基于注意力胶囊网络的家庭活动识别
2019-12-12王金甲纪绍男崔琳夏静杨倩
王金甲 纪绍男 崔琳 夏静 杨倩
全球正在面临人口老龄化的问题,预计到2050 年,64 岁及以上的人口将超过世界人口的20%.据调查显示,有40%的老年人将独自居住在自己家中[1].这将导致许多社会问题,例如疾病和卫生保健费用的增加、护理人员的短缺以及无法独立生活的人数增加.因此,开发环境智能辅助生活工具帮助老年人独立在家中生活是势在必行的[2].基于音频的家庭活动识别是一个新问题,也是声音事件分类的一个新兴应用领域.声音事件分类将语义标签与音频流相关联,并识别产生它的事件.用于家庭活动识别的声音事件分类系统能够预测对应的活动事件.声音事件分类问题在基于人工智能(Artificial intelligence,AI)的机器人导航、智能驾驶、监测家庭活动及老年人生活等方面有重要应用[3].
传统的声音事件分类方法是从音频信号中提取预先设计的人工特征用于训练分类器[4].这种方法在很大程度上依赖于预先设计特征的能力,而这需要大量信号处理方面的专业知识.事实上,鉴于现实生活中遇到的问题和特殊情况的高度多样性,这种方法在许多问题中既没有效率也没有可持续性[5].
基于深度学习的声音事件分类方法采用端到端的深度神经网络实现自动特征提取和分类.近年来,基于卷积神经网络(CNN)和循环神经网络(RNN)等深度学习方法在声音事件分类方面显示出良好的性能,并且卷积循环神经网络(CRNN)结合了CNN 和RNN 也已经获得了较先进的声音事件分类性能.例如,Hershey 等通过将不同结构的CNN 用于音频分类任务中,发现以前应用于图像分类的CNN 在音频分类任务中也表现良好,并且更大的训练和标签集有助于达到更好的分类效果[6].Parascandolo 等提出了一种基于双向长短时记忆(Bi-LSTM)循环神经网络用于复音声音事件检测,并在来自不同日常环境的不同类别的音频样本上进行测试,显示出了很好的效果[7].Cakir 等提出了将卷积循环神经网络应用到复音声音事件检测任务中,结果显示CRNN 方法优于先前只用CNN 和RNN 的方法[8].徐勇等在DCASE 2016 任务4 弱监督音频标记问题中,在卷积循环神经网络上加入注意力和定位方案[9];在DCASE 2017 任务4 弱监督声音事件检测问题中提出了门控卷积循环神经网络模型,其中可学习的门控线性单元可以帮助选择对应于最终标签的最相关特征,获得竞赛第一名的成绩[10].
DCASE 2018 挑战任务5 是用于家庭环境中日常活动识别问题的多声道声音事件分类任务,该任务的目标是将由麦克风阵列获取的多声道音频段分类为所提供的预定义类之一,这些类是在家庭环境中进行的日常活动(例如“ 烹饪”).这个任务的重点在于可以利用多声道音频系统来识别家庭活动,多麦克风信号处理技术可以有效地提高音频分类的鲁棒性[11],由于多个声音事件的并发性,多声道音频分类是一项具有挑战性的任务.该任务的基线系统使用了两个卷积层和一个全连接层的结构[12].Kong 等使用了AlexNetish和VGGish 的卷积神经网络,更深网络层的VGGish 模型有更好的性能,这说明VGG 模型不仅能够在大规模图像数据集上分类效果很好,在音频数据集上的推广能力也非常出色[13].在此竞赛中并列第一名的两个团队是Tanabe 团队和Inoue 团队.Tanabe 等所提出的系统是基于盲信号处理的前端模块和基于机器学习的后端模块的组合方法.为了避免过拟合,前端模块采用盲去混响,盲源分离等,它们使用空间线索而无需机器学习.后端模块采用基于一维卷积神经网络(1DCNN)的架构和基于VGG16 的架构.所有的网络概率输出进行集成[14].Inoue 等提出了数据增强的前端模块和基于CNN 分类方法的后端模块的组合方法.首先,它通过混洗和混合声音片段来增强输入数据,这种数据增强方法有助于增加训练样本的变化,并减少不平衡数据集的影响.其次,使用CNN 深度学习模型作为分类器,CNN 模型输入是增强后数据的对数Mel 语谱图[15].
