基于ATT-IndRNN-CNN的维吾尔语名词指代消解
2019-10-21祁青山田生伟艾山吾买尔
祁青山,田生伟,禹 龙,艾山·吾买尔
(1. 新疆大学 软件学院,新疆 乌鲁木齐 830091;2. 新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
0 引言
指代(anaphora)是在自然语言中常见的一种语言现象,在篇章中通常利用一个抽象的词语代替前面的某个具体的词语。语言学中将抽象的语言单位称为照应语(anaphor),而具体的实体称为先行语(antecedent)。确定某个照应语的先行语的过程称为指代消解[1]。指代消解对于自然语言处理(natural language processing,NLP)研究中的机器翻译(machine translation)、信息抽取(information extraction)、自动文摘(automatic abstracting)以及自动问答(question answering)等自然语言应用系统都具有非常重要的支撑作用[2]。指代消解分为指代(anaphora)和共指(coreference),回指也称为指示性指代,是当前的词语与上文中出现的具体的词语具有密切联系;共指也称为同指,是两个具体的词语对应于现实世界中共同参照物的指代[3]。
指代消解发展的几十年来,已经从基本的基于规则的研究方法逐渐过渡到机器学习的研究方法中。McCarthy[4]等首先提出将指代消解改成二分类问题,在候选先行语中判断与照应语是否具有紧密的联系,进而判断是否具有指代关系。Soon[5]等在此基础上提出使用机器学习进行指代消解的研究框架并给出了可用的系统。他们在语料中提取12种特征作为分类的标准,再利用支持向量机对其进行训练得到分类模型。这一思想影响了后期大多数学者的研究。Ng[6]等在Soon的基础上将特征扩充成53种;Yang[7]等提出了一种双候选模型,可以更好地确定照应语对应的先行语;Kong[8]等把中心理论应用到语义层,提高了指代消解的性能。在中文指代消解中,郭志立[9]提出了利用人称代词本身的语义信息等进行人称代词先行语的分析;马彦华[10]等采用了一种 “主题人物法”的方法来解决中文的人称代词消解问题;许敏[11]等利用上下文中的语义信息进行指代分类;王厚峰[12-14]等对汉语的指代消解有较多的研究。但是对于像维吾尔语这种小语种的研究较少,主要有李冬白[15]等提出了一种基于DBN深度神经网络学习模型的方法对维吾尔语的人称代词进行消解;李敏[16]等提出了一种基于栈式自编码深度学习的维吾尔语名词消解方法。
随着研究不断深入,研究者们发现对于特征给予不同的关注程度可以更好地进行分类,并且在篇章中上下文信息对于指代消解也具有极其重要的作用。此外,目前的研究大多都集中于中文和英文,针对维吾尔语这种语料资源匮乏的小语种的研究非常少,并且将深度学习用到维吾尔语的名词指代消解中的研究也很少。基于上述问题,本文提出一种基于注意力机制、独立循环神经网络和卷积神经网络相组合的方法,用于维吾尔语的名词指代消解。在该方法中先利用注意力机制作为模型特征的选择组件计算特征的权重,使得特征与消解结果的联系更加紧密。再利用独立循环网络和卷积神经网络分别得到全局特征和局部特征,并将这两种特征进行融合,在得到上下文信息的同时又不丢失局部信息,可以得到更好的分类结果,提升维吾尔语名词指代消解的性能。
1 相关知识
1.1 指代消解
指代消解是自然语言中的一个语言单位用于确定其指向之前出现的语言单位的过程。其中用于指向的语言单位,称为照应语(anaphors),被指向的语言单位称为先行语(antecedent)。根据消息理解会议(Message Understanding Conference,MUC)对指代的定义,认为指代关系不仅仅存在于代词与名词(名词短语)之间,还存在于名词(名词短语)与名词(名词短语)之间。例如,
例1

(最终有一天,我收到了母亲一封奇怪的信,这封信是寄给姐姐阿依努尔的。为了读母亲给她写的这一封完整的信,就需要我必须跟姐姐见一次面)

1.2 维吾尔语的特点
维吾尔语是一种带格语法的黏着性语言,词组与句子之间有严格的词序,并且拥有“格”结构。这种“格”结构对于指代消解工作起到非常重要的作用,利用维吾尔语的格语法可以判断词语的词性等重要内容。在维吾尔语中一般认为有6种格,具体如表1所示。

