基于深度学习的医疗问答系统的开发
2019-12-12姚智
姚智
江苏省南通市第一人民医院 信息科,江苏 南通 226001
引言
深度学习的历史可以追溯至20世纪40年代对控制论的理论研究,而自从21世纪初Hinton研究并提出“深度信念网络”的概念以及计算机硬件技术的发展后,研究人员已经具备了训练较深神经网络的能力,使机器学习在社会上的关注热度越来越高、应用范围越来越广。就目前来看,深度学习在医疗卫生方面中的应用研究成果主要集中于肿瘤学、病理学、罕见疾病诊断等方面[1]。作为人工智能的一个重要研究领域,问答系统在医疗方面具有不可忽视的应用潜力,然而,起步较晚各项技术还不够成熟。早期的医疗问答系统主要是利用信息检索、数据库等技术,如国外研究人员开发的MedQA[2]、MiPACQ[3]和AskHERMES[4]等系统。目前的医疗问答系统一般是基于知识图谱技术,将医疗知识信息以实体-关系的形式存储到非关系型数据库中[5],然后通过检索与推理的形式提供医疗建议,例如Izcovich等[6]设计了基于图谱化GRADE的医疗问答系统 Oyelade等[7]通过患者症状提取过程中的语义,收集信息,用于专家初步诊断。另外,近年来国内在这一方面也有不少研究成果,如颜昕[8]通过自然语言处理技术与多项机器学习算法所构建的社区健康问答系统,李超[9]利用大数据分析、深度学习技术构建的疾病导诊系统,有效地解决了患者的就诊引导问题。然而,由于汉语自然语言处理的复杂性、相关理论与工业化成果不足以及医疗类问题对错误的低容忍性,目前对医疗问答系统的研究尚待发展[10]。基于此,本文设计并实现了一种基于深度学习的医疗问答系统,通过深度长短期记忆(Long Short Term Memory,LSTM)构建了序列到序列(Seq2Seq)模型,并结合考虑了检索式回复策略建立医疗知识库以便提高回复的准确性。本文旨在推动医疗信息化相关研究及产业的发展,助力我国医疗卫生行业与人工智能技术的深度融合。
1 医疗问答系统的总体设计
本文所设计与实现的医疗问答系统选择分层风格作为体系结构,总共包括4层,自底向上依次为:数据持久层、语义层、业务功能层和前端表示层。选择分层风格体系结构的原因在于:该任务能够在不同抽象层次上进行分解、本身不存在逆向与跨层调用、良好的可复用性与内部可修改性[11]。基于深度学习的智能医疗问答系统体系结构,如图1。
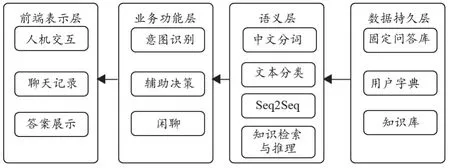
图1 智能医疗问答系统体系结构
数据持久层主要用于管理语料和知识库,为语义层提供数据检索和数据存储服务,是整个系统运行的基础。该层主要是知识库模块,封装语料存储的细节,并实现系统的数据管理。
语义层使用数据层所提供的数据管理服务,完成对语料的初步处理,实现分词、同义词扩展、相似度计算等基础性的功能。该层封装了自然语言处理中语义层面的常规操作,以便于完成高层更复杂的处理。但在该层实现的功能尚不具备业务价值。
业务功能层使用语义层提供的基础性自然语言处理(Natural Language Processing,NLP)服务,实现了智能医疗问答系统的意图识别、辅助决策、闲聊等功能,并且从该层起体现了系统的业务价值。
