基于深度图及分离池化技术的场景复原及语义分类网络
2019-12-12林金花姚禹王莹
林金花 姚禹 王莹
在客观物质世界中,目标实体的客观存在形式通常取决于其所占用的三维空间位置.机器系统识别客观实体的语义及其拓扑存在性需要精准的神经网络模型.在机器视觉感知系统中,鲁棒重建三维场景以及识别目标语义至关重要,能够实现机器系统对目标区域信息的有效捕捉与精准定义,有效地识别出目标场景形状及其语义信息,语义识别与场景重建相互作用以确保机器视觉系统能够鲁棒识别并复原目标场景.传统方法一般分别完成这两项工作,例如,二维识别方法一般仅对二维图像进行分类处理,不会重建目标拓扑结构[1−2];相反,几何重建方法仅复原三维结构信息,而不识别目标语义.针对这一问题,本文构建了一种场景重建与语义识别相互结合的深度卷积神经网络模型,同时实现了对三维场景的重建与语义分类功能.
为了高效训练本文的模型,使用监督式学习方法完成卷积神经网络的训练过程,进而实现场景重建与语义识别功能.本文方法对深度数据进行重新表示,使用截断式带符号距离函数(Truncated signed distance function,TSDF)编码方式对目标场景进行三维体素重定义,每个体素包含:被占用体素与空闲体素两种含义.如何从不完整的目标场景中识别其语义以及不可见区域的语义标注问题是本文需要解决的关键问题.
针对上述问题,本文构造了一种上下文区域拓展网络,增加了接收区域场景的体素信息,使得目标语义识别面更广.另一方面,本文构建了一种有效的用于深度学习的数据集,并对其完成了体素标注.
1 相关工作
在机器视觉系统中,鲁棒完成三维场景的语义分割任务至关重要,常用任务包括机器人路径规划、人员协调辅助以及智能监控等.近年来,为了满足视觉系统需求,实现对目标场景的语义分割任务,深度学习神经网络得到广泛应用,深度神经网络通过学习大规模场景数据,生成训练标签,进而实现目标场景理解任务.然而,对于大多数的视觉处理任务,真实场景数据是有限的,并且受深度感知技术和语义分类方法的限制,使得构建高效的深度学习网络并不容易.
深度神经网络被广泛用于解决对象分类和目标检测问题[3−4].然而受数据规模、存储介质和计算能力的限制,深度神经网络的复杂程度也随之提高,限制了深度神经网络的适用范围.这种限制主要出于两个方面:1)随着模型尺度的增大,网络的复杂度也随之增加,例如Googlenet 数据集的50 MB 模型,Resnet-101 的200 MB 模型,Alexnet 的250 MB 和VGG-net 的500 MB 模型;2)复杂神经网络通常需要超高性能的处理器的支持,即高配置的GPU 高速并行处理单元的支持,这使得研究人员致力于模型的压缩,以减小神经网络的内存和处理单元占用率[5−6].例如,Ren 等[7]对遮挡目标场景鲁棒地完成重建过程,将大权重矩阵分解为几个可分离小矩阵来减少冗余,重建效果较好,但无法实现语义识别功能.对于神经网络的完全连接层,这种方法已被证明非常有效.科研工作者给出了多种基于连接限幅的语义重建方法,删除了预训练和再训练模型的冗余连接.这些方法将模型参数的数量减少了一个数量级,而不会对分类精度造成重大影响,但三维重建精度会随着降低[8−11].另一种语义重建策略是限制模型本身的架构.例如,去除完全连接的层,使用小尺寸的卷积滤波器等,目前较先进的深层网络,如Nin、Googlenet 和Resnet 都采用这种架构.然而这种方法对重建场景的几何拓扑细节表示不佳影响了重建分辨率[12−13].Zheng 等[14]使用固定点表示来量化预训练神经网络的权重,以加快网络在CPU上的运行时间,同时使用空间预测方法来推断遮挡场景信息.Kim 等[15]提出了替代量化方法来减小模型尺寸,在保证最小精度损失的情况下,使用k级均值矢量量化实现了4∼8 倍的重建精度,然而引起网络训练时间的增加.Hane 等[16]和Blaha 等[17]使用绑定更新优化策略来保证重建视觉的多样性,以此加强网络的重建精度.
针对上述问题,本文给出了一种适用于大尺度场景重建与语义识别的深度卷积神经网络模型,将目标几何信息与目标上下文语义信息相结合,进而完成对目标场景的鲁棒重建与识别.另外,本文建立了一种用于三维场景学习的数据集,可用于对RGB图像的语义分割过程[18−21].
2 语义场景复原网络
本文的深度卷积神经网络由多个层次的处理单元组成,关键核心是完成摄像机视锥体划分范围里的空间体素分配到一系列语义类别标注,假设C{c0,···,cN+1},其中,N表示目标场景包含的类别总数,c0代表未被占用的体素.每个神经单元的激励函数如下:zg(wwwTx),其中,Rc×w×h为权重向量,Rc×w×h为输入向量,g(·)为非线性函数.本文卷积神经网络实现了由这些单元构成的多个层,并用张量Rc×w×h来表示权重.c,w和h分别用来定义滤波器通道的数量,宽度和高度.由于这种基本运算在整个网络中重复,且神经网络通常由繁多的处理单位组成,式(1)的表示方式是决定整个网络模型复杂程度的主要因素.网络的复杂程度主要与两个因素有关:1)存储权重www需要巨大的内存开销;2)大量的点积运算wwwTx需要高成本的计算开销.当权重和点积运算为浮点值时,上述两个方面的开销会剧增,导致实际应用能力差[22].因此本文所提的低精度卷积神经网络更适用于解决实际三维重建与语义分类问题.本文网络的场景重建与语义识别过程如图1 所示.下面分节阐述本文网络模型的构造与重建过程.
