,可以保证良好的泛化性能。
1 SVM算法原理
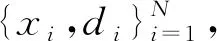
(1)
式中:优化所得的非零拉格朗日乘子αi对应的样本项称为支持向量;C为选定的正参数。该方法可以通过将输入样本x非线性映射到高维特征空间φ(x)进行拓展。然后使用如下核技巧:
K(xi,x)=φ(xi)T·φ(x)。
(2)
相应的SVM决策边界可以通过下式来实现:

(3)
式中Ns为支持向量的个数。
2 势函数密度聚类的优化下采样SVM方法
本文所提方法的一个关键任务是如何实现对原始训练样本集的下采样优化选取,这里所提的下采样指的是从原始样本集中抽取或聚类选择具有一定代表性的样本,以达到训练样本规模的降低。
2.1 算法实现原理
为了能有效降低原始训练样本集的规模并保证SVM的分类性能,本文首先使用势函数密度聚类的方式从原始的训练样本集中筛选出新的样本集合,以此构造下采样训练集来训练SVM分类器。在此基础上,寻找分类器边界的错分样本及距离边界较近的样本点,以此构成二次训练样本集合来训练出一个新的SVM分类器。
势函数[18]反映的是空间中两个向量随距离变化的影响程度。设x,y分别表示模式空间的两个向量,γ(x,y)表示由这两个向量建立的势函数。根据文献[18]的描述,一类常用的势函数模型给定如下:

(4)
式中:T为常数,可以视为距离加权因子;d(x,y)表示x与y之间的距离。
借助势函数的定义,本文将势函数的数学模型引入训练样本空间,设计了势函数密度聚类的学习机制以实现对训练样本空间的密度度量,然后将聚类所得各个中心样本作为下采样所得的SVM训练样本集合,这一过程主要通过建立不同参数的高斯核对样本空间进行覆盖来完成。每一次覆盖增量生成一个采样样本,依照该方式来完成对原始样本空间不同区域样本的抽取。为提高样本空间不同区域覆盖的准确性,在本文所提利用势函数来度量样本空间区域的密度的过程中,考虑训练样本集的标签信息,即样本势值的度量是以训练集中的相同模式类别样本集合为基础来完成的。