前端表示层通过对低层模块的逐层调用来实现系统功能,从而满足用户需求。该层主要包括系统的前端界面与人机交互等模块,它封装了用户交互,为用户提供系统前端展现并接收用户的交互行为。前端表示层是系统的最高层,也是唯一一个用户所能直接接触的层次。
2 医疗问答系统的关键技术
2.1 深度LSTM算法
神经语言模型是基于人工神经网络的自然语言处理模型,在NLP问题的研究和应用上取得了显著成果[12]。尤其是Gao等[13]提出使用递归神经网络来理解文本后,该模型在经历了不断改进之后已成为了一项成熟的自然语言处理技术。
语言信息实际上是一组序列数据,因为在文本中前一部分在一定程度上可以决定后一部分。最初研究人员使用循环神经网络(Recurrent Neural Network,RNN)来处理这种序列数据,其特点是引入了循环机制,从而实现模型不同部分之间参数在时间上的共享:

ht表示t时刻的系统状态;xt表示t时刻的输入,θ表示不变的参数。可见,某个时刻的输入被当成了下一时刻的部分参数,并在下一时刻接收新的输入,具体步骤可表示为:
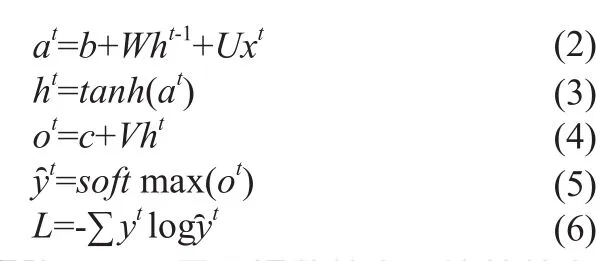
其中,向量b与矩阵W、U用于调整输入,连接输入与隐藏层;向量c与矩阵V作为隐藏层中一个结点不同状态之间的连接;激活函数softmax将输出ot归一化;L是损失函数,用交叉熵来计算。
LSTM则是RNN的一种改进模型。其改进之处在于通过引入状态属性与门限机制来避免避免梯度消失或弥散的问题。而状态属性又代替了激活层为模型引入非线性,具体计算方式为式(7)。
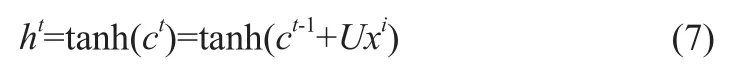
式中,tanh为双曲正切型激活函数;h表示神经网络模型中的隐藏层;c代表新引入的状态属性;x表示输入向量;U是系数矩阵;t是时间步。LSTM的神经元结构以及门限机制如图2所示。
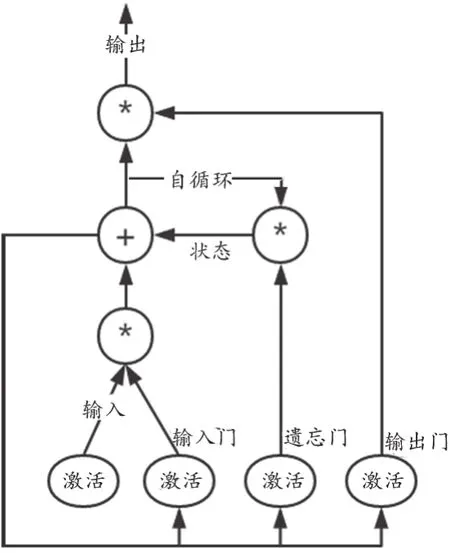
图2 长短期记忆的神经元结构与门限机制
而根据有关实验,在使用上述结构的LSTM模型时引入深度,即把较低层的原始输入转换为更适合更高层的形式[14]。本文也是采用了这种方法,将深度LSTM作为基础以构建用于医疗问答任务的序列到序列模型。
2.2 问答系统构建策略
2.2.1 基于Seq2Seq模型的生成式回复策略
本文所设计并实现的智能医疗问答系统主要使用基于LSTM的Seq2Seq模型来为患者提供回答。Seq2Seq模型实际上是一个编码-解码器结构:编码器将长度可变的数据序列转换为固定长度的向量;解码器将这个定长向量转化为变长的数据序列。不定长的序列数据被映射至高维空间后,模型的编码器将其进行规范化操作并压缩数据大小,其结果为LSTM中最后一个隐藏结点或多个隐藏层结点的加权总和。Seq2Seq模型的工作流程,如图3。
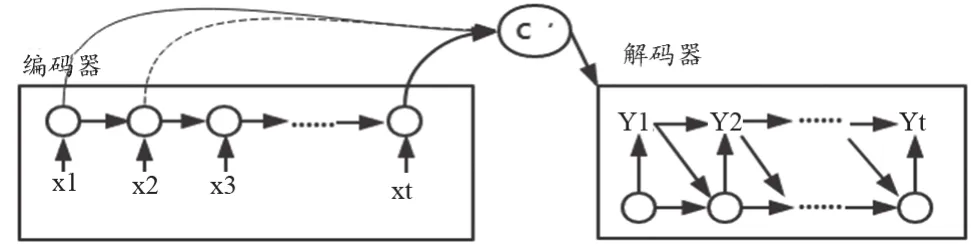
图3 Seq2Seq模型的工作流程
在实验时首先通过Web爬虫技术从各大医疗咨询网站中爬取医疗问答数据,在进行适当的清洗、切分后得到21652条问答记录作为模型的训练语料,然后通过word2index等方法实现文字向量化编码与保存,以便于训练模型。
构建该模型时使用了谷歌公司开发的Tensor flow框架来完成Seq2Seq模型的编写。该模型基于深度为4层的LSTM结构,每层包含512个神经元。使用上述处理后的语料数据进行100轮次的训练,训练过程如图4所示。

