八角形斯坦纳树问题的文化基因算法
2019-12-21叶福玲朱伟大徐赛娟刘耿耿
叶福玲,朱伟大,徐赛娟,刘耿耿
(1.福州大学数学与计算机科学学院,福建 福州 350108;2.福州大学网络信息安全与计算机技术国家级实验教学示范中心,福建 福州 350108;3.福建商学院信息工程系,福建 福州 350012)
0 引言
随着集成电路技术的迅猛发展与成熟,其设计尺寸进入了超深亚纳米时代,可以在一个芯片集成数亿的晶体管甚至更多,使得芯片具有微型化、高性能、高集成等优点.同时,随着集成电路的集成度和设计复杂性的提高,布线的难度也随之提高[1-2].而总体布线是整个物理设计中极其重要的一个环节,总体布线的结果将决定后面详细布线的质量,从而影响到整个物理设计的结果[3].
一般的总体布线算法都是以直角结构为模型基础,其布线的方向只能是水平和垂直.在通常情况下,每一层只有一种布线方向,不同层之间通过通孔连接,这样限制了研究人员优化布线可能性.因此,为了改变传统的直角布线结构,有些研究人员开始尝试以八角形结构为基础模型进行布线[4-5],并实现了一些资源的优化,比如线长的缩短,通孔数的减少,提升了芯片整体性能.但是绝大数针对八角形布线结构的研究基于贪心策略,易陷入局部极值,无法得到最优解,所以并不能有效地发挥八角形结构所带来的优势.
斯坦纳树在图论中是极其重要的数学模型之一,是八角形结构下布线问题的基本模型[6],也是超大规模集成电路物理设计的布线阶段中多端线网的最佳连接模型,被证明是NP难问题.此外,作为一种比较优秀的算法,文化基因算法[7]于1989年由Pablo Moscato首次提出,并逐渐引起各国研究人员的兴趣和关注.文化基因算法的这种全局搜索和局部搜索的结合机制使其搜索效率在某些问题领域比传统遗传算法高效,并在NP难问题的求解中展现出良好的应用前景.近年来文化基因算法已被成功地应用到了诸多自动化控制、工程优化、机器学习等领域并取得令人满意的结果[8-12].
本研究主要分析基于文化基因算法的八角形斯坦纳树构建问题,首先,使用Prim算法预处理种群,产生初始种群,避免了因引脚数过多而无法收敛的情况.然后,通过修改文化基因的编码形式和相应操作,使其能应用于八角形斯坦纳树这一离散问题,解决超大规模集成电路中布线问题.最后,调整权重因子,使其能在一定迭代次数下,快速得到一个最优或者较优的拓扑结果.
1 问题模型
1.1 八角形斯坦纳树问题描述
给定一组未布线的线网N={N1,N2,…,Nm},对于每个线网Ni,都有n个需要完全连接的引脚,即Ni={P1,P2,…,Pn},而对于每一个引脚Pi在二维图中都对应一个坐标(xi,yi).八角形斯坦纳树问题是以最小的线长代价,将每个线网Ni对应的所有引脚都连接起来,形成一棵斯坦纳树[13].
1.2 拐点与走线模式定义
定义 1(拐点)假设源点和终点之间连接过程方向发生了改变,出现了额外的点,则称这个点为拐点.如图1所示.
定义 2(VX模式)从源点沿垂直线向上至拐点,再从拐点沿45度方向至终点,则称为VX模式.
定义 3(XV模式)从源点沿45度方向至拐点,再从拐点沿垂直线向上至终点,则称为XV模式.
定义 4(VH模式)从源点沿垂直线向上至拐点,再从拐点沿水平线向右至终点,则称为VH模式.
定义 5(HV模式)从源点沿水平线向右至拐点,再从拐点沿垂直线向上至终点,则称为HV模式.
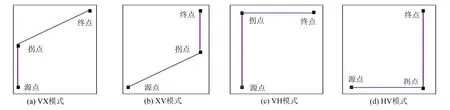
图1 走线模式图Fig.1 Routing pattern
1.3 编码方式
编码是算法和模型之间的映射关系.在斯坦纳树的构建过程中,连接方式以走线模式的编码方式来决定.对于一个线网,需要连接n个引脚,则需要生成n-1条边,每条边有4种走线模式,因此需要用一个四元组来确定一条边,则一个个体的编码长度为4(n-1)+1.例如对一个有3个引脚的线网来说,需要生成两条边.因此,其个体的编码可能为[1,1,2,VX,1,2,3,HV,8.5].其中,前4位代表第一个四元组,5到8位代表第二个四元组.四元组第一位代表的是个体所属的线网,第二位和第三位是当前选中的引脚,引脚以第四位的走线模式相连,所以,第一个四元组[1,1,2,VX]表达的意思就是线网1的引脚1和引脚2以VX模式相连.编码的最后一位代表的是这个个体的适应度函数值.
