灰色GM(1,1)模型的拓展及其应用
2019-11-25史国军程毛林
史国军,程毛林
(苏州科技大学数理学院,江苏苏州215009)
现如今,随着时代与科技的发展,信息的变化也日新月异。而通过现有的信息来对未来的发展趋势做出推测与估计,即为统计预测。目前常用的预测模型主要有:多元线性回归[1]、时间序列预测[2]、贝叶斯预测[3]等。在20世纪80年代,邓聚龙教授提出的以“少数据”、“贫信息”的不确定性系统为基础的灰色系统理论之后,更是将统计预测推向了新的高度。在短短的二三十年间,灰色系统理论亦被广泛运用于经济预测[4]、综合评价[5]、环境污染[6]、能源预测[7]等方面。
灰色GM(1,1)模型作为灰色系统理论的基本模型之一,越来越受到人们推崇。因此,近些年来,一些专家学者对GM(1,1)模型进行了研究与优化。程毛林[8]运用三和法和三点法以平均相对误差绝对值最小准则对时间响应函数的初始值进行了优化;徐进军等人[9]给出了一种新的基于一次累加序列约束和基于原始序列约束条件下积分参数的确定方法;何文章等人[10]运用线性规划来代替最小二乘法对模型参数进行了求解;王国兴[11]通过指数变换对原始数据的光滑度进行了优化;段智力等人[12]通过对背景值权进行了优化;卢懿等人[13]通过加入调节因子λ来优化了背景值的公式;王瑞敏等人[14]通过向前差商和向后差商的加权平均值来优化了模型的灰导数;何霞等人[15]通过全最小一乘准则代替最小二乘法来进行了参数估计;彭正明等人[16]采用积分优化、二次拟合优化以及残差改化方法,分步对GM(1,1)模型进行改进,建立灰色多重修正模型等等。然而该文既不是对原始数据进行优化,也不是对背景值和参数估计方法进行优化,而是对GM(1,1)模型的白化方程进行非线性的修正,旨在能够更加贴合数据的非线性变化趋势,也能够更好地提高预测精度。
1 模型的建立
1.1 传统灰色GM(1,1)模型
传统灰色GM(1,1)的模型原理[17]主要为:对原始数据进行一次累加之后使其满足指数的性质,然后对累加数据进行一阶微分的求解,通过最小二乘法确定解中的未知参数,最后求出的结果通过累减再还原成人们所想要的灰色预测值,从而通过预测值来对未来进行预测。其原理实现主要可以分为以下几个步骤:
第一步设原始时间序列为x(0)=(x(0)(1),x(0)(2),…,x(0)(n)),其中x(0)(k)≥0,k=1,2,…,n;x(1)为x(0)的1-AGO序列,即
第二步建立灰色GM(1,1)模型的白化微分方程,也称为影子方程

其中,a称为发展系数,b称为灰色作用量。但此白化方程本质上只是一个一阶微分方程。因此,可以解得白化方程的通解为:x(1)(t)=Ce-at+b/a,其约束条件为经过原始序列的第一个点,即t=1时,取x(1)(1)=x(0)(1),代入通解可得C=[x(0)(1)-b/a]ea,将C代回白化方程的通解则可得到灰色GM(1,1)模型的时间响应方程为

第三步需要确定时间响应式中的参数a和b才能具体求出预测值(1)(t)。下面需要用到GM(1,1)模型的灰微分方程

其中z(1)(k)=(1/2)(x(1)(k)+x(1)(k-1))称为背景值。通过灰微分方程的最小二乘法来参数估计为

其中
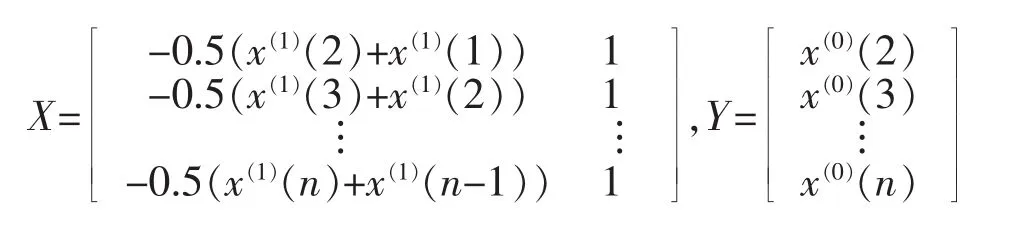
第四步在计算出a和b后代入时间响应方程就能够得到(1)(t)的预测值。但计算出来的(1)(t)是累加过后的预测值,所以需要对它进行累减来还原到原始序列的预测值

1.2 灰色GM(1,1)拓展模型
对于一个累加序列而言必然是递增的一个序列,但这种递增并非线性的,而是非线性的。因此,笔者旨在改变白化方程的结构,在其中加入一项非线性的序列修正项来对时间响应式进行修正,从而希望得到更高的预测精度。接下来将介绍一种笔者发现的序列修正项。
1.2.1 灰色作用量为指数的GM(1,1,dt)模型
区别于传统的灰色GM(1,1)模型,将白化方程修正为

