一种新的IoT PaaS大数据服务平台的设计
2019-08-17孙丽娜武海燕
孙丽娜,武海燕
(1.河南大学民生学院, 河南 开封 475004;2.铁道警察学院 图像与网络侦查系, 郑州 450053)
目前,信息科技是进入企业市场的基本技术支撑,在国际市场科技运用日益更新的压力下,各产业迈入 21世纪的主要目标是结合工业4.0,创造出智能产线,提高年、人均产值。国际上的大公司能够透过物联网与大数据进行实时监控,达成公司由制造业转型为大数据服务的目标[1-2]。对国内制造业来说,信息化所需的门坎过高,包括软件开发、软件测试、营运系统。目前的信息化相关服务产品已无法满足中小型制造业及用户对应市场这一区段的具体要求,部分产品针对单机提供的软件或云端服务 (针对软、硬件服务),亦无法有效全面提升产线智能。故产业亟需整合机台物联网与制造云服务平台,从而提升整体产业之上、下游竞争力。
在云端服务时代,软件服务[3-5](software as a service) 与基础设备服务[6-7](infrastructure as a service)是大家较熟悉的两个服务层,一般是较容易理解的类软件及硬件层,此两大类云端服务在过去的发展阶段获得了大多数公司与研究机构的关注与投入,经多年努力,已取得可观的进展[8-10]。近年来,越来越多的研究团队已开始将研发的目光聚焦于平台服务PaaS[10-11]。平台服务定义为提供应用程序工程师开发、执行与管理应用程序的云端系统环境,此服务将应用程序开发的系统层 (例如数据储存与分析处理 )以API接口方式提供给应用程序接入使用,提高开发效率、降低开发与维护成本[12]。
建构高效能、高容量、高稳定性与易用性高的物联网云端服务平台系统是本文研究的目标。在提供客户端软件服务的作用平台服务中,本文的解决策略是发展物联网云端服务平台技术,以大幅降低产业发展信息化的门坎,提供一个垂直整合度高的数据收集与储存平台,负责收集物联网装置的各项数据,从而建立一个具有高性能的分布式计算平台,负责执行客户端应用服务所上传的数据分析应用程序。