表1 维吾尔语的格

续表
维吾尔语中的名词存在单复数变化,可以将名词单复数作为一个非常重要的特征,判断是否具有指代关系,排除不存在指代关系的样本,这也为维吾尔语名词的指代消解提供了较好的基础。
2 模型介绍
针对维吾尔语名词指代消解问题,本文利用Soon[5]等提出的框架,首先确定照应语的候选先行语,提取名词短语的特征,再引入注意力机制(attention)赋予特征权重,将得到的带权特征分别输入到独立循环神经网络(IndRNN)模型和卷积神经网络,得到包含上下文信息的全局特征和局部特征,最后将得到的全局特征和局部特征进行融合,放入Softmax中训练分类,模型如图1所示。

图1 维吾尔语名词短语消解框架
2.1 特征提取
在自然语言处理中特征提取是一项非常重要的工作,提取的特征是否具有代表性和通用性直接决定了最后实验结果的好坏。而特征提取在指代消解中起到的作用更大,因此本文结合实验组维吾尔语言学专家总结的具有指称性的名词短语以及前人的经验选取以下特征进行指代消解。
2.1.1 规则特征
规则特征是根据语言内部结构规则进行提取的特征,主要体现先行语和照应语在文章内部的关系,本文主要提取了17种规则特征,具体如表2所示。

表2 规则特征

续表
2.1.2 语义特征
在指代消解工作中,提取规则特征虽然可以进行消解工作,但是缺少对整个句子语义的考虑。因此本文采用词向量的方式将先行语和照应语在句中深层次的语义特征表现出来。为了避免维度灾难,本文采取了Mikolov等[17]在2013年提出的Word2Vec工具进行词向量的训练。同时为了准确得到词语在多维空间中的语义分布情况,对原有语料进行了扩充。利用爬虫从人民网和天山网等网站的维吾尔语板块爬取维吾尔语文本,并进行简单降噪处理,得到8 000篇未标注的生语料文本,经过分词处理后得到1 003 267个分词数据,与实验语料进行结合,训练照应语和先行语的语义特征。
2.2 训练和测试样本构成
本文将语料文本进行预处理,再经过维吾尔语言学专家对语料库进行词性和相应的指代链标注。通过对进行标注的照应语在句子中出现的位置提取上下文的名词构成候选先行语集合,再将其遍历,判断是否是该照应语的先行语,若是则形成正例样本,否则形成负例样本。具体算法为:
Step1提取单个文本中所有的名词短语,根据标注判断是否为照应语,若是,则存入集合{anaphors},否则存入集合{nouns}中。
Step2遍历集合{anaphors},将每一个照应语anaphor与集合{nouns}中每个元素noun进行对比,若两个元素属于同一指代链,则将标签标记为1,作为正例;否则将标签标记为0,作为负例。同时根据2.1.1节中表2中所提到的特征,读取文本中这两个元素的信息,进行对比,构成样本。
Step3重复step1、step2,直到将所有的语料遍历一遍。
通过上述算法得到全部样本,并且将其中的80%作为训练数据集,20%作为测试数据集。
2.3 ATT-IndRNN-CNN
ATT-IndRNN-CNN模型结合注意力机制与两种不同的神经网络,可以有效地将全局特征与局部特征进行组合,该模型对数据处理主要分为3个阶段: 首先利用注意力机制强化特征,然后将处理后的特征分别输入IndRNN和CNN得到全局特征和局部特征,最后将全局特征和局部特征进行融合,形成新的特征,输入Softmax进行分类训练。模型总框架如图2所示。
2.3.1 注意力机制(ATT)
注意力机制最早是在图像处理中的被提出来的,Mnih[18]等将之用于图像分类的同时Bahdanau[19]也将其用到了机器翻译之中。本文中利用注意力机制主要是将不同的特征赋予不同的权重,以便更好地进行模型的训练。在注意力机制中将输入特征Data看做由
其中,La为Data的长度,aj为valuej对应的权重系数,aj求解方式如式(2)所示。
利用Softmax对Q和各个Key之间相似度数值进行归一化,同时也利用Softmax内在的机制突出重要成分的权重,而Q和各个Key之间相似度计算通常通过计算两者之间的点积来得到,如式(3)所示。

