基于信息熵抽样估计的统计学习查询策略
2019-12-18曲豫宾
曲豫宾,陈 翔
传统有监督学习是使用标记数据集训练模型,然而标记数据集有时候需要花费大量时间与成本,主动学习[1]框架通过在未标注数据集中选择少量示例进行标注,达到较好的分类效果.基于池的主动学习查询策略大致可以划分为基于异构标准的样例选择策略、基于性能的样例选择策略、混合选择策略等[2].基于异构标准的样例选择策略包括Uncertainty Sampling,Query-By-Committee,Expected Model Change[1]等;基于性能的样例选择策略包括ExpectedErrorReduction,Variance Reduction;混合选择策略包括Density-Weighted Methods,QUIRE等几种.常见用于分类的模型包括朴素贝叶斯、随机森林、支持向量机等.
本文重点关注基于统计学习的主动学习查询策略,该类策略是从影响主动学习的分类性能出发选择标注样例.同时关注基于信息异构的主动学习查询策略.
Uncertainty Sampling基于不确定度的角度来选择未标注样例,实践中发现该策略具有较强的鲁棒性,但是存在异常点选择的问题;Query-By-Committee维护分类器集合,根据不同分类器的不一致性作为选择未标注样例的标准,常见的评价标准包括VoteEntropy,Killback-Leibler divergence[1]等,该策略本质上是一种通过对假设空间的收缩来实现样例选择;Expected Model Change策略使用决策信息论的方法选择对模型影响最大的未标注实例;Expected Error Reduction是基于统计学习理论直接计算未标注样例的不同标注带来的期望风险,根据期望风险最小化准则来选择未标注样例,该策略优点是根据样例直接计算优化损失函数,但存在计算复杂度较高的问题;Variance Reduction策略不是通过直接优化期望风险,而是间接地减少输出方差实现对未标注样例选择;Density-Weighted Methods在考虑未标注样例信息量的同时考虑未标注样例的代表性,对信息量与代表性施以不同的权重,根据权重值选择样例.HUANG S J等人[3]结合支持向量机提出的QUIRE算法也属于此类,在多个领域具有较好的分类效果,然而存在计算复杂度较高的问题.
使用统计学习的方法选择未标注样例得到了深入的研究.MACKAY D、COHN D A等人[4-5]提出使用统计学习的方法来优化目标函数,使用前馈神经网络等分类器来创建模型.ROY N等人[6]提出直接使用最小化期望风险函数的统计学习方法来选择未标注样例,但该方法仍然存在计算信息量较大的问题.WANG Z等人[7]通过极小化经验风险选择信息量大及有代表性的未标注样例.TANG Y P等人[8]引入自步学习选择易分类的未标注实例,同时选择符合信息量大等特征,有潜在价值的未标注实例,取得了较好的分类效果.
目前,ZHU X J等人[9-10]提出了使用概率图模型优化期望风险函数,在优化的同时使用半监督学习来减少标注量,取得了不错的分类效果.GAD E E等人[11]从标注数据集中引入先验信息,使用概率图模型做样例选择.这些查询策略从概率图模型角度去选择样例,为主动学习研究提供了新的视角.
为了解决随机采样的性能不稳定问题,以及计算复杂度过高等问题,本文提出使用信息熵作为衡量标准对未标注样例进行选择,对选择的样例子集合计算平均期望风险,选择使得平均期望风险最小的样例进行标注.在真实数据集上进行实验,实验结果表明该策略与基准策略相比,时间复杂度较低,有效性较高.
1 基于信息熵的期望误差减少抽样估计的主动学习查询策略
基于信息熵的期望误差减少抽样估计的主动学习(Active Learning through sampling estimation of Expected Error Reduction based on Information Entropy,ALEERIE),该主动学习查询策略的提出是基于看待数据的角度不同,使用期望误差减小的统计模型选择查询样例偏向于整体数据分布,而信息熵关注的是单独样例的信息量.基于信息熵的不确定度采样策略在选择特定样例过程中要有较强的有效性和鲁棒性,因此可以结合两种策略制定混合式的主动学习查询策略.