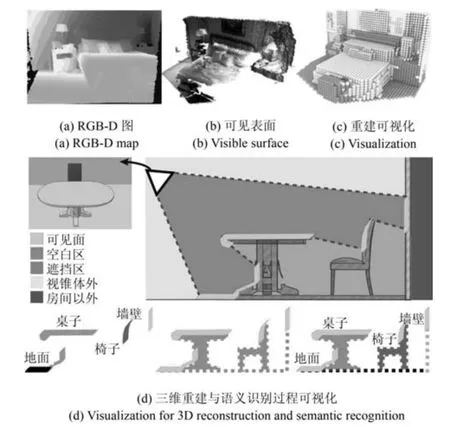
图1 本文深度卷积神经网络的场景重建与语义分类过程Fig.1 3D reconstruction and semantic classification of our depth convolutional neural network
2.1 体素数据编码及分离池化方法
首先,对三维场景的语义分类原理进行分析,构建基于改进的TSDF 编码以及细粒度池化特性的深度卷积神经网络模型;其次,提出估计算法对三维语义感知特性参数进行估计,解决TSDF 编码下具有细粒度池化层的深度卷积神经网络的模型优化问题;最后,建立考虑改进的TSDF 编码下三维语义场景的语义分类性能评价体系,预测网络对三维场景的语义分类性能,改善机器系统对三维场景的语义感知性能,为具有三维语义感知能力的机器视觉系统在军用和民用上的应用提供理论依据.
本文对TSDF 进行了改进,使之适应于场景重建与语义分类的混合卷积神经网络模型.一般情况下,深度卷神经网络模型使用距离相机位置最近投影直线的方式来获取场景关键点.然而,该方法在节省重建投影视觉的同时,却以关键点捕获精度为代价,影响了对三维场景的最终重建精度以分类性能.为提高重建精度及语义分类性能,本来采用了一种随机选取池化层内部表面点的方式来提取关键点,改善了TSDF 距离的计算时间,同时保证了重建与分类精度.分离池化后的特征区域本身具有细粒度空间几何拓扑结构的特性,当随机采用发生时,平均池化粒度值基本保持不变,因此确保了随机采用的平均精准度,以此构建的TSDF 的精度也随之增加.本文采用池化技术的体素编码方式如图2 所示.
2.2 复原网络结构
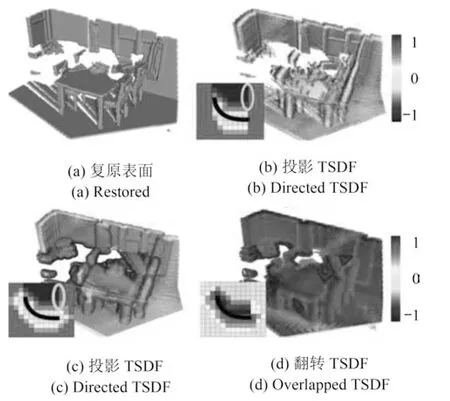
图2 常用的TSDF 编码可视化结果Fig.2 Visualization of several encoding TSDF
三维场景语义分类问题是机器视觉领域的热点研究问题.本文考虑结合TSDF 编码与分类池化技术的三维场景重建与语义分类网络模型如图3 所示.下面分五个方面阐述本文深度卷积神经网络的场景复原与语义分类过程.