图2 ATT-IndRNN-CNN模型
通过上面一系列的计算可以得到特定元素Q的Attention数值。将得到特征经过注意力机制可以突出其中某些特征权重信息,进而可以更加有效地进行分析。
2.3.2 独立循环神经网络(IndRNN)
独立循环神经网络是由Li等人提出的一种新型循环神经网络[20],这种新型循环神经网络可以有效地解决普通RNN在训练收敛时存在的梯度爆炸和梯度消失的问题,同时可以处理更长的序列。其基本计算如式(4)所示。
其中,σ为神经元的逐元素激活函数,u为一个循环权重向量,W为当前权重,b为神经元偏差,⊙表示u与ht-1的阿达马积。基本结构图如图3所示。

图3 IndRNN结构
IndRNN中每层的神经元是相互独立的,但是可以将IndRNN进行多层叠加,并且层与层之间的神经元进行连接。对于隐含层第n个神经元的hn,t可以通过式(5)进行计算。
其中,μn表示第n行的循环输入权重,而wn表示第n行的当前输入权重,bn为第n行的神经元偏差。由式(5)可以看出,每个神经元仅接收当前状态隐藏层和输入其中的信息,各个神经元之间都是相互独立的时空特征,这就使得IndRNN可以方便地进行组合。本文将经过ATT处理的特征输入到两层的IndRNN中,每层IndRNN包含64个隐含单元,得到包含上下文信息的全局特征。
2.3.3 卷积神经网络(CNN)
CNN是一种前馈神经网络,前期主要应用在图形处理中,可以避免前期复杂的图像处理。近年来研究者们将CNN引入自然语言处理可以有效缓解特征工程中的工作量,并且可以得到局部特征。CNN如图4所示,主要包括输入层、卷积层、池化层。

图 4 卷积神经网络
输入层为ATT的输出特征,经过卷积层利用卷积核对局特征进行卷积处理得到局部更具代表性的特征。基本计算如式(6)所示。
其中,x为卷积核窗口词向量矩阵,W为权重矩阵,b为偏置,f为激活函数。池化层是卷积神经网络的重要网络层,该层可以对卷积层得到的特征向量进行采样,进一步调整卷积层的输出。池化函数利用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出。当我们重点关注某个特征是否出现而不是出现的具体位置时就要利用到局部平移不变性,而池化就实现了这一点。一般的池化函数有最大池化函数和平均池化函数之分,本文使用最大池化函数。
2.3.4 特征融合
这一阶段将2.3.2和2.3.3得到的特征进行融合,本文使用张量相乘的方法对两种特征进行连接,对于两个特征V和U其张量乘积V⊗U计算定义如式(7)所示。
其中,n和m分别为V和U的协变张量。利用张量积可以将两个张量融合,并且张量积继承了其因子的所有指标,不丢失原本张量的信息。
3 实验和分析
3.1 语料准备
基于机器学习的指代消解的方法是需要相应的语料支撑的,目前进行的英文的指代消解的语料常用消息理解会议(Message Understanding Conference,MUC),中文指代消解采用的语料大多数是自动内容抽取会议(Automatic Content Extaction,ACE)或者OntoNotes的语料,但是目前关于维吾尔语的已标注的语料尚未见公开报道,因此需要针对维吾尔语名词指代消解对维吾尔语语料进行筛选和标注。
本文利用网络爬虫从人民网和天山网等网站的维吾尔语板块爬取的文章中筛选出存在指代链信息,在维吾尔语专家的指导下对其进行标注,包括标注指代链信息、名词短语、语义类别、名词单复数、格语法等特征,对标注后的语料利用Excel文件进行存储。
本实验中共标注了370篇文章,其中包含19 553条实体名词,9 725条动词和3 239条代词,标注的语法结构包括6 172条主语,8 232条谓语,6 518条宾语,6 984条定语和10 335条状语。语料中共有17 046条词语包含语义类别,13 265条词语拥有格属性。利用2.2节中提出的方法形成训练和测试数据集共75 084组数据,其中包括具有指代关系的20 266组正例和不具有指代关系的54 818组负例。
3.2 实验结果与分析
为了方便实验结果的对比,本文采用自然语言处理经常采用的3种测评标准: 准确率P、召回率R和F值,对实验进行测评。其中P可以反映模型的准确率,R可以反映模型查全率,F值可以很好地综合考虑P和R进而反映模型的综合性能,F值的计算如式 (8)所示。
同时,为了实验结果的稳定性和代表性,本实验采用5折交叉验证,取平均值作为最终实验结果。每次实验均利用GPU GTX 1050提高运行速率,进而减少运行时间。本文对不同的参数组合进行了反复实验,确定实验中各个模型的最优参数。后续实验均采用最优参数进行实验。最优参数如表3所示。