图4 Seq2Seq模型的训练过程
2.2.2 基于知识库的检索式回复策略
实际上,良好的客户服务离不开知识库的支持。基于深度学习的医疗问答系统,在生成式回复模型的基础上使用知识库可以有效提高回答的准确度。目前知识库的最新形式是智能知识库,具有结构化存储、自主学习功能和图谱化的特点[15]。建立面向医疗问答系统的知识库可以将分散于各疾病种类、医护人员、医疗资讯网站中的知识集中起来统一管理,便于用户通过知识地图和搜索引擎进行查询。
实验时使用Web爬虫技术从医疗咨询网站、百科词条等收集了大量医疗类相关信息,并将其按疾病种类、所属科室进行分类整理。为了保证知识库中信息的准确性,实验中采用人工审核的方式对其进行验证,确认无误后组织成JSON格式。以疾病“中耳炎”的JSON格式为例,总共包含18个键值对:疾病编号、疾病名称、疾病描述、标签、预防措施、疾病症状、医保状态、患病概率、易患病人群、伴随症、所属科室、治疗方式、治愈周期、治愈概率、常规概率、治疗花费、检查项目、饮食推荐,以及其对应数据。具体过程如下:{ “_id” : “5bb578cc831b973a137e47ec” ,“name” : “中耳炎”, “desc” : “中耳炎是指...”, “category” :[ “疾病百科”, “五官科”, “耳鼻喉科” ], “prevent” : “1、注意休息,保证睡眠时间...”, “symptom” : [ “耳后疼痛”,“耳痛”, “发烧”, ... ], “yibao_status” : “否”, “get_prob” :“0.9%”, “easy_get” : “无特定人群”, “get_way” : “无传染性”, “acompany” : [ “慢性中耳炎” ], “cure_department” :[“五官科”,“耳鼻喉科”],“cure_way”:[“药物治疗”,“手术治疗”],“cure_lasttime”:“7-90天”,“cured_prob”:“95%”,“common_drug”:[“阿奇霉素片”,“头孢克洛颗粒”],“cost_money”:“市三甲医院约(500~5000元)”,“check”:[“耳鼻咽喉CT检查”,“...],“do_eat”:[“鸭肝”, .. ],“not_eat”:[“田螺”,.. ],“recommand_drug”:[“当归龙荟片”,.. ]}。
传统关系型数据库可以通过使用触发器来实现知识的表示与推理[16],但这种方法需要建立和维护大量触发器,并且只能实现简单的知识表示和推理过程。而非关系型数据库则具有存储方式灵活、适当增加冗余等特点,适合于存储非结构化数据。因此本文使用了图形数据库NEO4J来构建医疗问答系统所需的医疗知识库,存储医疗信息实体以及实体之间的关系。对上述所有数据进行整理后总共得到8808个知识条目,每个条目包含的键值对数量大致在15~25对。将所有数据批量导入NEO4J图形数据库后,形成的图谱化知识库结果(图5)。
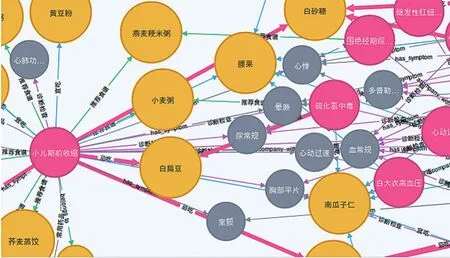
图5 医疗知识库图谱化结构
3 应用效果和数据分析