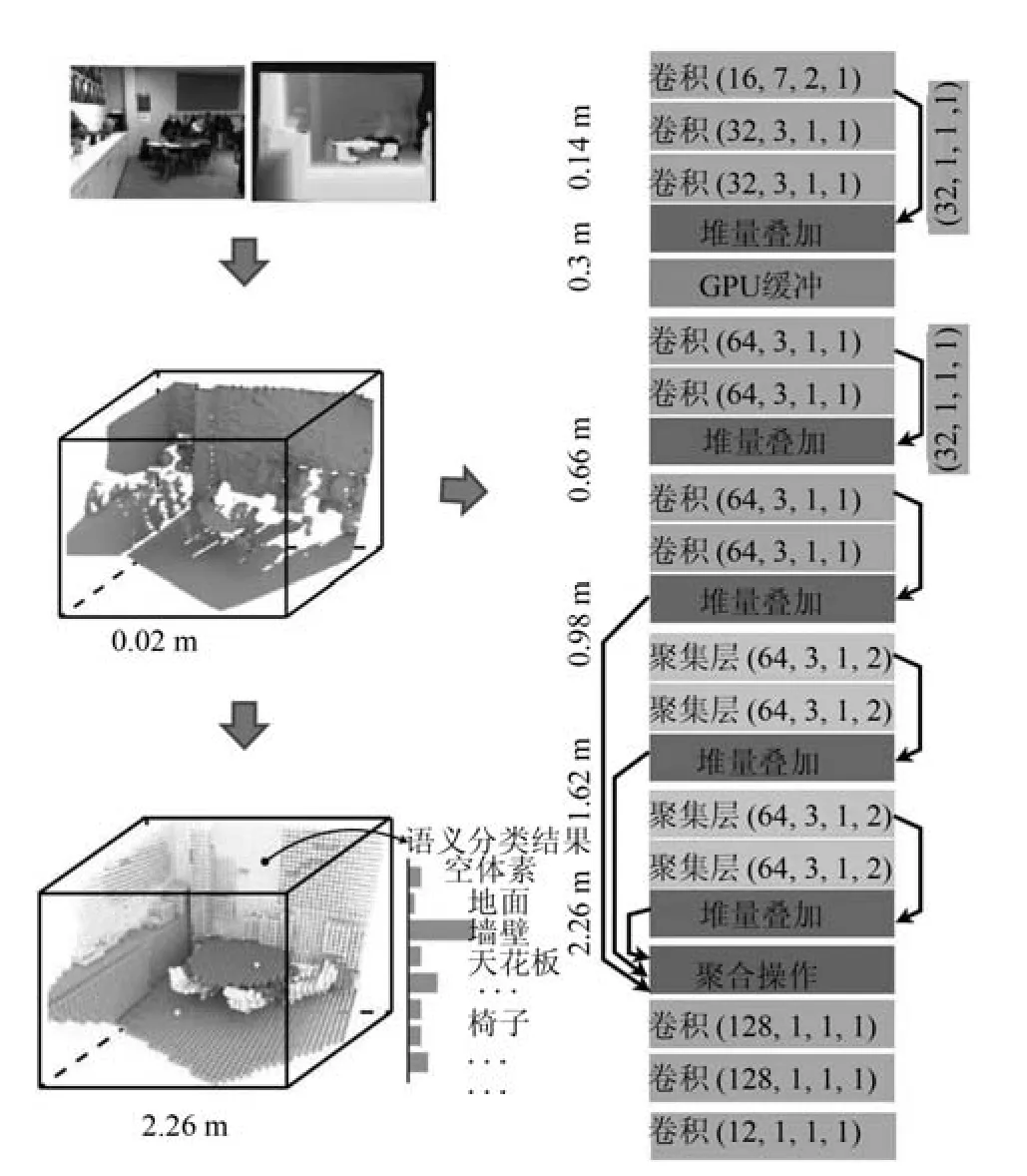
图3 本文所提深度卷积神经网络模型Fig.3 Our depth convolutional neural network
1)本文构建了一种以RGB-D 深度图作为输入的深度学习网络框架.一个点云由一组三维点数据构成,即{Pi|i1,···,n},每个三维点Pi由五维向量表示.对于对象分类任务,输入点云直接从目标形状采样,或者从一个场景点云预分割得到.对于语义分割,输入可以是用于部分区域分割的单个对象,或者用于对象区域分割的三维场景子体积.本文网络将为n个点和m个语义子类别中的每一个输出n × m个分数.图4 给出了本文语义分类网络架构.T1 和T2 是输入点和特征的对称转换网络.FC是完全连接的层在每个点上操作.MLP是每个点上的多层感知器.vec是大小为16 的向量,指示输入形状的类别.本文网络能够预测体素数量,如图4 中的左下角曲线图所示,这表明本文复原网络能够从本地邻域获取信息,对区域分割具有鲁棒性.
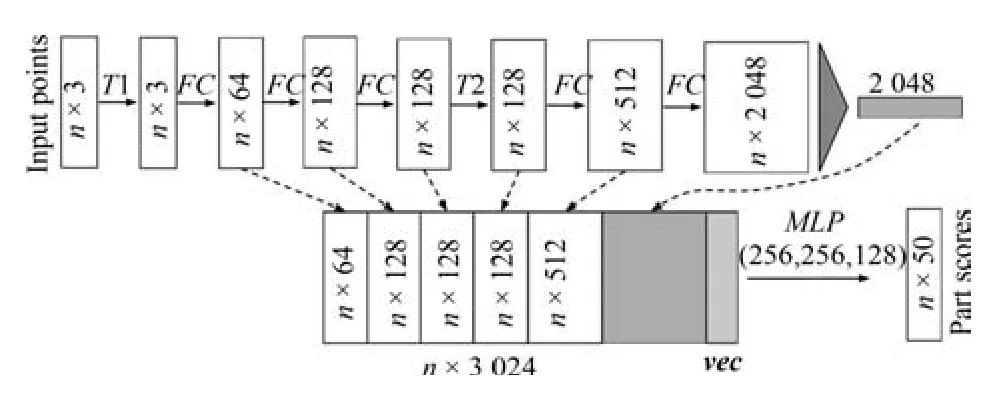
图4 本文语义分类的卷积流程Fig.4 Convolutional streamline of our semantic classification
2)本文语义复原网络从训练LS-3DDS 合成数据集中,直接学习接收域信息来获取条件概率矩阵,即在三维场景语义分类中,条件概率p(Ai|Cn)表示在语义类别Cn中出现的语义对象Ai的比率来计算概率分布
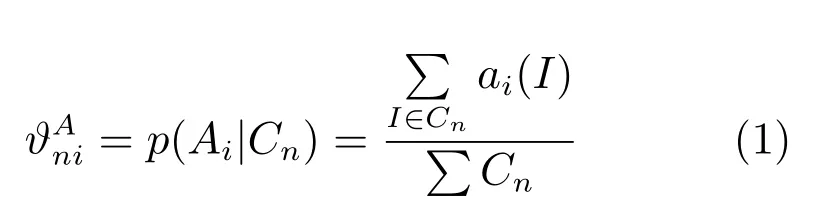
其中,Cn表示 LS-3DDS 数据集中属于类别Cn的场景个数,且i p(Ai|Cn)1.本文的三维场景语义类别个数N,对象个数为M,语义对象条件概率矩阵为N ×M阶矩阵,即这里通过计数随机事件的出现频率来估计概率分布,需要大量的真实观测数据.使用本文构建的LS-3DDS数据集训练语义神经网络模型,由于合成数据集规模较大且手动标记标签精准,使得计算得出的条件概率较准确,保证了本文语义场景复原网络的精准度,如图5 所示,接收区域的增大提高了本文网络的上下文语义识别精准度.