总的来说,CNN 是将局部特征提取进行处理,RNN 是对局部特征之间的时间依赖性进行建模,尽管它们在很多方面取得了成功,但是由于CNN 网络对各个部件的朝向和空间上的相对关系并不敏感,它只在乎有没有相应的特征,所以CNN 不能很好地反映部分和整体的关系.加之各个特征的重叠性,现有的深层学习技术仍然不足以将单个声音事件从它们的混合物中分离出来,所以取得的效果并不是很理想.而且CNN 和RNN 都不能很好地减少过拟合.胶囊网络是Hinton 在2017 年提出的,胶囊是一组神经元,其表示特定类型的对象或对象部分的实例化参数[16].胶囊网络的一个主要优点是它提供了一种类似于人类感知系统的方法,可以很简单地通过识别其部分来识别整体.对于DCASE 2018 任务5,我们使用胶囊路由机制的神经网络架构来完成.
在该网络中,胶囊层为每个声音事件选择代表性的频带,低级胶囊通过权值矩阵对高级胶囊所代表的事件类别进行预测,如果该预测向量与高级胶囊层中某个胶囊的输出有较大点积值,则通过反馈来增加胶囊与该高级胶囊的耦合系数,并降低与其他胶囊的耦合系数从而可以准确地反映部分和整体的关系.与最大池化实现的原始路由形式相比,胶囊路由可以避免忽视除最显著特征之外的其他特征,可有效地减少特征损失[16].另一个创新是在胶囊网络中的初级胶囊层后加入了注意力层,它可以通过加权来提高对显著部分的关注度,即可以自动选择音频事件类最相关的重要帧,同时忽略不相关帧(例如,背景噪声段).我们提出的注意力层通过对时间片的显著性选择实现了注意力机制,从而减少了模型过拟合.
1 注意力胶囊网络模型
1.1 胶囊网络的动态路由
胶囊网络和标准神经网络的重要区别在于胶囊的激活是基于多个输入姿态预测之间的比较,而在标准神经网络中,它是基于单个输入活动向量和学习到的权重矢量之间的比较.解决部分和整体关系问题的一种方法是找到高维投票的紧密聚类,这个方法称为路由协议.不同于CNN 的输入输出形式,也不同于CNN 的池化操作,胶囊层的输入输出均为向量形式,并且采用了动态路由算法,来对这些向量进行运算.
胶囊网络每一层有若干节点,每个节点表示一个胶囊.低级胶囊连接到更高级别胶囊的过程中,连接权值会在学习中发生变化,由此引起节点连接程度的变化,因此称为动态路由.通常,在两层胶囊之间用动态路由算法对该网络进行训练.以下是我们描述的动态路由算法[16].
算法1.动态路由算法
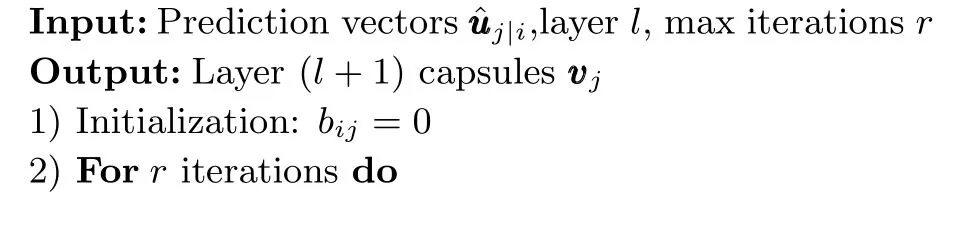
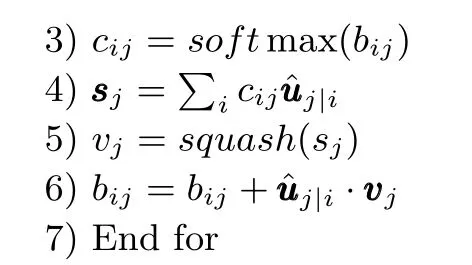
胶囊路由的概念图如图1 所示,圆圈为单个神经元,虚线圈出的为一个胶囊.胶囊可以代表实体,左侧L层两个胶囊分别表示人的左右胳膊,从实线箭头可以看出正确朝向的左胳膊对应右侧(L+1)层胶囊的人体上半身构造,而虚线箭头表示不能对应.两个胶囊层之间通过识别局部的器官,学习到局部和整体的关系,然后找到正确的人体上半身结构.
