基于动态因子结构的贝叶斯分位面板协整研究
2019-12-17李素芳
李素芳, 张 虎, 吴 芳
(中南财经政法大学 统计与数学学院,湖北 武汉 430073)
0 引言
协整最初由著名的诺贝尔经济学奖获得者Engle和Granger[1]教授提出,主要用来描述经济系统里面两个或多个非平稳变量间的长期均衡关系。近年来,随着面板数据的不断发展和面板数据库的日益完善,多个时期数的面板数据与日俱增,时间序列协整问题不可避免地存在于多时期面板数据分析中。在面板数据框架下进一步发展的协整理论,即面板协整,是利用长面板数据的特征,从面板时间序列角度挖掘变量更多的数据信息,以便更有效地分析变量间的长期均衡关系。因此,利用面板协整方法可以有选择地混合关于协整参数的长期信息,同时允许各个截面之间的短期动态和固定效应不同。面板协整的主要优势在于,靠增加截面维数,融合截面和时间两个维度的数据信息以挖掘更多的数据信息量,从而提高协整检验和预测的准确性。
如果依据面板数据是否具有截面相关性来分,面板协整可以分为截面独立的面板协整和截面相关的面板协整。在截面个体单元独立条件下,Kao[2]借鉴传统时间序列协整中EG协整的思路,基于残差进行检验,得出面板数据框架下残差协整检验的渐近理论和模拟结果。Kao和Chiang[3]以及Pedroni[4,5]也提出了基于残差的原假设是没有协整关系的协整检验。进一步,Westerlund[6]提出面板数据CUSUM检验统计量,能够对异质性面板数据进行协整检验。而Larsson和Lyhagen[7]以及Larsson等[8]则研究了截面个体单元独立的条件下,基于似然的协整检验。在截面个体单元相关的条件下,O’Connell[9]最早提出截面个体单元相关条件下的单位根检验,他利用公共时间效应和广义最小二乘方法刻画截面相关,检验了购买力平价理论。之后,截面个体单元相关条件下的面板协整在近些年得到迅速发展。在截面相关条件下,Bai和Kao[10]采用因子模型对面板协整回归的估计进行了研究,提出了传统面板数据FMOLS估计的因子扩展。接着,Westerlund和Edgerton[11]在面板协整里运用Sieve自助法,考虑了具有更广泛形式的截面相关结构,从而提出了一种基于LM统计量的新面板协整检验。Chang和Nguyen[12]基于残差进行检验,进一步研究了综合考虑了截面相关、异质性和内生性的面板协整。
但是,这些面板协整检验统计量的渐近性质都是以个体单元数N和时期数T趋于无穷为前提的,而在实际经济社会应用中面板数据的个体单元数和时期数一般都有限,从而导致面板协整检验出现检验水平歪曲和检验势不稳定;同时,传统面板协整检验是在原假设成立的条件下进行的假设检验过程,它们基于原假设为存在协整或原假设为不存在协整来进行分析,因此,在原假设设置的时候存在主观选择问题,从而会影响协整判断的准确性。从贝叶斯角度进行面板协整分析能够避免以上几个方面的问题。首先,贝叶斯面板协整方法将原假设和备择假设同等对待,构造后验概率比来表示假设发生的可能性,从而得到更客观的协整检验结果,避免了传统面板协整中必须要以原假设为基础来进行假设检验的问题;同时,贝叶斯面板协整方法基于贝叶斯后验分布进行分析,其综合了模型参数和样本数据两方面的信息,能够进行更准确的协整检验和预测。
