基于全卷积神经网络与低秩稀疏分解的显著性检测
2019-12-12张芳王萌肖志涛吴骏耿磊童军王雯
张芳 王萌 肖志涛 吴骏 耿磊 童军 王雯
随着信息科技的快速发展与推广,图像数据成为人类重要的信息来源之一,人们接收的信息量呈指数级增长.如何在海量的图像信息中筛选出人类感兴趣的目标区域具有重要研究意义.研究发现,在复杂场景下,人类视觉处理系统会将视觉注意力集中于该场景的少数几个对象,也称为感兴趣区域.感兴趣区域与人类视觉感知关系较为密切,具有一定的主观性.显著性检测作为图像预处理过程,可以广泛应用到视觉跟踪[1]、图像分类[2]、图像分割[3]和目标重定位[4−5]等视觉工作领域.
显著性检测方法分为自上而下和自下而上两种.自上而下的检测方法[6−8]是任务驱动型,需要人工标注真值图进行监督训练,融入更多的人类感知(例如中心先验信息、色彩先验信息和语义先验信息等)得到显著图.而自下而上的方法[9−17]是数据驱动型,更注重利用对比度、位置和纹理等图像特征得到显著图.最早的研究者Itti 等[9]提出一种基于局部对比度的空间域视觉模型,使用由中心向四周变化的图像差异性得到显著图.Hou等[10]提出了基于谱残差(Spectral residual,SR)的显著性检测算法.Achanta 等[11]提出基于图像频域计算显著度的频率调谐(Frequency-tuned,FT)算法.Cheng 等[12]提出了基于直方图计算全局对比度的方法.Perazzi 等[13]引进了一种将显著性检测看作滤波的思想,提出了显著性过滤器(Saliency filters,SF)方法.Goferman 等[14]提出了基于上下文感知(Context-aware,CA)的显著性检测算法.Yang 等[15]先后提出基于图形正则化(Graphregularized,GR)的显著性检测算法和利用显著性传播的流行排序(Manifold ranking,MR)算法[16].Qin 等[17]提出基于背景先验和单层元胞自动机(Background-based method via single-layer cellular automata,BSCA)的显著性检测算法.此外,低秩矩阵恢复作为高维数据分析及处理的工具应用到显著性检测中[18−20].Yan 等[18]提出将图像显著区域看作是稀疏噪声,将背景看作是低秩矩阵,利用稀疏表示和鲁棒主成分分析算法计算图像的显著性.该算法首先将图像分解成8×8 的小块,对每个图像块进行稀疏编码并合并成一个编码矩阵;然后利用鲁棒主成分分析分解编码矩阵;最后利用分解得到的稀疏矩阵构建相应图像块的显著性因子.但是,由于大尺寸的显著目标包含很多图像块,每个图像块中的显著目标不再满足稀疏特性,因而极大地影响了检测效果.Lang 等[19]提出多任务低秩恢复的显著性检测算法,利用多任务低秩表示算法分解特征矩阵,并约束同一图像块中所有特征稀疏成分的一致性,然后采用重构误差构建相应图像块的显著性.该算法充分利用多特征描述的一致性信息,效果比文献[18]有所提升,但由于大尺寸的目标包含大量的特征描述,此时特征不再具有稀疏特性,仅利用重构误差不能解决这一问题,故该方法同样不能完整地检测出大尺寸的显著性目标.为了改善低秩矩阵恢复的结果,Shen 等[20]提出一种融合高层次和低层次信息的低秩矩阵恢复检测算法(Low rank matrix recovery,LRMR),这是一种自下而上与自上而下结合的算法.改进了文献[18]中的不足,首先将图像进行超像素分割,并提取超像素的多个特征;然后通过学习得到特征变换矩阵和先验知识,包括中心先验、人脸先验和色彩先验,再利用学习得到的特征变换矩阵和先验知识对特征矩阵进行变换;最后利用鲁棒主成分分析算法对变换后的矩阵进行低秩与稀疏分解.该方法在一定程度上改善了文献[18−19]的不足,但是由于中心先验存在一定的局限性,而在复杂场景下色彩先验也会失效,因此该算法对背景较复杂的图像检测效果不理想.
随着深度学习研究的不断深入,卷积神经网络逐渐应用到显著性检测中.李岳云等[21]提出了一种基于深度卷积神经网络的显著性检测方法,首先利用超像素算法和双边滤波分别得到区域和边缘信息,再利用深度卷积神经网络学习图像的区域和边缘特征,最后将卷积神经网络输出的区域置信图和边缘置信图融入到条件随机场中,达到判断显著性的目的.Wang 等[22]提出了一种基于循环全卷积神经网络(Recurrent fully convolutional neural networks,RFCNN)的显著性检测方法,主要包括预训练和微调两个步骤,利用RFCN 对原图和显著先验图进行训练达到对显著先验图修正的目的,然后利用传统算法对修正后的显著图进行进一步优化处理.Lee 等[23]提出了在一个统一的深度学习框架中利用高层次和低层次特征进行显著性检测的深度显著(Deep saliency,DS)算法,使用VGG-net 提取高级特征,利用低层次特征与图像中其他部分进行对比得到低层次距离图,然后使用卷积神经网络对距离图进行编码,最后将编码的低层次距离图和高级特征连接起来,采用一个全连接的神经网络分类器对特征进行评估,得到显著图.以上方法显示了深度学习在显著性检测中的优良性能.
如前文所述,文献[20]中的中心先验存在一定的局限性,而在复杂场景下色彩先验也会失效,二者均为不稳定的先验知识.为了提高方法在复杂场景下进行显著性检测的性能,本文对文献[20]进行改进,利用基于全卷积神经网络(Fully convolutional neural networks,FCNN)学习得到的高层语义先验知识替换文献[20]中的中心先验、人脸先验和色彩先验知识,并将其融入到低秩稀疏分解中.FCNN通常用于语义分割[24],即对图像中的各部分进行区域分割并给出语义类别.本文忽略类别因素,仅利用FCNN 定位前景目标,由于前景目标通常是观察者感兴趣的区域,因此FCNN 分割出的前景可作为显著性检测的语义先验知识.因为FCNN 对前景目标定位准确,所以本文方法能够有效提高显著性检测的准确性.