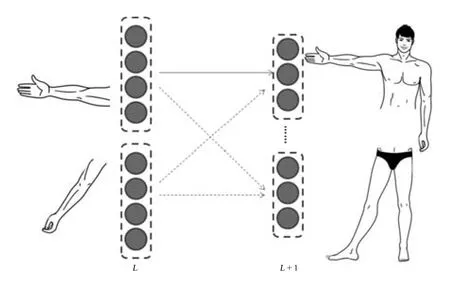
图1 胶囊路由的概念图Fig.1 Conceptual diagram of capsule routing
1.2 注意力机制
注意力机制可以从大量信息中选择出对当前任务目标更关键的信息,并抑制不相关的信息,从而减少了过拟合问题.图像处理中的注意力机制关注空间注意力,我们提出的方法关注时间注意力.注意力模块用sigmoid 作为激活函数,能在选择重要特征的同时抑制不相关的信息[9].它也可以帮助平滑训练集和测试集之间不匹配的问题.第t帧的注意力因子z(t)表示当前音频帧对音频类的重要程度.z(t)的输出值为0 到1 之间.当z(t)接近1 时,对应t时刻帧作为重要帧被选择,当z(t)接近0 时,对应t时刻帧作为不相关帧被忽略.通过这种方法,网络可以关注音频片段中的音频类事件帧,忽略噪声帧.z(t)定义为:
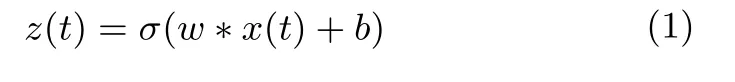
其中,x(t)为输入特征,w为权重矩阵,b为偏置参数,σ是sigmoid 非线性激活函数.通过训练网络来更新参数w和b.
1.3 提出的网络模型
本节提出了注意力胶囊网络模型来进行家庭活动识别.网络模型如图2 所示,首先将音频片段转变成对数Mel 语谱图,其次将对数Mel 语谱图输入到提出的注意力胶囊神经网络模型,最后模型输出是音频标签预测值.
提出的注意力胶囊网络模型由三个门控卷积模块,一个初级胶囊层,一个高级胶囊层,一个注意力层和一个融合层组成.每个门控卷积模块由两层门控卷积网络和最大池化组成,每层门控卷积网络包括线性(linear)函数和sigmoid 激活函数.与传统的CNN 相比,门控卷积网络用门控线性单元(GLUs)取代了修正线性单元(ReLU).这个可学习的门能控制当前层传入下一层的信息量[10].GLUs 能减少梯度消失现象[17],这是通过用sigmoid 激活函数保留了神经网络的非线性能力,同时用线性(linear)函数为梯度提供线性路径来实现的.最大池化操作能减少特征的空间维度.