3)本文神经网络的池化器采用分段常值函数,定义为
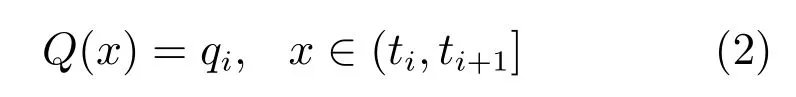
该池化器将量化间隔(ti,ti+1]内的所有x,并将其映射为量化级别qiR,其中,i1,···,m,且t1−∞,tm+1+∞.这将泛化符号函数,将其看作是1 位池化器.一个均匀池化器需要满足以下条件:
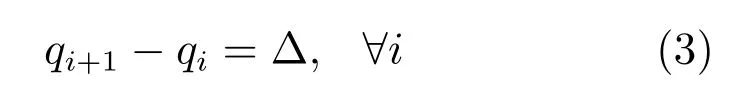
其中,∆是恒定量化步长.受精度降低的约束,量化级qi作为激励x的重构值.因为对于任意x,该池化器足以存储式(2)的量化索引i以恢复量化级别qi,所以非均匀池化器需要log2m比特的存储空间来存放激励x.然而,在算术运算过程中,通常需要超过log2m比特来表示x,并使用qi代替索引i.对于均匀池化器,∆是通用缩放因子,通常以log2m比特来存储激励x而不存索引.本文在卷积运算中也同样采用这种存储策略.
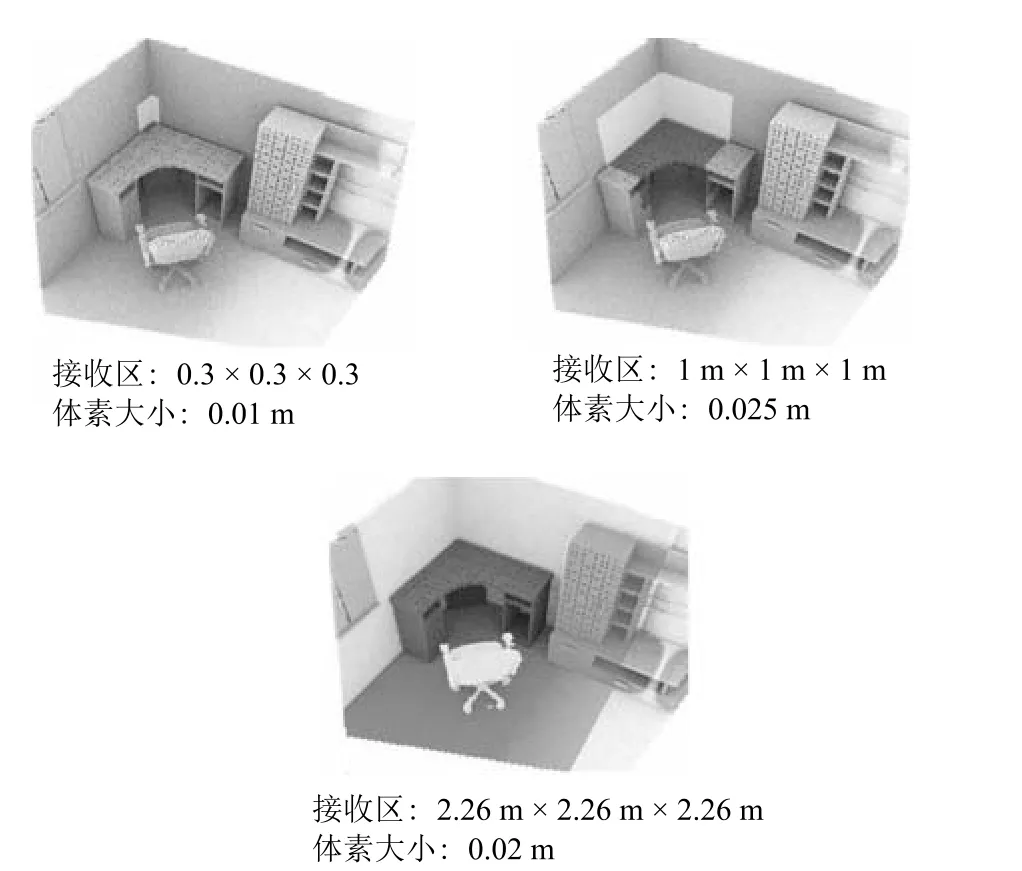
图5 本文摄像头接收范围直接影响网络性能Fig.5 Our camera receiving range directly affects performance of network
4)设计最优池化器以保证三维重建精度与语义分类准确率,需要将池化器定义在均值误差范围内,即
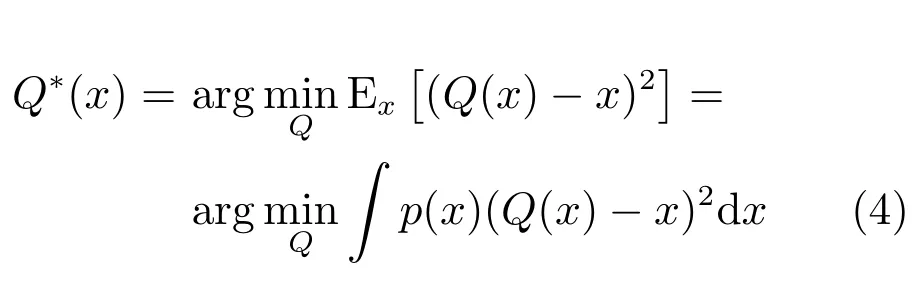
其中,p(x)是x的概率密度函数.因此,式(2)中点积的最优池化器取决于它们的统计值.虽然式(4)的最优解Q∗(x)通常是不均匀的,但通过将式(3)的约束代入式(4),可以得到均匀解Q∗(x).给定点积样本,式(4)的最优解可以通过劳埃德算法获得.这是一个迭代算法.由于每个网络单元必须设计不同的池化器,并且该池化器随反向传播迭代而改变,因此该过程的直接计算实现是较繁琐且有难度的.