1 基于全卷积神经网络与低秩稀疏分解的显著性检测方法
本文方法的具体步骤是:1)对图像进行Meanshift 超像素聚类,并计算每个超像素中所有像素的颜色、纹理和边缘特征均值构造特征矩阵;2)为了使图像背景具有相似性以利于低秩稀疏分解,需要对上述特征矩阵进行变换,使其在新的特征空间中背景部分可以被表示为低秩矩阵,本文利用MSRA图像数据库中的图像基于梯度下降法学习特征变换矩阵[20];3)为了利用高层次信息以提高感兴趣区域的检测效果,利用全卷积神经网络对MSRA 数据库标记的图像进行学习,得到高层语义先验知识矩阵;4)利用特征变换矩阵和高层语义先验知识对特征矩阵进行变换;5)利用鲁棒主成分分析算法对变换后的矩阵进行低秩稀疏分解得到显著图.总体框架如图1 所示.
1.1 构造特征矩阵
输入一幅图像,提取颜色、纹理和边缘等特征,构成维度d53 的特征矩阵.
1)颜色特征.提取图像的R、G、B 三通道灰度值以及色调(Hue)和饱和度(Saturation)描述图像的颜色特征;
2)边缘特征.采用可控金字塔(Steerable pyramid)滤波器[25]对图像作多尺度和多方向分解,这里选取3 个尺度、4 个方向的滤波器,得到12 个响应作为图像的边缘特征;
3)纹理特征.采用Gabor 滤波器[26]提取不同尺度、不同方向上的纹理特征,这里选取3 个尺度、12 个方向,得到36 个响应作为图像的纹理特征.
利用Mean-shift 聚类算法[27]对图像进行超像素聚类,得到N个超像素{pi|i1,2,3,···,N},如图2(b)所示.这里的N为超像素个数,是Meanshift 方法自动聚类的类别数.计算每个超像素中所有像素特征的均值表示该超像素的特征值fi,所有超像素特征共同构成特征矩阵F[f1,f2,···,fN],Rd×N.
1.2 基于梯度下降法构造特征变换矩阵
本文采用文献[18−20]的思想,将图像显著区域看作稀疏噪声,将背景看作低秩矩阵.在复杂背景下,超像素聚类结果后的图像背景相似度依旧不高,如图2(b)所示,因此原始图像空间中的特征并不利于低秩稀疏分解.为了找到一个合适的特征空间能够将大部分的图像背景表示为低秩矩阵,本文基于梯度下降法利用MSRA 标记的数据库学习得到特征变换矩阵,在此基础上对特征矩阵F进行特征变换.获得特征变换矩阵的过程如下:
1)构造标记矩阵Qdiag{q1,q2,···,qN}RN×N,如果超像素pi在人工标注的显著性区域内,qi0,否则qi1.
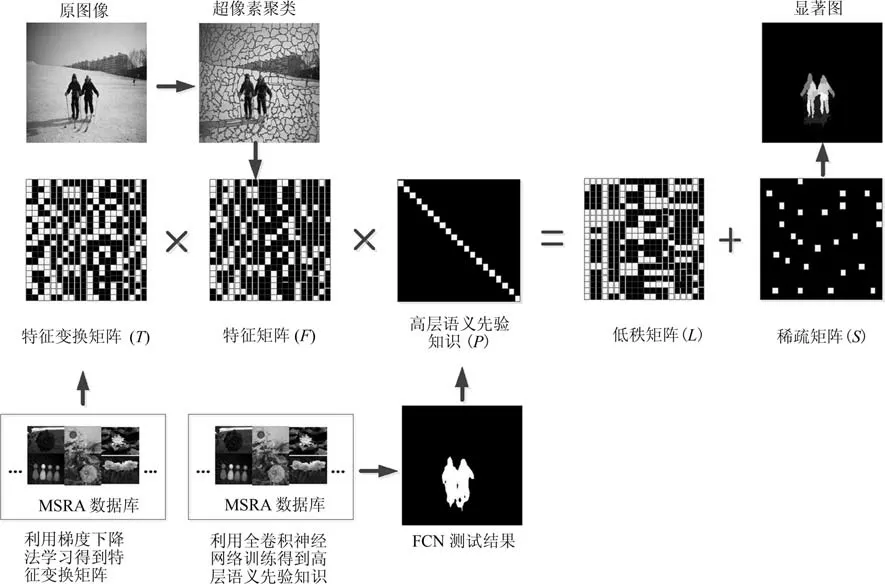
图1 本文方法的总体框架Fig.1 The overall framework of the proposed method
2)根据下式利用数据库中K幅图像学习特征变换矩阵T的优化模型[19].
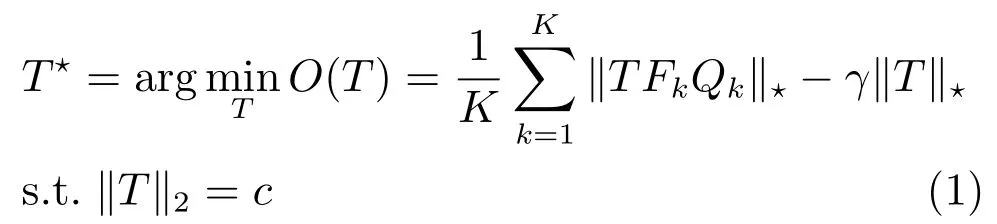
其中,FkRd×Nk为第k幅图像的特征矩阵,Nk表示第k幅图像的超像素个数,QkRNk×Nk为第k幅图像的标记矩阵;表示矩阵的核范数,即矩阵的所有奇异值之和,γ是权重系数,在一定意义下,核范数是矩阵的秩的最佳凸估计;2 表示矩阵T的2 范数,c是一个常数,阻止T任意变大或变小.如果特征变换矩阵T是合适的,则TFQ是低秩的,的作用是为了避免当T的秩任意小时得到平凡解[20].
