“互联网+查收查引服务”自动化平台的构建与优化策略研究*
2019-12-05马云辉周文云
马云辉 周文云
(苏州大学图书馆 江苏苏州 215006)
1 引言
近年来,我国高校、科研院所、企事业单位资源日益丰富,政府高度重视创新,查收查引业务越来越错综复杂。诸如苏州[1]等地区,其查引服务体量在几年内增加了数十倍,服务对象涵盖了“国家自然科学基金”“国家杰出青年科学基金”及其团队等千余个,业务量平均年增长30%以上。传统的查收查引服务模式已不能适应社会发展需要,现阶段存在的发展局限主要有:用户需求量大且多变,依靠手工检索已不能满足;没有特定的受理业务渠道;缺少统计分析,不能紧密跟踪科研评价动态;多由查新站承担查收查引服务职能,两项服务同时处于高峰委托时段,科研需求繁复多样与人力资源有限之间的矛盾凸显;用户、馆员情感体验均较差。因此,图书馆必须依靠其专业的馆藏和人才资源开拓创新。本文将从查收查引现状及存在的问题出发,结合科研需求的实际情况,研究“互联网+”业态下查收查引服务的平台开发及优化途径,旨在更好地为区域科研发展提供支撑,并为创新聚力地区图书馆在科研服务方面提供借鉴经验。
2 研究现状
我国有关查收查引方面的文献,主要集中在:①自主开发或购买查收查引系统,如北京大学马芳珍等人评价CALIS查收查引系统[2];山东大学师晓青等人设计在线查收、查引和查新检索系统[3];华北电力大学陈月从等人公开基于互联网+技术(云平台和移动终端)的自动查收查引方法[4]。②利用数据分析、文献管理等比较成熟的计算机软件,机构库自主开发查收查引软件,如中国医学科学院蒋君等人运用Excel和VBA实现论文查收查引工具[5];上海交通大学关智远等人利用Java的Word文档编辑库docx4j结合自编程序分析数据、实现报告[6];中国科学技术大学张雪娟等人将Note Express应用于查收查引[7];兰州大学刘艳民等开发基于机构知识库CSpace的查收查引功能[8]。③对查收查引服务流程或其中部分环节进行研究,如:北京邮电大学侯瑞芳等人对查收查引服务进行优化[9];西安交通大学陈伟等人基于批量处理构建查收查引报告工作流程[10]。
116所教育部认定的大学图书馆查新站中,使用Web系统处理业务的仅15所,如浙江大学、南京大学等,大部分图书馆仍采用邮件或当面受理委托单,利用手工检索完成查收查引服务。
综上所述,现有研究主要侧重于查收查引的瓶颈问题分析、提高服务质效的半自动或自动化途径研究,系统在去自引计算、调用历史等过程中多需人工干预,软件辅助不适合批量处理业务,将机构知识库与查收查引相结合的又对校外读者并不适用。因此,在探讨服务质效提升的同时,“互联网+”业态下,面向查收查引自动化服务平台开发及建立全方位优化策略体系显得尤为迫切。
3 “互联网+查收查引服务”自动化平台的构建
3.1 平台设计思路
当前,手机等智能设备给人们的生活带来了翻天覆地的变化。如果将查收查引服务以易于接受的智能终端和个人电脑都能使用的Web形式呈现给读者,仅用手机验证码或微信扫码进入,不再区分校内外读者、作者本人还是代办者,并进行更新状态的微信或短信实时提醒,将更好地满足时下人们手机不离手的社交习惯。