目前,贝叶斯面板协整模型的相关研究还相对较少,其中,Meligkotsidou等[13]考察了基于截面相关面板数据模型的贝叶斯单位根检验方法,进而分析了G7国家的国内生产总值数据;Koop等[14]对面板协整模型进行了贝叶斯推断。总体而言,面板协整的贝叶斯方法研究尚处于初始开发阶段,并且主要是基于条件均值模型进行协整检验,因此,面板协整建模过程易受到异常值的影响,不能充分全面挖掘数据中所包含的信息,只能分析变量均值间的长期关系,却难以全面地刻画变量间的长期均衡关系。本文利用动态公共因子刻画面板数据内部潜在的截面相依特征,结合贝叶斯分位回归方法和面板协整模型构建包含动态因子截面相依结构的贝叶斯分位面板协整模型,据此研究贝叶斯分位面板协整问题,克服了传统面板协整检验水平歪曲和检验势不稳定的问题,并且能够避免面板协整检验原假设设置的主观选择难题以及协整分析中潜在的异常值影响。通过Monte Carlo仿真实验分析贝叶斯分位面板协整的性质,测试了贝叶斯分位面板协整的有效性与可靠性;同时,利用结合卡尔曼滤波的Gibbs抽样算法对中国金融发展和经济增长变量进行贝叶斯分位面板协整分析,验证贝叶斯分位面板协整的有效性与可行性。
1 基于动态因子结构的截面相关面板协整模型
假设yit是I(1)变量,xit是m维I(1)向量,则有如下只包含个体截距项的面板协整回归模型:
yit=αi+βixit+μit
(1)
xit=xi,t-1+ηit
(2)
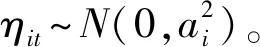
(3)
在此,ft=(f1t,f2t,…,fkt)′是k维不可观测的公共因子,λi是k×1因子载荷矩阵,eit为异质项,而且动态因子ft满足ft=φft-1+wt,wt~N(0,Σf)。 因此,考虑了截面相依特征的面板协整模型可以表示为如下包含动态因子结构的面板数据模型形式:
(4)
eit=ψiei,t-1+εit
(5)
xit=xi,t-1+ηit
(6)
ft=φft-1+wt
(7)
其中,误差项εit的τ分位数假定为0,其余参数定义同上。该模型的参数集简记为Ω,根据分位数回归的思想,将非对称加权绝对离差取最小化,从而得到分位面板协整模型的参数估计,即
(8)
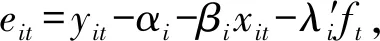
pAL(εit)=τ(1-τ)exp{-ρτ(εit)}
(9)
2 截面相关面板协整模型的贝叶斯分位推断
2.1 参数的贝叶斯分位推断
借鉴Kobayashi和Kozumi[17]的观点,利用如下非对称拉普拉斯分布的位置—尺度混合形式,以进行分位回归模型的贝叶斯推断:
(10)

(11)
(12)
xit=xi,t-1+ηit
(13)
ft=φft-1+wt
(14)
从而,模型的似然函数为
L(y,x|Ω)=p(y|x,Ω)p(x|Ω)