表3 参数设置
其中,ε表示训练过程中的学习率,batch表示每次迭代时批量处理的个数,act表示模型的激活函数,filters表示CNN中卷积核的数目,filter-size表示CNN中卷积核的大小,dropout表示在训练过程中的丢码率,epochs表示迭代的次数。迭代次数对实验结果的影响如图5所示。
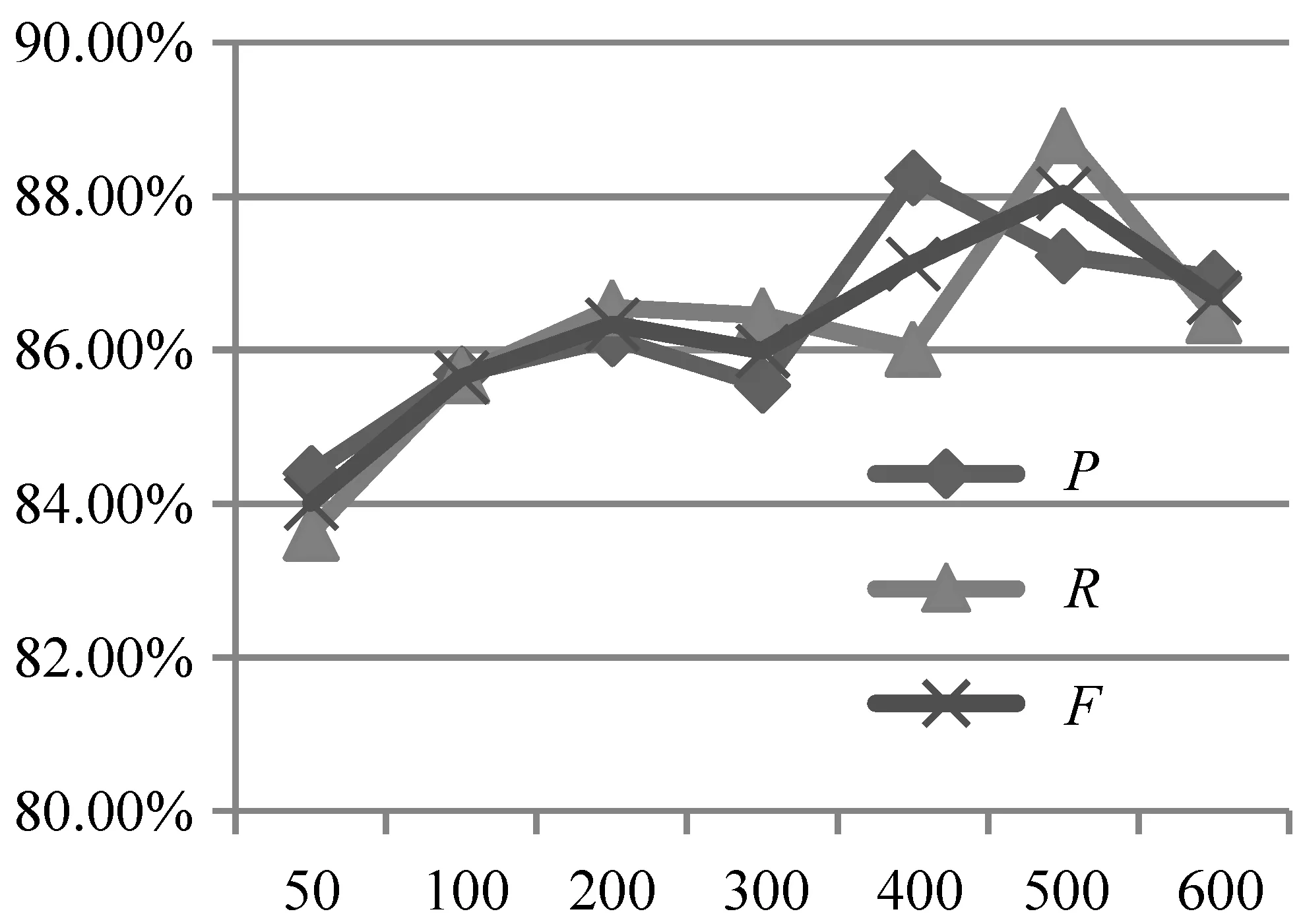
图5 迭代次数对实验结果的影响
3.2.1 ATT-IndRNN-CNN模型的有效性
在维吾尔语名词指代消解上,为了验证本文提出的模型的有效性,在特征相同的情况下,对不同的神经网络进行了对比实验,为了使得实验更具有说服性,各个网络均在自己的最优参数下进行实验,实验结果如表4所示。