5)本文使用半波高斯池化器来实现反向近似操作,通过利用深层网络激励的统计结构来的克服池化器随反向传播迭代而改变的问题.文献[23−24]证明了点积近似具有接近高斯分布的对称、非稀疏分布特性.考虑到ReLU 是半波整流器,本文使用半波高斯池化器(Half wave Gauss pool,HWGP)来实现反向近似操作,定义如下:
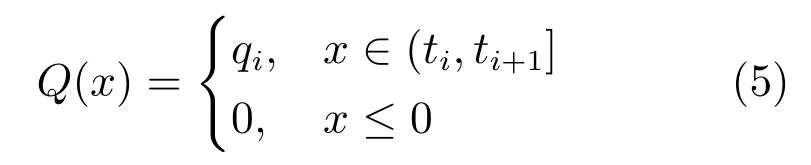
其中,qiR+,i1,···,m,tiR+,i1,···,m+1,t10,tm+1∞;qi和ti是高斯分布的最优量化参数.SGNN 保证了这些参数仅取决于点积分布的均值和方差.然而,因为这些参数在不同的单元之间变化,所以无法消除网络上劳埃德算法的重复使用.
这个问题可以通过批量归一化方法来缓解,这迫使网络的每个层的响应都具有零均值和单位方差.本文将这种归一化操作应用于点积运算,结果如图6所示.尽管点积分布不完全符合高斯分布,它们之间存在微小差异,但二者都接近高斯分布,且平均值和单位方差为零.因此,最佳量化参数和在神经网络的单元、层和反向传播迭代过程中大致相同.因此,劳埃德算法在整个网络上仅使用一次即可.实际上,由于所有分布都近似于零均值和单位方差的高斯分布,因此可以从该分布的样本中设计池化器.本文从零均值和单位方差的标准高斯分布中抽取了106个样本,并通过劳埃德算法获得了最优量化参数.在点积批量归一化之后,再将所得到的参数和用于参数化在所有层中使用的SGNN.
3 实验结果与分析
为测试本文卷积神经网络的重建精度与语义分类性能,本节采用摄像机捕获的三维场景数据以及合成数据对网络进行训练与测试.
在使用真实场景数据进行训练时,本文使用NYU 数据集训练深度卷积神经网络模型,该数据集由1 449 个RGB-D 深度图.本文针对由Guo 等[25]提出的带有几何标注的三维体积模型,捕获了大量的三维真实场景数据信息.另外,同时采用了Sun等[26]的采样策略捕获了多种三维场景对象数据.通常情况下,当语义标注信息与实际网络拓扑信息不完全对应时,数据集中的深度信息与几何信息也会出现不匹配的现象.针对这一问题,Silberman 等[3]等采用绘制RGB-D 图的方式对目标三维场景的三维物理位置信息进行标记.然而在标记的过程中不可避免的影响原有三维拓扑结构,使得三维重建场景的本地特性未能较好地保留.为此,本文结合了上述几种重建数据集的构造方式,对本文神经网络进行测试.
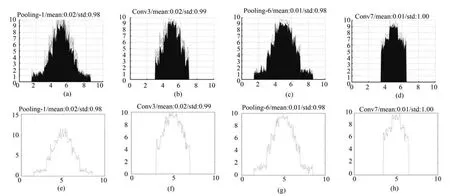
图6 带有二进制权值和量化激励的网络层点积分布图.(a),(b),(c),(d)分别为下采样层1、卷积层3、下采样层6、卷积层7 的点积分布图(具有不同的均值和标准偏差);(e),(f),(g),(h)分别为下采样层1、卷积层3、下采样层6、卷积层7 对应的点积误差分布曲线Fig.6 Dot product distribution of network with binary weights and quantitative activation.(a),(b),(c)and (d)are the point product distribution maps of the pooling layer 1,the convolution layer 3,the pooling layer 6 and the convolution layer 7,respectively,they share a different mean and standard deviation;(e),(f),(g)and (h)are the dot product error distribution curves corresponding to the pooling layer 1,the convolution layer 3,the pooling layer 6 and the convolution layer 7,respectively.