(15)
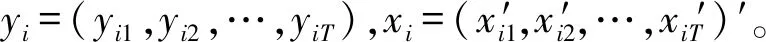
yit=αi+βixit+ψiyi,t-1+zvit-ψiαi-
(16)
xit=xi,t-1+ηit
(17)
ft=φft-1+wt
(18)
其中,因子ft是不可观测的潜变量。为了简化计算,便于利用状态空间模型的贝叶斯方法对其进行参数估计,将上述分位回归模型转换为如下线性状态空间模型形式:
(19)
ft=φft-1+wt
(20)

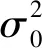
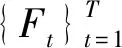
(21)
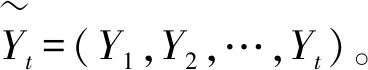
(22)
(23)
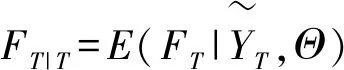
(24)
(25)
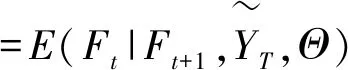
=E(Ft|Ft+1,Ft|t,Θ)
(26)
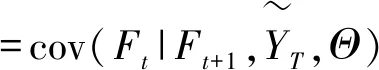
=cov(Ft|Ft+1,Ft|t,Θ)
(27)
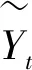
(2)参数空间Θ的条件后验密度。依照条件概率的定义,在观测值和估计因子已知的条件下,式(19)和(20)变成标准回归方程,因此,(19)和(20)分别确定了{αi,βi,ψi,λi,vit}和{φ,Σf}的条件后验分布,从而使得Θ的完全后验分布具有简单的标准形式。同时,由于误差项不存在相关性,故可以对方程(19)依次进行估计,以{αi,βi,ψi,λi,vit}获得的估计,从而αi的条件后验分布为
π(αi|y,Θ-α,Ft)=L(y|Θ,Ft)π(αi)
(28)
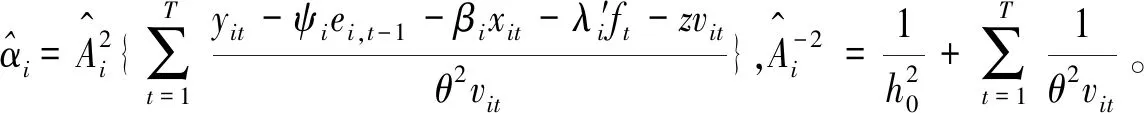
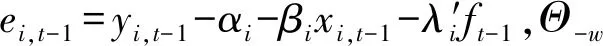
类似地,βi的完全条件后验分布为
π(βi|y,Θ-β,Ft)=L(y|Θ,Ft)π(βi)
(29)
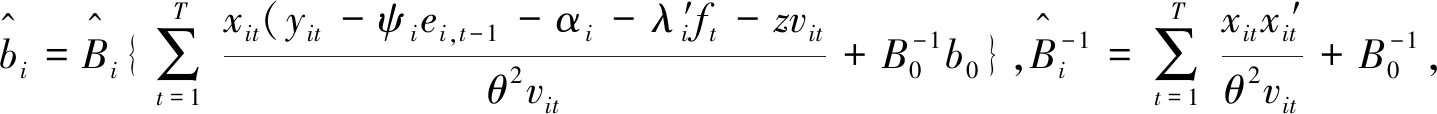
π(ψi|y,Θ-ψ,Ft)=L(y|Θ,Ft)π(ψi)
(30)
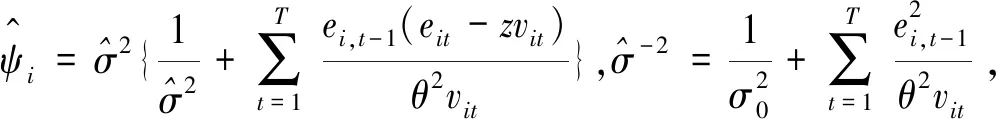
(31)
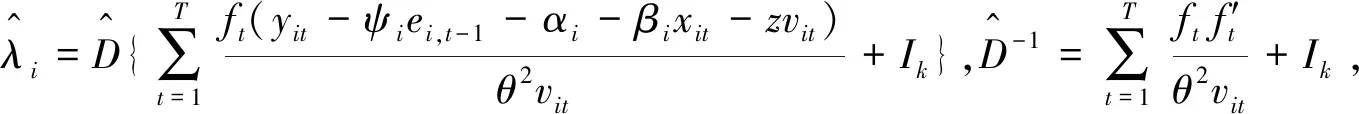
(32)
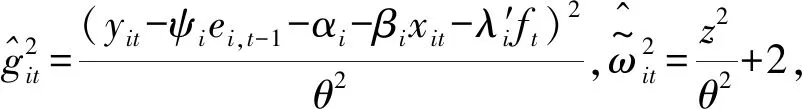
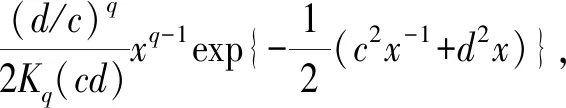
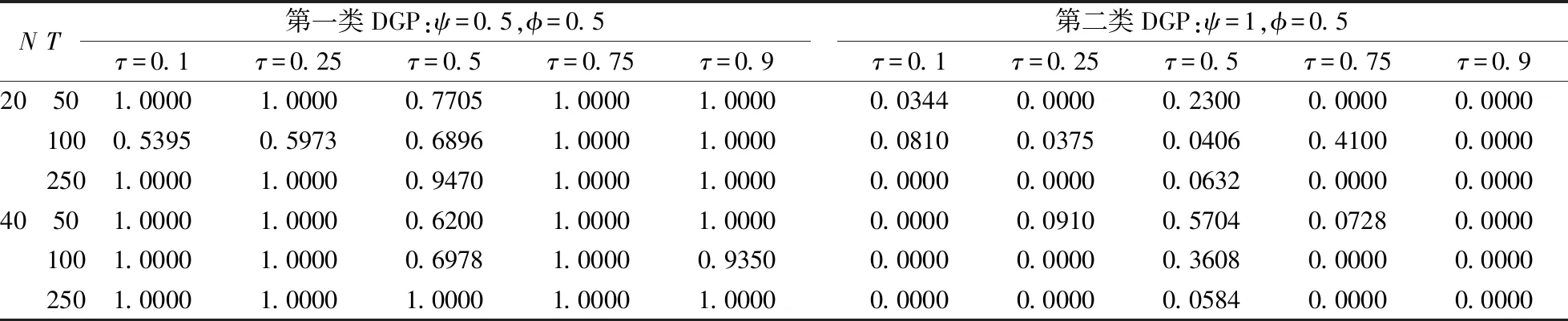
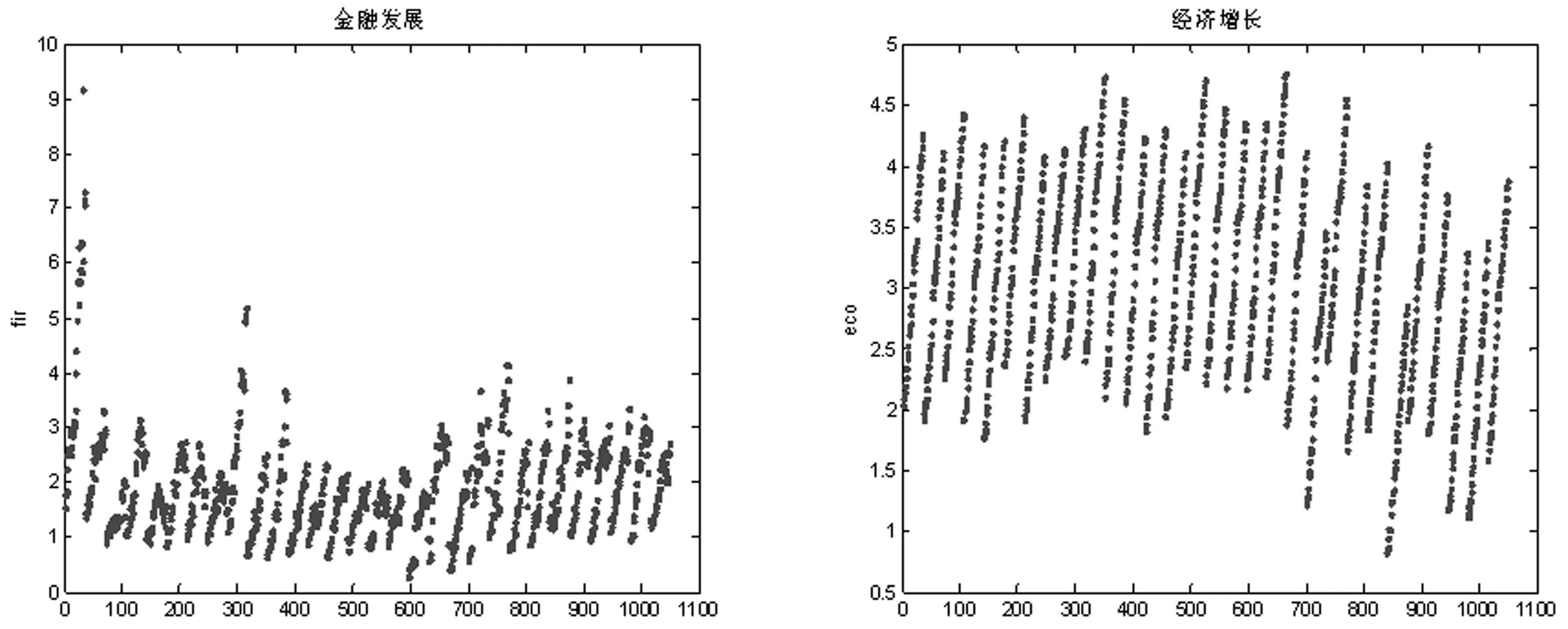