基于统计学习的学习策略需要循环遍历整个未标注数据集,因此存在计算复杂度比较高的问题,具体复杂度是O(N2),而在基于信息熵的期望误差减少抽样估计的主动学习中,使用基于信息熵的抽样估计以后,复杂度可以降低为O(Q×N).N表示未标注样例的总数,Q表示使用信息熵进行抽样估计的数目.
ROY N等人[6]提出使用统计学习中最小化期望风险的办法来选择未标注样例.使用主动学习框架建立的最佳分类器应该是选择未标注实例以后,人工标注实例并将其加入到训练数据集,在该训练数据集训练模型时能够减少期望风险,具有最佳的泛化能力.
设训练样例x∈D=Rn,实例的标记为y∈Y={y1,y2,…,yk},对训练样例x的条件概率分布为P(y|x),该分布未知.已标注样例集合D采用独立同分布采样,其联合概率分布P(x,y)=P(y|x)P(x),对输入样例x,则生成后验概率(y|x),因此基于统计学习的期望风险为
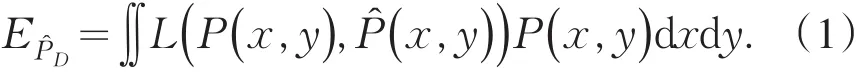
损失函数L用于衡量样本(x,y)的真实概率分布P(x,y)与后验概率估计分布(x,y)的差值.本方法采用的损失函数为对数损失函数,
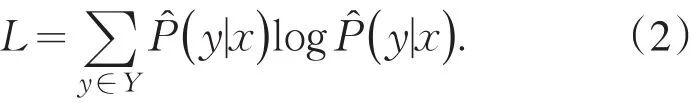
期望风险EP̂D优化的目标为选择最优未标注样本序列k={x1,x2,x3,…,xk},其中k表示从未标注样本中采样的次数,对于样本序列k中的每个未标注样例(x*,y*),

本策略针对基于未标注样例池M进行学习,因此学习的范围确定,对于未标注样例有确定的估计P(x).定义将未标注样例(x*,y*)加入已标注样例集合D产生的新的标注集为D*=D+(x*,y*),新的标注样例集D*的分布函数未知,为了能够有效地计算公式(2),采用已标注样例集的概率分布来估计当前未标注样例(x*,y*),则当前分类器的经验风险为
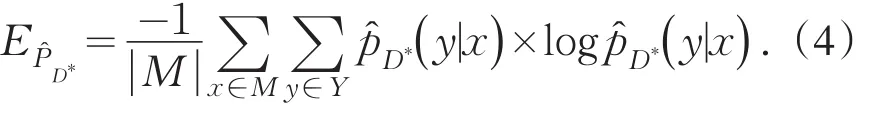
E计算出未标注样例x*,在y*∈Y情况下期望风险值,y*的真实值是未知的,可以使用已知的概率分布P(x,y),计算估计概率分布值,将不同的概率分布作为权值,计算最终期望值
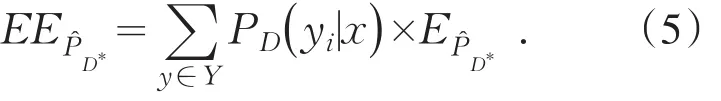
该策略存在计算量过大,复杂度较高等问题.最优未标注样本序列k的建立过程实际是在对未知分布进行有选择抽样过程.简单的抽样策略是每次在未标注实例集M循环遍历每一个样例,其时间复杂度为O(|M|2).可以选择随机采样,或者预先过滤异常点等方法减少未标注样例的选择范围.
信息熵可以用于衡量未标注样例的不确定性,作为主动学习的策略具有较强的鲁棒性.基于信息熵可以对集合M进行采样,采样的过程是计算每个样例的不确定度,从中选择不确定度最高的Q个样例.