本文在表1 和表2 中展示了对神经网络性能的定量分析,同时在图7 中给出了网络的定性分析结果.在表1 中,将本文网络模型与Lin 等[12]以及Gupta 等[8]和Wang 等[21]提出的网络模型展开对比,为方便引用,文中下述段落将上述几种网络重命名为L 网、GW 网.这两种网络模型采用深度输入帧为神经网络的输入数据,同时在目标场景的体素级网络上生成语义标注.L 网采用包围盒以及超平面近似的方式标记全部体素网格.GW 网对场景进行测试的同时搜索RGB-D 数据信息,进而完成对全局场景的重建测试.以上两种网络能够在较小的训练数据集上重构精准的三维场景几何结构模型,对应关系的匹配方法较精准.与之不同,本文网络采用单一深度图作为输入,同时结合分离池化技术对特征采用关键点进行优化处理,生成细节丰富的TSDF 编码方法,另外无需附加网络来协调测试过程,提高了重建性能.因此,本文深度卷积神经网络模型能够生成更加精准的重建模型,同时保证了语义分类精度.本文深度卷积神经网络的三维场景复原精度值为30.5%,GW 网的精度百分比为19.6%.由图7 给出的重建对比图可知,这两种网络模型同时将沙发对象语义标记为床,然而,本文网络模型能够准确识别目标对象语义,并采用虚线方框来标记,本文方法的语义标记精准度更高,同时,本文网络无需对目标场景进行预处理,三维场景复原与语义分类同时完成,在保证重建精度的同时,节省了对三维目标场景的重建时间已经语义分类开销.
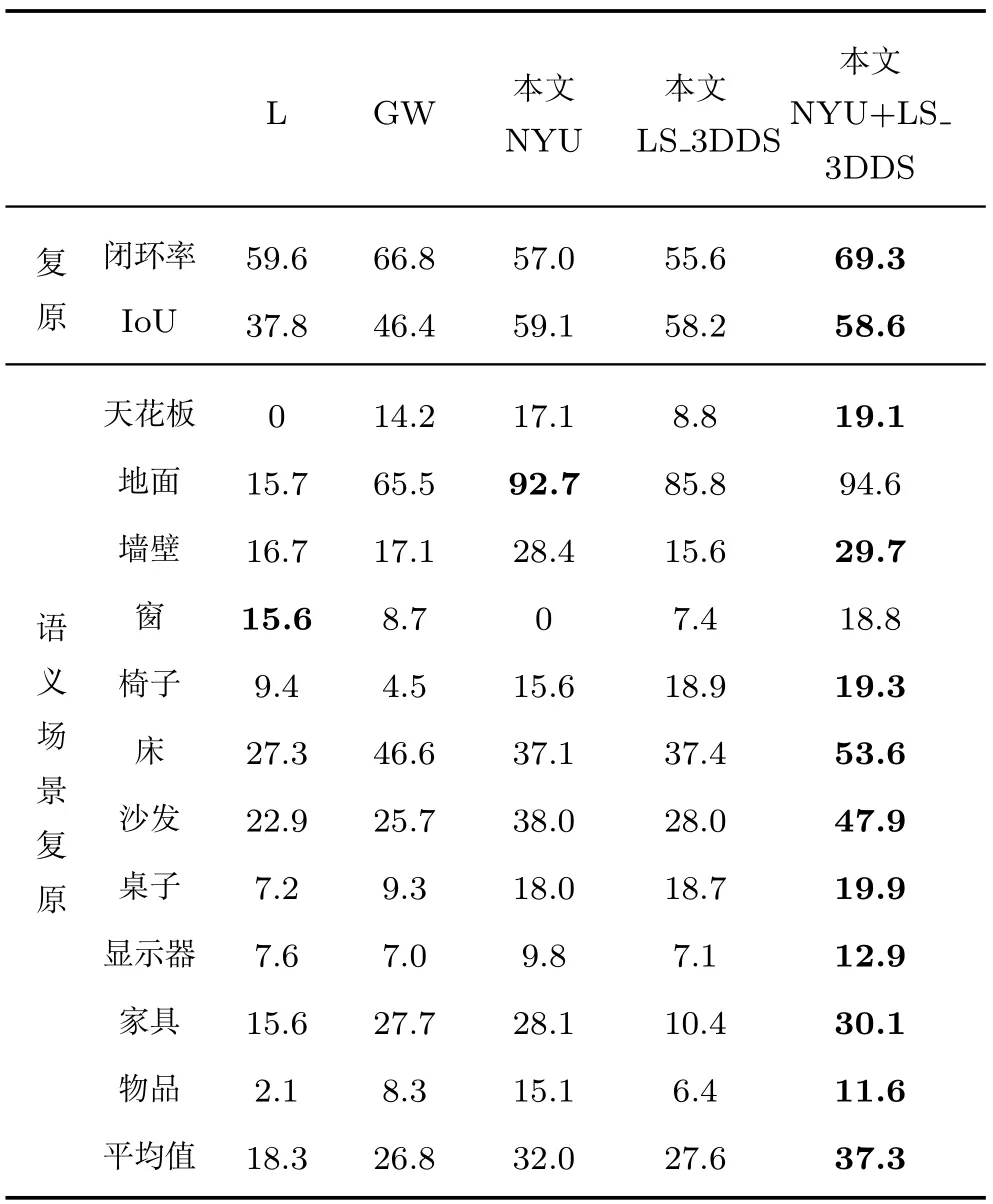
表1 本文网络与L、GW 网络的复原与分类性能比较(%)Table 1 Comparison of three networks for performance of reconstruction and semantic classification (%)
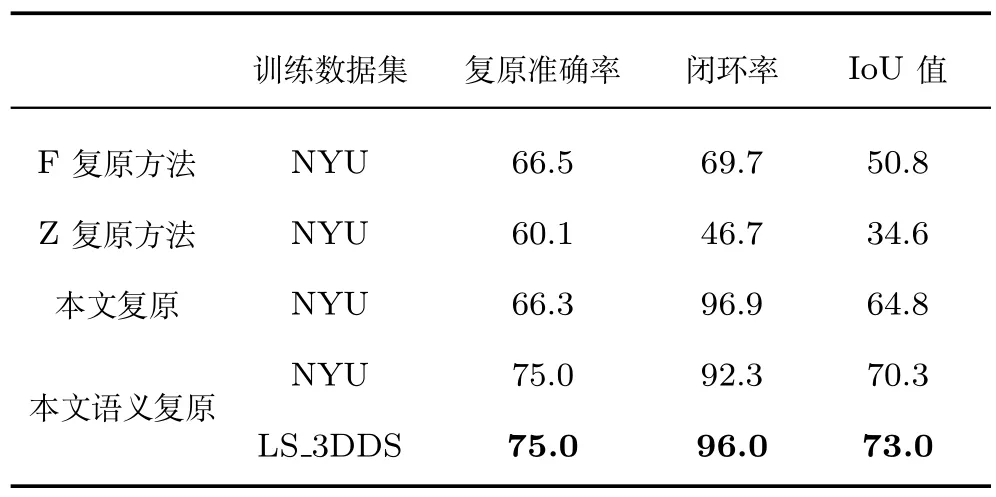
表2 本文网与F 网、Z 网的重建性能对比数据(%)Table 2 Comparison of our network reconstruction performance with F and Z networks (%)

图7 几种复原网络的可视化性能对比图Fig.7 Visualization performance comparison for several completion neural networks