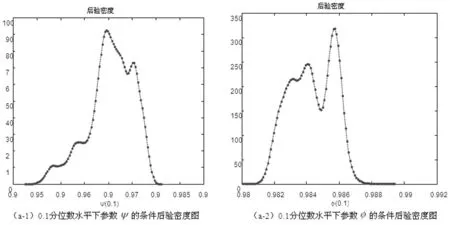
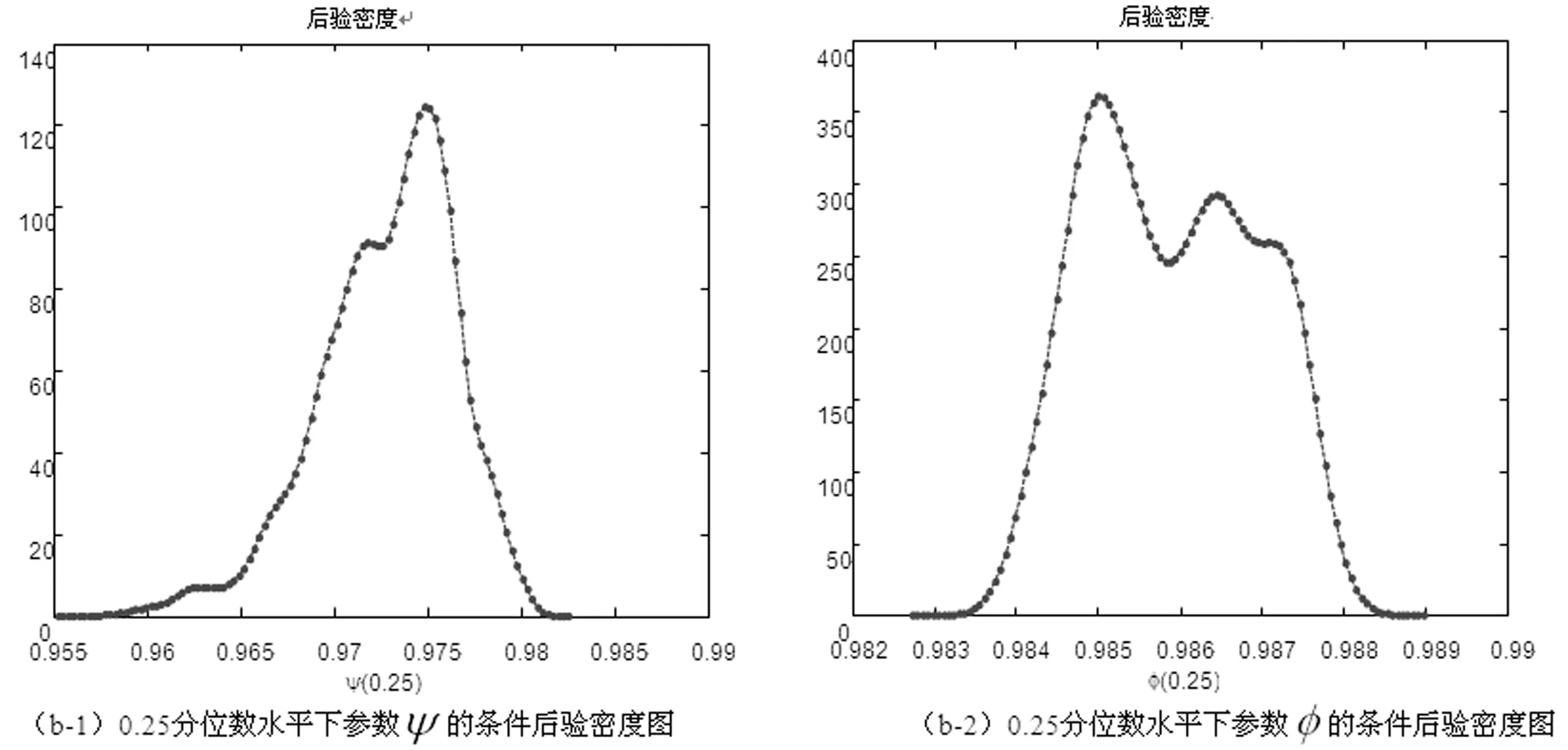
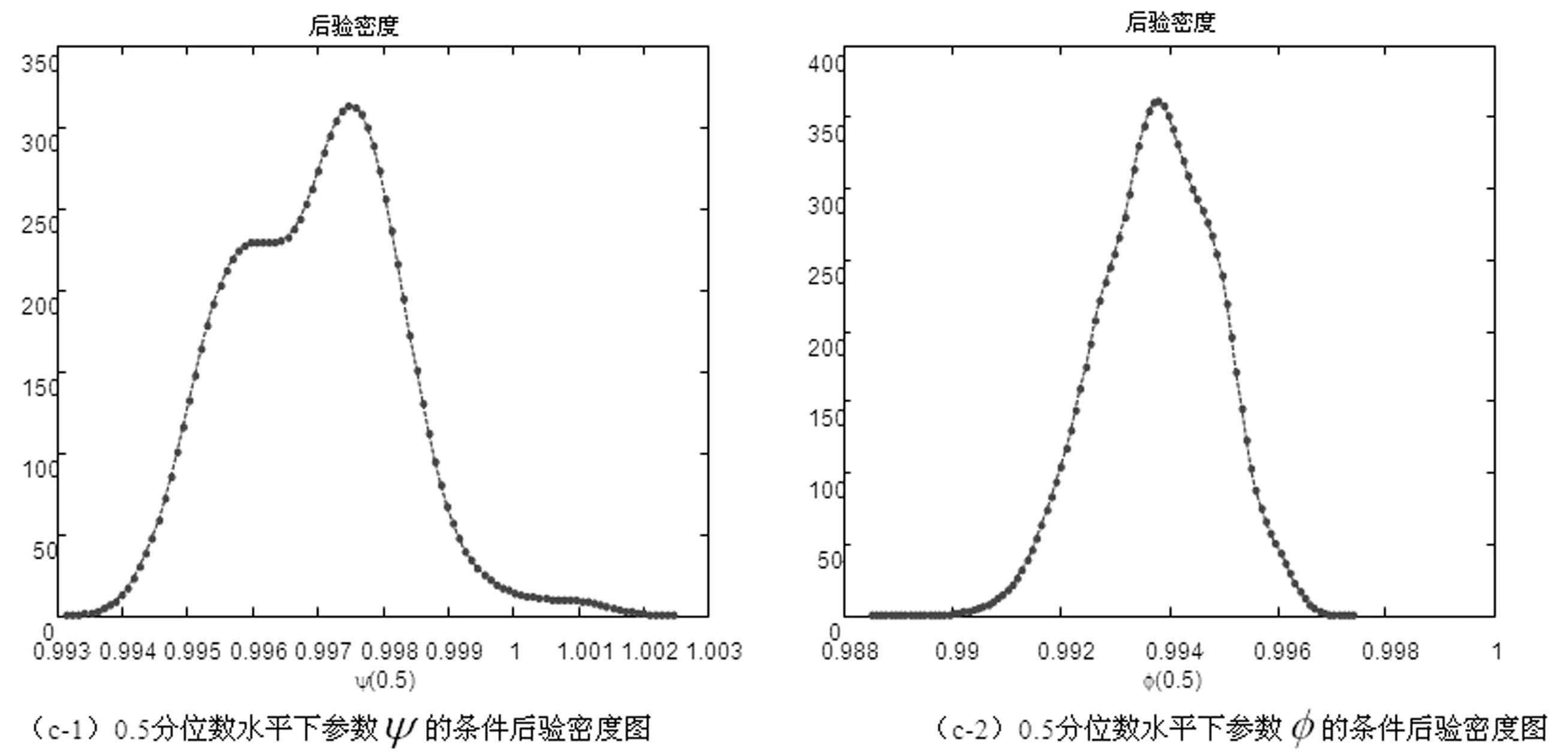
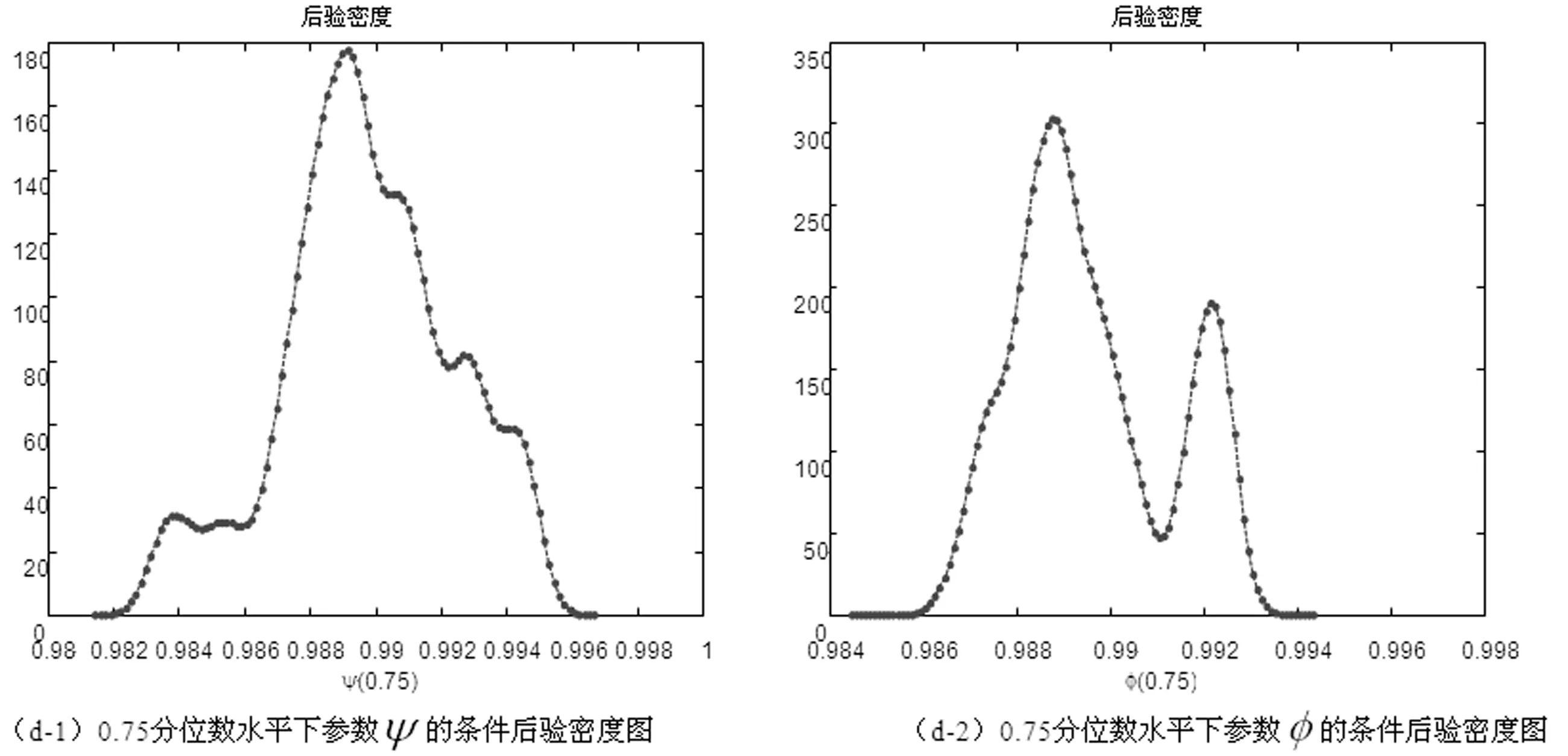
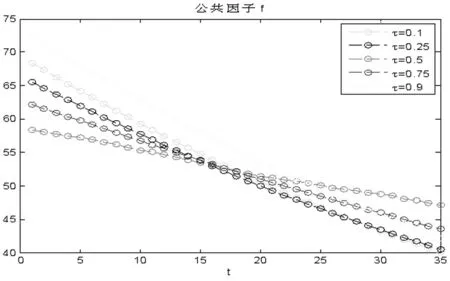
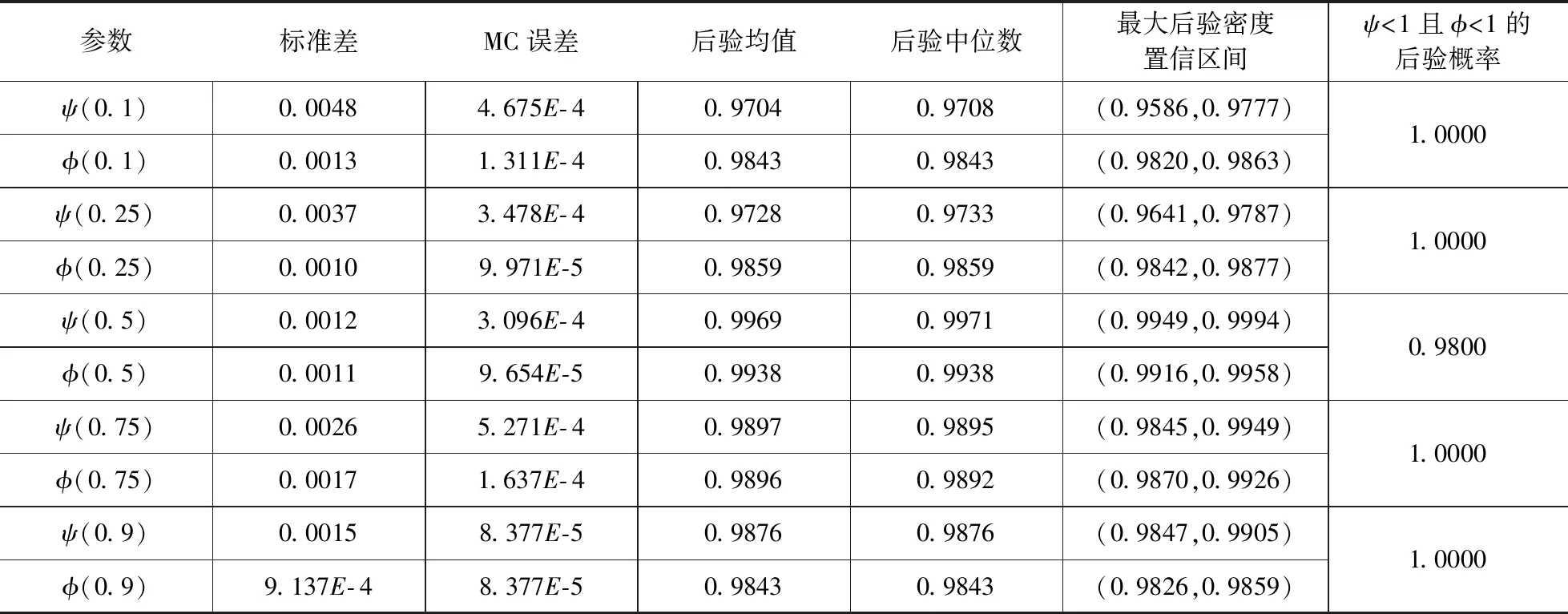
x>0,-∞ (33) 在此,Kq(·)是第三类修正的Bessel函数。 因此,形如式(20)的一阶向量自回归模型参数的条件后验分布为 (34) 在进行截面相依条件下的面板协整检验时,如果协整回归残差eit和公共因子ft都是平稳的,则认为变量yit和xit具有协整关系,即进行假设检验H0:ψi=1或φ=1↔H1:ψi<1且φ<1,其中,ψi<1且φ<1表示变量yit和xit之间具有协整关系。同样地,在分位协整回归模型中,第τ分位数水平下的协整假设为H1:ψi(τ)<1且φ(τ)<1,若ψi(τ)<1且φ(τ)<1,则表明在第τ分位数水平下变量yit与xit具有协整关系,反之表明在第τ分位数水平下变量之间不存在协整关系。相对而言,运用分位协整检验进行协整分析将更符合现实背景,例如,在中位数水平下的协整关系意味着大多数个体存在变量间的协整或者较少个体的变量间具有强协整关系,因此,在分位数水平下进行协整检验能够更好的反应检验目的。 在贝叶斯框架下进行模型选择或假设检验时,一般通过计算贝叶斯因子来实现。贝叶斯因子的计算通常较为复杂,往往需要利用边缘似然函数来进行贝叶斯因子的计算。此处,令协整检验的贝叶斯因子为B10=P(H1|Data)/P(H0|Data),可以利用MCMC算法得到模型参数的后验分布抽样,运用这些抽样样本估计出参数,进而可以利用这些抽样计算出贝叶斯因子及假设相对应的后验概率。 依照分位面板协整模型中参数的条件后验分布和遍历性定理,对协整模型的参数进行估计的MCMC算法首先用卡尔曼滤波估计出不可观测的因子{Fi},继而用Gibbs抽样算法依次估计(αi,βi,ψi,λi,vit)和(φ,Σf),具体步骤如下: 步骤1初始化(αi,βi,ψi,λi,φ,vit,Σf),{Fi}。 步骤4从π(αi,βi,ψi,λi,vit|y,Ft)抽样参数(αi,βi,ψi,λi,vit): (i)从π(αi|y,Fi,Θ-α)抽样{αi},i=1,2,…,N。 (ii)从π(βi|y,Fi,Θ-β)抽样{βi},i=1,2,…,N。 (iii)从π(ψi|y,Fi,Θ-ψ)抽样{ψi},i=1,2,…,N。 (iv)从π(λi|y,Fi,Θ-λ)抽样{λi},i=1,2,…,N。 (v)从π(vit|y,Fi,Θ-v)抽样{vit},i=1,2,…,N,t=1,2,…,T。 步骤5首先从π(Σf|Ft)抽样Σf,继而在抽样Σf的条件下,从π(φ|Σf,Ft)抽样φ。 为了考察面板数据序列的贝叶斯分位面板协整检验的性质,利用Monte Carlo仿真实验进行分析。