(5)
其中u,v=1,2,…Ni且u≠v
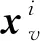
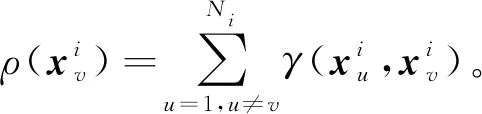
(6)

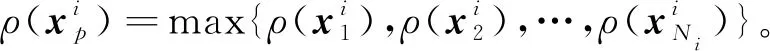
(7)
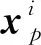
v=1,2,…Ni,v≠p。
(8)
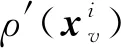
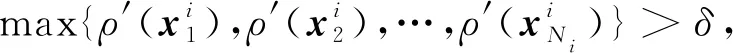
(9)
则为寻找下一个具有代表性的训练样本做好准备,其中δ为阈值。通过这种方式逐次完成对Si所在样本空间的有效覆盖;否则,转向学习其他的模式类别,直到所有模式类别学习完毕,并最终构建新的训练样本集合S′。
以上所提势函数密度聚类来增量构建下采样训练集的过程中,考虑每一类样本的标签信息,通过统计样本空间中每个样本点的势值,可以建立各样本的势值度量,其中势值较大的样本点所在的样本区域较为密集,反之较为稀疏,以此视为对样本空间的密度聚类学习。这种势值的度量考虑到了当前样本与其他样本之间的距离信息,可以将训练样本空间的全局分布信息有效利用起来。通过将学习所得的最大势值所对应的样本作为各个高斯核的中心,可以建立不同参数的高斯核完成对样本空间不同区域的有效覆盖,每一次覆盖对应生成一个相应的下采样样本。考虑到高斯核具有良好的局部特性,该下采样样本可以视为在原始样本空间中某个局部区域的表征;同时,建立起相应的势值更新机制,以消除被某个已建立起的高斯核所覆盖区域的样本势值,为生成下一个下采样样本做准备。