本文对卷积神经网络进行训练,进而检测三维体素的空间占用比率,首先将单个体素数据进行编码,未被占用的体素用二进制字符“0”来标记,已经被占用的体素项目用字符“1”来标记.表2 给出了使用以上数据集训练完成的网络模型的性能对比数据.使用本文网络对场景进行重建复原,同时使用Silberman 等[3]和Zheng[14]等提出的网络对场景重建复原,为方便引用,文中下述段落将上述几种网络重命名为F 网、Z 网.这两种方法采用RGB-D图作为网络的输入,实现对三维场景的复原处理,然而二者皆不具有语义分类标注功能.本文网络针对上述两种网络完成了整合改进,将场景复原与语义分类融合到统一的深度卷积神经网络模型中.本文网络首先在测试阶段,采用200 张输入深度图,同时采用NYU 体系来平均本文网络的重建与分类性能.F 网实现了对大规模场景的三维重建过程,并且重建的精度较高,然而,当场景的目标语义较复杂,遮挡现象严重时,网络的重建精度受到限制,三维场景的重建效果受到影响.例如,在图7 中第4 行的椅子复原失败(如图中蓝色圆圈所示).然而,使用本文网络来重建目标场景时,由于结合了上下文语义评价体系,改善了语义重建的精准度.从本组实验结果可以看出,本文的将重建与语义分类相结合的方法,在提高三维重建精度的同时,避免了不必要的语义检测失效问题.
本文训练了一种用于三维重建与语义分类的统一架构深度卷积神经网络模型,本文对未被遮挡的场景表面几何进行具体的语义标注,同时采用联合策略对目标网络模型进行训练,并对比起重建结果.然而,当本文网络对未被遮挡的表面进行测试是,采用三维场景重建结合语义分类来训练三维神经卷积神经网络模型的效果由于仅使用几何表面语义训练的网络模型,实验结果表明带有几何标注的三维场景重建精准度为52.3%,然而,联合两种网络得到的三维场景重建精准度为55.3%.因此,本文提出的重建与语义分类相互结合的网络模型,具有互相协作相互促进的优势.
在图8 中,本文网络对未知区域的场景语义及几何形状进行了预测.当桌子场景周边的目标场景未出现在摄像头捕获范围内时,使用本文网络仍然能够较精准的预测出目标场景的上下文语义信息,从预测结果可见,本文网络的重建精度较好,语义分类预测出的对象标注信息较准确.例如,在图8 中出现的第1 张深度图中,该图中的周边对象均不可见,然而,即便信息被完全遮挡,依据本文的池化技术仍然能够精准的预测出上下文语义,扩大了语义识别的目标场景面积,本文网络的重建性能从39.0% 提高到45.3%.
图9 给出了不同体素编码方式对复原网络性能的影响.无增量卷积和带增量卷积网格具有相同数量的参数,而在带增量卷积网络结构中,三个卷积层被增量卷积取代(如图3 所示),将接收域从1.62 m增加到2.26 m (如图5 所示).增加接收区域使网络能够获得更丰富的上下文信息,并将网络性能从38.0% 提高到44.3%.将带有和不带有聚合层的两种网络进行性能比较,如图9 所示,结果表明带有聚合层的模型对场景复原和语义分类都产生较高的IoU 值,分别增涨3.1% 和2.1%.
