基于SVM的共享单车需求预测
2019-08-17黄同愿刘渝桥
宋 鹏,黄同愿,刘渝桥
(1.重庆市住房公积金管理中心, 重庆 401121; 2.重庆理工大学 两江人工智能学院, 重庆 401135;3.四川大学 计算机学院, 成都 610044)
1 概述
共享单车是指在公共场所不固定使用者的自行车单车共享分时租赁服务,它的出现开启了共享经济的时代,解决了城市内“最后一公里”的问题,既解决了资源闲置又方便出行。然而,随着规模扩大、用户增多,各种问题和瓶颈也接踵而至。
首当其冲的是“乱”,共享单车随用随取、随停随还,但这一特点导致它在发展的过程中出现乱停乱放现象也只是时间问题,对城市空间的管理以及城市的美化造成了极大的困扰;紧随其后的是“费”,共享单车的初衷是共用共享、经济节约,但一味的扩张、过多的投放量造成了极大的浪费,背离了共享经济的初衷,必然导致后继发展无力;最后是“不均”,共享单车营运是基于广大用户,具有显著的流动性,城市是一个大的场景,各个区域的单车分布常常出现不均的情况,有的区域人多车少,有的区域人少车多,用户体验不佳。
要想解决共享单车“乱”与“费”的困局、突破“不均”的枷锁,实现共享单车平稳、有序、健康、绿色、可持续发展,根本上是实现供需平衡,即共享单车的投放与用户的需求相适应、相匹配。而用户的需求是一个动态的过程,会随着各种因素变化而变化,故通过对各因素的分析,用户需求可呈现一定的可预测性,动态调整共享单车区域投放数量、协调资源、智能调度,降低运营成本、提高用户体验、增强服务质量,对共享单车行业的可持续发展具有重大意义。
共享单车需求预测具有重要意义、良好前景、深远影响,并且根据研究现状,结合已有数据进行需求预测具有可行性,许多学者和研究人员在这个研究方向上做出了不懈的努力。
2016年,黄同愿等[1为了对股票价格进行预测,采用了支持向量机以及人工神经网络进行对比仿真实验,并通过不同支持向量机核函数的对比构造了效果较好的预测模型,在一定程度上实现了股票价格的预测。
2017年,张建宽等[2]采用支持向量机以及最小二乘支持向量机预测股票价格的涨跌,并通过实验仿真证实了支持向量机在股票价格预测场景上预测的可行性,具有较稳定的预测效果。