1 大数据处理与分析
透过物联网的建立与信息传播技术的更新,人们生活与工作环境所产生的各项数据被系统快速地聚集,这是在物联网盛行前所无法达到的数据规模数(PB规模以上)。据Statista 2018年最新统计数据显示:2018年全球连接的物联网设备数量达到了230亿,至2025年物联网设备数量将增加到750亿。这说明物联网时代的到来,伴随而至的挑战是对数据提供有效率的处理,故对物联网海量数据的处理也得到越来越多的关注。
1.1 大数据分析方法
对大数据处理的挑战已定义为4个主要方面:量(volume)、速度(velocity)、多变性(variety)、价值(value),大多数的机构或企业对大数据的处理仍着重于前3个方面,对于第4个方面则有较多不同的见解与定义。
有高质量的原始数据,容易得到高效率与高价值的信息。数据的不良情况包含不完整性、噪声与不一致性等,数据的处理意味着在原始数据写入数据库前必须进行前置处理,以达到高质量的目标。前置处理主要着重于数据写入前处理,这在数据分析前属于重要的部分。
前面对大数据的第4个挑战,即如何处理原始数据后提高其附加值,特别是对数据进行分析以获取有用的信息再加以利用,这就是数据的加值服务。目前,业界采用的分析方法为早期由谷歌提出的一个程式模型MapReduce,由于其企业特性常须面对使用者并要求在大量的数据里搜寻目标数据,其架构为用一组map函数并行处理大量原始数据,再由另一组reduce函数进行运算合并的作业,这样的分析架构在本质上已具有平行处理能力。然而,这是针对因特网型搜寻形态的作业,前提是针对大数据具有扁平而规律的结构,并分布于数个机器与储存装置中,对于需大量运算类型的分析工作,则不具有任何优势。