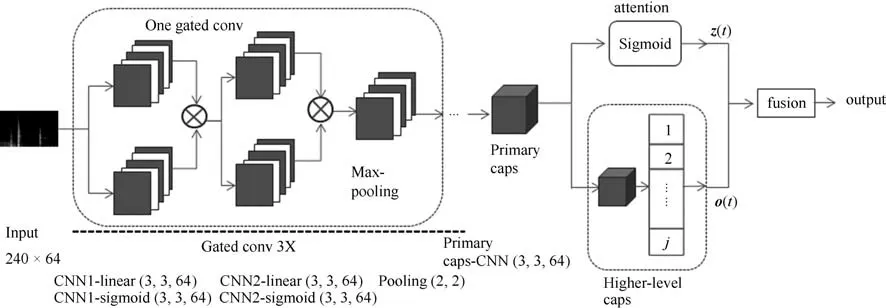
图2 注意力胶囊网络模型Fig.2 Attention capsule network model
经过三个门控卷积模块的输出特征被送入初级胶囊层.初级胶囊层由卷积模块,重塑模块和squashing 模块组成.输入特征先经过卷积层,加入偏差之后,又经过ReLU 非线性激活函数,然后重塑为一个T×V×U的三维张量,并用squashing 函数压缩.T是重塑前的时间维度,V是从其他变量推测出的维度,U4 是胶囊的大小.也就是说初级胶囊层的输出有T个时间片,每个时间片有V个胶囊,每个胶囊是1 ×1 ×U的张量.
将每个时间片的V个胶囊输入高级胶囊层.在初级胶囊层和高级胶囊层之间使用动态路由算法进行计算.动态路由算法将V个代表音频帧的低级胶囊与J个代表事件类别的高级胶囊进行匹配.当多个音频帧都预测到同一事件后,则确定出音频事件的类别.然后通过反馈来增加与该音频事件相关音频帧之间的权重,并降低与该音频事件不相关音频帧的权重,从而准确地学习到所有音频帧和音频事件之间的权重.每一次训练,路由算法的权重都会更新,算法结束时保存最终权重.用动态路由算法计算输出向量vvvj,再算出输出向量vvvj的欧氏长度.每个时刻t的所有J个类别的欧氏长度组成向量作为高级胶囊层的输出,记为ooo(t).
将每个时间片的V个胶囊输入注意力层.注意力层可以让网络模型更专注地找出与音频事件类相关的输入音频的显著帧.该层的sigmoid 激活函数能够预测出每帧的重要性,每个时刻t的注意力层输出为zzz(t),zzz(t)的值在0 到1 之间.注意力层在抑制音频事件类不相关帧的同时选择显著帧.时间注意力机制就是通过注意力层的输出来实现的.
最后是融合层,将高级胶囊层的输出ooo(t)与注意力层的输出zzz(t)合并.对时间片的显著帧选择实现时间注意力机制,注意力因子大的时间片对应着类相关显著音频帧,注意力因子小的时间片对应着类不相关的音频帧.通过计算高级胶囊层的输出ooo(t)和注意力因子zzz(t)的加权和得到最终的预测输出yj.yj表示第j类音频类事件的预测值,表达式如下:
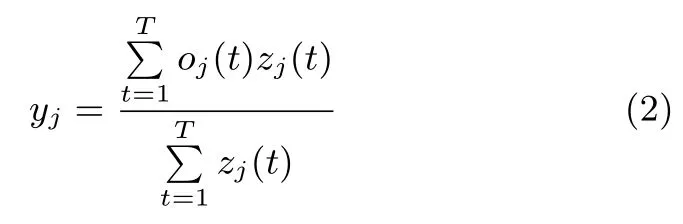
其中,oj(t)表示时刻t的第j个胶囊输出向量vvvj的欧氏长度,zj(t)表示时刻t的第j类注意力因子,j1,···,J,t1,···,T.zzz(t)控制了ooo(t)传送信息中的显著音频帧.选择一个概率阈值τ,当yj >τ时,输出是第j类音频活动事件.
2 实验
2.1 数据集
此次任务使用的是DCASE 2018 任务5 数据集,它是SINS 数据集的派生数据[18].对于这项任务,在起居室和厨房混合区域使用了7 个麦克风阵列组成网络收集音频,每个麦克风阵列由4 个线性排列的麦克风组成.图3 显示了声音录制环境的平面图以及使用的传感器节点的位置.
此数据集包含一个人一周住在度假屋中的连续录音,这个连续录音被分成10 s 的音频段,包含多于一个活动类(例如两个活动间的转换)的音频段被忽略了,这意味着每个音频段仅代表一个活动.这些音频段和对应的类别标签作为单独的文件被提供.每个音频段包含4 个声道(例如来自特定节点的4 个麦克风声道).这个9 类任务的日常活动如表1所示,表1 中还包括开发集和评估集中每类活动的10 s 片段的数量.