2018年,成波[3]通过机器学习机制进行了校园网络故障诊断的研究,弥补了传统方式在故障诊断、自学习能力方面不强的短板,为网络故障的及时、准确定位提供了重要的支撑保障。
通过这些学者以及研究人员的研究可以看出:在由数据支持的预测场景中,采用支持向量机可以达到预测分析目的,因此基本确定了通过支持向量机构建预测模型进行共享单车需求预测的研究路线。
2 需求预测研究理论基础
2.1 共享单车需求预测实现的原理
共享单车的需求受到各种因素如时间、季节、节假日、天气、温度、湿度、风速等左右和影响。在一天的时间中,共享单车白天的需求明显大于夜晚,同时又存在早晚高峰,同天中呈现双波峰、两波谷,波段变化的显著特点;在全年不同季节,又呈春秋两季高、夏冬两季低的分布态势;同时受其他因素扰动,最终形成迥异的时序需求,具有较大的研究意义。结合各因素数据与需求的关系,可以建立行之有效的预测模型,并不断利用现有数据对模型进行训练与优化,强化凸显数据与需求的关系,有效预测后续需求变化,得出真正需求,做到先知先觉。在实际应用过程中,不仅仅需实现预测,还需尽可能提高预测的准确率以及缩短预测消耗时间,增强时效性与精准性,原理如图1所示。
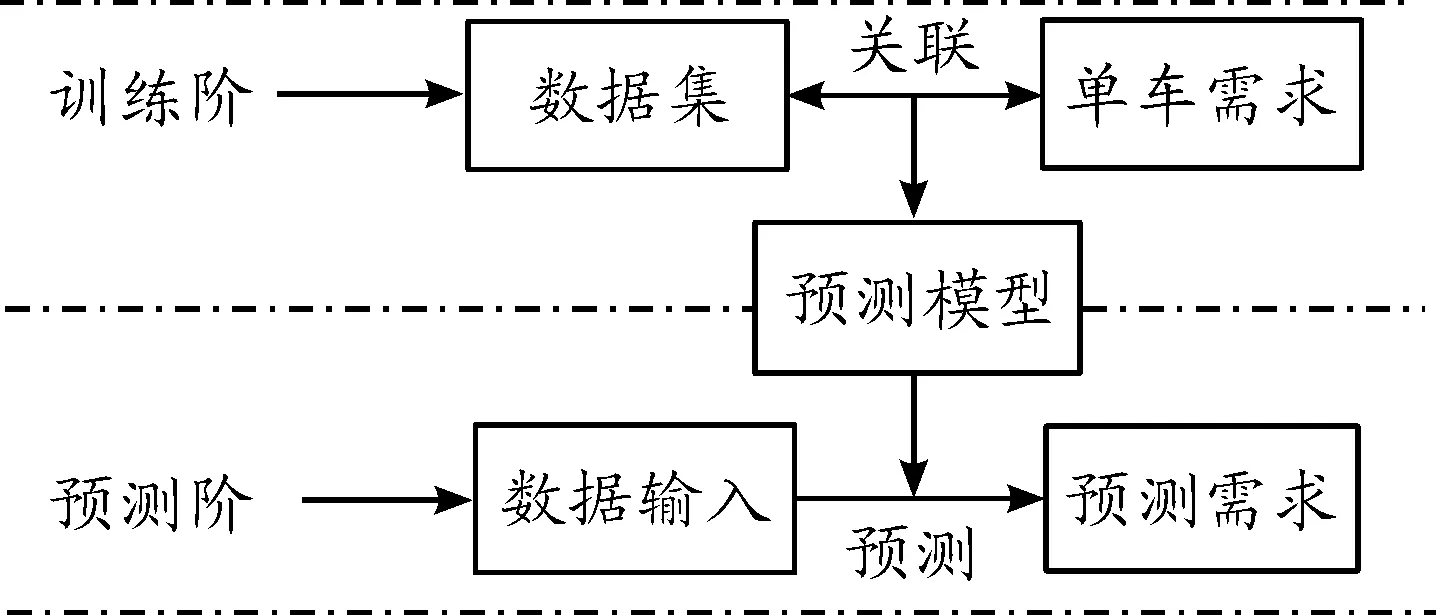
图1 共享单车需求预测原理
2.2 共享单车需求预测实现的步骤
由已知数据关系来预测后续数据关系,实现预测的原理,非常符合支持向量机的应用场景,故采用支持向量机来实现预测切实可行。一般地,支持向量机进行预测的实现步骤有4个,依次是数据处理(消噪、归一化、训测分类)、模型训练(训练数据)、模型测试(测试数据)、预测实用,是一个动态递进的关系。基础是已知数据集,是整个预测过程实现和不断完善的动力,模型的训练和测试是实现预测的具体过程,实际应用是预测的结果输出与价值实现,具体实现步骤如图2所示。
2.3 共享单车需求预测常用算法
由需求预测步骤以及实现原理可知:要想得到更好的预测效果,就必须在每一个步骤、每一个环节上采用适合数据以及应用场景的算法,如降低数据噪声的小波消噪算法、降低数据维度的主成分分析算法、构建预测模型的支持向量机算法。
2.3.1小波消噪