MapReduce在对数据做中介处理时,必须对储存装置进行大量的输出输入作业,缺乏效率。为解决此问题,加州伯克利大学的AMP实验室开发一个开源丛集运算架构 Spark,其最重要的特性是将需要处理的数据以及中介数据放于内存中,对处理的效率与速度有显著的效能提升。
1.2 云端平台服务
目前,各家通讯与科技公司皆积极投入平台服务的开发,目前存在的平台服务有:
IBM Bluemix:以Cloud Foundry为基底,建构开放式云端服务平台,主要提供 IBM 软件使用权给因特网与行动开发人员,进行快速应用程序开发,目标是大幅减少创建和配置应用程序所需开发时程。
甲骨文云端平台(oracle cloud platform):针对合作伙伴及产品用户的开发人员,简化开发应用程序周期,提供一致化服务平台,拓展甲骨文软件服务(SaaS)开发应用。
亚马逊(Amazon) PaaS:在各企业中最早大规模投入云端服务建置领域,其服务平台主要提供应用程序信息的储存与传递,主要目标是进行企业云端服务的垂直整合,为其客户提供更完整的服务。
研华WISE-PaaS:凭借其在工业计算机全球市场的占有率第一,进行其与客户端的垂直整合开发平台,主要采堆积木方式,透过其伙伴合作方案,协助客户端开发人员共同加速打造专属物联网应用软件。
综上,可以归纳出几个关于服务平台研发的重要方面:① 平台跨领域的服务是一个巨大的议题与挑战,这些企业的研发成果也无法有效地涵盖平台服务范围的广度与深度,大部分仍以企业既有客户群进行垂直整合为出发点;② 平台的研发目前仍着重于大量数据写入与读取的处理,对于增值产出的部分仍缺乏较具体的成果。
2 本文IoT PaaS架构
本平台建构的主要目标是提供一个数据收集与储存平台,负责收集物联网装置的各项数据。同时,提供一个高性能的分布式计算平台,负责执行应用软件服务所上传的数据分析应用程序。基于分布式架构,将工作进行分流,配置不同服务器,达到运算负载平衡的并行处理,得到对多传感器数据处理与分析的有效性能表现。