3)找到梯度下降方向,即
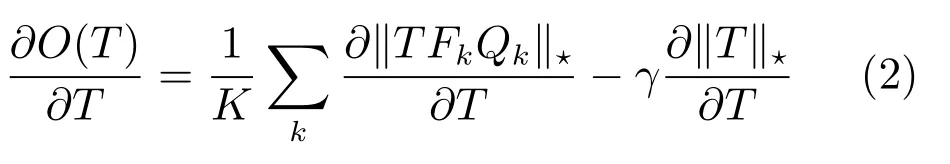
具体过程参见文献[20].
4)利用下式更新特征变换矩阵T,直到算法收敛至局部最优.
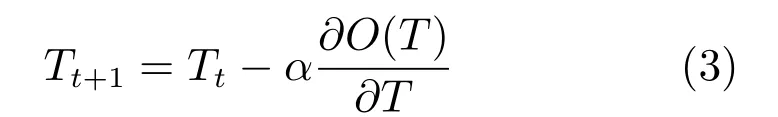
其中α为步长.
图2 显示部分中间过程结果.图2(a)是原图;图2(b)表示Mean-shift 聚类结果,可以看出由于背景复杂,聚类后的图像背景的相似性不够高,不利于低秩稀疏分解;图2(c)表示R、G、B 三个特征经过特征变换后合成的可视化结果,可以看出特征变换后背景的相似性明显提高;图2(d)表示利用特征变换矩阵对特征矩阵进行特征变换,再对变换后的特征矩阵进行低秩稀疏分解得到的显著图;图2(e)是真值图.从图2 可以看出,其中的背景噪声比较多,感兴趣区域不突出,显著图并不理想.说明虽然特征变换提高了背景的相似性,在一定程度上提升了低秩稀疏分解的效果,但由于背景非常复杂,仅基于颜色、纹理和边缘等低层次信息仍然无法得到准确的感兴趣区域.因此本文考虑在特征变换时融入高层语义先验知识,进一步提高特征的有效性.
1.3 基于全卷积神经网络提取高层先验知识

图2 部分中间过程结果图Fig.2 Part of the intermediate process result
如前所述,仅利用特征变换矩阵对特征矩阵进行变换,得到的最终显著图并不理想,这是由于仅利用底层特征提取显著图,干扰物体比较多,因此需要补充高层次信息以提升效果.本文采用的高层语义先验知识主要是根据以往经验(即训练样本)预测图像中最有可能感兴趣的区域,利用全卷积神经网络训练得到高层语义先验知识,并将其融入到特征变换过程中,用以优化最终的显著图.卷积神经网络(Convolutional neural network,CNN)是一种多阶段可全局训练的人工神经网络模型,可以从经过少量预处理甚至最原始的数据中学习到抽象的、本质的、高阶的特征[28].全卷积神经网络(FCNN)是卷积神经网络的一种扩展形式,由Matan 等首次提出[29],并成功运用到经典的卷积神经网络LeNet-5中.FCNN 可以接受任意尺寸的输入图像,与CNN的区别在于FCNN 以反卷积层代替全连接层,对最后一个卷积层的feature map 进行上采样,从而恢复到与输入图像相同的尺寸,最后在上采样的特征图上进行逐像素分类,对每个像素都产生一个二分类预测,输出像素级别的分类结果,从而解决了语义级别的图像分割问题.语义先验是感兴趣区域检测的一种重要的高层次信息,可以辅助检测感兴趣区域,因此本文利用FCNN 得到高层语义先验知识并将其用于感兴趣区域检测.
FCNN 的网络结构[24]如图3 所示,本文在原分类器参数的基础上,利用MSRA 数据库使用反向传播算法微调FCNN 所有层的参数.
实验的训练数据集来自MSRA 数据库中标记的17 838 张图片,将训练图像标记为前景和背景两类.在如图3 所示的网络结构中,第1 行在交替经过7 个卷积层和5 个池化层之后,得到feature map,最后一步反卷积层是对feature map 进行步长为32像素的上采样,此时的网络结构记为FCNN-32s.本文首先训练得到FCNN-32s 模型,实验发现,由于经过多次最大池化操作造成精度下降,直接对降采样输出的feature map 进行上采样会导致输出结果非常粗糙,损失很多细节.因此,本文尝试将步长为32 像素上采样得到的特征做2 倍上采样,与步长为16 像素上采样得到的特征进行求和,并将得到的特征上采样至原图大小进行训练,得到FCNN-16s 模型,此时获得了相比于FCNN-32s 更加精确的细节信息.使用同样的方法继续训练网络得到FCNN-8s模型,对细节信息的预测更为准确.实验表明,继续融合更底层的特征训练网络虽然能使得细节信息预测更为准确,但对低秩稀疏分解所得结果图的效果提升不明显,而训练时间会明显增加,故本文采用FCNN-8s 模型获取图像的高层语义先验知识,而不再融合更底层的特征.
至此,已训练得到FCNN-8s 模型.对于每一幅待处理图像,利用训练好的FCNN-8s 模型进行处理,输出基于FCNN 的语义先验知识,据此构建相应的高层语义先验知识矩阵RN×N,即
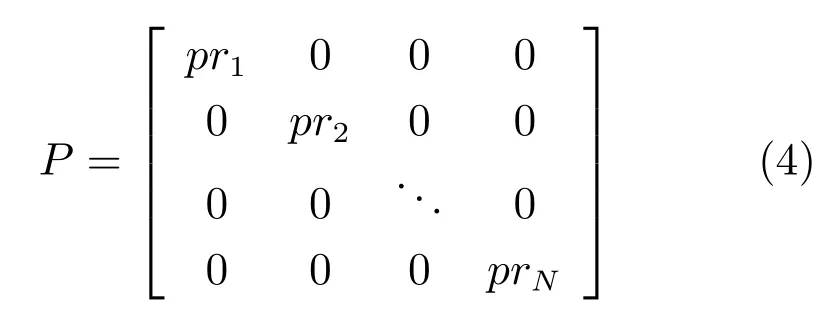
其中,pri表示FCNN 测试结果图像中超像素pi内所有像素的均值.
