面向手语信息处理的维吾尔文本采集的研究
2019-06-15艾山江·亚生阿里甫·库尔班张丹丹
艾山江·亚生 阿里甫·库尔班 张丹丹



摘 要: 从自然语言处理以及深度学习的基本理念、原则出发,为基于中国手语的维吾尔文本信息处理研究提供数据资源,为面向手语信息的手语合成研究,为手语新闻文本编辑研究提供科学依据,对维吾尔文本进行自动分词、自动分句研究,并利用Word2Vec方法进一步建立文本词元库,通过这样保证训练语料的多元化及通用性。最后,利用词干提取方法以及分割字母的方式将维吾尔文本信息转换成手语文本信息,并在此基础上初步采集面向手语信息处理的维吾尔文本信息。实验表明该研究达到了预期目标。
关键词: 深度学习; Word2Vec方法; 手语合成; 文本词元库; 词干提取; 字母分割
中图分类号: TN912.34?34; TP311.1 文献标识码: A 文章编号: 1004?373X(2019)12?0136?04
Abstract: Proceeding from the basic concepts and principles of natural language processing and deep learning, research on automatic word and sentence segmentation is conducted for the Uyghur text, so as to provide data resources for Uyghur text information processing research based on Chinese sign language, and scientific basis for research on sign language synthesis and sign language news text editing based on sign language information. The Word2Vec method is used to further establish the text word element library, so as to ensure the diversity and universality of training corpus. The Uyghur text information is converted into the sign language text information by using the methods of word stem extraction and letter segmentation. On this basis, the Uyghur text information based on sign language processing is initially collected. The experimental results show that the research can achieve the expected research goal.
Keywords: deep learning; Word2Vec method; sign language synthesis; text word element library; word stem extraction; letter segmentation
0 引 言
聾哑人(听障人)是一个特殊的“少数民族”[1]。手语是聋哑人学习、生活及更好地融入主流社会的一种特殊交际工具,并且被越来越多的人了解和应用。21世纪以来,我国语言文字资源建设逐步向专用型的语料库方向发展,蒙、藏、维等少数民族语言语料库、地方方言有声数据库等成为语言资源建设研究的重点。目前我国高度重视针对手语方面的研究工作。
由于基于中国手语的其他少数民族自然手语的文本信息采集研究刚刚起步,在这种情境下,将面临很多新的问题和新的挑战。如语料库的词汇量不够全面,手语文本处理技术不够标准,手语文本信息不够全面等。