2.1 平台架构
本平台架构采用分布式架构设计,如图1所示,主要包含3个模块,分别为注册模块、数据收集模块与分布式运算模块。
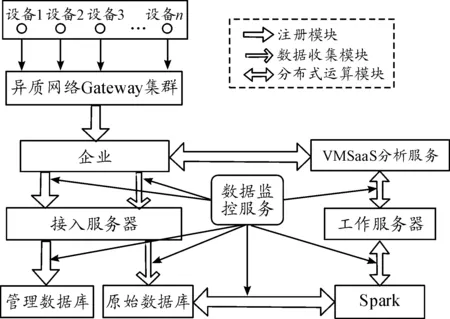
图1 本文IoT PaaS架构
IoT PaaS平台布署后可由营运支持接口透过注册模块提供的应用程序编程接口(APIs)来注册使用者与服务,注册之后,才能提供客户端进行机器设备的注册。在数据收集方面,已注册且认证过的机器设备与传感器可使用数据收集模块提供的APIs将数据传送至平台数据库储存。
当数据开始写入后,即可进行数据分析。例如,训练一个商品退货 (RMA)预测模型,此时云端软件服务程序可以透过分布式计算模块提供的 APIs将数据分析程序上传至平台,并使用此平台提供的分布式计算环境进行运算,运算完成后可以使用 API进行预测模型运算 (可进行实时或批次的预测运算)并完成结果取回(如图2),其中“ACL模组”表示访问控制列表(access control list,ACL),目前仅提供基本权限控制,亦可用来延伸与云端垂直服务层权限进行整合,达到对云端所有服务一致的控制。
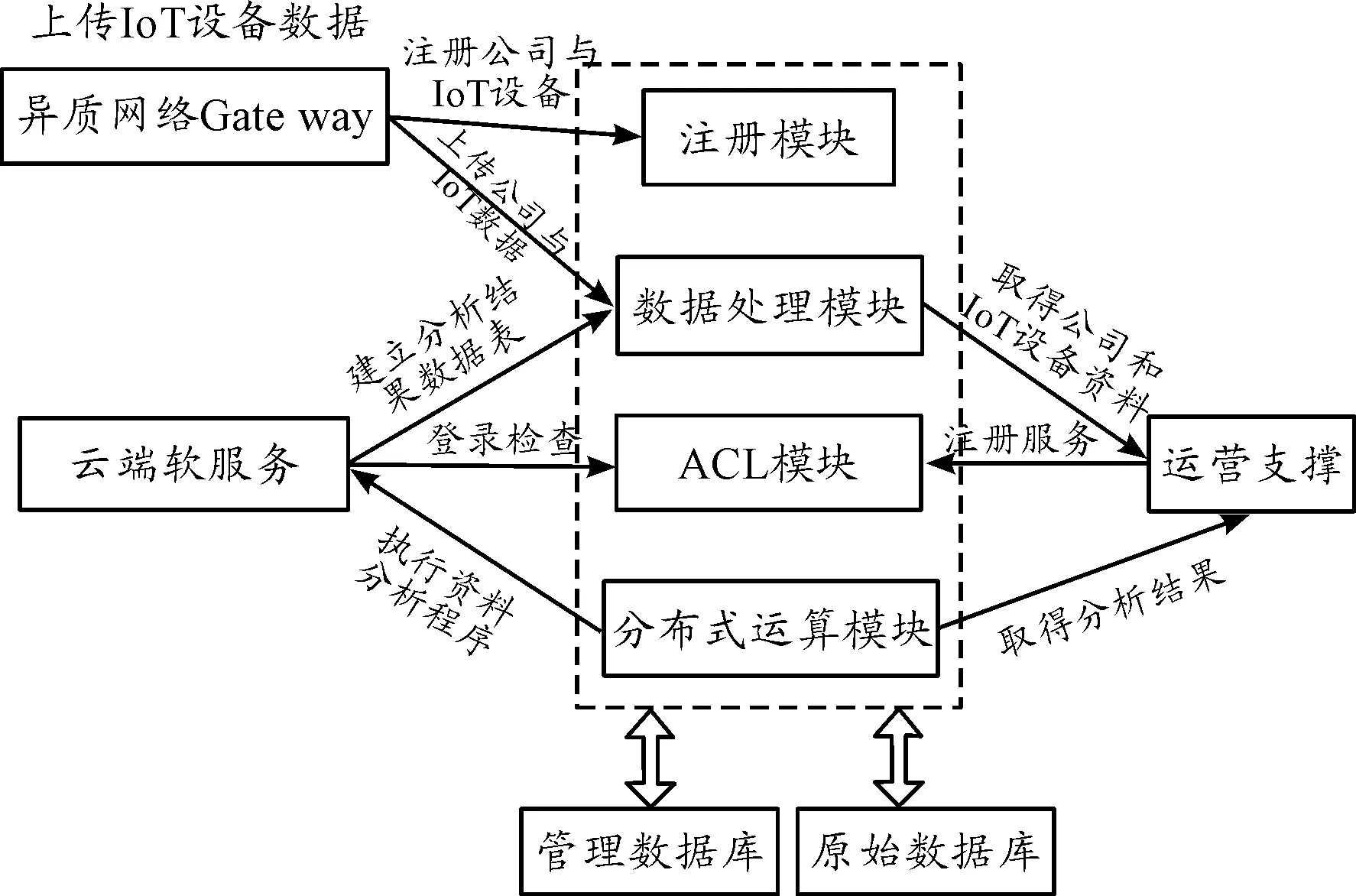
图2 平台模块与周边关系
2.2 不同模块的介绍
1) 注册模块。平台的数据注册主要针对机器设备与传感器,为便于对数据的后续收集与管理,将一企业组织定义为3个阶层,即厂区(Company)、机器设备(Machine)与传感器(Sensor)。注册模块对于任一阶层对象的识别,以〈C,M,S〉定义,其中C表示厂区物件,M表示机器设备对象,S表示传感器物件。客户端采用此组合定义与IoT PaaS对其所属的各阶层对象进行注册作业。
