基于Hadoop平台的网站日志分析系统的设计
2019-09-10刘亮
刘亮

摘 要:随着移动互联网时代的到来,用户数据呈现出了爆炸式增长,网站产生的访问日志也越来越大,达到了GB甚至TB级。大规模的日志中,隐藏了企业感兴趣的数据,挖掘其中的价值变得非常重要。网站日志分析系统基于Hadoop大数据处理平台进行设计,由5个部分组成:由Flume组件收集日志编写MapReduce应用程序对原始数据进行清洗;通过Hive的HQL对数据进行查询分析;Sqoop组件将Hive中的数据同步到Mysql;使用Echarts对数据进行可视化。经实验结果表明,数据量大于10G时,集群较于单结点具有更大的优势;同时,该技术栈使得Hadoop工程师与软件工程师的工作可以有效分离,充分利用技术人员的技能特点。
关键词:网站日志;集群;Hadoop;
中图分类号:TP391 文献标识码:A
一、概述
对于GB、TB级别的半结构化数据的处理,传统的关系型数据库已经无法在特定的时间内进行查询分析,随着互联网2.0时代的来临,Web数据已经呈指数级增长,单一结点的平台已经无法完成海量数据的分析任务。Hadoop是一个适用于大数据处理分析的分布式平台,其生态系统组件包括:Flume、Hive、Sqoop等,通过Mapreduce对数据进行预处理,导入至Hive进行统计分析,通过Sqoop组件将分析结果同步到关系型数据库,对于大规模数据处理方面,该技术栈在企业中得到了广泛应用。
Echarts是一个强大开源的图表JS类库,对Hive的分析结果能够进行图表化展示,供企业管理层进行决策。
二、相关技术
Hadoop是一个开源的大数据计算框架,具有HDFS、MapReduce、Yarn三大核心组件,开发人员只需要实现map()以及reduce方法就能够快速编写MapReduce程序,大大降低了大数据开发的难度。同时,Hadoop具有强大的生态系统,Flume擅长日志的收集、聚合以及传输;Hive是一个数据仓库系统,提供强大的HQL功能;Sqoop是一款HDFS(Hive)与关系型数据库的传递工具。
ECharts属于Apache的孵化项目,由百度开发,是一个使用JavaScript实现的开源可视化库,可以流畅的运行在 PC和移动设备上,提供直观,交互丰富,可高度个性化定制的数据可视化图表,在数据可视化方面具有广泛应用。
三、系统设计
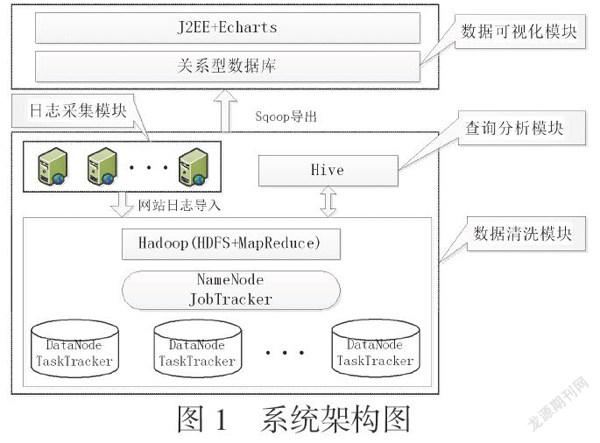
基于MapReduce+Hive+Sqoop+Echarts技术的网站日志分析系统的系统架构如图1所示:
图1 系统架构图
1、日志采集模块:Flume是一个高可用的日志采集、聚合和传输的Hadoop组件,负责将各个前端web服务器中的日志传送到日志接收节点上。Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。能保证Flume的可靠性及可恢复性。
2、数据清洗模块:通过Flume采集过来的日志,通常需要经过特定的处理,此时需要自定义一个MapReduce程序完成特定的任务,将清洗过后的数据,作为Hive的数据源。MapReduce首先对输入文件分片,Map输出的中间结果会先放在内存缓冲区中,从缓冲区写到磁盘的时候,会进行分区并排序,接下来进入reduce阶段,每个reducer对应一个ReduceTask,在真正开始reduce之前,先要从分区中抓取数据,相同的分区的数据会进入同一个reduce。这一步中会从所有map输出中抓取某一分区的数据,在抓取的过程中伴随着排序、合并,最后得到完整的reduce输出。
3、查询分析模块:Hive部署在Hadoop集群中的NameNode,也即master节点上,具体的查询分析由HQL来完成。Hive执行具体的 HQL语句的步骤如下:一、用户通过客户端组件(cli,webUI等)提交HQL语句。二、驱动器将接收到的 HQL语句发送到编译器,编译器将 HQL语句进行解析、优化。最终的优化策略是一个由MapReduce任务和HDFS任务组成的有向无环图。最后执行引擎利用 Hadoop来执行这些任务。
4、数据可视化模块:通过Sqoop将Hive查询结果同步到关系型数据库,使用J2EE+Echarts技术对结果以图表形式进行展示。用户在向其提供的浏览器客户端上输入或选择需要查询的内容,后台利用J2EE技术连接关系型数据库,将查询结果以JSON格式作为Echarts的数据源,进行以图表、表格等多种形式进行展示。
四、实验结果分析
为了测试系统,我们在特定的平台上做了实验,分别利用几组规模不同的数据分别在单机情况下和集群情况下进行时间测试。
实验环境。实验环境为单机配置为:处理器类型:Intel(R)Core(TM)i5-8250U;内存容量:8GB。Hadoop集群是由5台与单机配置相同的服务器组成。在集群中的所有服务器上都运行Centos7.4操作系统,并安装配置 Hadoop 2.8。在这 5台服务器中,其中的一台用来作为Master,并安装配置Hive 2.3.6,其余4台作为数据节点。
实验数据及内容。在实验中,我们采用实际网站中的日志作为输入。实验的内容是统计某一给定的时间片内,用户访问网站使用的代理工具前五排名。
③ 实验结果分析。通过分析实验结果,我们发现,如果数据量小于5G,那么 Hadoop集群并不能发挥其海量处理的优势,甚至时间消耗大于单机处理。但是,当要处理的网站日志达到10G的时候,Hadoop集群的优势就会随着数据量的逐渐增大而显现出来。如圖 2所示。
图2 单击与集群模式耗时比对图
五、结论
本文使用了Flume、MapReduce、Hive、Sqoop、Echarts等技术设计了一种基于Hadoop集群的网站日志分析平台,相比于单机模式具有较大的优势,数据量越大越能体现出集群的优势;同时,该平台使得Hadoop工程师可以专注于数据的收集、清洗及分析,传统软件工程师可以专注于数据可视化,将两者的工作有效分离出来,克服了开发人员的技能短板问题,能够面向企业商业应用,具有积极的推广意义。
参考文献
[1] 云计算中Hadoop技术研究与应用综述[J].夏靖波,韦泽鲲,付凯,陈珍.计算机科学.2016(11).
[2] 周勇,刘锋.基于Hadoop的Web日志分析系统的设计[J] 软件工程,2019,2(3):11—12.
[3] 基于Hadoop平台的日志分析模型[J].于兆良,张文涛,葛慧,艾伟,孙运乾.计算机工程与设计.2016(02)
[4] 陈苗,陈华平.基于Hadoop的Web日志挖掘[J].计算机工程,2011,37(11):37-39.
[5] TomWhite.Hadoop权威指南[M].曾大聃,周傲英,译.北京:清华大学出版社,2010.