图4 是FCNN 高层语义先验知识及显著性结果图.图4(a)是原图;图4(b)是基于FCNN 的高层语义先验知识;图4(c)是融合高层先验知识后基于低秩稀疏分解的结果图;图4(d)是文献[20]方法的结果图;图4(e)是真值图.图4(b)中白色区域是根据训练图像学习得到的高层语义先验知识,即FCNN 预测的前景目标物体.经实验发现,基于FCNN 得到的高层语义信息对目标物体的定位比较准确.虽然有些目标物体的轮廓变形(例如图4(b)中的第2 行)有时存在误检(例如图4(b)中的第1行),但是并不影响其消除背景噪声的作用,将其应用到低秩稀疏分解(低秩稀疏分解方法将在第1.4节中介绍)中,可以提升感兴趣区域的检测效果.尤其是在复杂背景下,相比于文献[20]利用中心、颜色、人脸先验知识得到的结果而言,融合FCNN 高层语义先验知识后,基于低秩稀疏分解的检测效果明显改善,如图4(c)和图4(d)的对比结果所示.
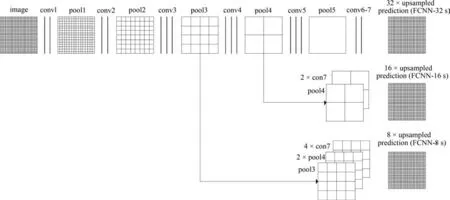
图3 FCNN 的网络结构Fig.3 The network structure of FCNN

图4 FCNN 高层语义先验知识及显著性检测结果图比较Fig.4 The FCNN high-level semantic prior knowledge and the comparison of saliency detection results
需要说明的是,虽然FCNN 能够准确预测人们感兴趣的前景目标,但给出的前景目标既不完整,也不精细,如图4(b)所示,需要进一步修正.所以本文利用FCNN 定位出前景目标并将其作为高层先验知识与提取的传统特征相融合,然后再进行低秩稀疏分解,得到最终的显著性检测结果,具体见第1.4 节.
1.4 基于低秩稀疏分解检测显著性
受文献[18]的启发,图像中的背景可表达为低秩矩阵,而显著区域可看作是稀疏噪声.对于一幅原始图像,首先根据第1.1 节所述方法得出特征矩阵F[f1,f2,···,fN]Rd×N,以及根据第1.2 节得出特征变换矩阵T,然后根据第1.3 节得出高层先验知识P.根据下式,利用学习得到的特征变换矩阵T和高层语义先验知识P对特征矩阵F进行变换,并利用鲁棒主成分分析算法[30]对变换后的矩阵进行低秩稀疏分解.
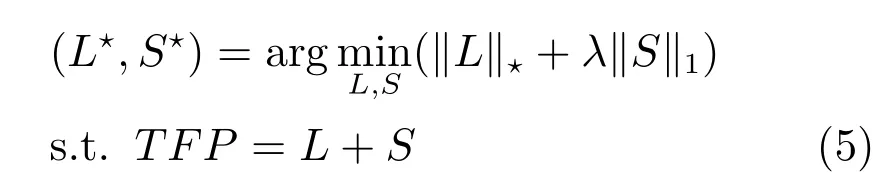
其中,Rd×N是特征矩阵,Rd×d是学习得到的特征变换矩阵,RN×N是高层先验知识矩阵,Rd×N表示低秩矩阵,Rd×N表示稀疏矩阵,表示矩阵的核范数,即矩阵的所有奇异值之和,1 表示矩阵的1 范数,即矩阵中所有元素的绝对值之和.
假设是稀疏矩阵的最优解,由下式可计算出显著图为
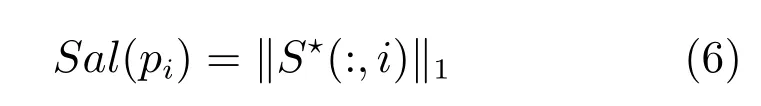
其中,Sal(pi)表示超像素pi的显著值,(:,i)1表示的第i列向量的1 范数,即向量中所有元素的绝对值之和.
2 实验结果与分析
利用两个公开标准数据库MSRA-test1000 和PASCAL−S 对方法的准确性和有效性进行评价.MSRA-test1000 是本文在MSRA-20000 数据库中随机挑选出来的1 000 幅图像,这些图像未参与高层先验知识的训练,其中有些图像背景比较复杂,如图5(a)所示.PASCAL−S 来源于PASCAL VOC2010 数据库,包含了850 幅复杂背景的自然图像.这些数据库图片都有人工标注的真值图,方便对算法进行客观评价.
将本文方法与当前较为经典和流行的算法进行比较,包括基于频域的FT 算法[11]、SR 算法[10]、基于上下文感知的CA 算法[14]、基于滤波的SF 算法[13]、基于凸壳中心和图形正则化的GR 算法[15]、基于流行排序的MR 算法[16]、基于单层元胞自动机的BSCA 算法[17]和基于低秩矩阵恢复并且融合先验知识的LRMR 算法[20].这8 种传统算法是前述自上而下和自下而上方法中较为经典或者处理效果较好的算法,源代码均由作者提供.此外,将本文算法与基于深度学习的RFCN 算法[22]和DS 算法[23]进行对比.