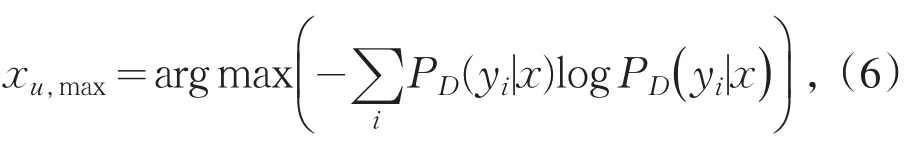
xu,max表示从集合M中选择的信息熵最高的样例,以已标注样例结合D来计算样例的信息熵值.根据信息熵,选择不确定度最高的Q个样例,对Q个样例计算响应的期望风险,并选择期望风险值最小的样例进行手工标注.算法过程如图1所示.
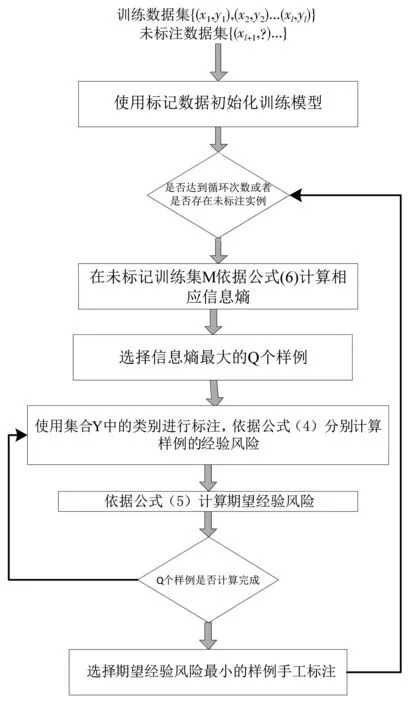
图1 基于信息熵的期望误差减少抽样估计的主动学习查询策略
算法流程如下:
算法 基于信息熵抽样估计的统计学习查询策略.
①Input:初始化标记数据集D={x1,…,xl},未标记数据集M={xl+1,…,xl+u},数据标记y1,…,yl,最大循环次数Umax.
⑥在标记数据集上训练模型.
⑦在未标记训练集M依据公式(6)计算相应信息熵.
⑧选择信息熵最大的Q个样例.
⑨forj=1 toQdo:
⑩对样例使用集合Y中的类别进行标注,分别加入到训练集中,重新训练模型,依据公式(2)计算相应的损失函数.
太和医院始建于1965年,如今已然成长为四省(市)交界地综合实力最强的一家三级甲等医院,医院服务能力辐射周边40多个县市区。
⑪依据公式(4)计算相应的经验风险函数.
⑫根据类别的不同,依据公式(5)计算期望风险函数的期望值.
⑬选择使得期望值最小的样例,进行手工标注.
⑭end while.
⑮return 条件概率分布
2 实验设计
为了验证基于信息熵抽样估计的统计主动学习策略的有效性,与随机采样过程在多个数据集上进行了对比.随机采样过程从未标记实例中随机选择若干样例,选择使得期望风险最小的样例进行手工标注.
实验数据来自于加州大学欧文分校提出的用于机器学习的数据集.选择其中的tic-tac-toe、transfusion、kr-vs-kp、diagnosis、breast-cancer用于二分类的数据集,该部分数据集经常用于主动学习查询策略的研究[8],具体的数据集描述见表1.

表1 实验中用到的数据集
实验数据采用分层抽样对数据集进行划分,50%用于训练数据,50%用于测试数据,从训练数据中取出10%作为初始标注数据集,用于建立模型.实验随机重复执行5次,采用交叉验证,因此数据集产生5×2组数据,取所有数据的平均值为该标注数据点的预测结果.