在完成系统的设计、实现以及部署等工作之后,需要对系统相关业务功能最后的实现效果以及部署上线之后用户的满意程度进行考察。首先,它作为一种问答系统应当具备使用自然语言同人类进行聊天的能力。本系统主要使用生成式以及检索式回复策略,前者是通过从大量的训练语料中学习自然语言的语法、聊天方式等特征信息,后者则是依照知识库中的实体关系进行检索与推理性回复。对此本文收集了大量医疗问答系统(测试版)在上线之后的实际问答数据,并对其进行比较分析。这些问答数据总体上可分为3个类别:闲聊类问答、知识检索类问答以及知识推理类问答(图6),以下将对其进行分析从而验证系统能否与用户进行有效交流。
(1)知识检索类问题。此时在知识库保存有能够直接回答它的相关知识数据,例如根据上文对医疗知识库建设的阐述中可知,气胸的形成原因、所属科室信息都是直接存储于知识库中。系统面对此类问题可以通过知识检索向用户提供准确的答复。
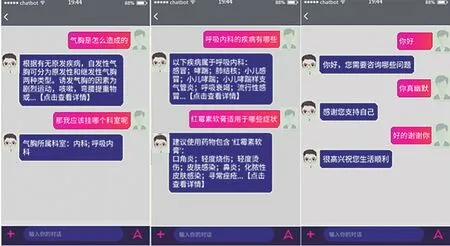
图6 系统实际应用中的三种问答类型
(2)知识推理类问题。在知识库中间接地保存有能够回答它的相关知识数据,例如在系统的知识库中没有直接存储某一种药物能够治疗的疾病种类,在面对此类问题时,可以通过知识图谱中的推理功能整合出所有推荐药物中包含红霉素软膏的全部疾病。
(3)闲聊类问题。用户并没有向系统提出医疗类的相关资讯,而是输入了其他聊天类的信息。这一类问题无法通过系统的医疗知识库来得出答案,而是通过上文提到的生成式回复策略来产生一个输出,而这种输出的准确性、通顺性与Seq2Seq模型的训练语料质量、训练轮次直接相关。例如当用户输入“谢谢你”时,系统将反馈“祝您生活顺利”,这样的答复具有典型的医疗咨询网站风格。
由于系统对用户的所有医疗方案建议都是来源于医疗知识库,而该知识库经过了严格的人工审核,因此其回答具有准确性保证。更重要的是,系统在无法向用户提供经过人工审核的信息时将以闲聊的形式与用户进行交流,这种交流并不会输出医疗方案,所以不会向用户提供错误的医疗建议,避免造成严重后果。该系统的这一特性使其在上线后得到了较好的用户评价,系统后台对于用户访问量、使用反馈等信息的统计界面如图7所示。
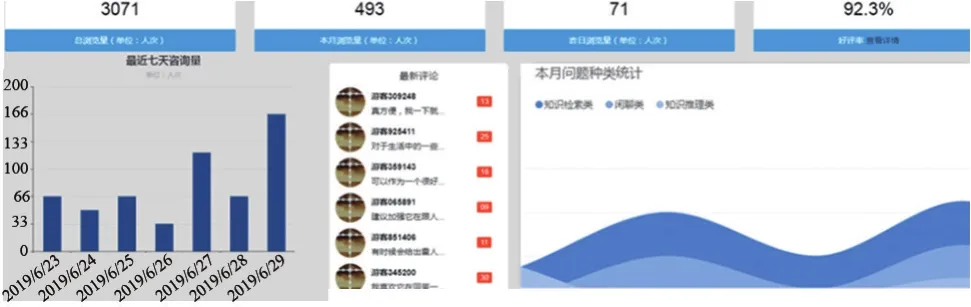
图7 系统后台流量监控界面
由图7可见,系统上线两个月后总共获得了3071人次的访问量,且个人的访问次数呈上升趋势。根据用户的反馈数据,系统的好评率为92.3%,不少用户表示使用本系统能够足不出户地享受医疗咨询服务,方便了他们的生活。
4 总结和展望
本文基于深度学习技术设计了一款智能医疗问答系统。使用基于LSTM的Seq2Seq模型实现了问答系统的生成式回复策略,从互联网上收集相关语料来完成模型训练。此外,还使用NEO4J图形数据库构建了医疗类知识库,爬取多个医疗咨询网站、百科词条等作为知识来源,从而实现了问答系统的检索式回复策略。实验结果表明,该系统能够与用户进行有效交流,为用户所遇到的医疗类问题提供相关知识介绍以及初步解决方案,为人工智能技术与医疗行业的深度融合提供了助力。
本系统在实验验证、实际使用中取得了较好的结果,然而,系统在使用过程中需要对知识库中的数据进行定期维护,这是一项较为繁琐的工作。此外,由于训练语料的质量与针对性,医疗问答系统在与用户进行交流时的语言表述能力显得较为生硬。因此,本课题在未来工作中的方向应当着力于解决上述两点问题,即改进系统的自主学习能力,并收集、编制更具有针对性的高质量训练语料。