本模块作业数据以结构化数据库(MySQL)储存相关管理性数据,注册模块的数据库作业程序以标准SQL语法进行。此类数据库为管理性数据库,本身极具结构化特性,且数据量(MB)在作业能力可接收范围内。
2) 数据收集模块。储存与处理来自传感器终端设备的大数据量是本平台研发的主要目标。因此,对于原始数据的特性须经由分析后设计其纲要结构,以决定最佳储存与处理效能的目标数据库。由于各产业结构与设备性质差异较大,为取得最具弹性化的设计,响应上述讨论中有关大数据的多样性挑战,在数据纲要设计上采用以下的基本数据元设计:
{“key”,“value”[;…]};
key:数据属性名称;
value:原始数据值
其中“[…]”表示数据属性数量,可由用户自行定义,不需要预先定义数据库纲要。
对于这类原始数据,半结构或非结构性是其主要特质。模块提供数据以实时或批次方式将传感器数据写入平台内数据库。由于数据源的特性,对于此类数据,本模块采用PostgreSQL数据库作为原始数据的储存目的地。
3) 分布式运算模块。为实现对大量数据进行有效的实时或批次分析,分散并行运算架构是最佳选择。采用Mesos作底层工作节点管理加上 Spark的分散运算架构建立分布式计算环境,如图3所示。Mesos是一个开放原始码的丛集管理系统,主要实现分散应用程序间的资源隔离与分享。
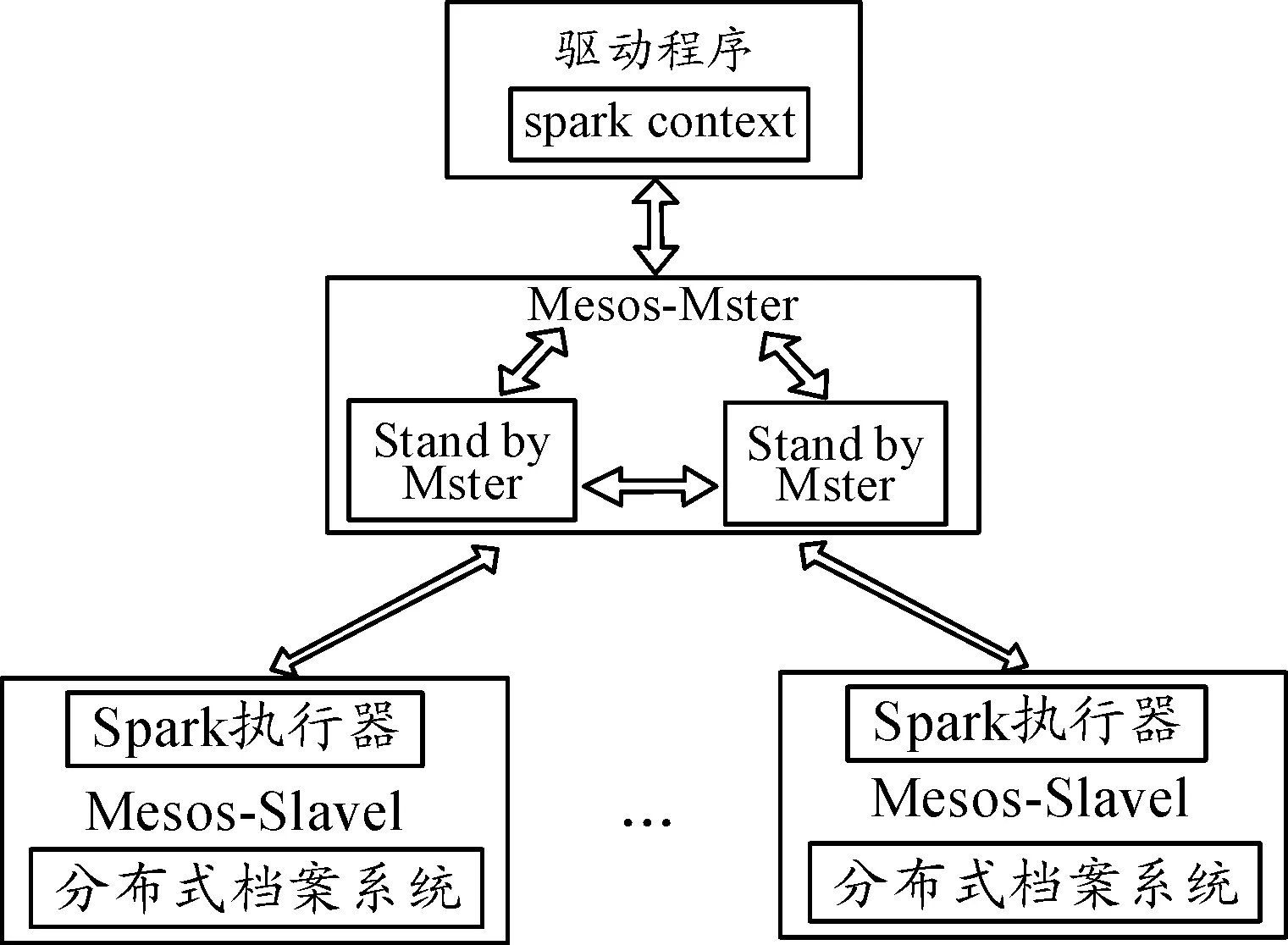
图3 Spark分布式计算架构图
由于Spark将运算数据块皆存放于记忆体内部,因此在分析成效上有显著的效率。而且,对于丛集内多工作节点的管理,Mesos采用的架构具有自动产生master管理的智能机制,所有分布式节点共享分布式文件系统。这符合对大数据分析的另一挑战,目标是在建立分布式计算环境、提供平台使用者进行有效的分析后,将结果反馈回终端装置进行智能管理,以提高产能。
3 平台通信接口设计