本文为解决上述叙述的几个问题,以及为手语合成研究[2]、手语新闻文本编辑研究[3]提供可靠数据依据,对于维吾尔文本进行分词、分句研究,与此同时,利用 Word2Vec方法扩大训练文本范围,进一步采用词干提取方法、分割字母方法对原文本进行手语研究,最后采集中国手语的文本信息。
此研究的提出对于自然手语文本处理研究[4]、深度学习[5]、机器学习[6]、自然语言文本挖掘[7]等方面有一定的现实意义。
1 中国手语及维吾尔自然手语
1.1 手势语
众所周知,手语作为一门共同语言,不同手语语言的手势语保持着一个完整的通用性结构。我国广大少数民族手语研究中的手势语皆来源于中国手语中的手势语。基于中国手语的维吾尔自然手语是在中国手语的基础上,按照常用、公用、标准化、基础性和科学性五个原则建立的维吾尔语手势语和手指语。从手语构成要素上分析,基于中国手语的维吾尔自然手语是由手指语、手势词汇和语法规则三个主要因素构成。从手语动作类型上分析,基于中国手语的维吾尔自然手语词汇包括单手手势语词汇及双手手势语词汇。例如“Oqush tarihi”(学历)为典型的双手手势语,其手语词的表示过程大约由4个连续的动作结合组成。值得强调的是,基于中国手语的维吾尔自然手语的手势语是来自于中国手语中的手势语,因此本研究的主要研究参考依据为中国手语。双手手势语图如图1所示。
图1 双手手势语图
下面要讨论手语中的单手手势语。单手手势语也作为手语的主要组成部分,它的整个动作表示是通过用单手的方式表示的。如“Ashqazan”(胃)作为单手手势语,其手语词的表达过程和组成结构截然不同。仅用右手放至身体的胃部,用一个单一的动作即可表示出“Ashqazan”(胃)的手语。单手手势语如图2所示。
图2 单手手势语
1.2 手指语
上述已讨论了关于手势语方面的基本概念,下面要进一步讨论关于手指语方面的主要理念内容。所谓的手指语是在面向手语信息处理中不可缺少的手语组成部分。手指语与手势语是不同的概念,凡是我国所有的手势语均来源于中国手语的手势语,而手指语则是根据不同语言的基本特征而有所不同。以基于中国手语的维吾尔手语为例,在维吾尔语中,一般的情况下,大部分词汇是由词干和附加成分(词缀)组成。词干是由手势语来表示,而附加成分则是通过手指语来表示。因此,在基于中国手语的维吾尔自然手语中,维吾尔语中的32个字母均为表示上述已提及的手指语。维吾尔手指语如表1所示。
表1 维吾尔手指语
2 训练文本的搜集
词汇和句子是作为文本语料的重要组成部分,需要进行海量的搜集。词汇是手语文本语料库收录的日常交流中较通用性的词汇。词汇可分为核心词汇和非核心词汇两大类。核心词汇指使用频率颇高而且具有具体性的词汇,而非核心词汇则与核心词汇恰恰相反。上述已闡述的维吾尔语手语词典中的维吾尔手势语均为属于核心词汇,而剩下的词汇便属于非核心词汇。至于句子搜集的必要性,可以进一步研究难度稍微大的研究对象以便提升研究效果。
至于分词研究,目前自动切分的有若干种切分方法,其中以空格为单位的分词法是既常用又传统的分词法之一。鉴于维吾尔语的特性与研究目的需求,且便于词汇研究,本文仍然采用空格分词方法。分句是以复句为单位,以自然语言学的基本理念、规则为科学依据,以文本处理以及数据挖掘的基本概念为指导,采用维吾尔语中的具有表示一条完整的句子的标点符号来进行分句。图3为自动分词、分句的描述结构图。
由图3可知,自动分词以及分句是整个研究的首要工作,因此要保证训练文本采集分析的完整性、客观性、准确性。那么下面需要严格遵守自然语言处理中文本处理的基本原则,在计算机科学及语言科学理念的指导下进行切分词和分句研究。
图3 训练文本采集描述图

3 基于Word2Vec方法的词元库的建立
Word2Vec方法是用来重构语义上下文的算法,它将词汇空间映射到一个高维实向量空间中。此系列算法非常注重词汇的上下文和语义,因此有别于传统NLP领域中将词汇看作是原子对象的做法,因而在NLP中取得了突破性的成功,而且被广泛应用。Word2Vec模型是根据文章中每个词的上下关系,把每个词的关系映射到同一坐标系下,构成一个大矩阵,反映每个词的关系。这些词的关系是通过上下文相关得出来的,具有前后序列性,因此对它再做一些相似词或者词语的扩展都有很好的效果。具体来说,“某个语言模型”指的是“CBOW”和“Skip?gram”。COBW和Skip?gram训练模型图如图4所示。