按照该方式,本文所提方法可以根据原始样本空间的分布情况自适应生成下采样样本集,这些生成的下采样样本直接来自于原始样本空间各个不同的局部区域,可以有效逼近原始样本空间的结构分布,从而确保了学习器的泛化能力。设初始训练集S中的个数为N,经过下采样所得S′中的个数为M,当N较大时,只要所设定的覆盖原始样本空间的初始核宽有效,总能保证M≪N。当本文所提基于势函数聚类的优化下采样方法运行完毕,即可利用已有SVM算法对下采样得到的集合S′中的样本进行训练,以得到相应的SVM决策边界。
尽管如此,相对于原始样本集所直接训练出的SVM决策曲面,由于下采样特性引起的样本空间稀疏性问题,可能导致所得的SVM分类边界仍然会有一定程度的偏离。为进一步改善该问题,在所建立的SVM决策边界寻找原始训练样本集中边界附近的样本。相对于其他样本,分类器边界附近的样本显然拥有更多分类信息,以此构成一个新的二次训练样本集S″。如图1所示为本文所提方法的原理示意图。图中每个圆圈表示一个不同参数的高斯核,用以实现对样本空间局部区域的覆盖,这种覆盖按照样本空间的密度从密集到稀疏,以增量学习的方式逐次进行,每个高斯核的中心即为抽取的下采样样本。
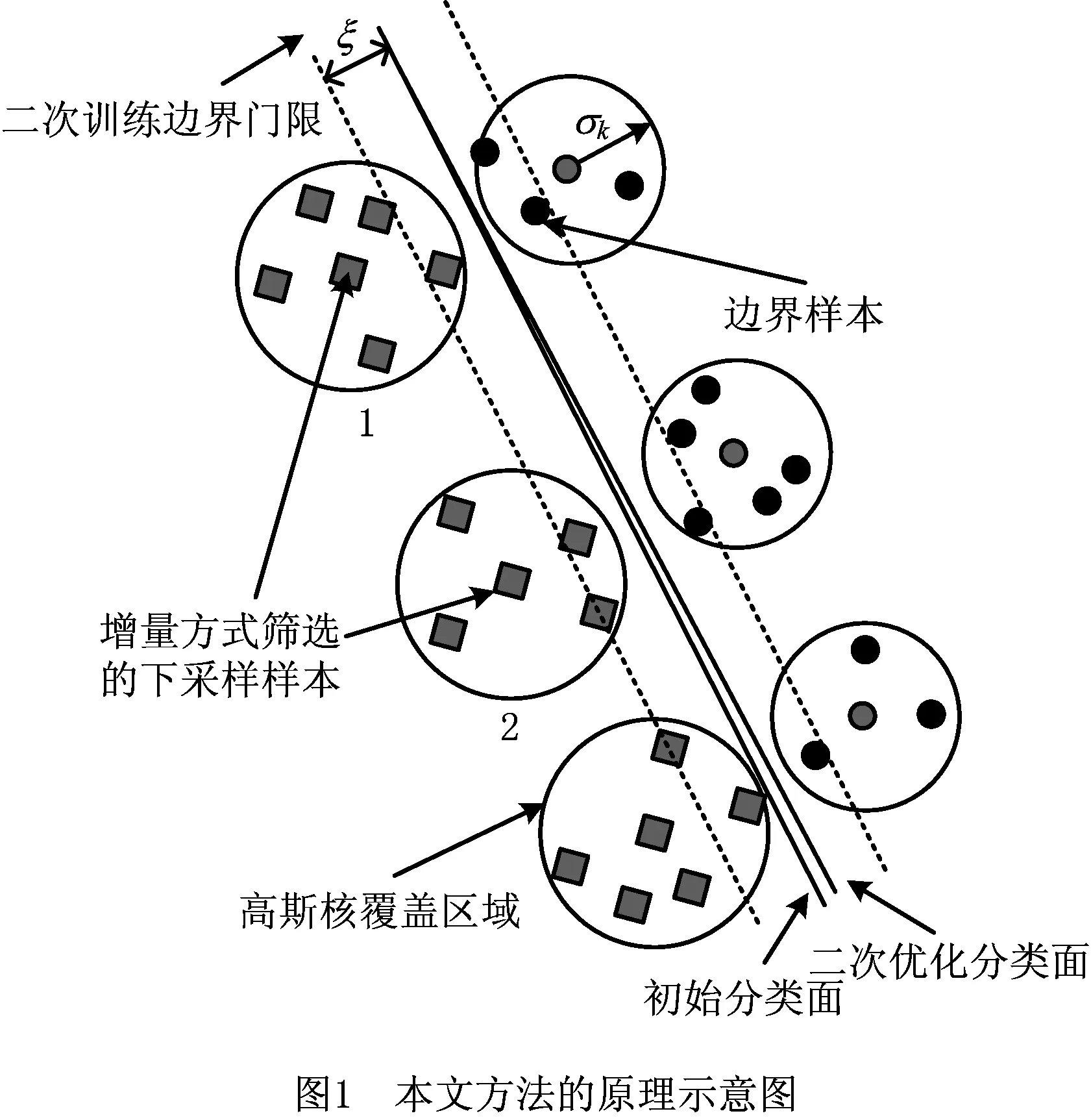
结合以上描述,本文所提的势函数聚类的优化下采样SVM学习算法如下:
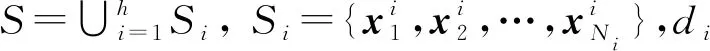
1.使用式(5)和式(6)计算每个样本势值。
2.使用式(7)来确定最大势值对应的样本。
4.使用式(8)来更新Si中每一个样本势值。
5.设置迭代终止条件

返回第2步继续执行。
Else
当前Si类中样本的学习进程结束。转向学习其他模式类别集合,直到所有模式类别集合学习完毕。