实验过程中使用sklearn工具包,分类器选择随机森林分类器与logistics回归分类器,参数使用系统默认参数.分类器的超参数优化对学习策略的影响在后期的工作中会继续研究.UCI数据集中的类别数据转换通过sklearn的LabelEncoder类来实现类标的编码,将属性转换为对应的整数值.从未标注实例中选择子集需要设定超参数Q,超参数Q表示从未标注实例集中抽样的数目,在本策略中,设定Q为20.
算法的评价指标采用ACCURACY,表示真正例与真负例与所有样例总和的比值.常见的性能评价指标还有AUC、F1-Measure等,此次实验选择的数据集,不存在明显的类不平衡问题,因此主要在ACCURACY指标上做性能评价.分类结果的混淆矩阵如表2所示[12].

表2 分类结果混淆矩阵

ACCURACY表示分类模型总体判断的准确率,是涵盖了所有分类的总体准确率.
3 结果分析
3.1 标记实例的数量对策略性能的影响
在数据集tic-tac-toe、transfusion、kr-vs-kp、diagnosis、breast-cancer中两种待比较算法随着标注样例的增加性能变化如图(2)、图(3)、图(4)、图(5)、图(6)所示.采用随机森林作为数据集的分类模型,随后将会考虑其他分类器,以验证所提的主动学习策略的有效性是否具有一般性.

图2 数据集tic-tac-toe的ACCURACY性能变化
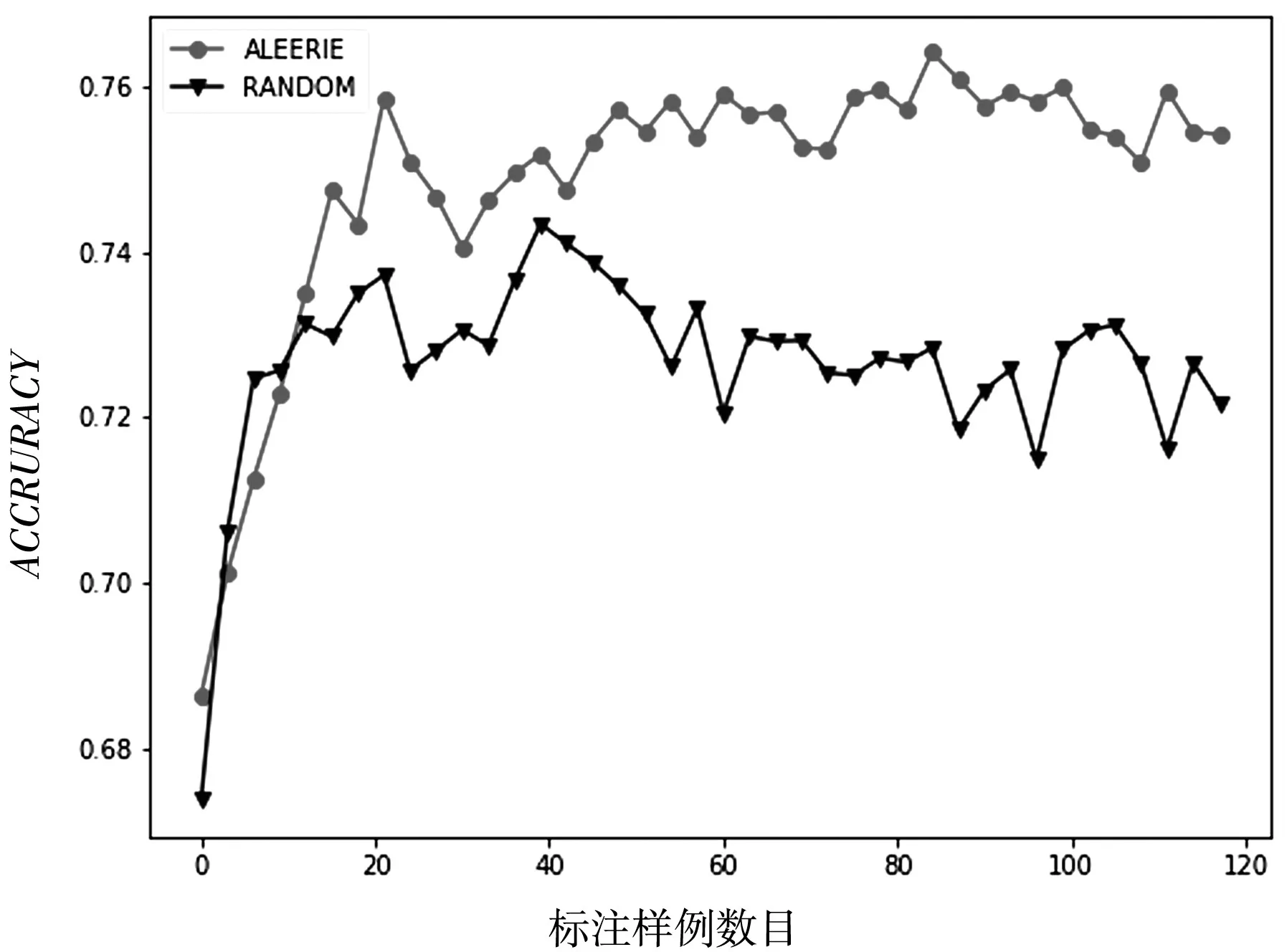
图3 数据集transfusion的ACCURACY性能变化
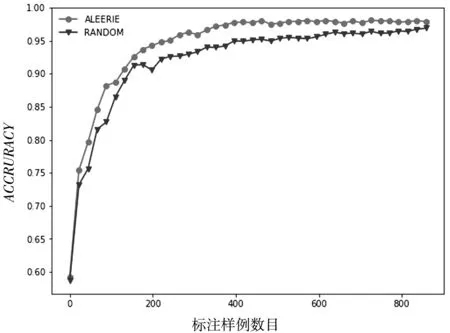
图4 数据集kr-vs-kp的ACCURACY性能变化
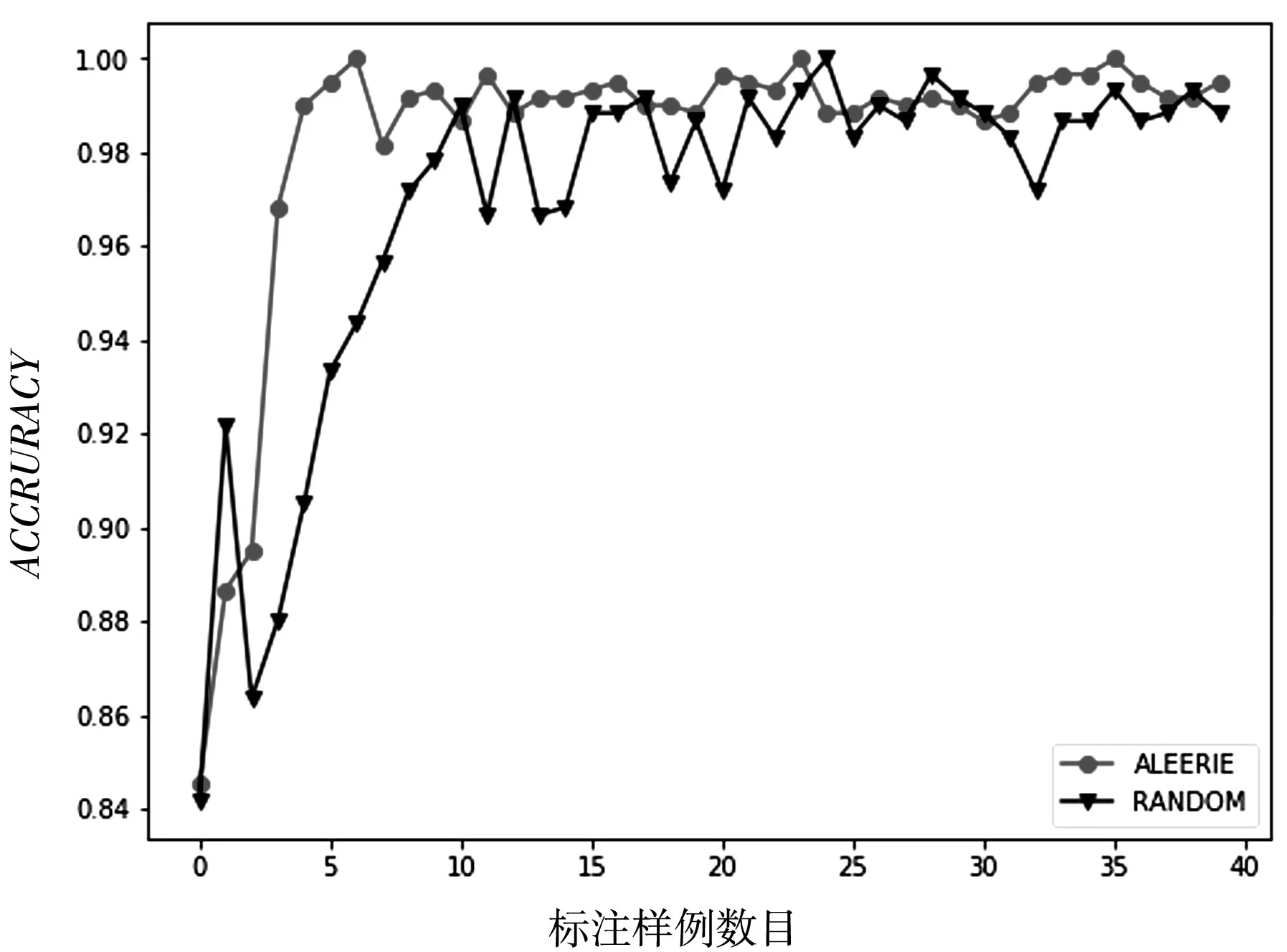