数据信号都存在或多或少的噪声数据,一方面增加了数据体量,增加复杂度、影响时效性;另一方面又对模型构建产生扰动,降低准确率,干扰稳定性,数据噪声是一切基于数据进行分析过程中首要克服的困难。小波消噪实际上通过短波实现噪音消除,首先对含噪声信号进行小波变换,然后对变换得到的小波系数进行某种处理,以去除其中包含的噪声,最终对处理后的小波系数进行小波逆变换,得到去噪后的信号[4]。实质上是在小波母函数伸缩和平移版本所展成的函数空间中,根据提出的衡量准则,寻找对原信号的最佳逼近,以完成原信号和噪声信号的区分,这一过程实际上就是低通滤波,是一种保留信号特征的低通滤波,不是单纯去掉信号,而是寻求信号特征与整体逼近的折中,如图3为小波消噪原理图。
2.3.2主成分分析
主成分分析运用统计方法,将存在相关性的变量转换为不相关的变量。当变量之间具有相关性时,可以认为是对最终结果信息有重叠的影响,会加大后续分析的复杂性,太过冗余。而主成分分析将具有相关性的变量通过数学手段变换后进行删除,重新构造尽可能少的不相关的新变量,同时使这些变量对最终的结果依然具有原来的影响。而根据共享单车运营数据的特点可以发现,主成分分析算法十分适用[5]。
2.3.3支持向量机
支持向量机是一种以结构风险最小化为基础的凸二次优化问题算法,不像以经验风险最小化原理为基础的算法一样得到局部最优解,得到的极值解都是全局最优解。支持向量机(SVM)是由Vapnik于1992年提出的一种机器学习方法,对于解决小样本、高维数、非线性以及局部最优解等问题有着显著效果[6]。
支持向量机的基本思想是通过一个非线性映射,将数据集映射到高维特征空间,并在该空间内回归拟合。
非线性映射函数表达式为:
根据表达式可以看出:只需考虑K(xi,xj)=φ(xi)·φ(xj),则K(xi,yj)为核函数,运用不同的核函数构建的模型具有不同的性能,对不同情况的数据具有不同的处理能力。由于支持向量机对非线性数据进行分析处理时,往往会通过核函数映射将非线性数据转化为线性数据,因此数据的复杂度直接决定了核函数的种类,核函数的种类又直接影响了最终模型的性能,故而核函数的选取要根据数据的复杂度及所需达到的分析程度来决定。
核函数的准确性受自身参数的影响,设置不同的核参数会不同程度地影响最终模型的性能,因此在参数的选取上需要有依据,可以采用较科学的选优方式对参数进行训练,得到最适合数据分析的参数,构建性能最佳的模型[7]。