End If
6. 使用SVM学习库(Libary SVM, LIBSVM)[16]算法对样本集合S′中的样本进行训练,得到SVM初始分类曲面。

8.使用LIBSVM算法对样本集合S″进行二次训练,得到最终的SVM决策曲面。
2.2 计算复杂度分析
本文首先通过使用势函数密度聚类的方式来构造下采样样本集,然后在所获取的下采样集上进行SVM初始训练,通过寻找原始训练集中的边界样本,以进行SVM二次优化。其计算复杂度分析如下:
(1)使用势函数密度聚类的方式在增量构造下采样训练集。设初始训练集S中的个数为N,经过下采样所得S′中的个数为M,本文所提势函数密度聚类来增量构建下采样训练集的过程中,考虑了每一类样本的标签信息,样本势值的计算需要遍历当前模式类别中所有其他样本,这里设定初始训练样本集包含2个模式类别,其样本个数分别为N1和N2,则N1+N2=N,同时考虑到建立不同参数的高斯核来覆盖样本子空间的势值更新过程,计算复杂度为O((N1-1)2+(N2-1)2+M),整理后为O(N2-2N1N2-2N+M)。
(2)使用下采样集进行SVM初始训练并寻找原始训练集中的边界样本,以进行SVM二次优化。设二次优化SVM的训练样本个数为L,结合SVM的初始训练过程,计算复杂度为O(M3+L3)。
结合以上分析,计算本文所提势函数聚类的优化下采样SVM分类方法的整个计算复杂度为O(N2-2N1N2-2N+M+M3+L3)。当设定的覆盖原始样本空间的初始核宽有效,可以保证经过下采样抽取所得下采样样本数M≪N;SVM的二次训练样本来源于原始训练集中使用下采样集进行SVM训练的边界附近样本,其样本个数L≪N。这里需要指出的是,直接使用原始样本集进行SVM训练的计算复杂度为O(N3),对于大样本集,当N很大时,相对于直接使用原始样本集进行SVM训练的方法,本文所提方法的训练效率可以得到很大程度的提升。