图5 数据集diagnosis的ACCURACY性能变化
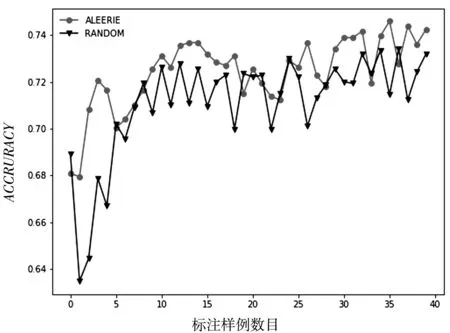
图6 数据集breast-cancer的ACCURACY性能变化
为了深入研究所提出策略的有效性,在标注数据比例为20%、40%、60%、80%、100%的情况下对两个算法的结果作win/draw/loss分析.win/draw/loss分析用于描述不同算法对于同一数据集的算法差异.比如标注数据比例为20%时候,在数据集tic-tac-toe上信息熵采样策略的分类器ACCURACY均值记为Aie,在数据集tictac-toe上随机采样策略的分类器ACCURACY均值记为Ar,如果Aie>Ar,那么win=1,如果Aie=Ar,那么draw=1,如果Aie<Ar,那么loss=1.表3展示了基于信息熵采样策略与随机策略对比的win/draw/loss.