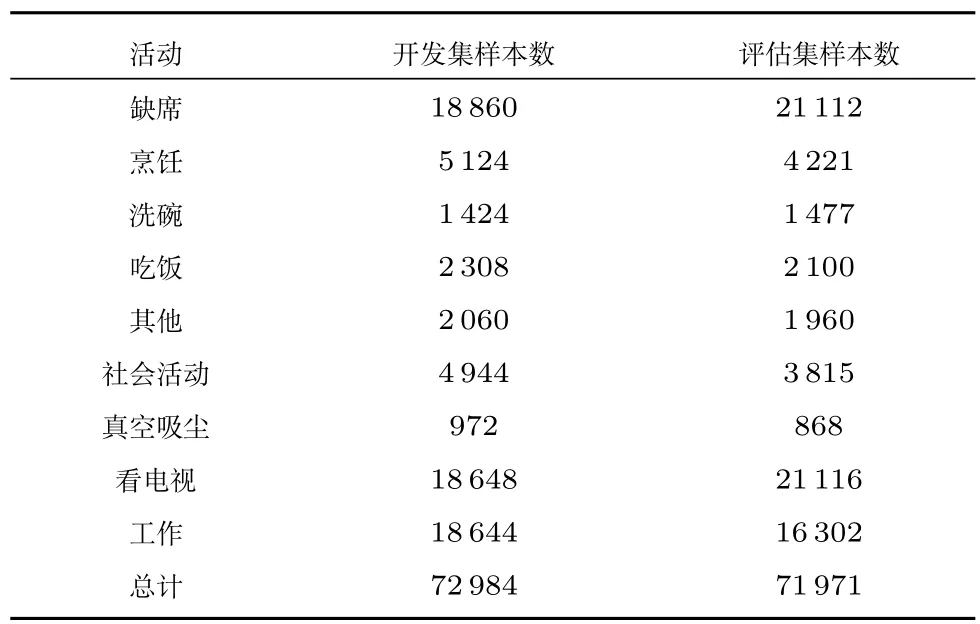
表1 开发集和评估集音频数量Table 1 Development set and evaluation set audio quantity
2.2 特征提取
我们此次实验采用的特征提取方法是目前音频处理最常用的对数Mel滤波[19−20].在提取特征之前,我们将每个剪辑的音频以16 kHz 重新采样,然后进行短时傅里叶变换得到语谱图;其次我们生成一个64 频带的Mel 滤波器组;将语谱图和Mel 滤波器组相乘,并进行对数运算,得到对数Mel 语谱图.即每个10 s 音频样本产生一个240 ×64 的特征向量.图4 是我们列举的每类活动的对数Mel 语谱图.
2.3 实验设置
在训练阶段,我们在预测标签和录音的真实标签之间应用对数交叉熵损失函数.神经网络的权值可以通过反向传播计算的权值梯度来更新.损失定义为:
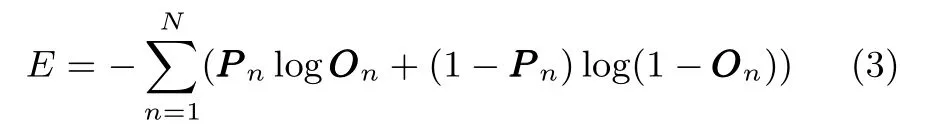
其中,E是对数交叉熵损失,OOOn和PPP n表示样本索引n处的预测和真实类别标签向量,批处理大小用N表示.我们采用Adam 作为随机优化方法,初始学习率为0.001,以0.9 的衰减率每两轮衰减一次学习率.批处理的大小为64,总共训练了30 轮.
2.4 实验结果
我们此次实验折叠了四次开发集数据,三折数据集用于训练模型,一折数据集用于预测结果,然后计算四折结果的平均值.重复该过程10 次计算预测结果的平均值,得到开发集上模型的F1 得分.这样更好地避免了偶然性,让实验结果更具有说服力.最后我们在评估集上进行了测试,得到了各模型的评估集F1 得分.