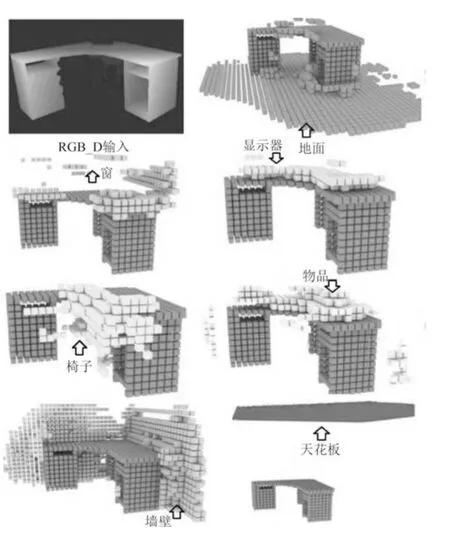
图8 本文网络预测出的周围对象Fig.8 Prediction of surrounding object by our network
图9 中给出了采用不同体素编码方式的网络性能,即投影TSDF,标准TSDF 和翻转TSDF (改进后)三种编码方式的比较.实验结果显示,使用标准TSDF 可以消除摄像机视角的依赖性,并使得IoU值提高了2.4%;而使用翻转TSDF 时,梯度变化集中在表面上,IoU 值比标准TSDF 提高了10.1%,比投影TSDF 提高了12.5%.
4 结束语
本文提出了一种基于深度图与分离池化技术的深度卷积神经网络模型,将深度图作为输入并使用分离池化方法提取深度特征,进而完成对三维场景的几何结构重建及语义分类任务.同时,构建了一种用于训练本文网络模型的三维合成数据集,增强了神经网络的学习能力.实验结果表明,本文网络兼具复原与分类功能为一体,与单一形式的网络模型相比,本文网络的重建精度提高了2.1%.本文网络采用分离池化技术及语义丰富的训练数据集,优化了传统单一类型网络的性能,实现了对三维场景的鲁棒重建与分类.
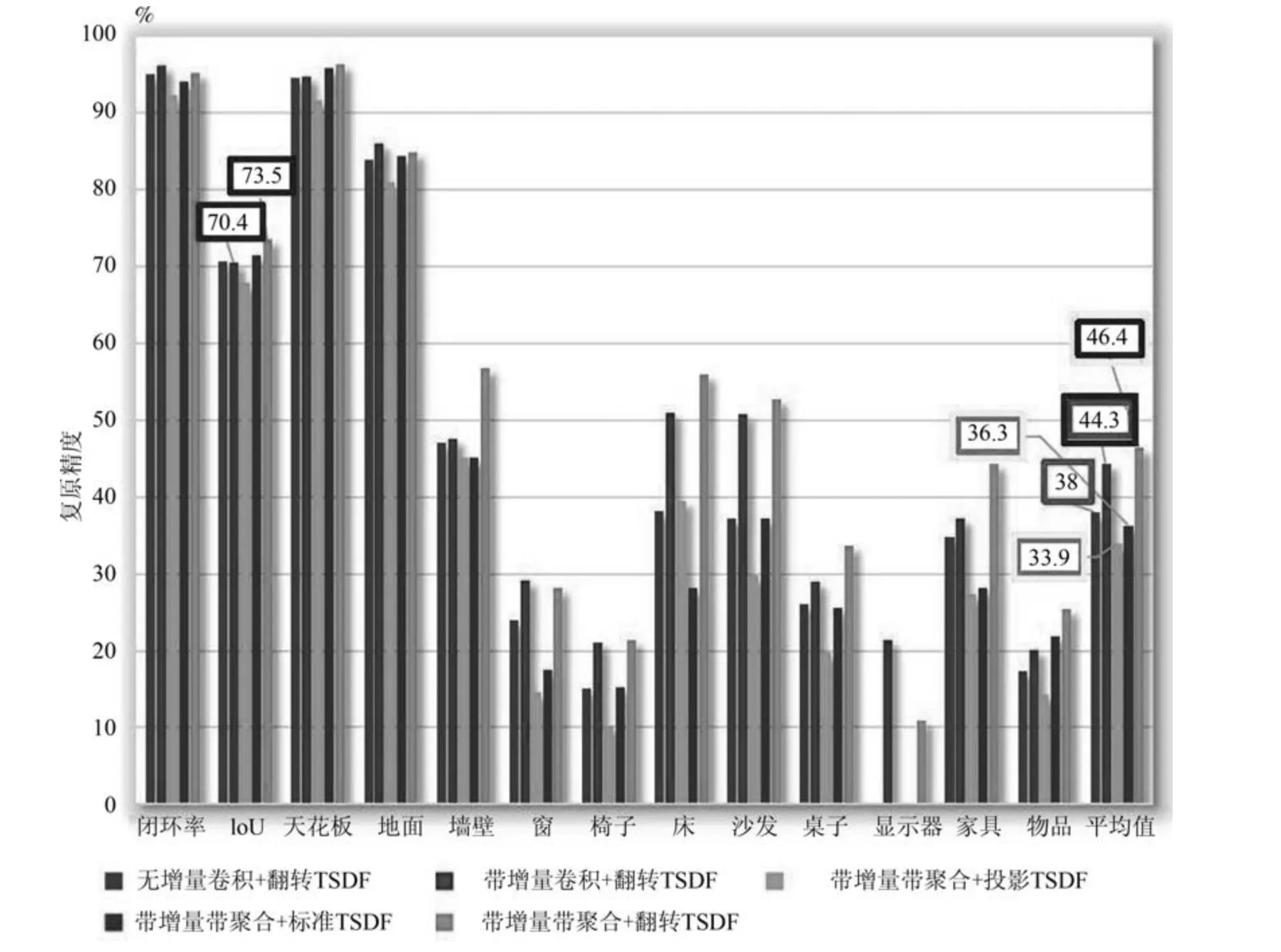
图9 改进的TSDF 编码对语义场景复原性能的影响Fig.9 Effect of improved TSDF on semantic scene completion