首先,基于如下数据生成过程(DGP)产生序列y和x: ft=φft-1+wt,Δxit=ηit (35) 其中,{εit,ηit,wt}∀t=1,2,…,N,t=1,2,…,T由独立同分布的标准正态分布生成,λi则由λi~N(1,1)生成,取时期数为T={50,100,250},个体数为N={20,40},α=0.2,β=1,公共因子个数为k=1,φ=0.5,ψ={0.5,1};此处,记ψ=0.5时的数据生成过程为第一类DGP,记ψ=1时的数据生成过程为第二类DGP。 接着,利用上述生成数据,基于含有动态因子的截面相关面板协整模型,进行贝叶斯分位参数估计,从而进行贝叶斯分位面板协整检验。表1列出了ψ<1且φ<1的后验概率,即为变量间具有协整关系时的后验概率。 表1 贝叶斯分位面板协整检验的后验概率 从表中结果可知,当ψ=0.5,φ=0.5时,即在截面相关假设下两个变量之间具有协整关系,特别地,在小样本时,贝叶斯协整检验方法在0.1,0.25,0.5,0.75以及0.9这5个主要分位数水平下的协整后验概率基本为1,例如,N=20,T=50和N=40,T=50时,在中位数水平下变量间具有协整关系的后验概率分别为0.7705和0.6200,而在其余分位数水平下变量间具有协整关系的后验概率均为1;而在样本相对较大的情况时,中位数水平下具有协整关系的后验概率均大于0.6,表明大多数个体的变量之间具有协整关系的后验概率0.6。当ψ=1,φ=0.5,时,即是用平稳的公共因子刻画截面相关性且变量之间不存在协整的情况,此时,在N=40,T=50时,在低分位数水平和高分位数水平下变量间具有协整关系的后验概率均小于0.5;而对于其它样本,在5个主要分位数水平下变量间具有协整关系的后验概率均小于50%,并且,当时期数T相对个体单元数N更大时,更多分位数水平下不存在协整关系,这也表明时期数更多的情况下协整检验判断的准确性更高,例如,在N=20,T=250时,在低分位数水平和高分位数水平下,变量间具有协整关系的后验概率均为0,从而可以认为极端水平下拒绝协整关系的后验概率为100%。综合而言,贝叶斯分位面板协整给出了更为全面的协整检验判断,能够避免异常数据点的影响,使得检验更为有效可靠。 下面利用贝叶斯分位面板协整检验方法考察1978~2012年中国除香港、澳门和台湾外的各省(直辖市)金融发展和经济增长的均衡关系。为了保持数据的一致性,将重庆市1997年以后的数据纳入四川省进行计算。数据来源于《中国统计年鉴》和国泰安数据库。在已有研究金融发展与经济增长关系的文献中,经济增长变量大多采用真实GDP或者其对数值,本研究将采用真实GDP的对数值代表经济增长。同时,采用各地区金融机构年末存贷款余额占GDP的比重来计算金融发展,经济增长和金融发展分别记为ecoit,firit,i=1,2,…,30,t=1,2,…,35。金融发展与经济增长变量序列的散点图如图1所示,同时,表2列出了金融发展和经济增长两个变量序列的基本统计特征。 