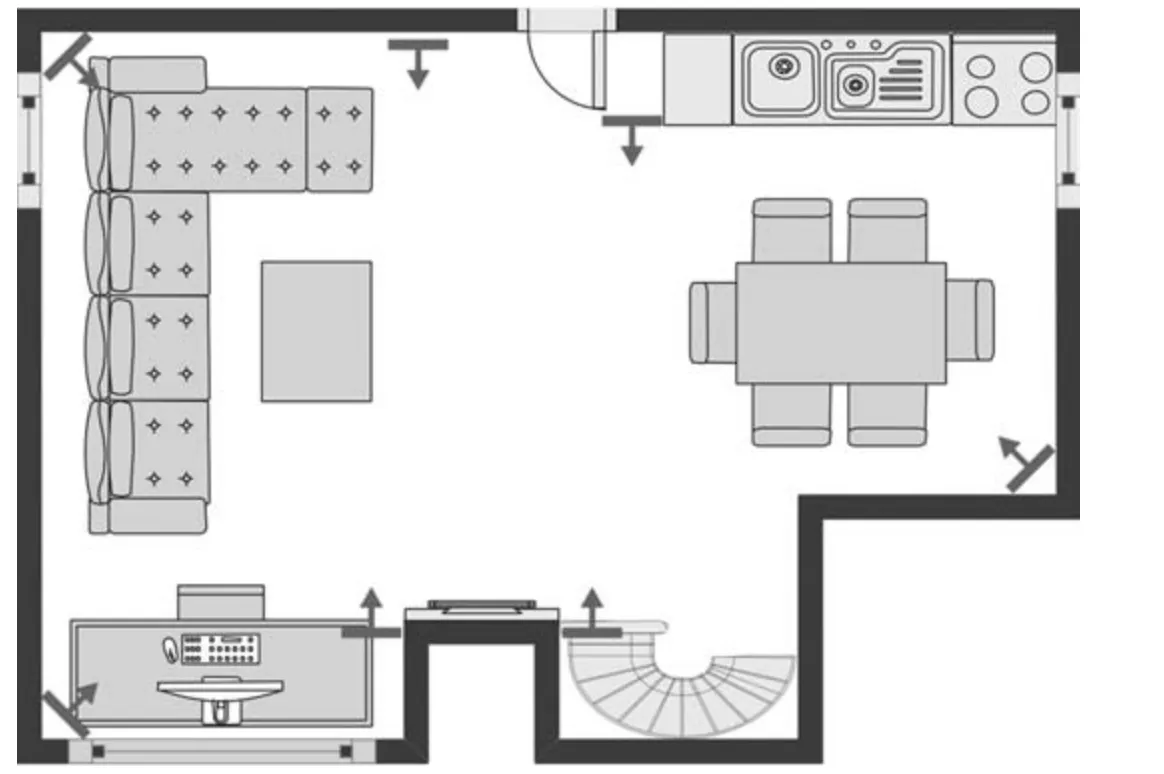
图3 具有传感器节点的厨房和客厅混合的2D 平面布置图Fig.3 2D floorplan of the combined kitchen and living room with the used sensor nodes
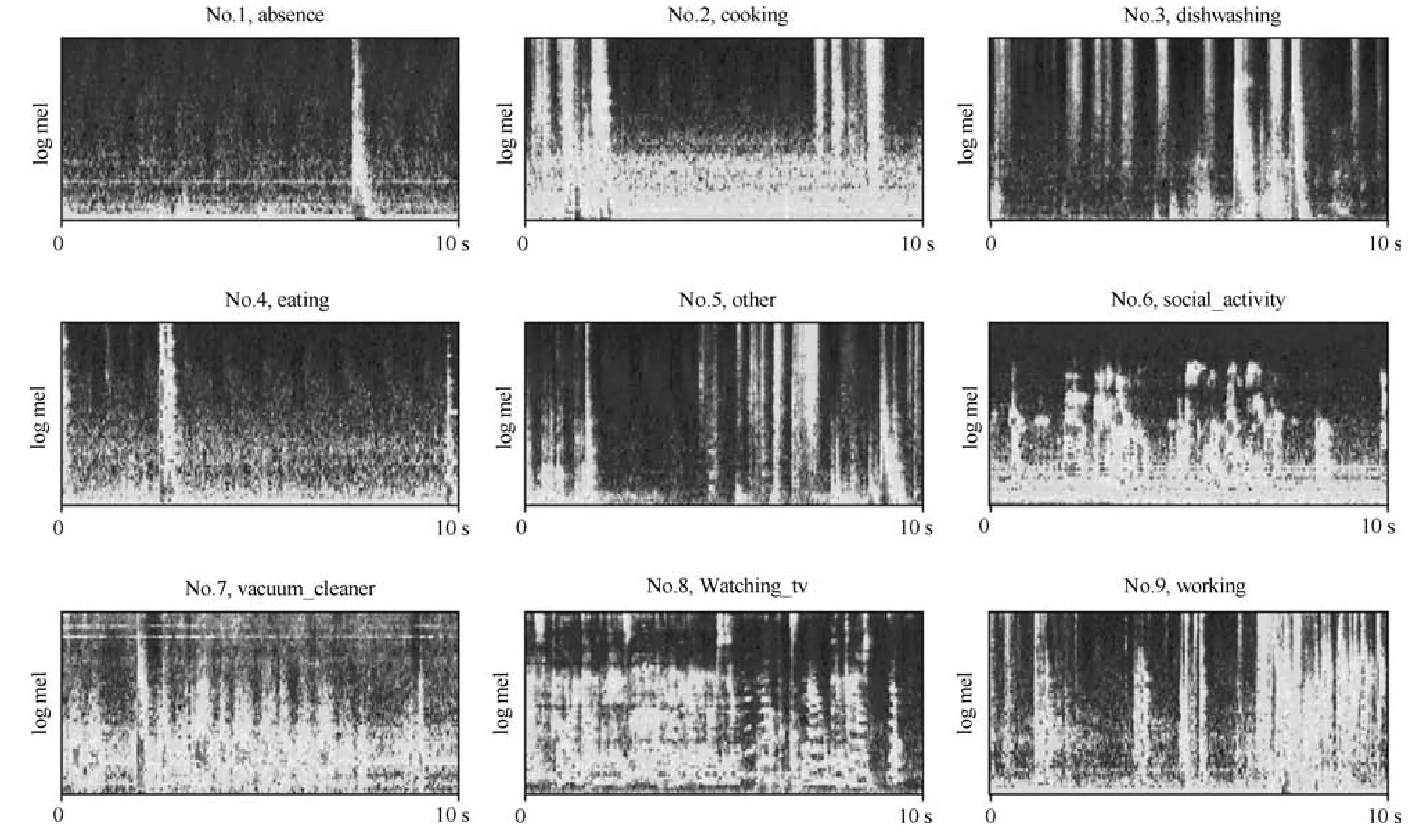
图4 各类活动的对数Mel 语谱图Fig.4 Logmel spectrum of various activities
表2 显示了5 个不同模型在开发集上各类活动的F1 得分,表3 是评估集上各模型平均F1 得分.其中基线系统是简单的两层卷积结构[12].GCRNN 是在卷积循环神经网络基础上加了门控线性单元.GCRNN-att 是GCRNN 后端加上了前文提到的注意力模块.Caps 是指没有加入注意力模块的胶囊网络模型.Caps-att 是我们提出的模型.