通过对数据以及实际研究需求进行分析,机器学习可以有效构建共享单车需求预测模型,并通过大量数据进行训练,不断优化模型,使需求预测更加准确和迅速。支持向量机可用来构建预测模型,并通过对比基于不同核函数的支持向量机构建的预测模型从而得到最佳预测模型,并应用于实际中,而需求预测效果主要体现在预测准确率及预测分析消耗时间。
3 数据处理
原始数据集为某共享单车品牌在某个区域内需求情况,包含时间、季节、节假日、工作日、天气、实际温度、体感温度、湿度、风速、未注册用户租借数、已注册用户租借数、总租借数,共计十二维数据,数据集记录了由2016年1月起到2017年12月中每个月1号到19号的共享单车运营数据,其中每日从0点到23点进行24次数据记录,共计10 886条数据。
第1列到12列分别为:
datetime:时间
season:季节,1=春,2=夏,3=秋,4=冬
holiday:节假日,0:否,1:是
workingday:工作日,0:否,1:是
weather:天气,1:晴天,2:阴天,3:小雨或小雪,4:恶劣天气(大雨、冰雹、暴风雨或者大雪)
temp:实际温度,℃
atemp:体感温度,℃
humidity:湿度,相对湿度
windspeed:风速
casual:未注册用户租借数量
registered:注册用户租借数量
count:总租借数量
根据时序序列对整个数据集中共享单车的需求进行刻画,如图4所示。
由图4可知:由于每天以及每年的需求量波动类似,呈现周期性、逐年递增的变化态势,根据这一特性可以将由日期和时间构成的数据列进行量化,去除日期,将0∶00—23∶00转化为0—23,方便后续模型构建,训练优化。
数据集横向一行为一条数据,一列为一个数据属性,根据训练及测试的要求,以及总的数据集体量,可以把10 886条数据的前8 583条划分为训练集,剩余的2 303条划分为测试集,既有足够的数据进行模型训练和优化,又有足够的测试数据对模型的有效性进行充分验证。
3.1 消噪
消除数据集无效、异常数据称为数据的消噪,数据消噪可以减少噪声数据对整个预测模型的扰动,有利于降低模型复杂度,提高预测精度以及降低预测运行时间,强化预测效率,是开始构建模型前应该而且必须进行的步骤。数据集含有10 886条数据,数据最小间隔为1 h,在整体图形上细节显示较为明显,当某个时刻数据出现异常时,势必会影响数据的连续性与科学性,最终作用在预测模型上,产生负面影响。