本平台对应来自终端传感器的大量数据写入/读取处理与智慧分析的服务,由一群高效率的服务器接口(以下简称API)来完成,此API集终端装置与平台的通讯需求,借用高效率与安全的通讯传输,以实现对产生的大量数据进行效的处理与应用。
本设计规范采用RESTful API软件架构设计风格,考虑企业客户对来自于物联网大量数据所需的存取与数据分析需求,使用者依据本规范建置物联设备端数据存取应用程序及快速导入业界规范的大数据分析方法,如 Hadoop/Spark,从而快速有效地建立与存取其所属基本数据及物联设备产生的大量数据,并针对大数据分析提供扩充功能,有效提高企业产能。
本设计规范之数据存取API服务用于物联设备端与云端数据储存平台时能自动化对接、实时作业监控、提供数据集存取与导入巨量信息分析程序进行信息提取等。企业客户可根据本规范提供的 API接口定义进行相关应用程序编程接口开发,以提供数据用户或开发者一致性 API,进行取得、搜寻或分析所需的数据集数据,以取得有益信息并反馈给物联设备进行产能修正,从而有效提升产能。
数据存取应用程序API接口主要提供一般结构化数据内容存取,不包括数据内容应用层面解析,如复杂数学逻辑运算筛选、应用领域所代表之意义判断、字段之间相关性等。
界面规范准则分为语法规则和命名规则。语法规则采用RESTfulAPI的规划,主要目标是要让企业客户以HTTPGET、POST、DELETE方法存取IoTPaaS数据。API呼叫回传内容格式则以Json为主,API服务路径采用URI通用语法组成,分为服务网址(scheme+host)、资源路径(API service path)和服务选项 (API Query Options)。其中,服务网址为平台上提供该类别API应用服务之协议(目前仅支持HTTP)及主机网址/域名。资源路径接续于服务网址后,指定某一API服务项目路径名称。服务选项接续于API服务项目路径后,针对某一API服务,指定欲进行的作业数据参数。