2 本研究算法
2.1 文化基因算法
文化基因算法是一种基于种群的全局搜索和基于个体局部启发式搜索的结合体[7].与一般遗传算法不同的是在遗传操作中的对象是通过局部区域搜索出来的优秀种群,而不是一般种群.这样避免了一些迂回的无用搜索,使其能避免陷入局部极值,得到全局最优.文化基因算法的这种全局搜索和局部搜索的结合机制使其搜索效率在某些问题领域比传统遗传算法高效.
2.2 本研究算法描述
本算法是基于文化基因算法,通过使用Prim算法进行预处理,产生初始个体,并修改文化基因算法中的个体编码方式,同时修改相关操作来实现八角形斯坦纳树问题的解决.个体的更新如下式所示.
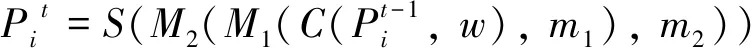
(1)
以下为基于文化基因的八角形斯坦纳树算法框架描述:

算法1 基于文化基因的八角形斯坦纳树算法: 遍历所有的线网NStep1 用Prim算法产生初始种群Step2 遍历种群中每个个体并计算其适应度函数值 Step3 算法终止条件内 1) 基于最大并集的交叉操作 2) 双重变异操作 3) 局部搜索 4) 计算适应度函数值 5) 选择下一次迭代的个体遍历结束
2.2.1初始化种群
初始的种群一般是随机产生的,也可以利用已知问题所含的信息,人为选取一些比较优质的种群个体加入.在基于文化基因的八角形斯坦纳树算法中,使用Prim算法初始化种群.这种预处理策略,能加速算法的收敛,并能在一定程度上辅助算法优化拓扑结构.
2.2.2适应度函数
在八角形斯坦纳树问题中,优化斯坦纳树的拓扑结构,使其线长最短是首要目标.在一个线网中,有n个需要连接的引脚,需要n-1条边和n-1个拐点.则对一个种群而言,其目标函数值应该是2n-2条边的长度之和,计算公式如下式所示:
(2)
其中:Ni代表第i个线网,ej属于八角形斯坦纳树的一条边.
适应度函数值的大小往往代表着个体的优劣,目标函数值越小,表示该个体越优秀.因此,在八角形斯坦纳树算法中,个体的适应度函数是一个非零常数和目标函数值之和的倒数,其计算公式如下:
F(Ni)=[C+L(Ni)]-1
(3)
其中,C是一个非零常数,代表的是线网中的单位长度.这样做的目的是为了防止出现目标函数值为0的情况,即引脚重合 .
2.2.3混合优化的遗传算子
遗传操作的结果是选出那些适应性强的优秀代表,同时也产生一些交叉作用后新的个体,这些新个体可能属于一些新的区域,在下一代的局部搜索中会被优秀个体取代,然后再进行进一步的全局进化.这种局部的启发式搜索与全局寻优搜索的混合搜索机制在进化效率上显然要比单纯在普通个体间搜索高得多.本研究使用混合优化遗传算子,分别是基于最大并集的交叉操作和双重变异操作.
1)基于最大并集的交叉操作.为了加快算法的收敛速度,基于文化基因的八角形斯坦纳树算法采用最大并集的策略来实现交叉操作,选择当前最优的个体和迭代过程中最优的个体进行交叉.初始阶段是得到两个个体的交集,第二个阶段是将剩下未连接到斯坦纳树上的引脚,随机选择前两者中的一种连接方式连接起来,最终得到交叉操作的结果,详见图2所示.
2)双重变异操作.为了降低造成局部收敛的可能性,避免种群选择的局限性.本算法采用双重变异操作,即两种变异方式来拓展文化基因算法的搜索.第一种是拐点的变异,第二种是引脚选取方式的变异.
拐点的变异是改变四元组的最后一位的走线模式,从四个走线模式中随机选择一种走线模式.例如,线网1的个体[1,2,1,HV]变异成为[1,2,1,HX],从而得到了更优的个体.如图3所示.
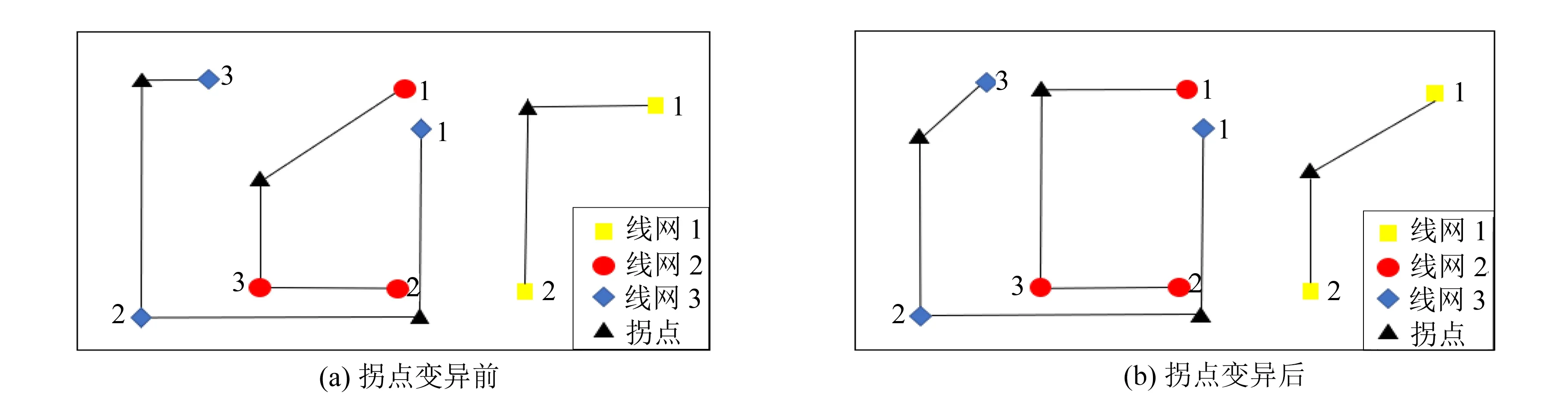
图3 双重变异操作Fig.3 Double mutation operation
引脚的变异是多点变异,改变了八角形斯坦纳树的拓扑结构.通过不同的拓扑结构来寻优,让基于文化基因的八角形斯坦纳树算法有较强的搜索能力,使其得到更好的结果.