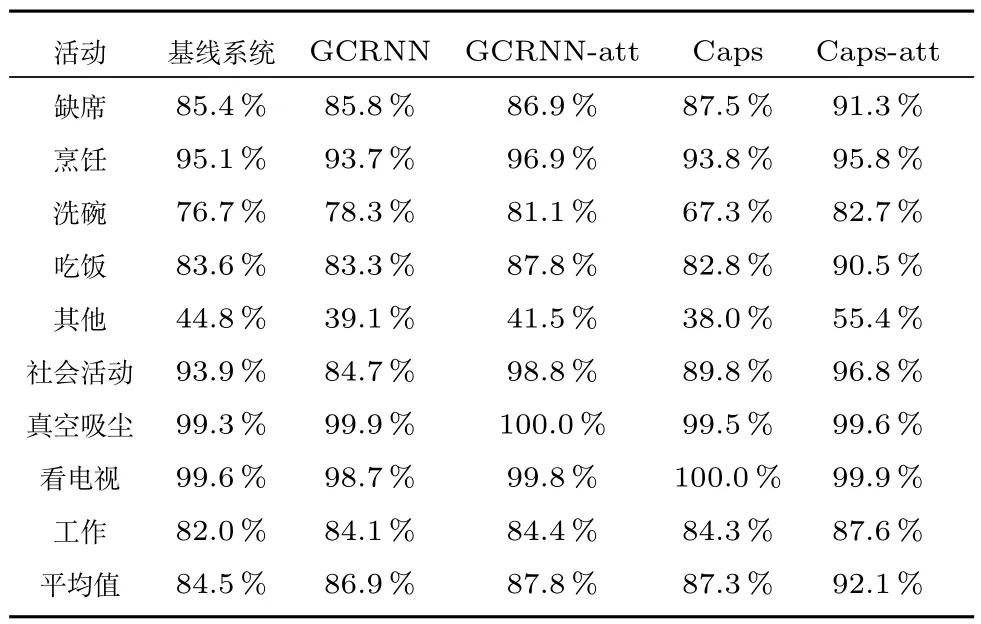
表2 开发集上各模型的F1 得分Table 2 F1 scores of each model on development dataset
从表2 的结果可以明显看出,我们的模型相比于其他4个模型在9 类活动中有5 类活动的F1 得分都是最高的,其中缺席类的F1 得分比其他4 个模型高出5% 左右,其他类的得分比另外4 个系统高出10% 左右.可以看出对于不是具体相关活动的类别,我们的模型能很好地减少过拟合现象.
从实验结果可以看出,我们模型在开发集和评估集上F1得分的平均值都要高于其他4 个模型.胶囊网络模型(Caps)在开发集和评估集的F1 得分明显高于基线系统,分别高出2.8% 和1.6%.这说明胶囊网络在音频分类问题中的效果是要明显好于这种浅层的CNN 结构.Caps 在开发集和评估集的F1 得分也高于GCRNN,分别高出0.4% 和0.1%.这说明相比于GCRNN 这种较深的网络结构,胶囊网络在分类效果上也有较好的表现.GCRNN-att 较GCRNN 在开发集和评估集F1 得分分别提高了0.9% 和0.7%;Caps-att 较Caps 在开发集和评估集F1 得分分别提高了4.8% 和2.2%,这说明注意力机制成功抑制了音频事件类不相关帧,选择了显著帧.
3 结论
在本文中,我们提出了注意力胶囊网络模型用于多声道音频分类任务.针对CNN 对局部特征间相对关系不敏感,提出采用胶囊网络学习局部特征与整体间的相对关系;针对最大池化路由造成的特征损失问题,提出采用动态路由避免忽视不显著局部特征,得到初级胶囊层与高级胶囊层间的权重系数,更加准确反映出部分与整体的关系;针对音频剪辑所有帧对音频类贡献程度不同,提出时间注意力机制赋予帧不同权重,减少模型过拟合问题.通过实验可以看出,相比于一般的卷积网络和卷积循环网络等方法,提出的网络模型具有更好的学习能力,模型在开发集和评估集上的F1 得分分别为92.1% 和88.8%.我们下一步的研究计划包括将注意力胶囊网络推广到注意力矩阵胶囊网络,将注意力胶囊网络用于弱标签半监督音频事件检测以及将注意力胶囊网络用于其他的类别区分度低的海量数据问题上.

表3 评估集上各模型F1 得分Table 3 F1 scores of each model on evaluation dataset