图5 实验结果比较图Fig.5 The comparison of experimental results
2.1 主观评价
图5 是本文方法结果与其他8 种传统算法的结果比较图.图5(a)∼5(l)分别是原图、真值图、FT 算法、SR 算法、CA 算法、SF 算法、GR 算法、MR 算法、BSCA 算法、LRMR 算法、和FCNN高层语义先验知识、本文算法.由图中对比效果可以直观看出,FT 算法可以检测出部分图像的感兴趣区域,但背景噪声较多.SR 和CA 算法可以较为准确地定位感兴趣区域,但是检测出的感兴趣区域边缘较明显而内部区域不突出,并且背景噪声较多.SF 算法背景噪声小,但是感兴趣区域显著度不高.GR、MR、BSCA 和LRMR 算法都是比较优秀的算法,对于背景与感兴趣区域对比度较明显的图像可以很好地检测出感兴趣区域,但是对背景噪声抑制有些不足,例如第2 行和第4 行的图像;对于背景复杂的图像,感兴趣区域与背景对比度不明显,这4 种方法不能很好地定位感兴趣区域,检测出的感兴趣区域显著度不够高,背景噪声抑制不足,例如第1、3 和5 行的图像.本文方法可以在复杂的图像中准确检测出感兴趣区域,并且很好地抑制背景噪声,与其他8 种算法相比更接近于真值图.此外,图5(k)是FCNN 高层语义先验知识图,由图可以看出,FCNN 高层先验知识图可以准确定位感兴趣区域,但是对于细节的表达有些粗糙,例如第2、4 和5 行的图像,由图5(l)可以看出,本文方法可以利用FCNN 高层先验知识更好地处理一些细节,这也证明了FCNN 高层语义先验知识对文本方法的贡献是较为突出的.
2.2 客观评价
为了对本文方法的性能进行客观评价,采用四个评价指标,即准确率(Precision)、召回率(Recall)、F-measure 以及平均绝对误差(Mean absolute error,MAE)进行对比分析.
2.2.1 与传统方法比较
1)准确率和召回率
首先采用最常用的准确率–召回率曲线对算法进行客观比较.如下式所示.
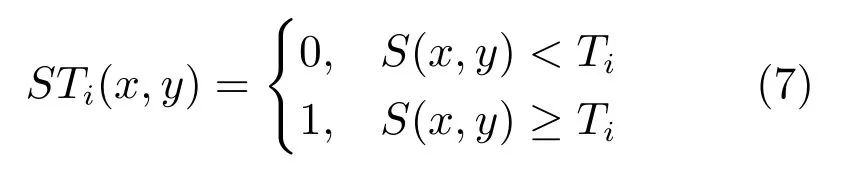
依次选取0 到255 之间的灰度值作为阈值Ti,分别将各算法的结果图进行二值化,得到二值图,并与人工标注的真值图进行比较,利用下列二式计算各算法的准确率Pi和召回率Ri,并画出Precision-Recall 曲线.
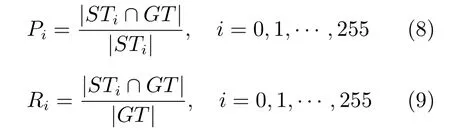
其中,STi表示显著图经过二值分割后值为1 的区域,GT表示真值图中值为1 的区域,|R|表示区域R中的像素个数.
Precision-Recall 曲线中,在相同召回率下,准确率越高,说明对应的方法越有效.图6 是9 种算法在MSRA-test1000 和PASCAL−S 两个数据库上的Precision-Recall 曲线,由图可以看出,在这两个数据库上本文方法优于其他算法.
为了综合考虑准确率和召回率,本文采用Fmeasure(Fβ)进一步评价各个算法.
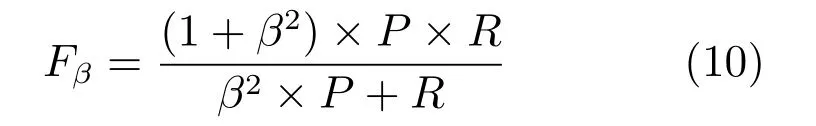
其中,P是准确率,R是召回率,β是权重系数.根据文献[11],设置β20.3,可以达到突出准确率的目的.F-measure 衡量了准确率和召回率的整体性能,数值越大,说明方法性能越好.计算F-measure时,需要将各个算法结果在同等条件进行二值化,本文采用自适应阈值分割算法,即将阈值设置为每幅显著图的平均值,然后与真值图进行比较,计算得到准确率和召回率,再利用式(10)计算F-measure值.图7 是9 种算法在两个数据库上的比较结果,可以看出本文方法的F-measure 最大.
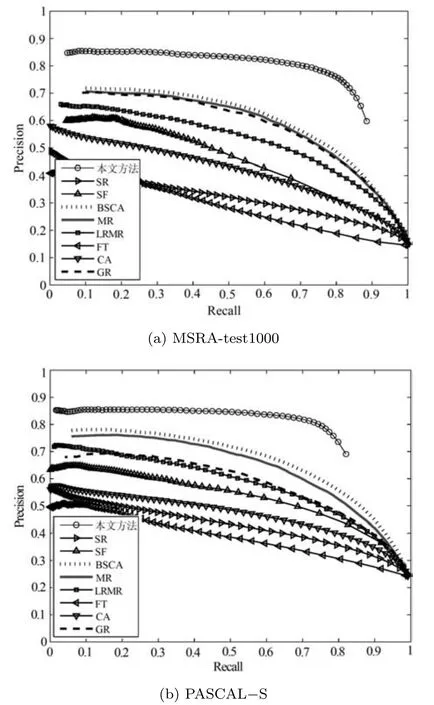
图6 准确率–召回率比较Fig.6 The comparison of Precision-Recall curves
2)平均绝对误差
Precision-Recall 曲线只是评价目标的准确性,而没有评判非显著区域,即不能表征算法对背景噪声的抑制情况,因此本文利用平均绝对误差(MAE)对整幅图进行评价.MAE 是以像素点为单位计算显著图与真值图之间的平均差异,计算公式为
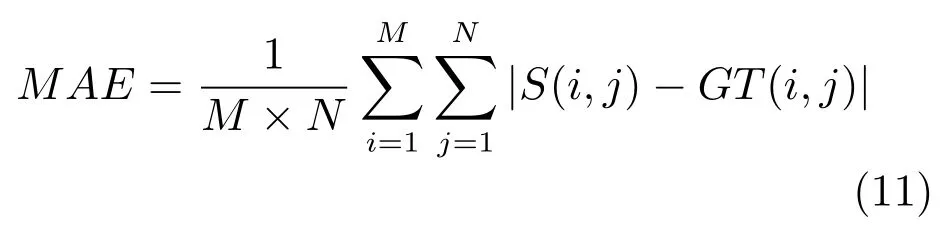
其中,M和N代表图像的高度和宽度,S(i,j)代表显著图对应的像素值,GT(i,j)代表真值图对应的像素值.显然MAE 的值越小,显著图越接近于真值图.表1 为9 种算法的MAE 比较结果.可以看出,在两个数据库中本文方法的MAE 值均小于其他8种算法,说明本文方法的显著图更接近于真值图.