3 实验结果及分析
为验证本文所提方法的性能,分别在双月人工数据集[19]、Occupancy基准数据集[20]、Record基准数据集[20]以及ljcnn1[21]基准数据集上,将本文所提方法分别与LIBSVM[21]、随机下采样SVM[9]、聚类SVM[12]、GSVM[13]、S_GSVM[16]以及APG_SVM[17]学习算法进行了实验对比,其中使用人工数据集是为了对本文所提方法进行图形化的验证,图2所示为双月人工数据集示意图。实验中所有样本都归一化到[-1,1]之间。本实验设置实验参数T=1,势函数聚类核宽参数σ取值在0.1~0.6之间,势函数学习阈值δ=0.001。SVM中选用的核函数为径向基函数,核宽参数取自集合[0.25,0.5,1,2],惩罚参数设置为C=1000,仿真算法为当前流行的LIBSVM,实验中设定二次训练边界门限值为ξ=0.05。实验环境为 Intel 2.8 GHZ CPU,4 G RAM。表1所示为分类数据集的信息描述。
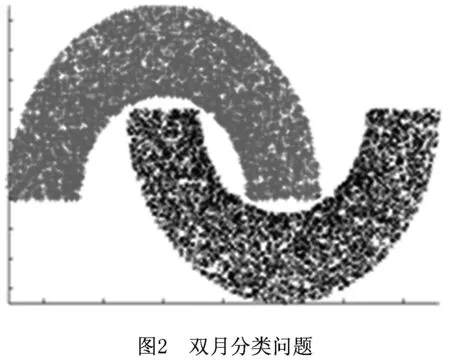
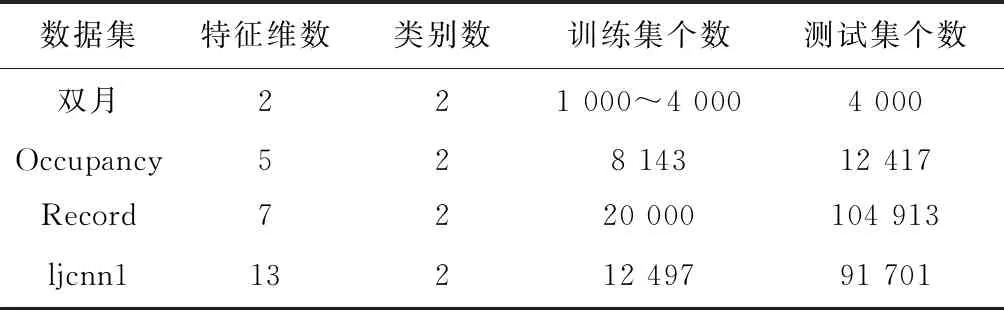
表1 分类数据集信息描述
3.1 双月人工数据集分类问题
图3所示为势函数聚类的优化下采样SVM训练和分类效果图。图3中选定训练样本个数为3 000,测试样本个数为4 000。图4所示为训练样本个数以及核宽参数σ改变时下采样与筛选边界样本效果对比。图4a~图4c对应取值为σ=0.1,图4d~图4f对应取值为σ=0.2。相对于原始样本集,采用本文所提的下采样方法所得的训练样本的个数得到很大程度的下降,并完成原始训练样本集的下采样优化筛选。相对于LIBSVM,本文所提势函数聚类的下采样方法可以完成对原始样本空间的有效逼近,其训练效率得到了很大改善。