针对共享单车数据的特点,选择较为科学的小波消噪方法,修剪细节,突出趋势,保证数据的连续性与科学性[8]。
小波消噪实际上通过短波实现噪音消除,首先对含噪声信号进行小波变换,然后对变换得到的小波系数进行某种处理,以去除其中包含的噪声,最终对处理后的小波系数进行小波逆变换,得到去噪后的信号,仿真结果如图5所示。
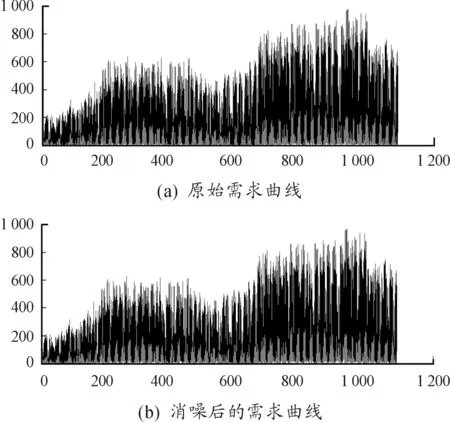
图5 数据集小波消噪图
由图5可以看出:数据大体趋势没有发生改变,基本上实现了强化整体、弱化细节的作用,对于预测模型的构建具有一定的促进作用。
3.2 降维
通过收集到的原始数据可以看出:用来进行共享单车需求预测的原始数据有12个属性,同时属性间并不独立,相互关联影响,具有特征属性多、相关性强的特点,不利于需求的预测[9]。属性多即维数高,相关性强即冗余多,属性冗余会对分析运算产生干扰,大大增加预测时间及模型复杂度,而属性的关联又会降低模型的可靠性,导致结果不理想,甚至分析失败。因此,必须精简特征属性,降低相关性,这是研究的需要,也是实际情况的选择,最终目的就是得到既能承载数据包含的大部分信息又尽可能多地降低属性个数,削减数据间关联度,降低数据的维度,否则分析的难度太大,复杂度过高,分析时间太长[10]。
通过对数据集进行主成分分析仿真,方差贡献率及累计方差贡献率如图6所示。
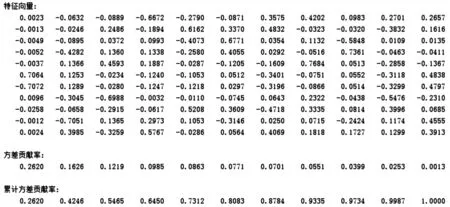
图6 主成分分析结果
通过累计方差贡献率以及阈值0.85可以将原除去需求标签以外的11维数据集降维为7维数据集,设7维分别为y1~y7,并通过特征向量与原数据集11维x1~x11对原数据集进行重构,则
y1=-0.279x1+0.616 2x2-0.407 3x3-
0.258x4-0.028 7x5-0.105 3x6-
0.121 8x7-0.011x8+0.520 8x9+
0.105 3x10-0.028 6x11
y2=-0.087 1x1+0.337 0x2+0.677 1x3+
0.405 5x4-0.120 5x5+0.051 2x6+