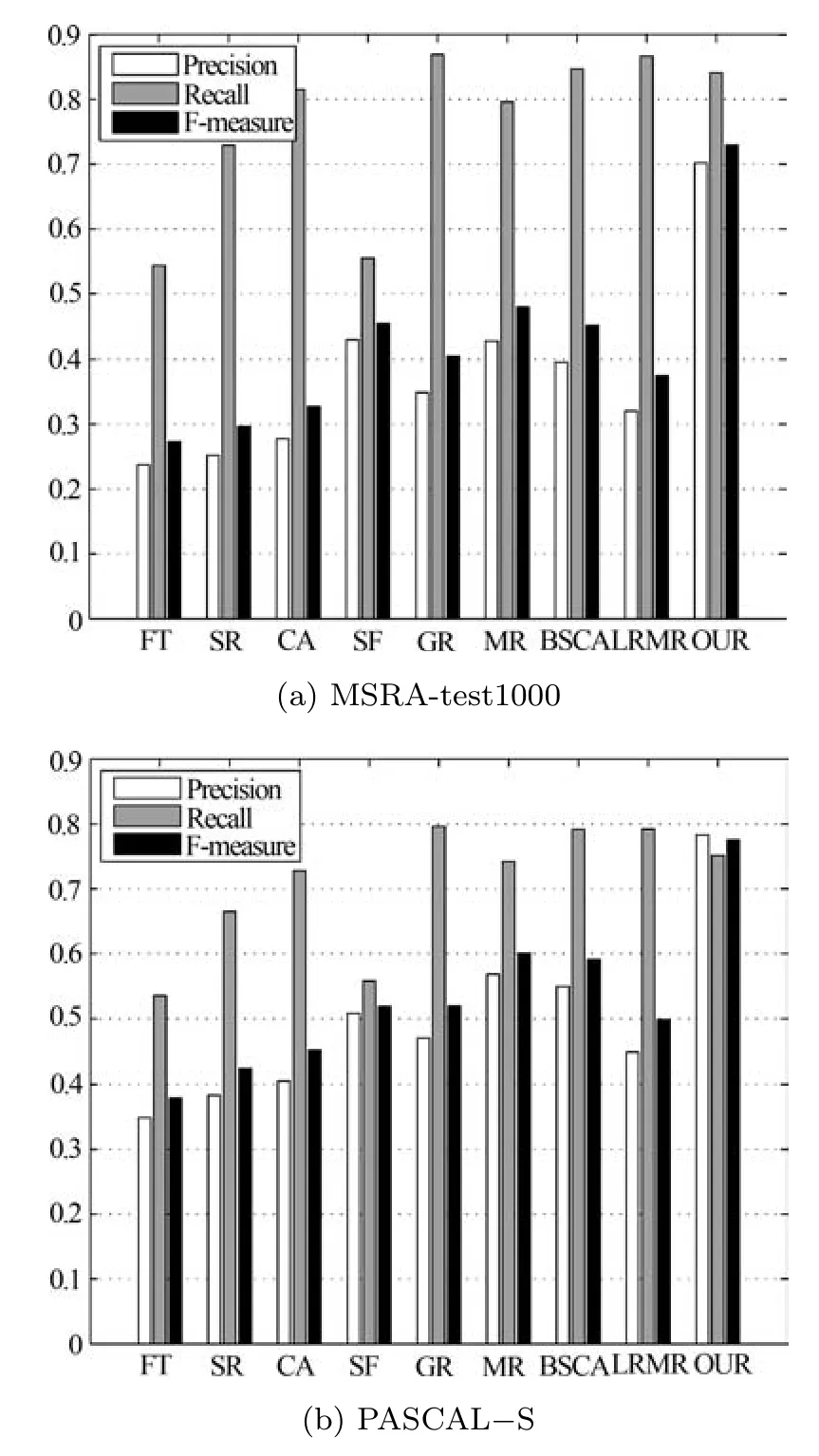
图7 F-measure 比较Fig.7 The comparison of F-measure
3)运行时间
在配置为i7-6700 k,内存32 GB,4.00 GHz CPU 的PC 机上利用MATLAB2012a 运行9 种算法,平均运行时间如表2 所示.
综合表1 和表2 可以看出,早期的一些算法,如FT、SR 和SF,虽然运行时间较快,但是在主观评价和客观评价中表现不太理想;CA 算法运行时间较长;GR、MR 和BSCA 算法在时间上稍慢于早期的几种算法,但效果有明显提高;本文方法的运行时间与LRMR 算法相当,虽然时间上没有太大的优势,但是无论是主观对比还是客观的P-R 曲线、F-measure 和MAE 等指标的对比,都明显优于其他算法.