命名规则:定义API接口的命名原则,提供企业客户于开发平台应用程序可依循之API 呼叫,命名规则依据下列格式定义并提供API服务:
{/}{VERSION}{/}{OBJECT}[{/}{SUBOBJ}…]
其中:{}表示必要项目;[]表示选择项目;…表示允许多重项目。
对于API界面类型,主要提供两大类型服务,即数据异动与取出。
1) 数据异动
POST:用于新增一企业级客户、部门厂区(company_uuid)、新增及修改机器/传感器的基本管理数据及感测数据、分析服务应用程序的作业部署与启动。对于企业自建的私有物联网云端数据储存平台,则可用于建立分公司/单位账号。
DELETE:删除机器/传感器的感测数据。
2) 数据取出
GET:用于向IoT PaaS取得数据库的数据,包括会期标识符、企业客户列表、机器/传感器的管理数据、机器/传感器的感测数据、分析服务应用程序的结果、分析服务应用程序的状态及物联网云端数据储存平台运作记录。
4 平台测试与分析
本文IoT PaaS服务平台的建置实现采用最轻量的架构进行平台设计与实行,主要目的为取得平台的压力参数作为扩增的架构参考数据。
本平台测试实验的主要参数如表1所示。测试环境部署因特网服务器(nginx+uwsgi+Flask),使其对应于处理使用者端的RestfulAPI服务要求;其次,安装管理性数据库(MySQL5.6)与感测器原始数据库(PostgreSQL9.5)。分布式分析运算丛集部署包含1台Spark驱动器、1台Mesos-Master及2台Mesos-slave。

表1 本文IoT PaaS 系统实验工作环境参数
由于设计与建置一云端平台服务对于其他云端垂直服务具有复杂的依存关系,在学界尚未有统一的量测性效能因子用作各平台的比较,故对平台服务的基准验证是一项困难的工作。鉴于此,对本平台部署完成后进行测试验证,以设计的功能与时间效能作为参考。在功能完整性方面,平台的设计目标在于提供高效、高容量的数据处理与分析。APIs的定义与各功能测试项目见表2,涵盖对云端平台服务的各功能项目。