图1 金融发展与经济增长序列散点图 由图中可以看出,变量数据存在明显的异常值,其中,金融发展变量数据尤为突出;并且,从表1中结果可以发现,金融发展和经济增长变量的标准差都接近1,标准差偏大,体现出数据的异质性特点;而金融发展的偏度系数大于0,经济增长的偏度系数小于0,说明经济增长变量具有右尾分布,金融发展变量具有左尾分布;另一方面,经济增长的峰度系数小于正态分布峰度系数值3,金融发展的峰度系数显著大于3,说明金融发展序列具有尖峰厚尾特征,而经济增长则不具有尖峰厚尾的特征;J-B(Jarque-Bera)正态性检验的结果则表明金融发展和经济增长变量数据均不服从正态分布。因此,贝叶斯分位协整方法进行其协整关系的考察有利于得出更加稳健的结果。 表2 金融发展与经济增长序列统计特征表 注:***表示在1%显著水平上拒绝正态分布的原假设。 为了检验面板数据序列的平稳性,首先对金融发展和经济增长变量分别进行面板单位根检验。在此,考虑用面板数据LLC检验、IPS检验以及Hadri检验进行面板数据的平稳性检验,结果如表3所示。从表3中LLC检验和IPS检验可知,金融发展fir和经济增长eco原始序列没有拒绝单位根原假设,而其一阶差分序列均拒绝了单位根原假设;同时,Hadri Z检验的结果表明,金融发展fir和经济增长eco在1%显著性水平下拒绝了变量序列是平稳的原假设,而其相应的差分序列却不能拒绝平稳的原假设。因此,可以综合判断变量金融发展fir和经济增长eco均为一阶单整序列。 注:*,**,***分别表示在10%、5%、1%显著水平下拒绝原假设。Hadri Z单位根检验的原假设为序列是平稳的。 进一步,需要运用协整分析来考察金融发展与经济增长之间的长期均衡关系,为了更全面有效地考察金融发展和经济增长的均衡关系,得出更加稳健的结论,下面对金融发展与经济增长面板数据序列进行贝叶斯分位面板协整研究。特别地,考虑到全国各省(直辖市)之间的区域关联性,利用公共因子刻画各省之间的相依特征,建立如下包含动态公共因子的面板协整模型: (36) eit=ψei,t-1+εit (37) ecoit=ecoi,t-1+ηit (38) ft=φft-1+wt (39) 首先设计贝叶斯MCMC算法以估计上述面板协整模型的参数,获得模型参数的贝叶斯分位估计。在MCMC抽样过程中,总共迭代15000次,为了消除初始值的影响,保证参数的收敛性,先进行10000次迭代,发现马尔可夫链达到稳定,然后通过退火舍弃掉这些迭代样本,再进行5000次迭代,然后用后面这5000次的迭代样本来估计分位协整模型的参数。根据各主要分位数水平下模型参数的轨迹图可以看出,参数的轨迹重合得很好,没有呈现明显的周期和规律,并且,退火舍弃掉前面10000次迭代后生成的Monte Carlo抽样都在稳定的平行区域内,同时,随着迭代次数增加,GR统计量趋于1,这些特征说明该Gibbs抽样具有较快的收敛速度,且收敛性很好。因此,结合了卡尔曼滤波的Gibbs抽样算法生成的抽样准确收敛到平稳的目标分布,利用后面5000次迭代样本可以得到准确的模型参数估计。