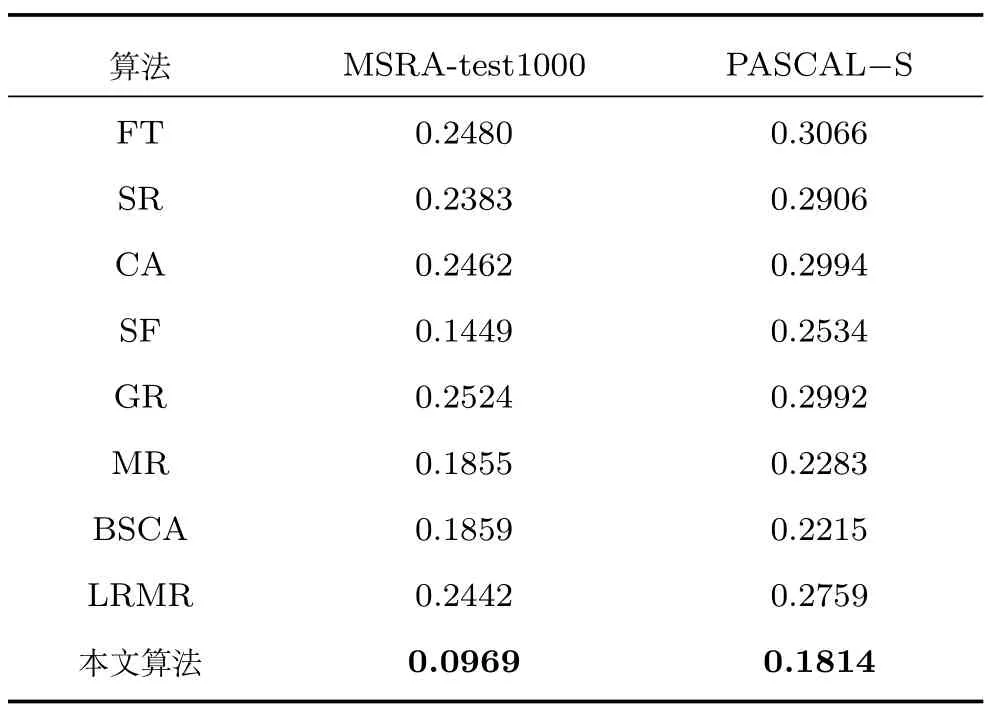
表1 本文方法与传统方法的MAE 比较Table 1 The comparison of MAE between the proposed method and traditional methods
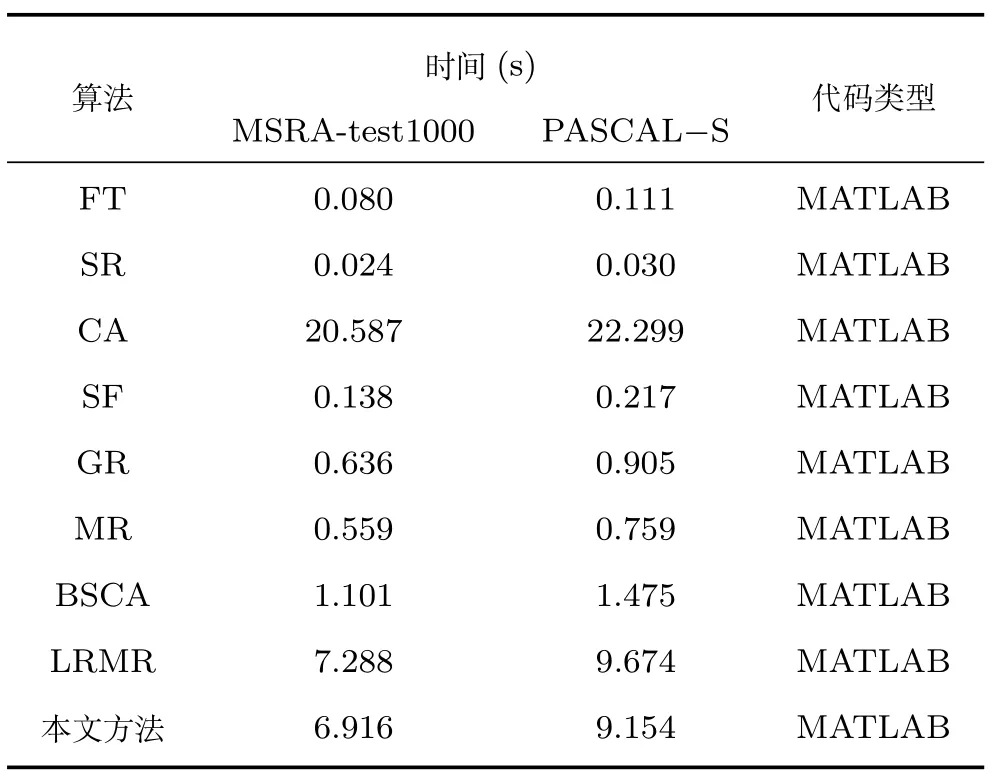
表2 本文方法与其他方法的平均运行时间比较Table 2 The comparison of average running time between the proposed method and other methods
2.2.2 与深度学习方法比较
图4 虽然体现出了FCNN 高层先验知识的不足之处,但并不能否认它的重要作用.本节通过比较FCNN 分割的前景目标与本文最终分割得到的感兴趣区域的准确性说明FCNN 在本文方法中的重要作用.由于得到的FCNN 高层先验知识是二值图像,所以将本文方法结果图进行二值化,在MAE 指标上对二者进行比较.表3 是二者在两个数据库上的MAE 值对比,可以看出本文方法的二值化结果与FCNN 结果图的MAE 值很相近,说明本文方法的结果图在一定程度上是由FCNN 结果图决定的.
表4 为在PASCAL-S 数据库上本文方法与RFCN 算法、DS 算法的F-measure 值和MAE 对比.可以看出,在PASCAL-S 数据库上,一方面,本文方法的F-measure 值高于其他两种算法,说明本文方法稳健性很好;另一方面,本文方法的MAE 指标略高于DS 算法.本文方法F-measure 值较好但MAE 指标略差的原因是经过低秩稀疏分解得到的稀疏矩阵能准确反映显著区域的位置,但稀疏矩阵中的数值偏低,造成恢复得到的结果图中显著区域的灰度值偏低(如图5 所示).