Web of Science等平台数据库目前都是采用IP限制用户在校园访问,使用云平台后可以不受地域限制,将读者历次提交的文献汇总建立机构库,方便检索人员、用户随时随地调用历史数据,需要增加的新文献部分在进入校园网数据库检索后补充入库,减少了每次提交、检索等大量重复工作。虽然有高校开通API接口建立本校作者成果库[11],但是该服务费用昂贵,且定期审核数据库自动推送的文献也只能覆盖校内读者,不确定的文献又需交由读者认领,这些读者是否都需要检索服务无法预知。因此,该平台开发着重于读者真实需求,建立一边高效完成服务、一边建立机构成果库的完善系统。
在查引过程中,检索人员的精力主要集中在引用部分,特别是他引的判断上,往往需要对照发表和施引文献中的作者姓名、地址字段,将自引的文献排除,一一手动甄别计算得出他引次数。当文献较多时,利用数据库分析工具,部分疑似自引的施引文献则无法关联显示,仍然需要人工计算。因此,考虑采用基于作者姓名和地址片词,将引文和发表论文中的信息进行模糊匹配计算,实现自动去除自引,提高结果的精确率。
3.2 平台体系架构
平台以用户为中心,面向两大层面:校内外读者。广泛意义上的高校图书馆员,既包括从事查收查引工作的检索员,又包含管理员以及一些需要统计分析数据的校内人员(如人事、科研等部门)。平台体系架构如图1所示。
3.3 主要功能模块设计
3.3.1 云通讯实现手机号验证码或微信登录、状态更新自动提醒

图1 平台体系架构图
现有查引平台主要采用输入用户名、一卡通、邮件和密码登录的方式[11-13],这些名称密码较为复杂,容易被遗忘。采用手机短信发送验证码、微信登录等方式,并设置状态更新提醒,能更好契合读者的使用习惯。
短信服务(Short Message Service)由阿里云提供,支持快速发送短信验证码、短信通知等,短信验证码3秒可达并采用三网合一专属通道[14],后端服务处理完成可回调通知用户,进而减少用户、Web前端和后端服务之间大量不必要的轮询请求。
微信OAuth2.0授权登录[15]目前支持authorization_code模式,适用于server端的应用。微信登录获取状态更新提醒,需将web平台嵌入微信公众号,公众号同时需被关注,或微信登录同时绑定手机。
3.3.2 利用数据库个性化功能和云平台建立作者论文、查引报告库
由于作者在Web of Science等平台数据库中收录的论文和引文信息是不断更新的,因此,系统必须根据数据变化更新作者论文库。以Web of Science为例,其提供Web of Service Lite、AMR、Web Service Premium等几种API接口[16],局限性主要在于批量查询、大规模检索、获取多个字段信息均为收费项目,查新站需定期审核论文,如不成功,还需提供Web页面交由用户认领完论文再入库。这些无疑都不能按读者真正所需定向服务。
鉴于上述考虑,系统采用Web of Science等平台自带的个性化功能和论文标准导出格式,在完成查引工作的同时,租用云平台来完成论文库、报告库的搭建。在作者下一次请求查引、更新论文时,在原有论文库的基础上,只需手动进入数据库网站,将新发表需要补充的论文、引文,按规范格式下载并导入系统,同时完成查引服务和论文、报告库的更新。
进入Web of Science等网站时,查新站可免费注册若干公共的账号密码,在校园网内,检索员仍登录该账户使用其定制功能,可将每位作者不同检索日期的论文保存在数据库的云端,再次登录时,随时调用获取标记结果,亦能在线增减、新建论文,引文也随着数据库定时更新,可任意下载。以SCIE为例,其个性化调用云端结果、论文及引文的标准输出格式如图2和图3所示。