表4 模型对比
表4表明在单独的神经网络中加入注意力机制时,ATT-CNN比CNN的F值提高了1.09%,ATT-IndRNN比单独IndRNN的F值提高了4.89%。这说明当在模型中加入注意力机制时,可以使模型的性能在一定程度上有所提高。当使用本文提出的ATT-IndRNN-CNN联合模型方法时,准确率P、召回率R和F值较之单一模型或者加入注意力机制的单一模型均有提高,充分说明了本文方法的有效性。
3.2.2 语义特征对指代消解的影响
2.1.1节的规则特征仅考虑了先行语和照应语之间的关系,对两者在句子中的语义内容考虑得较少,因此本节针对基于词向量模式的语义特征对指代消解的影响进行了对比实验,实验在原有规则特征的基础上引入100维的词向量语义特征,分别对不同的模型进行对比实验,并且对实验耗时进行了记录。实验结果如图6 所示,耗时结果如表5所示(表5中CNN+W表示在原有规则特征基础上添加语义特征,其他类似)。

表5 模型耗时对比

续表

图6 语义特征对比
由图6可以看出,在加入语义特征后所有模型的准确率P、召回率R和F值均有显著提高,实验结果充分说明了加入语义特征向量的有效性,这是因为规则特征仅包含先行语和照应语之间的结构特点,缺乏对整个句子中语义信息的考虑,而加入词向量融合特征后可以对先行语和照应语在句子中的语义信息进行建模,进而提高指代消解的准确性。
由表5可以看出,在增加语义特征时,模型耗时有少量的增加,说明加入语义特征后对于模型耗时影响较小。但将模型进行融合后耗时明显变长,表明运行时间受模型影响较大。
3.2.3 词向量维度对指代消解的影响
在融合语义特征时,训练的词向量维度的大小也会影响实验结果,理论上向量的维度越高,包含的语义信息也就会越丰富,因此本文分别采用10维、30维、60维、100维和150维的词向量进行了对比实验,实验结果如表6所示。
由表6可以明显地看出,在词向量维度达到100时,准确率P、召回率R和F值都达到最优,而当维度为150时, 性能有所下降。这是因为当维度越高时,包含的信息越多,就越有可能产生过拟合的现象,从而导致模型对数据的泛化能力降低。

表6 词向量维度对比
3.2.4 规则特征对实验的影响
为了证明本文提取的人工特征对实验的影响,本文进行了以下的对比实验。为了使一个规则特征可以得到有效训练,因此加入10维的词语向量,逐渐增加人工特征数目,其他设置按照3.2节中表3的最优设置。采用本文提出的模型进行实验得到准确率P、召回率R和F值如表7所示。

表7 规则特征对结果的影响
由表7可以看出,在不断增加规则特征的情况下,准确率和召回率虽有些上下波动,但F值在不断地提升,说明本文提出的规则特征可以提高指代消解实验的性能。
3.2.5 IndRNN层数对实验结果的影响
在本实验中用以提取全局特征的IndRNN采用的是两层结构,理论上堆叠的层数越多,就可以得到更深层次、更加抽象的语义信息。因此本文验证IndRNN层数对实验结果的影响,实验结果如表8所示。

表8 IndRNN层数对结果的影响
由表8可以看出,随着层数的增加,准确率、召回率和F值都是先增加再减小,并且在层数为2的时候准确率和F值达到最大,而召回率在层数为3时达到最大。所以本文将IndRNN的层数设置为2,以便取得更好的效果。
4 总结
本文提出一种基于注意力机制的混合模型的维吾尔语名词指代消解方法,通过引入注意力机制将特征内在的权重计算出来,进而分别利用IndRNN和CNN得到富含上下文信息的全局特征和局部特征;再将两种特征进行融合,进而可以得到更好的结果。另外在规则特征的前提下引入了语义特征,可以得到先行语和照应语在实验文本中的深层次语义信息,进一步提高特征的代表性。实验结果证明,该方法对于维吾尔语指代消解有较好的效果,可以明显提高实验的性能,并且在引入语义特征后可以显著提高实验的效果。