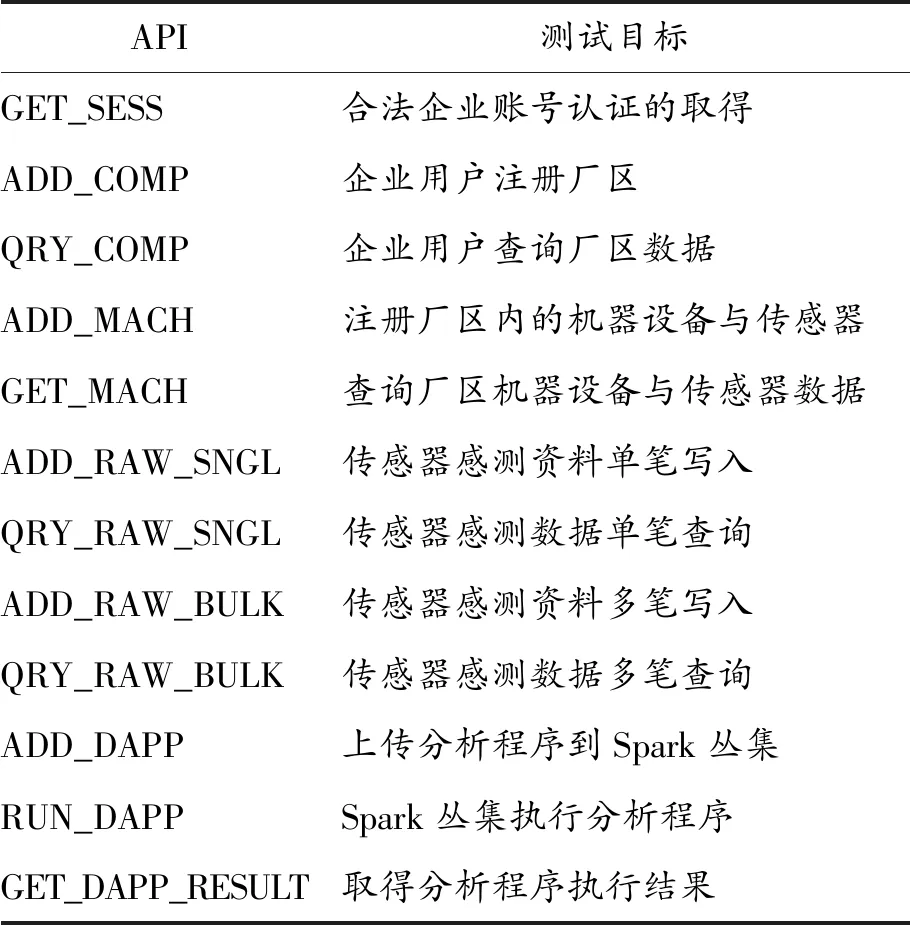
表2 API功能测试
部分应用程序支持接口(API)的运行时间分析见图4。进行深入的时间分析可见,约70%的时间用在信息接收后的解密运算,以增进更多Restful API服务需求的数量。目前,测试单一因特网服务器的 HTTP服务时要求进行负载测试,结果表明:在完成单一“GET_SESS”API的标准测试下可达1 800 次/s。
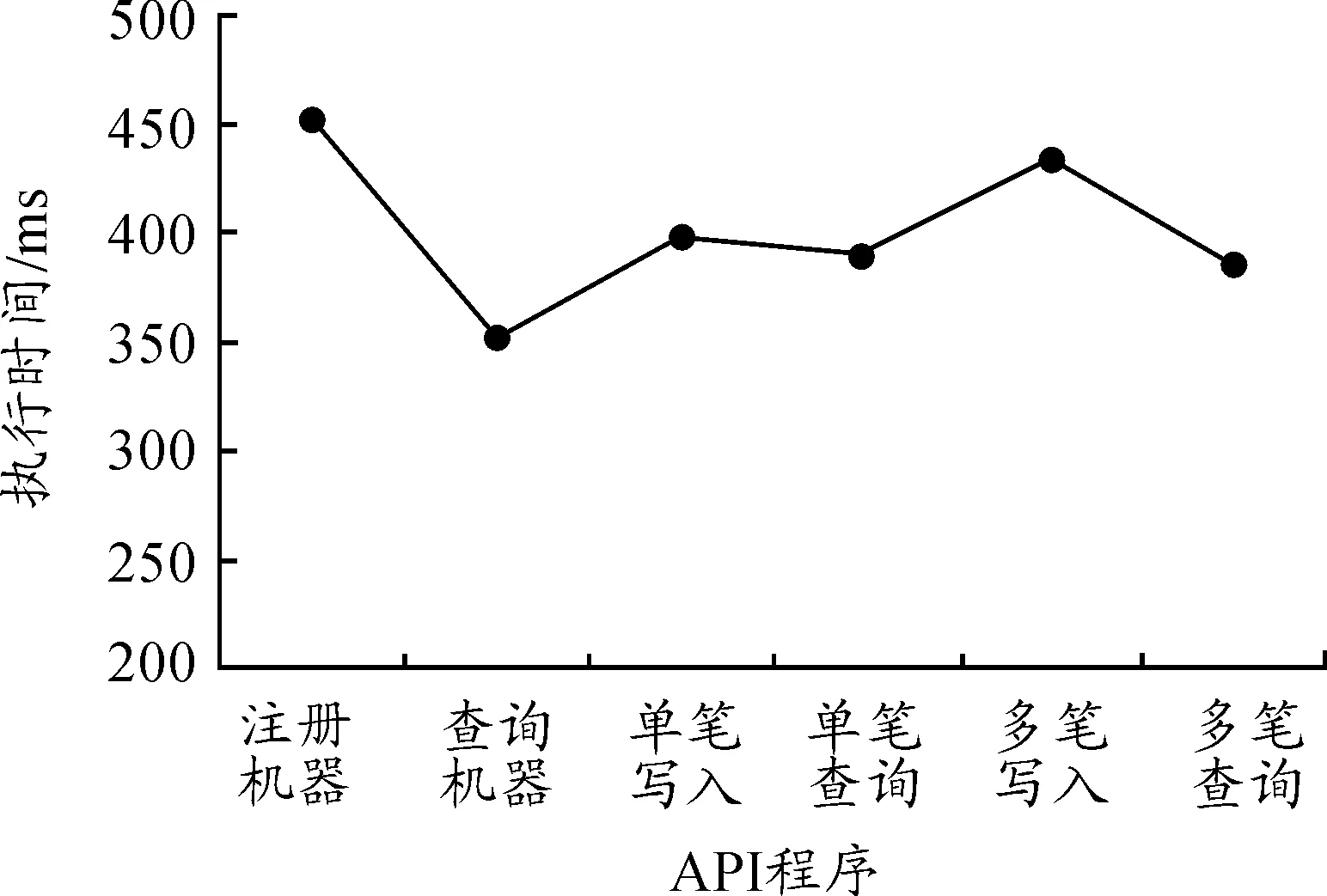
图4 应用程序编程接口(APIs)运行时间
对于数据处理与分析的平台服务时间效能测试结果见表3。

表3 数据处理时间效能
对于数据查询的时间效能与传统关系数据库的比较如图5所示。
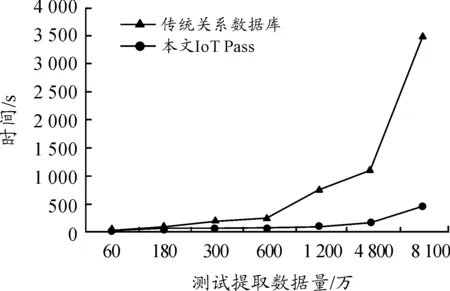
图5 查询数据(50万笔)时间比较
可以看出:本文平台并行式数据存取架构突破传统硬件架构存取效能,以分布式储存技术(Spark并行式数据计算丛集)提高大数据存取与平行分析效能,数据加载时间比传统SQL服务器减少了80%。
5 结束语
本文提出一种IoT PaaS平台,其目标在于能为客户端有效解决终端设备大数据的处理与分析,从而推导出智慧管理策略,以有效提高产能。在数据量与多样性方面为分布式储存架构与非结构化数据库的设计提供解决方案。在速度上,对于来自客户端的API执行要求,由于提供加解密的保护机制占据了执行的大多数时间,运行时间达毫秒级。在附加价值上,提供分布式计算的 Spark环境加上分布式文件系统的可扩充性,对于原始数据分析的规模与复杂度可再进行扩增以提升其结果的价值与效能。实验结果表明:数据查询速度与传统数据库相比有显著提高。未来研究将主要关注如何减少解密过程的时间。