因为篇幅有限,本文不一一列出模型各参数的动态轨迹图,GR统计量收敛诊断图和自相关图,只给出各主要分位数水平下参数ψ和φ的条件后验密度图,以及公共因子f的后验估计图。图2(a)~(e)给出了参数ψ和φ在各主要分位数水平下的条件后验密度图,图3则给出了公共因子f的后验估计图。 图2 贝叶斯分位面板协整模型参数ψ和φ的条件后验密度图 从图2(a)~(e)可以看出,参数ψ在低分位数水平τ=0.1,τ=0.25以及高分位数水平τ=0.75,τ=0.9下的后验估计基本在0.97左右,1不在最大后验密度置信区间(Highest Posterior Density Confidence Intervals,简称HPDI)内,而在中位数水平下ψ的条件后验密度图虽然覆盖了1,但是1却是在其条件后验密度的尾部,从而对贝叶斯分位面板协整检验的判断影响较小。而参数φ在中位数水平下的后验估计大概为0.994,在低分位数水平τ=0.1,τ=0.25和高分位数水平τ=0.75,τ=0.9下的后验估计也基本都在0.985左右,并且,参数φ在各主要分位数水平τ=0.1,τ=0.25,τ=0.5,τ=0.75以及τ=0.9下的后验密度图均没有覆盖1,从而可以直观地判断出参数φ<1。 同时,在图3中,各个主要分位数τ=0.1,τ=0.25,τ=0.5,τ=0.75以及τ=0.9水平下的公共因子f刻画了面板数据在各个主要分位数水平下的截面相关特征。在τ=0.1,τ=0.25,τ=0.5,τ=0.75以及τ=0.9分位数水平下公共因子序列ft都基本呈直线形式,并具有明显递减的时间趋势,从而可以认为公共因子序列ft是一个平稳过程,也再次验证了参数φ<1的判断。综合分析各主要分位数水平下面板协整模型参数的动态轨迹图以及条件后验密度图可知:面板协整模型参数的贝叶斯分位估计是合理且有效的。 图3 贝叶斯分位面板协整模型公共因子f的后验估计图 进一步,利用结合卡尔曼滤波的Gibbs抽样算法生成的抽样序列可以算出模型参数的后验估计值和相应的最大后验密度置信区间HPDI,表4列出了主要分位数水平下的贝叶斯分位面板协整检验结果,其中ψ<1且φ<1的后验概率即为变量间具有协整关系的后验概率。 表4 金融发展与经济增长序列的贝叶斯分位面板协整结果 由表4可以看出,各个分位数水平下参数ψ和φ的后验抽样的Monte Carlo误差都比较小,且明显小于标准差,这表明结合了卡尔曼滤波的Gibbs抽样算法具有很好的收敛性和有效性,从而保证了后验估计的准确。后验估计的结果表明,参数在各个分位数水平下的后验估计具有局部持续性;并且,模型参数ψ和φ均不等于1,其相应的后验置信区间都不包含1,说明在0.1,0.25,0.5,0.75以及0.9分位数水平下金融发展与经济增长之间可能存在协整关系,进而从后验概率可以判断,在0.5分位数水平下存在协整的后验概率为0.98,而在其它分位数水平下存在协整的后验概率均为1。因此,可以认为金融发展与经济增长之间存在协整关系,即中国金融发展与经济增长之间存在长期均衡关系。 