通过对下采样训练所得的SVM决策曲面附近寻找原始训练集中的边界样本,可以训练出一个新的学习器,这种采样优化和学习器优化相结合的策略在有效提高训练效率的同时保证了学习器具有良好的泛化性能。
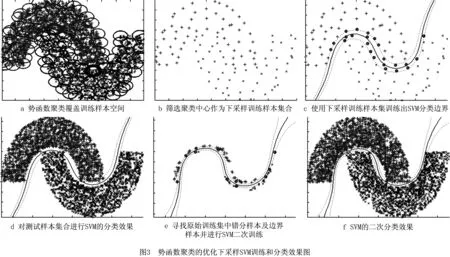
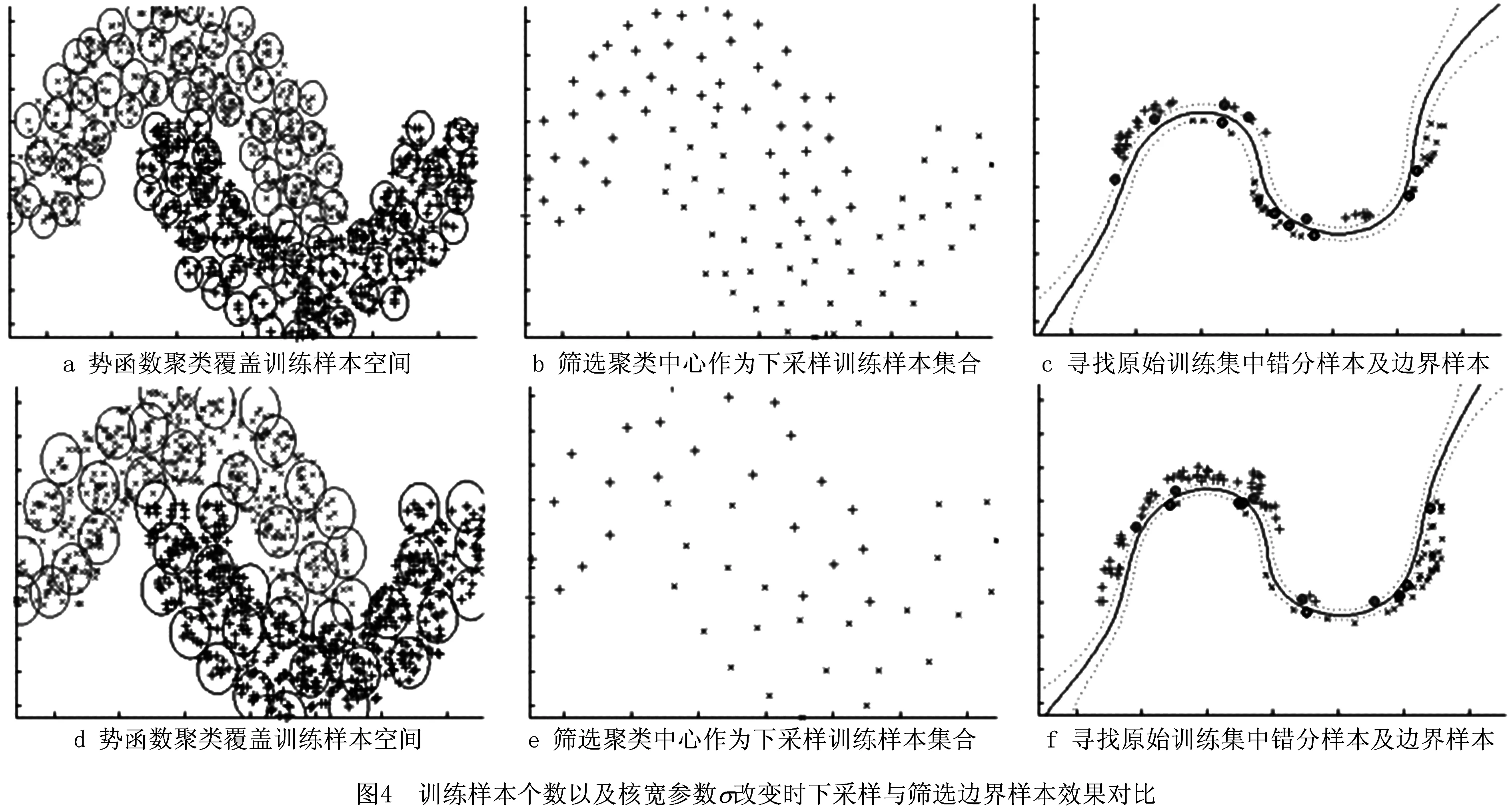
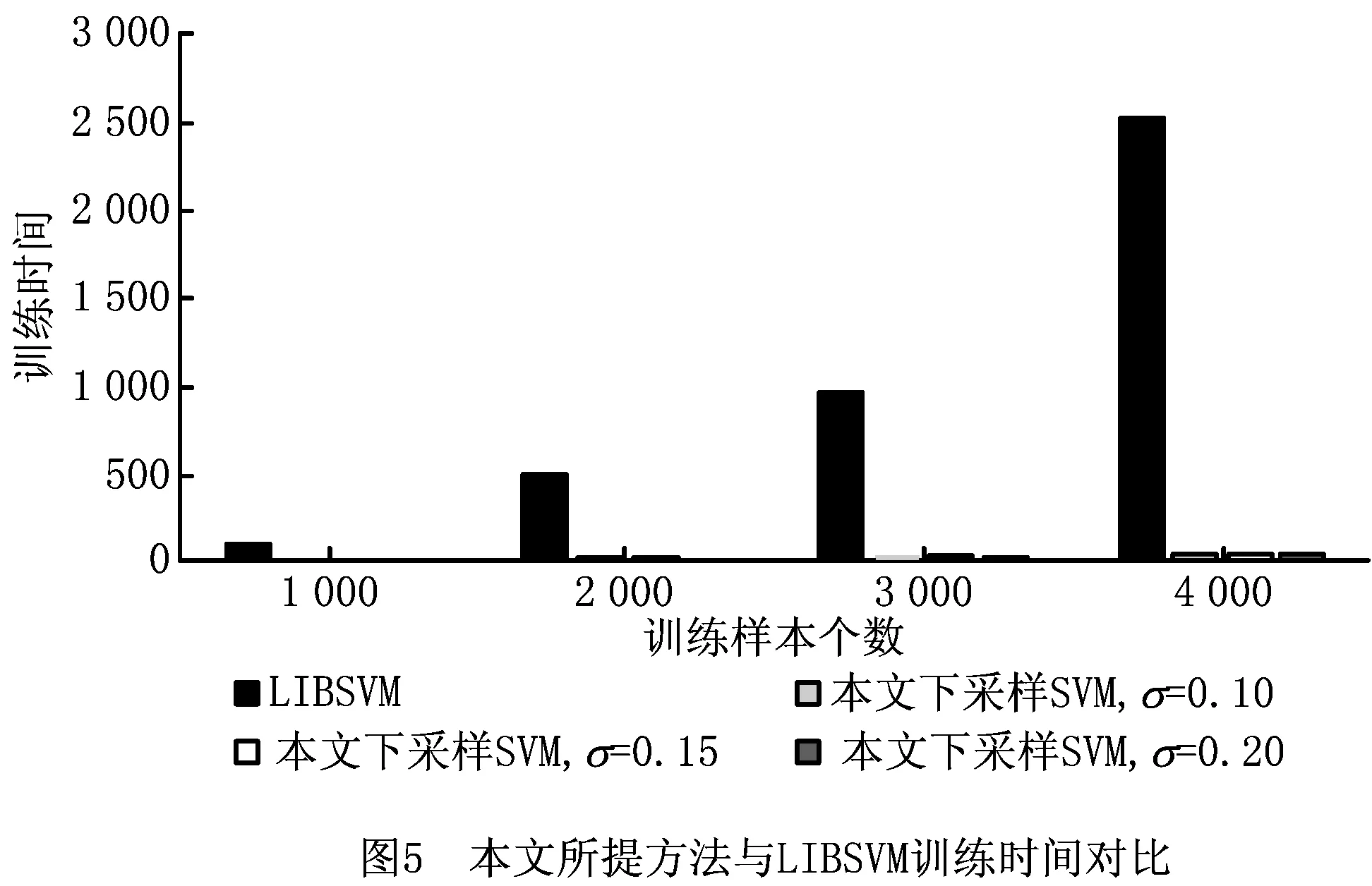
由图4选定训练样本个数为1 000可以看出,相对于图3,当训练样本个数发生变化时,本文所提方法依然可以在样本空间的不同子区域筛选出具有代表性的不同下采样样本集合,而随着核宽参数的增加,对原始样本空间的不同的局部区域覆盖范围增大,尽管下采样所得的样本个数减少,但整体上依然可以逼近原始样本空间的结构分布,从而进一步表明本文所提势函数聚类的下采样方法对样本空间具有较好的自适应性。表2所示为双月数据集下本文方法与LIBSVM的性能对比,由表2可知,在所提初始下采样样本方法有效的前提下,本文的二次筛选样本方式进一步确保了学习器的分类性能。图5所示为本文所提方法与LIBSVM训练时间对比。从图5可以看出,随着训练样本个数的增加,本文所提方法的训练时间明显少于直接对原始样本集进行训练的LIBSVM方法,因此尤其适用于大样本集下的SVM训练和分类。
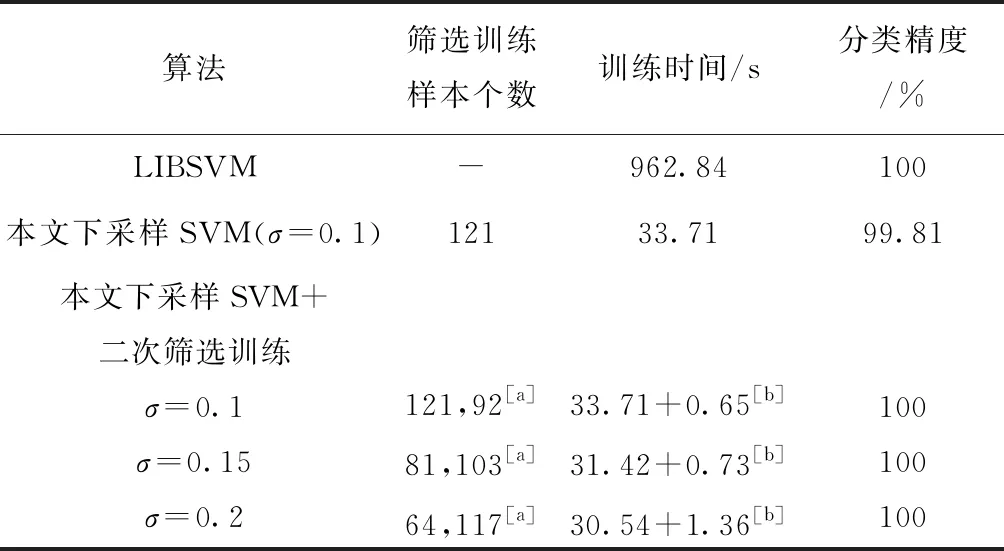
表2 双月数据集下本文所提方法与LIBSVM的性能对比
注:[a]表示势函数聚类筛选的下采样集合中的样本个数与二次优化筛选的边界样本个数;[b]代表从势函数聚类筛选下采样训练集到二次优化训练SVM分类器的时间。
3.2 基准数据集分类问题