图4 COBW和Skip?gram训练模型图

连续Bag?of?Words (COBW):从上下文来预测一个文字。Skip?Gram:从一个文字来预测上下文。下面进行基于Word2Vec文档语义分析。假设本文希望找到某一个词汇的相似词汇列表。CBOW(Continuous Bag?of?Words Model)是一种根据上下文的词语预测当前词语的出现概率的模型。其是已知上下文,估算当前词语的语言模型,学习目标是最大化对数似然函数:
式中,w表示语料库C中任意一个词。从图4可以看出:CBOW输入层是上下文的词语的词向量;投影层对其求和,所谓求和,就是简单的向量加法;输出层输出最可能的w。由于语料库中词汇量是固定的[C]个,所以上述过程其实可以看作一个多分类问题。给定特征,从[C]个分类中挑一个,获取两个词的相似度并获取相似度列表。
给定两个词汇W1和W2,S=similarity(W1,W2),0≤S≤1为W1和W2的相似度。S=1为最相似,S=0为最不相似。在实验中,设定:Word1=“Adem”(人);Words2=[“Haywan(动物)”,“Ademlerni(人+ni)”,“ademlerden(人们+din)”,“Ademdin(人+din)”,“Tor(网络)”,“Ashpez(厨师)”]。
表2 遍历结果

由实验数据可知,6个实验对象中只有3个对象与Word1的信息较为相似,故相似度也同步较高。其中,第2、第3、第4词汇的词干是同一个词,即“Adem”(人),剩下的部分都是附加成分部分。因此,通过利用Word2Vec方法来扩大训练文本语料的范围及数量。Word2Vec方法的应用是在此研究中具有较为客观的实际应用价值。
4 手语文本信息的采集研究
上述已经对于基于中国手语的维吾尔自然手语的基本概念进行了简单的描述,下面将根据上述的训练文本语料进行进一步的手语文本处理研究。本文主要采用词干提取方法将句子转换成维吾尔语中的字母,通过该方法初步实现手势语、手指语的分开研究。手语文本语料采集研究主要步骤如下:
1) 对训练文本语料进行文本处理研究,即基于词干提取方法的信息处理研究以及以分割字母的方式将维吾尔文本中的附加成分信息转换成维吾尔手指语信息。
2) 将上述已得到的文本信息与手势语信息进行匹配。
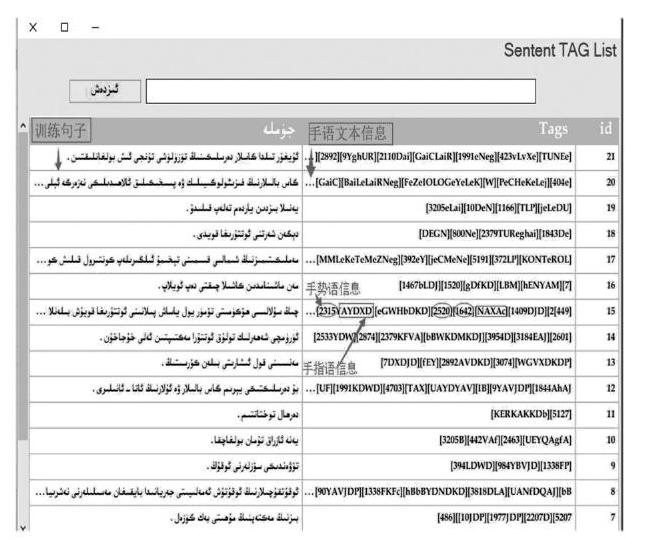
3) 将步骤2)和步骤3)结合在一起之后得到一个手语文本信息。在此信息中,有两种信息,分别为数字和英文字母,其中数字表示手势语信息,英文字母表示手指语。
总之,本次研究中,通过以上3个步骤初步实现了手语文本信息的采集研究。本研究的主要实现结果如图5所示。在此值得提及的是,其手语文本信息为将来的面向信息处理的手语合成研究提供了较为良好的数据资源以及信息依据,将来的研究者可以根据此手语文本信息结果进行进一步的手语合成研究。
图5 手语文本信息结果图
5 结 语
本文從计算机科学与语言学的角度阐述了关于基于中国手语的维吾尔自然手语的概念及采集素材语料方法。通过建立文本训练词元库来扩大训练文本语料的范围、数量。在建立词元库时,利用目前在自然语言处理、深度学习、机器翻译、文本挖掘等领域中常用的以及比较受欢迎的Word2Vec方法来实现词元库的建立。最后,采用词干提取方法以及分割字母的方式对文本信息进行手势语与手指语的分开研究,并在此基础上初步采集了面向手语信息处理的维吾尔文本信息。结果表明,本研究为聋哑人在以后的生活、学习、工作等各方面都起到积极的应用性作用。然而,目前手语研究中依然存在一些缺陷及不足之处,此缺陷需要不断的创新及探索。因此在新时代要以新的状态、新的方法去完善此方面的研究方法及技术。
注:本文通讯作者为阿里甫·库尔班。
参考文献
[1] 李恒.手语语言学方法论研究综述[J].中国特殊教育,2012(6):22?26.