0.029 7x7-0.074 5x8+0.360 9x9-
0.314 6x10+0.056 4x11
y3=0.357 5x1+0.483 2x2+0.035 4x3+
0.029 2x4-0.160 9x5-0.340 1x6-
0.319 6x7+0.064 3x8-0.471 8x9+
0.025x10+0.406 9x11
y4=0.420 2x1-0.032 3x2+0.113 2x3-
0.051 6x4+0.768 4x5-0.075 1x6-
0.086 6x7+0.232 2x8+0.333 5x9+
0.071 5x10+0.181 8x11
y5=0.098 3x1-0.032x2-0.584 8x3+
0.736 1x4+0.051 3x5+0.055 2x6+
0.051 4x7-0.043 8x8+0.081 4x9-
0.242 4x10+0.172 7x11
y6=0.270 1x1-0.383 2x2+0.010 9x3-
0.0463x4-0.285 8x5-0.311 8x6-
0.329 9x7-0.547 6x8+0.399 6x9+
0.117 4x10+0.129 9x11
y7=0.265 7x1+0.161 6x2+0.013 5x3-
0.041 1x4-0.136 7x5+0.483 8x6+
0.4797x7-0.231x8+0.068 5x9+
0.455 5x10+0.3913x11
3.3 归一化
通过消噪及降维处理后,由于数据各属性之间的量级不同,会造成属性间的差异,量级大的数据属性会对预测模型产生大的影响,量级小的数据属性则对预测模型没有太大的影响,不符合实际情况,需要使每个数据属性对最终预测结果有着同等重要的影响,故需要统一各属性量级,消除量级差异带来的巨大偏差。
将样本进行归一化处理,遵循的公式为[11]:
式中:xi为属性中的第i个样本数据;xmax和xmin为属性的最大值和最小值。
图7为10 886行,7列的数据集,每1行都可与需求构成关联式,用以不断训练预测模型。
4 基于支持向量机的预测模型
根据数据集样本以及实际应用场景,对于共享单车需求预测可采用支持向量机构建模型,但由于采用不同核函数的支持向量机性能各异,会影响预测模型效果,因此需要分别基于不同核函数进行仿真实验,选择效果最佳的模型。