因此,也将修正后的模型命名为灰色GM(1,1,dt)模型。易见当c=0时,该模型即为传统的灰色GM(1,1)模型。通过对上述的一阶微分方程求解,可得到修正后的白化方程的通解为:x(1)(t)=De-at+b/a+(cdt)/(a+ln(d))。同样的约束条件为经过原始序列的第一个点,即t=1时,取x(1)(1)=x(0)(1),代入通解可得:D=ea(x(0)(1)-b/a-(cd)/(a+ln(d)),将D代回修正后的白化方程的通解则可得到灰色GM(1,1,dt)模型的时间响应方程为

1.2.2 灰色GM(1,1,dt)模型的参数估计
已知灰色GM(1,1,dt)的白化方程为通过对白化方程求积分可得



此即为灰色GM(1,1,dt)模型的灰微分方程。仿照传统的灰色GM(1,1)模型,令z(1)(k)=(1/2)(x(1)(k)+x(1)(k-1)),此时称之为灰色等权GM(1,1,dt)模型,如果指数项dt的参数d已知,则可进行参数估计

其中
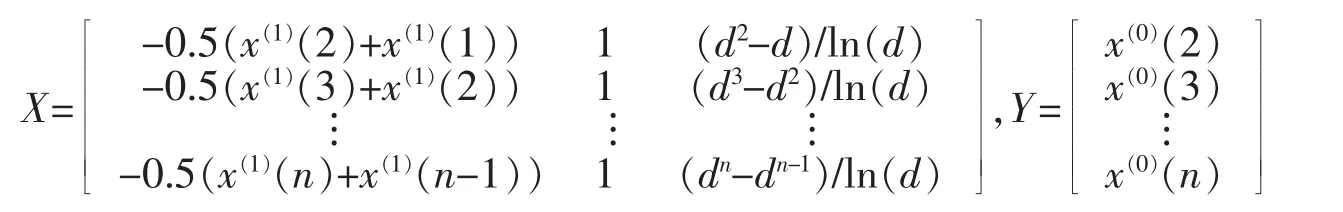
在计算出参数a、b和c后将它们代入时间响应方程就可得到累加序列的预测值(1)(t),然后进行累减得到原始序列的预测值
同样的,对灰色不等权GM(1,1,dt)模型进行参数估计

其中

同样的,在计算出参数a、b和c后将它们代入时间响应方程就可得到累加序列的预测值(1)(t),然后进行累减得到原始序列的预测值
1.2.3 两种灰色GM(1,1,dt)模型的参数确定
对于灰色等权GM(1,1,dt)模型,需要确定参数d就可以进行参数估计,进而得到具体的时间响应方程来进行预测,可以用最优化的方法来确定参数d。在此可以给d设置一个合理的定义域[1,2],因为在2以后的指数dt增长速度太快,这对于大部分序列预测来说都是不合理的。具体的目标函数及约束条件如下

对于灰色不等权GM(1,1,dt)模型,这比灰色等权GM(1,1,dt)模型要稍微复杂一点,需要确定参数d以及不等权系数α才能进行参数估计,但依旧可以利用最优化的方法,但约束条件要更严格一些。其具体的目标函数及约束条件如下