表3~表5分别给出在Occupancy、Record和ljcnn1基准数据集下,本文所提方法与其他方法的性能对比。可以看出,相对于LIBSVM,本文方法在保持分类器良好泛化性能的前提下,训练时间得到极大程度的降低。相对于随机采样SVM、聚类SVM以及GSVM方法,本文方法的训练时间和分类精度均有不同程度的改善。在ljcnn1数据集上(如表5),本文方法的训练时间与S_GSVM和APG_SVM相当;在Record数据集上(如表4),本文方法的训练时间稍高于APG_SVM。在分类精度上,本文方法的分类性能高于S_GSVM和APG_SVM。一方面,本文所提势函数聚类的方法有效结合了样本空间的全局分布信息和局部区域信息,通过统计样本空间每个样本点的势值,建立不同的高斯核实现对样本空间不同区域的覆盖来自适应生成聚类个数,可以根据样本空间的分布情况自适应筛选出具有代表性的下采样样本集合,这些下采样样本直接来自原始的训练集,由于可以有效逼近原始样本空间分布结构,保证了所得下采样训练集的有效性。相对于原始训练集,在下采样集合极大降低的情况下,本文方法的训练效率得到了很大的改善;另一方面,本文方法通过对所建立的SVM决策曲面寻找原始训练样本集中的边界附近样本,用以完成对SVM边界的二次优化,进一步改善了学习器的泛化能力。

表3 Occupancy基准数据集下本文方法与其他方法性能对比
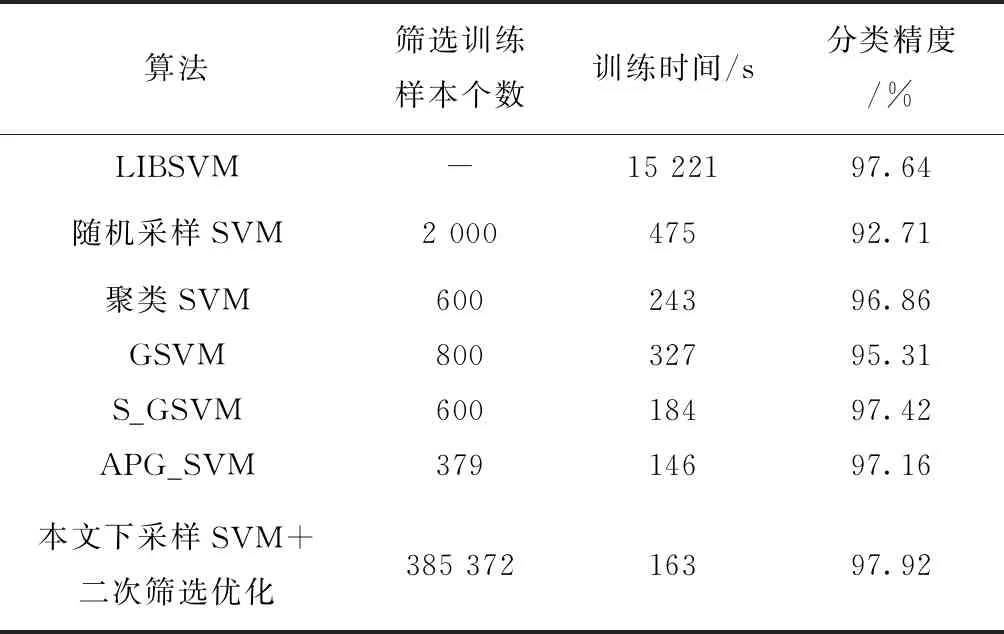
表4 Record基准数据集下本文方法与其他方法性能对比
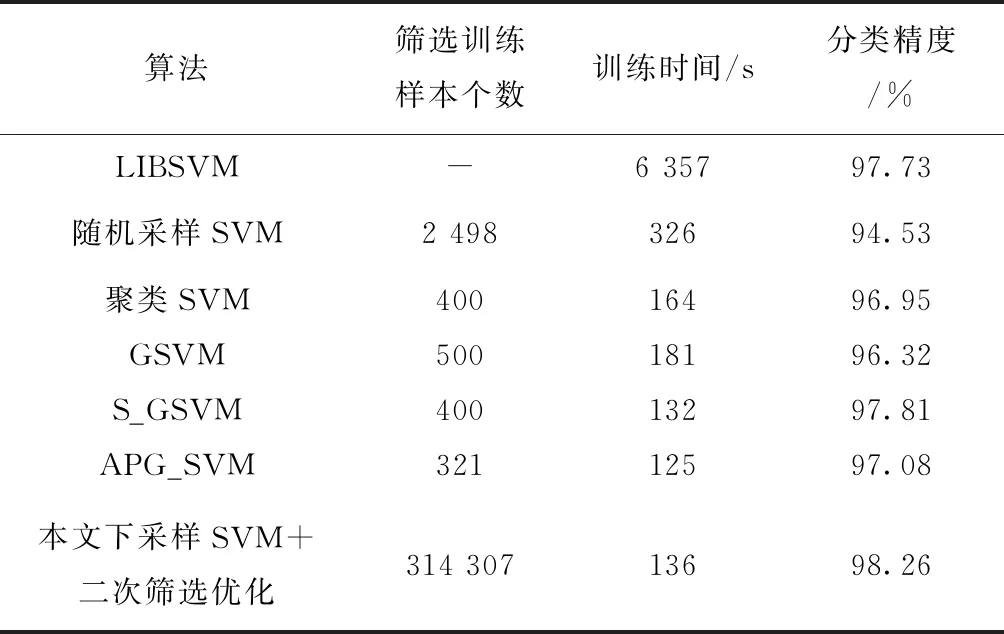
表5 ljcnn1基准数据集下本文方法与其他方法性能对比