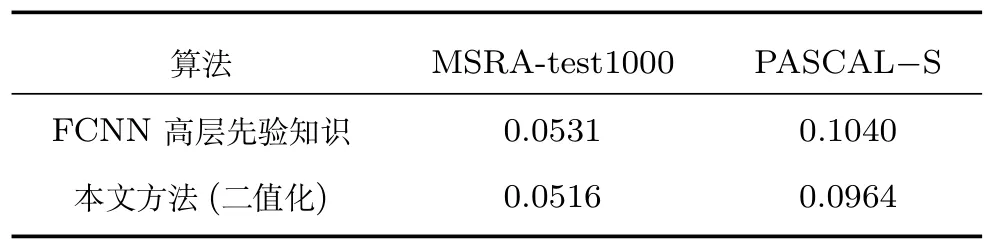
表3 FCNN 分割的前景目标与本文最终分割得到的二值感兴趣区域的MAE 比较Table 3 The comparison of MAE between the segmented foreground object by FCNN and the segmented binary ROI by the proposed method
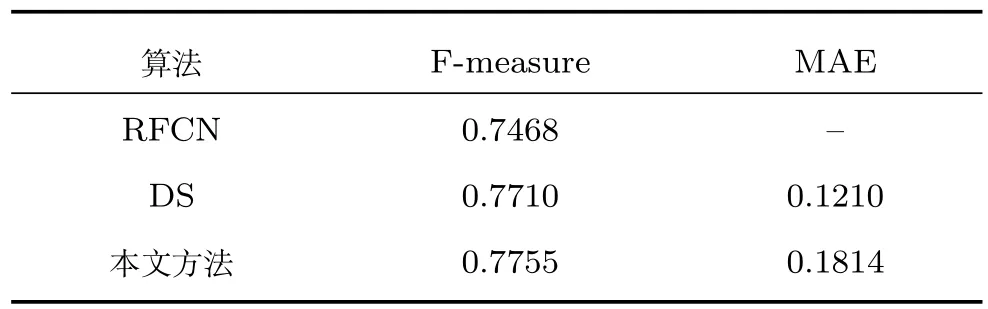
表4 本文方法与深度学习方法的指标比较Table 4 The comparison of evaluation indexs between the proposed method and deep learning methods
为了证实以上分析的正确性,本文对显著性结果乘以一个线性因子θ进行对比度线性拉伸,再计算MAE 指标,并绘制θ-MAE 关系图,如图8 所示.由图8 可以看出,θ3.2 时,本文方法的MAE 值与DS 算法相当,如果θ继续增大,则本文方法的MAE 值优于DS 算法.
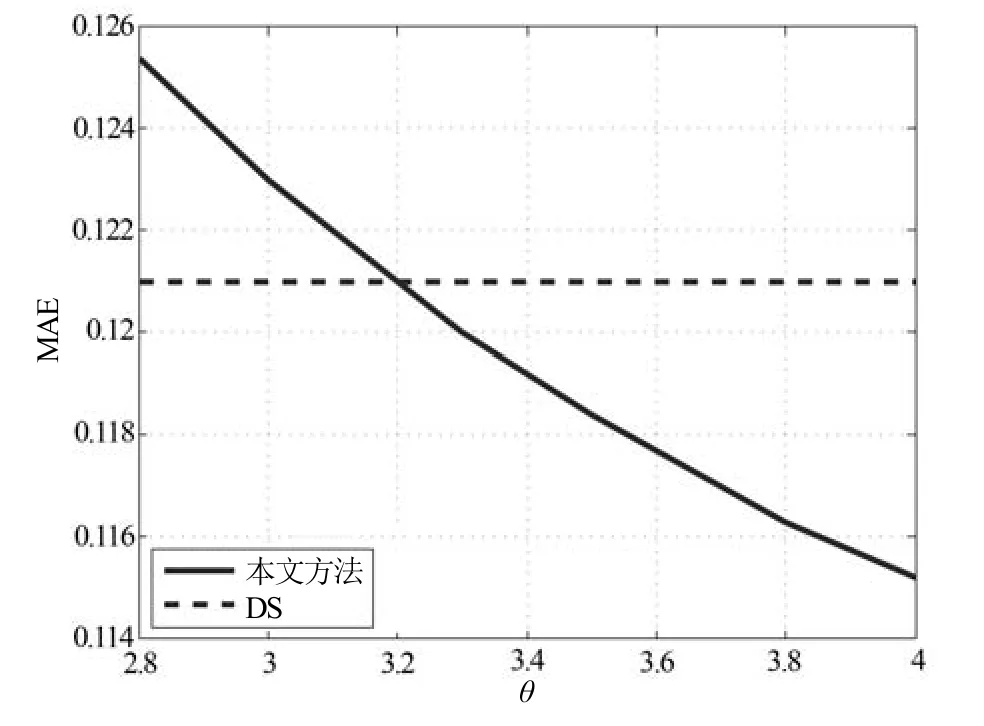
图8 对本文结果进行线性拉伸后与DS 方法的MAE 值比较Fig.8 The comparison of MAE between the results of linear stretching in this paper and the results of the DS method
因此综合来看,本文方法是一种定位准确、检测信息完整的显著性检测方法.
3 结论
本文提出一种基于全卷积神经网络与低秩稀疏分解的显著性检测方法.首先,对原图像进行超像素聚类,并提取每个超像素的颜色、纹理和边缘特征,据此构成图像的特征矩阵;然后,利用MSRA数据库基于梯度下降法学习得到特征变换矩阵;接着,再次利用MSRA 数据库对全卷积神经网络进行微调,学习得到高层语义先验知识矩阵;最后,利用特征变换矩阵和高层语义先验知识矩阵对特征矩阵进行变换,再利用鲁棒主成分分析算法对变换后的矩阵进行低秩稀疏分解,得到最终的显著图.在公开的MSRA-test1000 和PASCAL−S 数据集上进行实验验证,在准确率–召回率曲线、F-measure 和MAE 指标上优于当前流行算法.