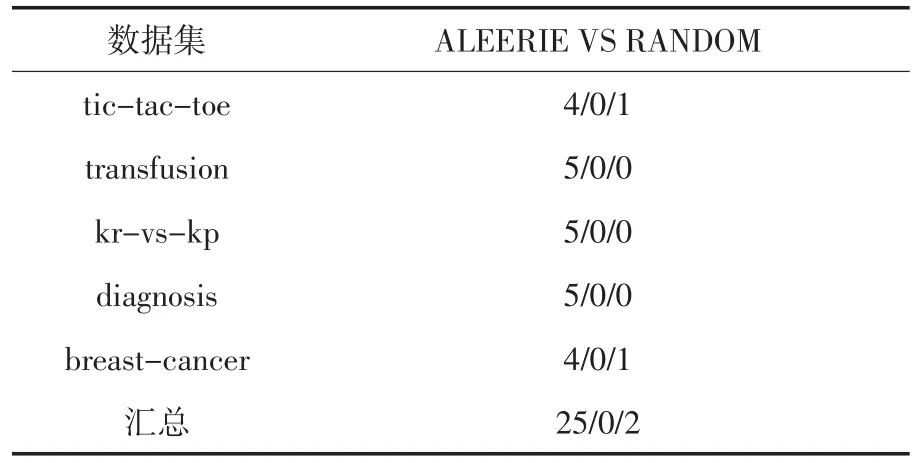
表3 基于信息熵采样策略与随机策略的win/draw/loss分析
从以上图表展示结果可以看出,基于信息熵的抽样策略比随机策略在大多数情况下都能达到较好的分类效果,充分说明了基于信息熵策略的有效性.同时也说明了在进行基于统计学习的子抽样时候,面向个体信息量的选择优于随机的选择.随着标注样例数目的增加,主动学习的两个采样策略依据不同角度进行抽样,分类算法的精度都得到了提高,也说明了主动学习方法框架的有效性.但是在数据集diagnosis上也有不同的表现,基于信息熵的策略随着标注样例的增加,快速达到较好的分类效果;而随机采样策略不但没有达到较好的分类效果,甚至分类性能出现了较大的波动.这样说明基于信息熵的策略更加有利于提升模型的分类器精度.从数据集transfusion的性能走势可以看出,随着标注样例的增多,算法性能得到了较快的增长,并且收敛于比较稳定的分类效果,而随机采样的策略在达到较好的分类效果以后甚至出现了性能下降的情况.
3.2 基于不同分类器上采样策略的性能对比
为了充分研究不同采样策略的性能变化情况,选择使用其他的分类器对数据集进行建模,通过不同分类器上不同采样策略的性能对比,为了节省空间,仅仅描述标注数据比例为20%、40%、60%、80%、100%的情况下性能对比情况.表4展示了不同分类器上不同采样策略的性能对比.
从表4的结果可以看出,不管是采用随机森林分类器(RF)还是采用逻辑斯蒂回归分类器(LR),本文提出的基于信息熵的抽样估计策略大部分情况下都取得了最优的效果,即使在部分情况下没有达到最优,也并不弱于最优性能很多.由此可以说明,针对不同的分类器或者不同的标注实例比例的情况下,本文提出的基于信息熵的抽样策略都能有稳定的性能提升.
另外从两种不同分类器的性能比较情况还可以看出,基于信息熵进行抽样估计的策略拥有更加稳定的表现,随着标注样例的增多,分类性能稳步提升直至收敛到最佳水准.而随机采样策略明显表现出比较强的随机性与性能的不稳定性.