图2 SCIE个性化定制调用云端历史

图3 SCIE论文和引文的标准输出格式
检索完成后,将论文集、查引报告集按作者信息布置在云平台上,用户在任何有网络的地方都可以调用历史论文和检索报告,之后再决定是否进行新的查引申请。系统搭建使用阿里云负载均衡服务SLB、内容分发网络CDN、云服务器ECS、对象存储OSS、云数据库RDS、云盾和云监控等[17],如图4所示。ECS、SLB负责对外http服务,CDN承担静态请求,云数据库RDS存储作者、论文及引文信息,OSS存储报告文件等数据,在云盾、云监控的安全防护之下,可自动防御异常网络攻击。对数据库网站获取到的论文和引文,经与SCIE、EI等不同数据库、作者匹配分类,存放于论文库中,当读者、检索员请求数据时,匹配其作者和数据库信息,返回结果。对系统自动生成的查引报告也是相同方法处理。
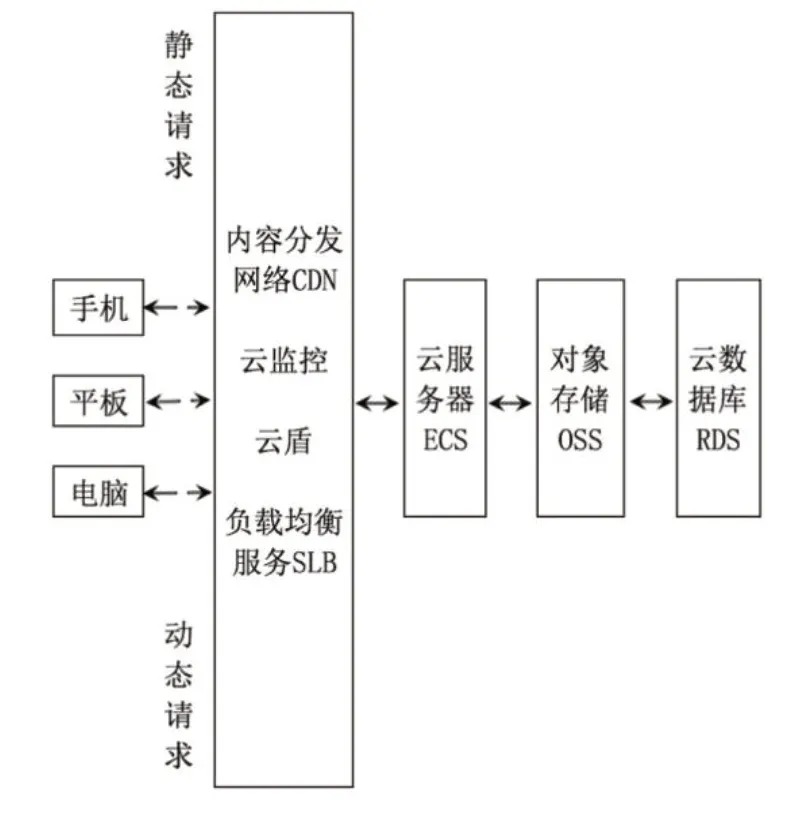
图4 云平台建立作者论文、查引报告库
3.3.3 基于片词的模糊匹配算法自动去自引
传统的查收查引过程中最费时费力的当属去自引计算,需要一一比对每篇论文和施引文献中的作者,部分文章的作者多达数十人。而Web of Science的分析工具,最大作者显示数仅500条。施引文献及其作者较多时,为达到精确去除自引的目的,只能靠肉眼逐个作者甄别,结果准确性很大程度上依赖于人工。
去自引的焦点问题还在于作者名在中英文表达方式上的差异。中文作者名的英文表述方式存在多种形式,如:张三,拼音表达可能存在ZhangSan、ZhangS、Sanzhang、San Zhang等,而字数在两个以上的姓名的拼音表达可能性要增加更多。因为时间节点的不同,作者地址存在变动,同一作者名有可能存在多个单位的情况,同一单位也可能存在多个表达方式。只有将作者名和地址一同判断,才有可能保证其结果的正确。
针对以上问题,平台采用基于片词的模糊匹配算法,将论文和引文标准文档内的作者、地址字段分割对比,自动去除自引。
以模糊数学为基础的模式识别方法称为模糊模式识别。模糊理论最早是由美国自动控制学家拉特飞·扎特于1965年提出[18-19]。模糊模式识别主要包括三步[20]:提取特征,首先从识别对象中提取与识别有关的特征,并度量这些特征。设X1,X2,……,Xn分别为每个特征的度量值,于是每个识别对象X就对应一个向量(X1,X2,……,Xn);建立标准类型的隶属函数,标准类型通常是论域U={(X1,X2,……,Xn)}的模糊集,Xi是识别对象的第i个特征;建立识别判决准则,确定某些归属原则,以判别识别对象属于哪一个标准类型。
基于片词的模糊匹配算法具体是将姓名和地址分别做片词分割,然后计算各自与标准姓名和地址片词之间的距离dn和da,通过加权求和每个片词的距离得到匹配度mn和ma,分别和两个阈值作比较,最终得出是否匹配成功的结论,以确定是否为自引。其中,是每个片词的权值,权值大小的调整则取决于每个片词在整个姓名或地址中的重要程度,具体如图5所示。

图5 基于片词的模糊匹配算法自动去自引