LI Heng. A review of the researches into the methodology of sign language [J]. Chinese journal of special education, 2012(6): 22?26.
[2] 张宁生.手语翻译概论[M].郑州:郑州大学出版社,2009.
ZHANG Ningsheng. General introduction to sign language translation [M]. Zhengzhou: Zhengzhou University Press, 2009.
[3] 李斌.用ELAN建设单点方言多媒体语料库[J].方言,2012(2):178?190.
LI Bin. Construction of single?point dialect multimedia corpus using ELAN [J]. Dialect, 2012(2): 178?190.
[4] 葛锐.汉语分词技术初探[J].软件,2013,34(3):140?141.
GE Rui. Preliminary study on Chinese word segmentation [J]. Computer engineering & software, 2013, 34(3): 140?141.
[5] 赵小兵,张志平,田寄远.现代汉语基本词汇自动识别方法研究[M].北京:中央民族大学出版社,2012.
ZHAO Xiaobing, ZHANG Zhiping, TIAN Jiyuan. Research on automatic recognition method for basic vocabulary of modern Chinese [M]. Beijing: China Minzu University Press, 2012.
[6] 阿里甫·库尔班,吾买尔江·库尔班,尼加提·阿不都肉苏力.维吾尔语框架语义知识库的概念设计[J].中文信息学报,2010,24(4):114?118.
Alifu Kuerban, Wumaierjiang Kuerban, Nijat Abdurusul. Conceptual design of Uyghur FrameNet [J]. Journal of Chinese information processing, 2010, 24(4): 114?118.
[7] 倪训博,赵德斌,高文,等.非特定人手语数据生成及其有效性检测[J].软件学报,2010,21(5):1153?1170.
NI Xunbo, ZHAO Debin, GAO Wen, et al. Data generation and its validity inspection of signer?independent sign language [J]. Journal of software, 2010, 21(5): 1153?1170.
[8] 易晓芳,卡米力·木依丁,艾斯卡尔·艾木都拉.基于分段式前景涂抹和背景细化的文本行分割[J].计算机工程,2013,39(5):204?208.
YI Xiaofang, KAMIL Moydin, ASKAR Hamdulla. Text line segmentation based on segmented foreground daub and background thinning [J]. Computer engineering, 2013, 39(5): 204?208.
[9] 朱兰,袁保社,余伟.基于滴水算法的印刷体维吾尔文切分方法[J].计算机技术与发展,2015(7):107?110.
ZHU Lan, YUAN Baoshe, YU Wei. Segmentation method of printed Uyghur based on drop fall algorithm [J]. Computer technology and development, 2015(7): 107?110.
[10] QIU L K, HU H L, WU Y F. Corpus?based method for differentiating genuine and spurious combinational ambiguity [J]. ICIC express letters, 2013, 7(4): 1437?1441.
[11] MASAKI M, MASAO U. Compound word segmentation using dictionary definitions: extracting and examining of word constituent information [J]. ICIC express letters?Part B Applications, 2012, 3(3): 667?672.
[12] ZHENG H T, KANG B Y, KIM H G. Exploiting noun phrases and semantic relationships for text document clustering [J]. Information sciences, 2009, 179(13): 2249?2262.
[13] LIU J Y, LIU Y. Resolution to combinational ambiguity of Chinese word segmentation [C]// Proceedings of International Conference on E?learning, E?Business, Enterprise Information Systems, and E?Government. Hong Kong: IEEE, 2009: 141?145.
[14] GE Chunbao, CHEN Yiqiang, YIN Baocai, et a1. A new method for motion retargeting for the hand gesture [J]. Chinese journal of computers, 2006, 29(10): 1850?1855.
[15] RYU J, KOO H I, CHO N I. Word segmentation method for handwritten documents based on structured learning [J]. IEEE signal processing letters, 2015, 22(8): 1161?1165.
[16] KAVALLIERATOU E. Word segmentation using Wigner?Ville distribution [C]// Proceedings of 13th International Conference on Document Analysis and Recognition. Tunis: IEEE, 2015: 701?705.