表6~表8分别给出在Occupancy、Record和ljcnn1基准数据集下,本文方法不同核宽参数的性能对比。从表6~表8可以看出,通过改变势函数聚类核宽参数σ,对原始样本空间的覆盖尺度发生变化,所得下采样集也随之改变,但是总体上维持相对稳定的分类性能,表明本文所提势函数聚类的下采样方法对样本空间具有良好的适应性。当核宽过小,例如当σ=0.1时,此时对高维样本空间的覆盖范围有限,下采样所得样本集与原始训练样本集相同,此时本文所提势函数聚类的下采样SVM方法直接蜕化为LIBSVM。因此,在实际应用中,为保证本文所提方法的有效性,要求势函数聚类核宽参数σ不应过低,从而保证所建立高斯核覆盖原始样本空间不同局部区域的有效性。
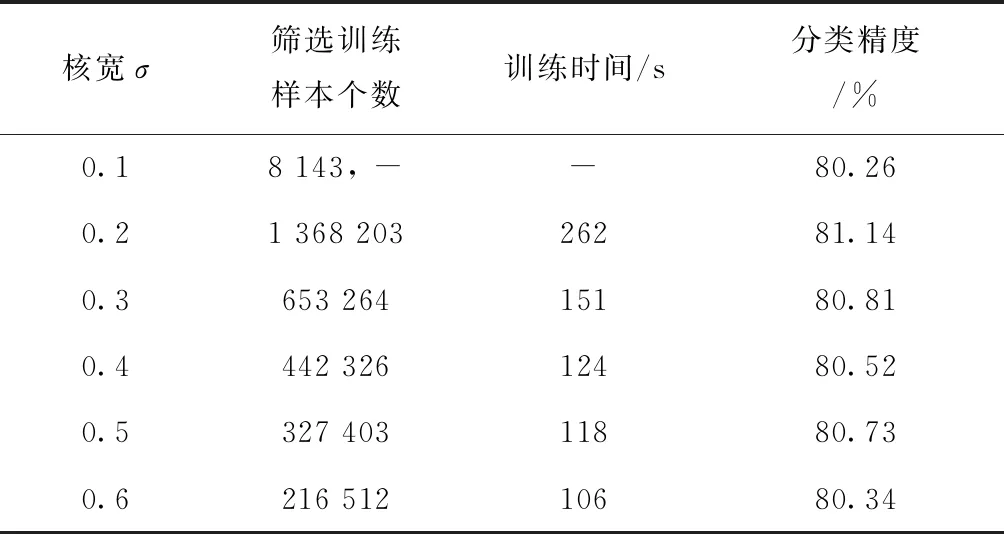
表6 Occupancy基准数据集下本文方法不同核宽参数下的性能对比

表7 Record基准数据集下本文方法不同核宽参数下的性能对比

续表7
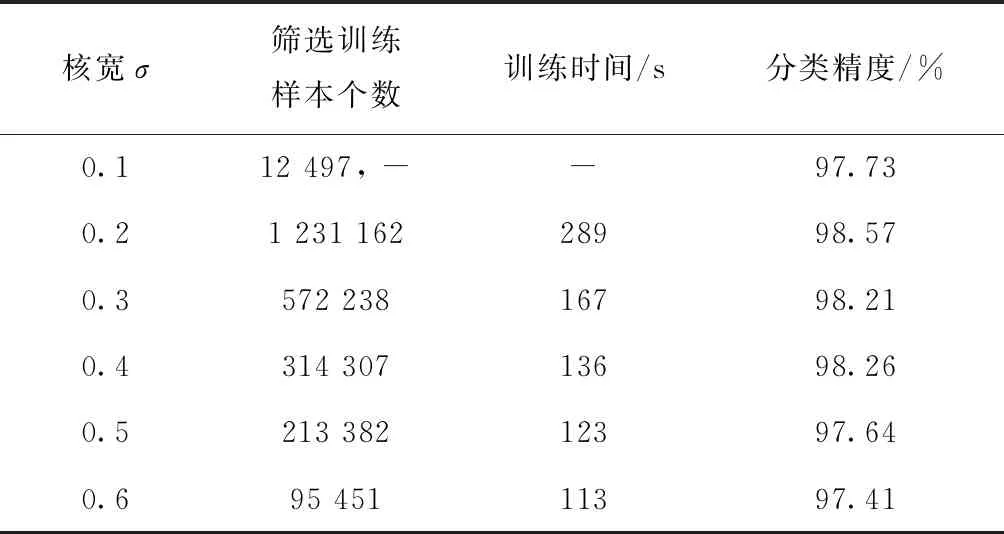
表8 ljcnn1基准数据集下本文方法不同核宽参数下的性能对比
4 结束语
本文针对大样本集SVM训练和分类问题,研究了一种势函数密度聚类的优化下采样SVM分类方法。该方法考虑了原始样本空间不同区域的稀疏程度,通过引入势函数对样本空间的各样本进行密度度量,建立了不同的高斯核完成对样本空间不同区域的覆盖,将每个核中心对应的样本作为采样样本,以此来增量构建下采样训练集,可以根据样本空间的分布自适应生成训练集的个数,并有效逼近原始样本空间结构分布。然后通过寻找分类器决策曲面附近的边界样本来进行SVM二次优化。通过在1个人工数据集和3个基准数据集上的实验表明,本文所提方法在有效改善SVM训练效率的同时保证了良好的泛化性能。由于本文所提方法采用的是批量学习的方式,适用于离线学习,但是实际问题中的训练样本往往不可能一次性得到,后续将关注在线序列学习问题,构建合适的基于增量学习的SVM。