以单篇文章引用数量较大(超过500条)为例,平台自动上传作者被收录和引用的论文,输入需要排除的第一作者英文姓名后开始解析。如图6所示,基于片词的模糊匹配解析实现了PDF文本的提取,分词器将作者姓名、地址信息切分为英文语义的词,存入索引。输入筛选条件“Huang ZhaoHui”,对索引进行检索,得到与该作者片词相匹配的结果集。解析结果共包括3种:姓名相同,地址完全相同;姓名相同,地址部分相同;姓名相同,地址不同。该篇论文的第一作者单位并未变动过,所以只呈现姓名相同(地址完全相同)的自引解析结果。根据该结果,系统可统计该单独作者的自引数,再经提取到的总引频次数值减除后得到他引次数,即排除掉论文作者本身的引用——自引。
系统在识别自引和他引问题上,除作者姓名外,将作者地址变动也考虑进去,必要时可进行人工干预,核查疑似匹配结果,提高去除自引的准确率(99.99%)。作者和论文数量越多,该方法优势越明显,耗时(秒/分计)远低于人工检索方式(时计),且准确性能得到有效保证。

图6 自引解析实例
4 “互联网+查收查引服务”自动化平台的优化策略
在互联网+技术高速发展、区域查收查引服务体量增长迅速、科研需求繁复多样的大背景下,“互联网+查收查引服务”自动化平台的开发势在必行,经过业务实践、读者反馈、数据分析的反复论证、评估,基于以上平台,制定了互联网+环境下的优化服务策略,即构建平台技术、平台访问、用户、区域合作、资源等层面优化的有机整体(如图7所示)。

图7 互联网+环境下的优化服务策略图
由图7可见,与以往系统相比,基于该平台真正实现了查收查引服务优化的良性循环:①在平台使用上,其可用性增强。PC和移动终端都能访问,改变了只能在PC访问的方式;无需注册,只需手机、微信验证登录即可;平台界面实时浮动语音、微场景、微视频、客服机器人、人工客服等多种形式的使用指导,状态更新又可自动跟踪推送到读者登录使用的手机或微信,减少了检索员重复解答、读者多次咨询的环节;②在技术实现上,关键环节的人工干预显著减少,论文和报告可重复利用,不再受IP限制。可在短时间内将海量电子论文的作者、地址字段同时进行配比自动去自引,结果准确,替代了大量繁复的手动计算,减轻了量大多变的业务压力;租用云平台建立了对应作者姓名、地址信息的论文、查引报告库,读者和工作人员均可随时随地调用历史论文和报告,减少读者反复提交、工作人员多次重复核实检索论文的过程;在利用好历史论文、报告的基础上,如需增加新论文和引文,才涉及到人工从校园网进入数据库检索的部分,且平台中的新文献提交具有选项提示,避免出现读者提供的论文清单常常与数据库标准格式存在差异、需要手动纠正等问题;③在功能上,更加完善。平台结合后台数据的可视化分析工具,能紧密跟踪科研和读者动态,为制定真正契合用户需要的服务优化策略提供量化依据;业务受理高峰期,系统实时显示接待状态,可自动为读者推送分流建议,通过区域合作、资源共享等层面的优化减轻接待压力。但仍存在一定的发展空间。读者发表论文、引文等更新数据需要在完成查引检索后,批量对应上传至系统进行去自引分析,结果的准确性主要依赖于初始数据。原始数据的获取主要有在线导出和读者提供等形式,读者提供需要数据库标准导出格式的文件,这一工作目前在选项提示、使用指导、微传播中推广,推广效果受到读者认知能力的影响,格式如不准确仍需检索员手动操作,但实际也已经减少了大部分历史论文查询的工作。
5 结语
“互联网+查收查引服务”自动化平台的构建与优化策略较为科学。高校图书馆可立足科技查新站,依托自动化平台,提高服务质效,实现动态调整服务方案的科学化和智能化,并能兼顾地区科研创新聚力的发展需求。将来还可尝试通过其获得的数据建立模型,分别进行打分,再根据得分进行参考决策,实现服务方案的自我优化管理。