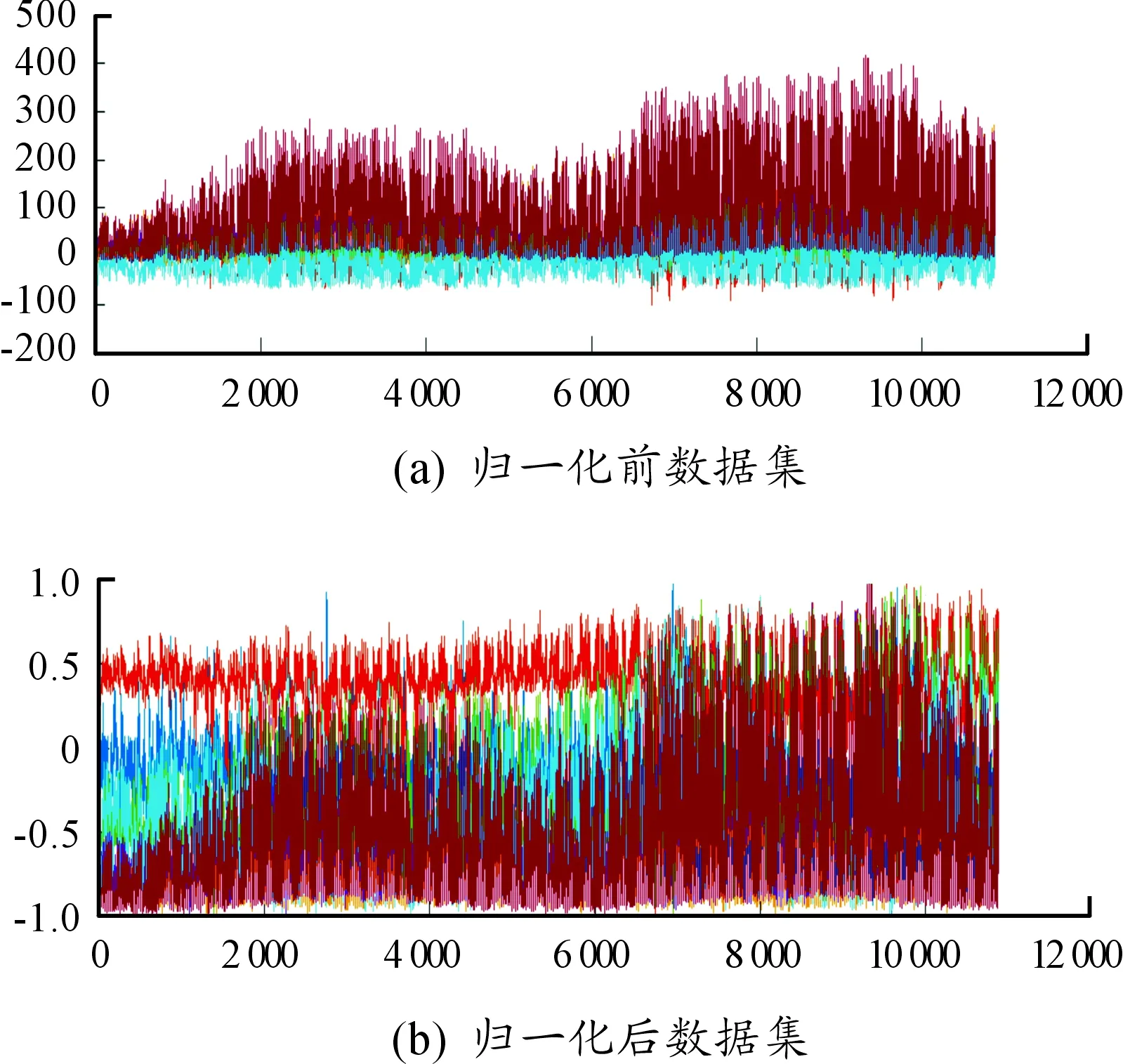
图7 归一化前后效果对比
4.1 支持向量机与核函数
支持向量机预测实际上是通过映射函数将非线性的数据样本映射到高维空间,然后回归拟合,构建模型,实现预测,而映射的函数、映射空间不同,构建的模型不同,预测的效果也不一,则需要构建多种模型,选取效果最好的模型[12]。
支持向量机的预测过程主要思想就是把原来的低维数非线性问题转化成更高维数的线性问题,从而便于求解,并且由于高维特征空间是通过核函数来定义和表示的,所以核函数能决定SVM模型的可靠性,影响最终效果。同时,核函数的学习过程是通过在线性子空间中计算来解决全局高维数问题的,类似于分治的思想,并未增加算法的复杂性。
核函数的选取非常重要,常见的核函数有[13]:线性函数K(xi,x)=xi·x;多项式核函数K(xi,x)=(xi·x+1)d;径向基核函数K(xi,x)=exp(-(x-xi)/σ2);多层感知器函数K(xi,x)=tanh(kxi·x+θ)。
4.2 基于不同核函数的支持向量机预测模型
由支持向量机的原理可知:核函数为映射高维空间的法则,不同核函数造成了不同实际情况下支持向量机模型性能的区别,要选取符合实际情况的核函数,还需要从实际出发,分别进行实验,通过对比最终确定。
为选取适当核函数进行预测,分别用不同核函数进行仿真对比,如图8、9、10所示。
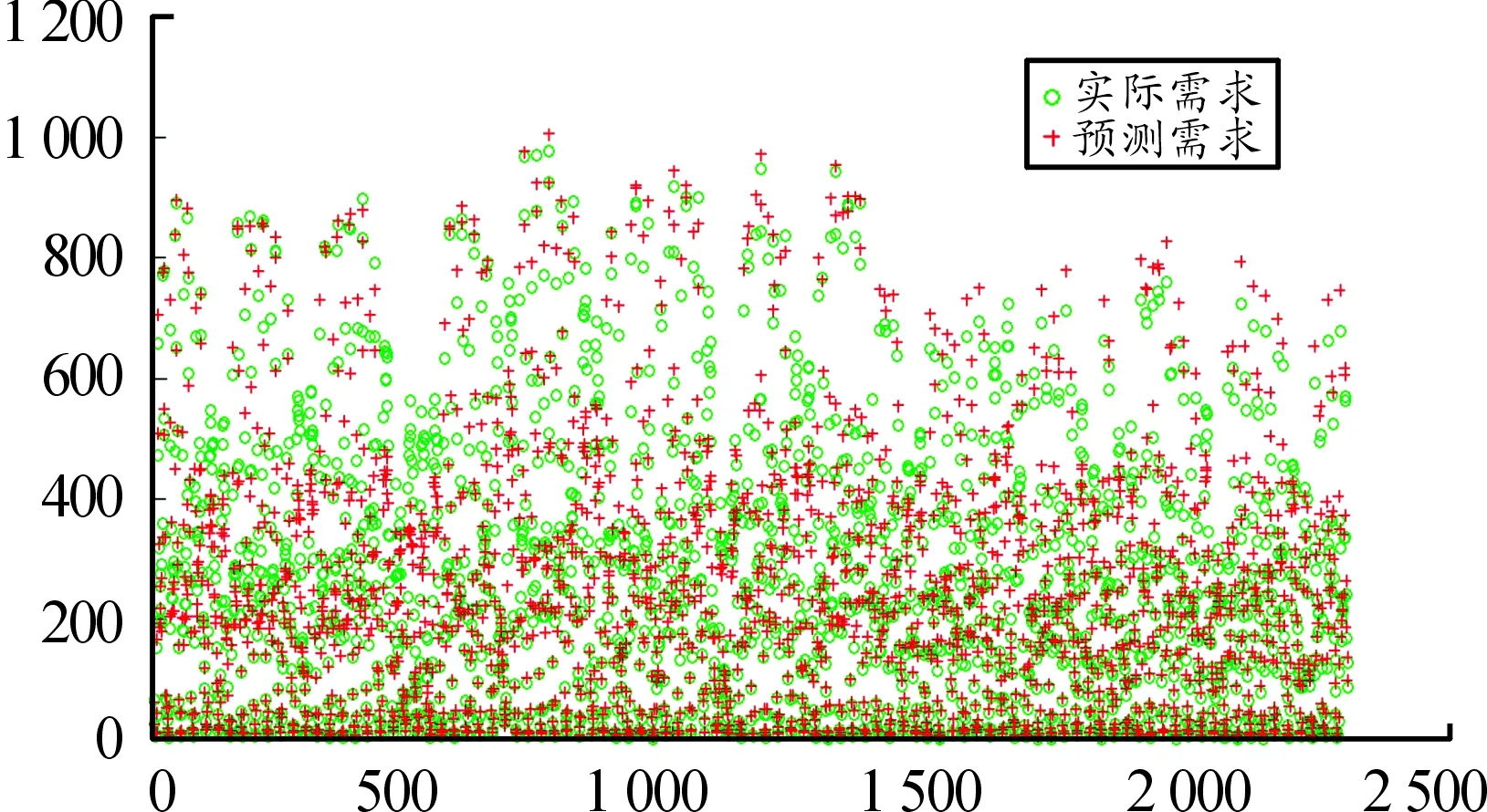
图8 基于线性核函数的SVM预测结果对比
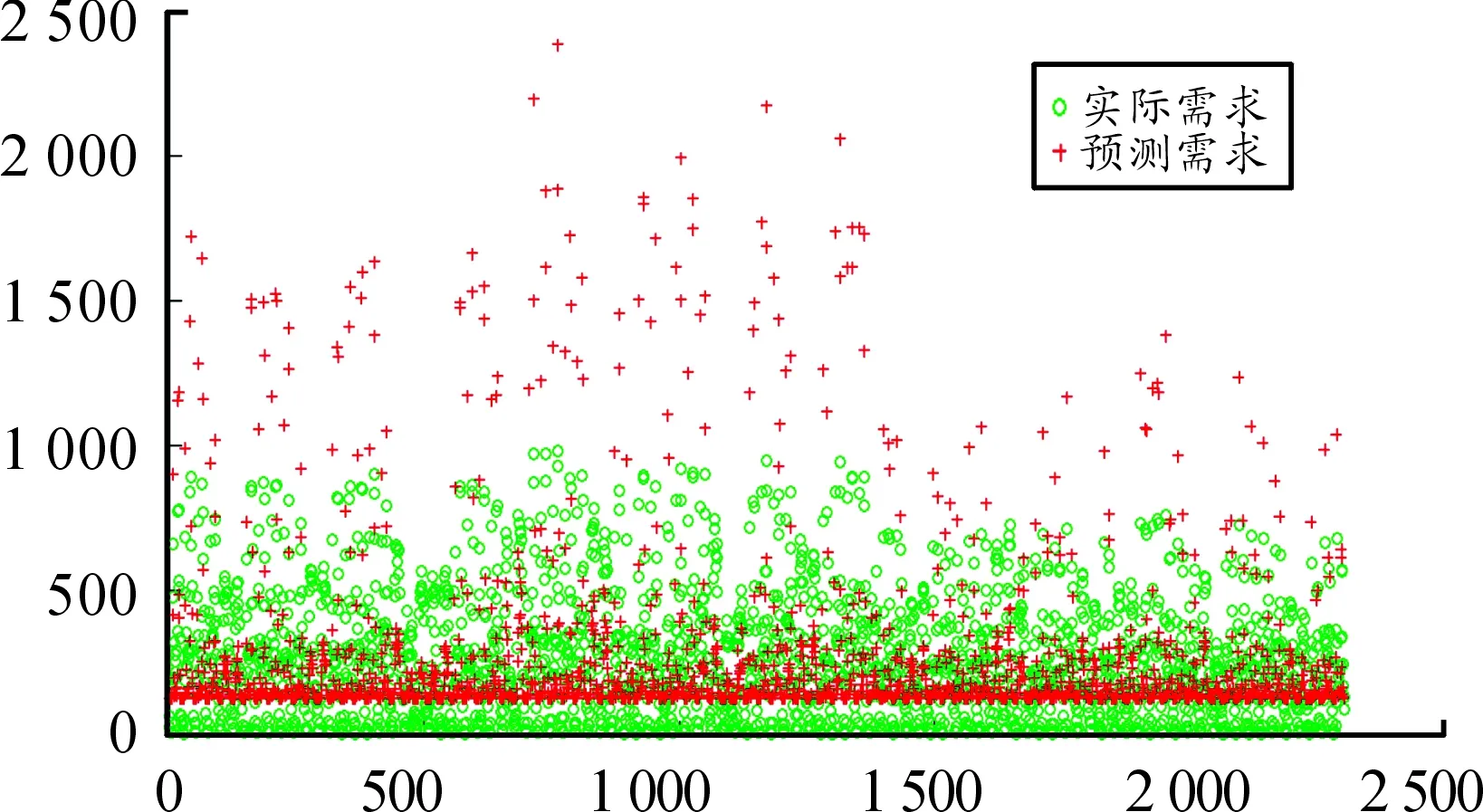
图9 基于多项式核函数的SVM预测结果对比
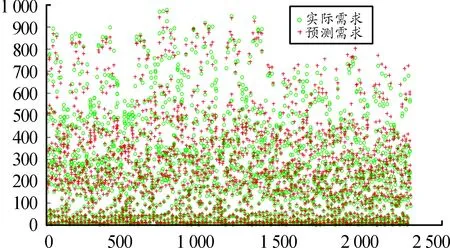
图10 基于径向基核函数的SVM预测结果对比
线性核函数、多项式核函数、径向基核函数三者SVM预测模型的效果对比见表1、2。
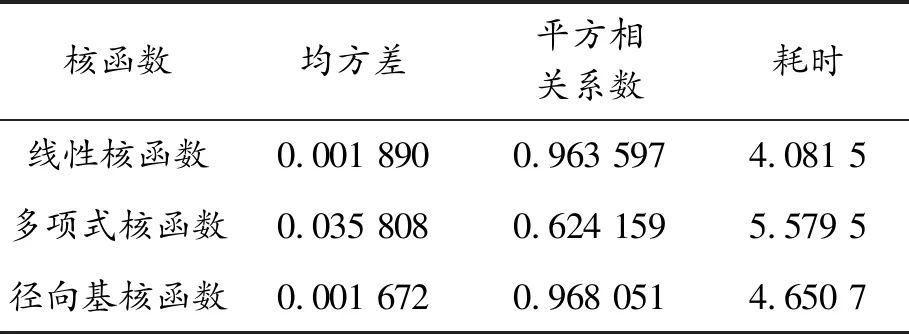
表1 各类型核函数预测模型效果对比