2.3 局部搜索
局部搜索的目的是得到局部区域内最优秀的个体[8].若不采用局部搜索算法,可能会导致算法的局部搜索能力变差,无法得到最优或者较优的结果.在八角形斯坦纳树算法中,局部搜索的领域是个体所有边的所有走线模式,从VX模式到HV模式.最终得到局部搜索领域中最优的个体,更新种群.局部搜索算法流程描述如下:

算法2 局部搜索算法: for 遍历所有的边for 遍历四种走线模式 计算当前走线模式的适应度值 if 当前走线模式的适应度值大于最大的适应度值 更新当前的最大适应度值
2.4 选择种群
合并父代和子代个体,计算所有个体的适应度值,按照适应值大小排序,选择与种群规模大小相同的优秀个体组成新种群.
2.5 终止条件
同其他优化算法一样,为了避免陷入极端,基于文化基因的八角形斯坦纳树算法也设置了一个迭代阈值和迭代结果要求精度邻域,当满足两者之一时,算法会终止.
3 实验验证
3.1 实验基本设置
为了验证基于文化基因的八角形斯坦纳树算法的有效性和优越性,本研究开展了一系列实验对比.实验环境:window 10 操作系统、i5-6500处理器、3.20 GHz主频、8.00 GB内存.算法采用C++实现,用Visual Studio 2015编写与运行,分别对单个线网和多个线网两种测试用例进行实验.
3.2 预处理策略的有效性证明

表1 验证预处理策略的有效性Tab.1 Verify the effectiveness of the preprocessing strategy
为了验证算法所使用的预处理策略的有效性,设置种群规模为50,最大的迭代次数为200,验证预处理有效性的10组测试用例是单个线网数据集,其引脚数最少的为8,最多的是1 000,每个测试用例均运行10次并取线长的平均值.
在相同的运行环境下使用Prim算法和未使用Prim算法预处理种群,通过10组测试用例,对比线长方面的优化效果(见表1).使用Prim算法预处理种群生成一个最小生成树,避免了因为引脚数过多造成的解空间过大而不能得到一个收敛结果的情况.正如表1的实验结果所示,第三列是未使用预处理策略得到的线网线长,第四列是使用预处理策略得到的线网线长,对于任何一个测试用例,预处理策略都发挥了优化的效果,并且随着引脚数量的增加,使用Prim算法预处理得到的结果优化率显著提高.对于这10组数据,使用了预处理方案的结果比未使用预处理的结果平均优化了50.74%的布线线长.
3.3 与其他算法的实验对比
验证算法优越性的测试用例是ISPD98的9组多线网数据集,其中线网数目从11 507个增长到64 227个,引脚总数从44 266个增长到269 000个.本研究中每个测试用例均运行10次该算法并取线长的平均值,最后与K近邻算法(K-nearest neighbour,KNN)[14]和伪布尔SAT的算法(A pseudo boolean SAT,SAT)[15]进行比较.本研究算法对于每个测试用例在线长方面都有较大的优化,几乎每个测试用例都优化了10%以上.最终,本算法分别比SAT和KNN平均减少了11.52%和10.24%的布线线长,充分说明基于文化基因的八角形斯坦纳树算法在处理现实布线中能有较大的优越性详,见表2所示.

表2 与SAT和KNN算法的对比Tab.2 Comparison with SAT and KNN algorithms
4 结论
本研究提出了基于文化基因的八角形斯坦纳树算法,并成功应用于超大规模集成电路物理设计中布线问题.首先,在预处理阶段使用Prim算法处理种群,克服了因为引脚数量过多造成的无法收敛的情况.其次,根据八角形斯坦纳树结构的特点,结合文化基因算法,定义了四种走线模式,设计了新的编码方式并修改了相应的操作,使其能在全局范围内,快速收敛并全局寻优.最后,通过实验证明基于文化基因的八角形斯坦纳树算法的有效性和优越性,再与最近几年提出解决布线问题的SAT和KNN算法相比,分别取得了11.52%和10.24%的优化率.