对金融发展和经济增长面板数据序列进行Fisher面板协整检验的结果如表5所示,由表中结果可知,当原假设为r=0,备择假设为r=1时,迹检验统计量和最大特征值检验统计量的P值都小于显著性水平1%,而当原假设为r=1,备择假设为r=2时,迹检验和最大特征值检验在10%显著性水平下不能拒绝原假设,但是在5%显著性水平下能够拒绝原假设,由此可见,这类临界值附近的检验统计量值使得我们的协整检验判断较为困难,而这种类似情况在三个及三个以上变量间的协整关系判断中更加困难,所以,此时需要提供更多的证据来进行相应的判断。由于贝叶斯分位面板协整方法可以避免传统面板协整检验中由于原假设设置不同而存在的判断偏误等问题[15],能够克服异常值以及异质性的影响[18],从而得出更为稳健的协整判断。因此,结合贝叶斯分位面板协整检验方法的结果和传统面板协整方法的结果综合判断,认为中国金融发展和经济增长之间具有协整关系。综上,协整检验的结果表明中国金融发展和经济增长之间存在长期均衡关系, 这也再次证实中国金融发展与经济增长之间存在强相关关系。 表5 金融发展与经济增长序列的Fisher面板协整检验结果 注:表中*,***表示在10%,1%显著性水平下拒绝原假设。 本文利用公共因子刻画面板数据个体之间的截面相关特征,构建包含动态因子以考虑截面相关结构的面板协整模型,并对模型参数进行贝叶斯分位推断,进而提出了基于动态因子截面相关结构的贝叶斯分位面板协整检验方法。然后,通过Monte Carlo仿真实验考察了贝叶斯分位面板协整检验的可行性与有效性,发现贝叶斯分位面板协整方法具有较好的性质。同时,对中国各省(直辖市)的金融发展和经济增长面板数据进行实证研究,建立带动态公共因子的面板协整模型,采用贝叶斯分位回归技术对其进行参数估计,设计结合了卡尔曼滤波的Gibbs抽样算法对面板数据时间序列进行贝叶斯分位面板协整检验。结果发现在0.1,0.25,0.5,0.75以及0.9分位数水平下中国金融发展与经济增长之间具有协整关系,表明中国金融发展与经济增长之间具有长期均衡关系,证实了中国金融发展与经济增长之间存在强相关关系;并且,贝叶斯分位面板协整检验方法给出了各个主要分位数水平下的协整结果,从而能够避免异常数据点的影响,提供了更为全面可靠的协整检验信息,这也再次验证了贝叶斯分位面板协整方法的可行性和有效性。因此,在进行面板数据序列协整分析时,贝叶斯分位面板协整检验能够避免传统协整检验方法中由于原假设设置不同而导致的协整判断发生偏误的难题,克服了异常值的潜在影响,从而可以进行更为具体准确的协整参数估计和协整检验判断,为均衡关系判断和协整预测分析提供更全面的视角。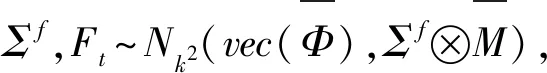
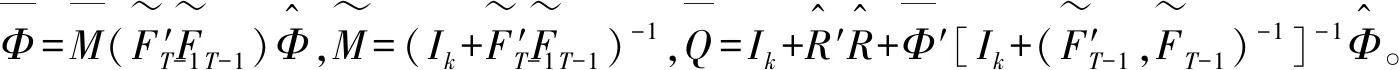
2.2 贝叶斯分位面板协整检验
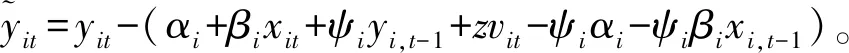
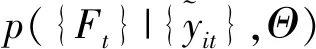
3 协整检验的Monte Carlo仿真实验分析
4 实证分析



5 结论