以上是对传统的灰色GM(1,1)模型以及拓展的灰色GM(1,1,dt)模型的系统介绍,下面将模型应用到具体的实例中,通过比较不同模型间的模拟和预测精度来说明模型间的优劣程度。
2 应用实例
国内生产总值(GDP)是指一个国家在一定的时间内生产的全部最终商品和服务价值的总和,同时也是国民经济核算的核心指标,更是衡量一个国家经济状况的重要指标,因此,预测我国GDP的增长对我国的经济体系研究有着重要的意义。在此,文中选取了2005年到2017年13年间的GDP数据(所有数据皆来自于国家统计局的《2018年统计年鉴》)为基础来进行实例说明,以2005年到2014年10年的数据来进行拟合,以2015年到2017年3年的数据来进行预测。我国的国内生产总值记为x(0)(t)(亿元),模拟结果见表1、预测结果见表2。
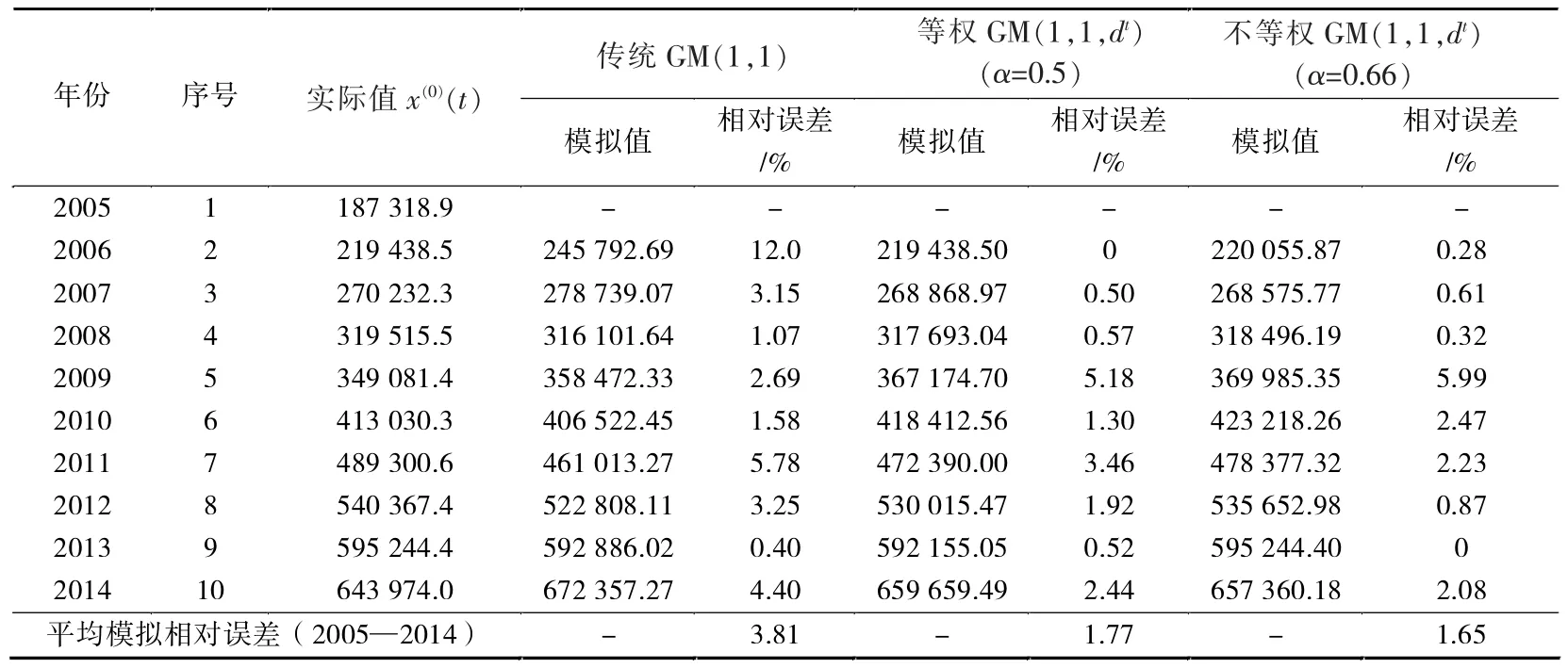
表1 我国国内生产总值灰色模拟结果 /亿元

表2 我国国内生产总值灰色预测结果 /亿元
建立传统灰色GM(1,1)模型,可得:a=-0.125 8,b=207 095.44。其时间响应方程为

建立灰色等权GM(1,1,dt)模型,可得

其时间响应方程式为

建立灰色不等权GM(1,1,dt)模型,可得

其时间响应方程式为

比较模型精度的好坏主要是比较误差的大小,为了更直观的表现结果,将以画图的形式来说明表1和表2中三个模型的优劣程度,如图1所示。

图1 三种模型的误差对比直方图
图1分别比较三种模型在平均模拟相对误差、平均预测相对误差、整体平均相对误差下的精度大小,可明显看出模型的精度排列为:灰色不等权GM(1,1,dt)模型>灰色等权GM(1,1,dt)模型>传统GM(1,1)模型。文中所提出的拓展模型相比较传统GM(1,1)模型来说,拟合效果良好,预测精度有着很大的提高,其中尤以灰色不等权GM(1,1,dt)模型效果为最好,可以适用于经济预测。
3 结语
文中先是对GM(1,1)模型做了详细的介绍,然后通过GM(1,1)模型引申出了其拓展模型GM(1,1,dt)。并同时给出了等权与不等权GM(1,1,dt)模型的白化方程、灰微分方程、时间响应方程以及参数估计方法。最后,通过对2005年到2017年的国内生产总值数据分段进行了模拟和预测,最后发现等权GM(1,1,dt)模型与不等权GM(1,1,dt)模型两者相比传统GM(1,1)模型来说在经济预测方面的精度有很大提高,两者中以不等权GM(1,1,dt)模型的精度为最高。因此,文中也以不等权GM(1,1,dt)模型为基础预测了2018年和2019年的国内生产总值分别为:935 611.47亿元和1 013 862.33亿元。尽管不等权GM(1,1,dt)模型的经济预测精度要比传统GM(1,1)模型高,但仍然存在着5%左右的误差,或许可以通过优化背景值来尽可能的降低预测的误差,这依然是笔者今后要研究的方向。