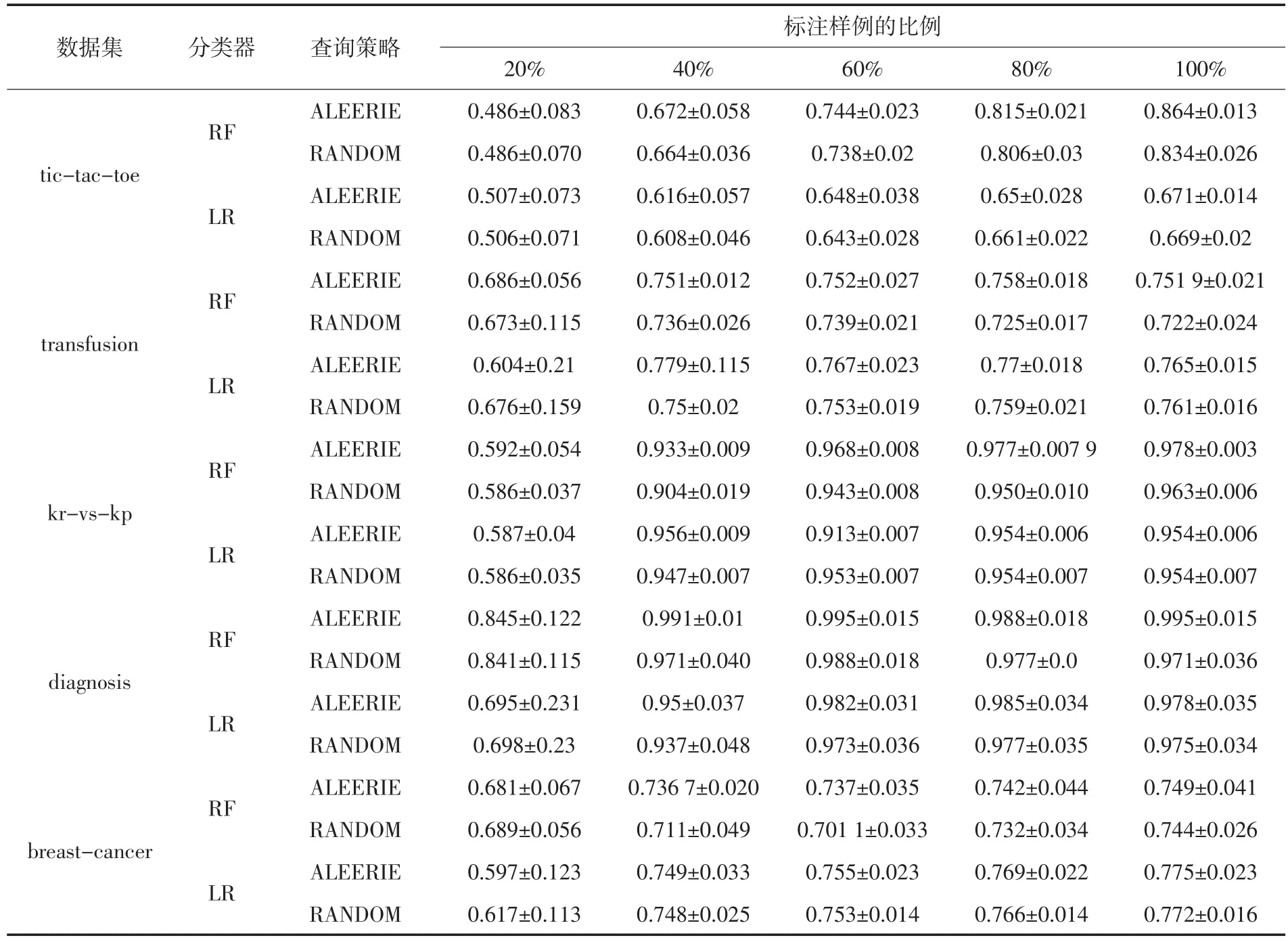
表4 基于配对t检验的采样策略对比试验
4 结论
本论文提出了在使用基于统计学习的面向期望风险减小的主动学习策略中,通过使用信息熵来进行子抽样.基于统计学习的选择策略是从宏观上选择期望风险最小的样例进行标注;而基于信息熵的样例选择策略则是从样例的微观角度选择样例,充分利用样例本身的信息量,对两者进行充分的结合有助于选择既能满足样例信息量较高又能满足期望损失最小的样例.同时选择策略有效降低了基于统计学习选择策略的计算复杂度.在机器学习的常见数据集上的实验表明,该策略能够有效地从未标注实例中选择需要人工标注的实例.后期的研究从其他的子抽样策略入手,对比研究不同的子抽样策略对于基于统计学习的主动学习查询策略的影响.当前研究的数据集采用的都是二分类的数据集,后面可以研究当前策略在多分类数据集上性能的变化情况.除了图像处理应用领域,未来也可以尝试将该查询策略应用于智慧农业等机器学习广泛应用的领域[13],从而有效减少数据集的标注成本.