根据统计学经验,将预测的效果进行量化,设平均相对误差率为acc,预测模型得到的预测数值向量为YC[i],原始数值向量为YS[i],测试集样本数量为n,则平均相对误差率acc可以表示为
由上式可以看出:平均相对误差率表示预测值相对于真实值的偏离百分比代数和的平均值,可以客观反映预测的效果,将仿真实验构建的各个预测模型的预测结果进行计算,得到表2。
由平均相对误差率定义可知:当数值较小时,表示预测值与真实值的误差越小,预测值整体越接近真实值,预测效果越佳;当数值较大时,表示预测值与真实值的误差越大,预测值整体效果不佳,达不到预测的要求。

表2 需求预测模型误差率对比
由图8、9、10以及表1可知:当以径向基核函数为支持向量机核函数时,构建的预测模型均方差最低,只有0.001 672,平方相关系数最高,有0.968 051,预测需求数值与实际需求数值基本上相当,表明该核函数下的模型最为精准,且这个预测过程耗时只有4.650 7 s,而其他两种核函数构成的支持向量机预测模型效果均不如径向基核函数,尤其是多项式效果比较差,而线性核函数稍弱于径向基核函数。
根据表2中的误差率可以看出:基于径向基核函数的SVM预测模型效果最好。综上所述,最终根据实验仿真效果,选定基于径向基核函数的SVM预测模型进行最终共享单车需求预测。
5 结束语
支持向量机对于分类和预测具有良好的效果,而共享单车的需求预测对于解决共享单车资源浪费、发展瓶颈、营运规划等现存问题具有重要意义,通过现有数据结合支持向量机可以有效预测共享单车需求。同时,由于是通过数据训练得到的模型,所以预测结果更加贴近真实情况,更具有实际应用意义。主成分分析及小波消噪算法的引入对预测过程具有促进作用,对于降低模型复杂度、缩减预测消耗时间、提升时效性都具有显著效果。
通过支持向量机构建的回归预测模型仿真实验,模型的精确性、时效性、可靠性较好,适合基于当前数据集的需求预测,坚持以数据为基础、以模型为准绳、以需求为目标,逐步优化、不断训练、反复测试,以期获得更高的预测精准度。支持向量机构建的预测模型可以实现精准的需求预测,模型的构建是基于总数为10 886组的数据集,是在较小区域、不长时间、较小流动的情况下收集的数据,后续在扩大数据范围、增大辐射区域、提升数据波动的情况下依然有待考证以及继续优化,需要继续探讨在更大量数据、更复杂情况、更多样场景下的应用。
