融合Attention多粒度句子交互自然语言推理研究
2019-06-06程淑玉郭泽颖
程淑玉,郭泽颖,刘 威,印 鉴
1(安徽电子信息职业技术学院,安徽 蚌埠 233060)2(中山大学 数据科学与计算机学院 广东省大数据分析与处理重点实验室,广州 510006)
1 引 言
近来年,随着自然语言处理技术的发展,人们开始研究让机器理解人类自然语言的方法,希望计算机不仅能够快速获取并处理语言中的表层信息,更能实现对文本的深层次 “理解”.在自然语言“理解”过程中重要的一部分就是对语义的推理,通过语义推理能够让计算机判断出句子之间的逻辑关系.
自然语言推理(NLI)定义为句子对之间的有向推理关系,是自然语言处理领域一项基础性工作[1],其基本任务是判断由前提句子(P)的语义是否能推断出假设句子(H)的语义,如果句子H的语义能从句子P的语义中推断出来,则句子对P与H之间是蕴含关系,如表1所示.
传统自然语言推理方法主要依赖人工的文本特征,结合机器学习方法对特征向量进行分类;基于深度学习的方法主要在深度网络中,通过将句子映射到向量空间的方式,使句子特征的计算和句子特征之间的关联性更容易被挖掘,从而能够很好的学习句子特征,包括序列学习、句子的表示学习和句子匹配等相关工作.
表1 自然语言推理任务样本
Table 1 Samples of NLI task

示例类型P:希拉里是前任美国总统奥巴马的妻子.H:希拉里是位女性.蕴含(Entailment)P:希拉里是前任美国总统奥巴马的妻子.H:希拉里是总统.矛盾(Contradic-tion)P:希拉里是前任美国总统奥巴马的妻子.H:希拉里有两个女儿.独立(Neutral)
句子匹配主要任务是聚合前提句子和假设句子之间的组合特征,传统方法都是针对两个句子进行向量间匹配[2],或先对两个句子之间的词语或者上下文向量做匹配,匹配结果通过一个神经网络聚集为一个向量后再做匹配[3,4],也有引入注意力机制[5,6]加以考虑,现阶段都取得了不错的效果,但是还存在以下问题:
1)基于词语级别或者句子级别的匹配都是单粒度同层次的匹配,这种匹配方式只关注捕捉句子自身的语义信息,忽略了句子之间的组合信息和交互特征,造成句义损失,不能有力的辨别句子对的蕴含关系.
2)一般的序列输入方式捕捉的是句子的全局特征分布,没有兼顾到句子局部特征的定位,导致句子语义信息不足,且基于文本相似度的方法容易丢失语义信息,降低模型的质量.
针对以上问题,本文提出融合Attention的多粒度句子交互自然语言推理模型,主要贡献如下:
1.针对句子间组合信息和交互特征问题,提出多粒度和不同层次的句子交互策略,对词语和句子进行交互建模,捕捉两个句子之间的交互特征,减少句义信息损失,提高蕴含关系识别准确度.
2.针对全局特征和局部特征兼顾问题,利用BiLSTM模型对序列信息处理优势,融合Attention机制捕句子交互过程中单词级特征的重要性,并将向量元素的对应计算作为两个句子向量的匹配度量,能有效的补充句子信息,提升模型效果.
2 相关研究
传统的自然语言推理方法有基于词袋模型[7]、 基于 WordNet 词典[8]、基于 FrameNet 框架[9]、基于句法树[10],这些方法都是基于特征分类的方法,对句子自身包含的语义研究并不多,而且基于文本相似度方法不具备推理性,“相似≠ 蕴含”,因此无法捕捉深层的句子含义.随着Word2Vec(2013)[11]和GloVe(2014)[12]模型为代表的基于深度学习的词向量的兴起掀开了基于深度学习的自然语言推理研究浪潮.Bowman[2]等人提出了LSTM模型,首先尝试使用基于句子编码的深度学习方法和基于词语级别的分类器方法来解决自然语言处理问题,验证了深度学习在自然语言推理上的有效性,但是在输入长句时,编码成的中间向量的信息损失也加大,生成的句子精确率也随之降低.Attention方法有效的缓解了上述问题,Rocktäschel[13]等人提出了word-by-word Attention模型,该模型分别用两个LSTM来学习前提句子和假设句子,通过在编码前提句子时考虑假设句子中每个词的信息,将假设句子中每个词与前提句子中的词产生对应的软对齐,获得假设句子中每个词对应的前提句子中的上下文信息,这种方法能缓解长句信息损失,其本质还是通过两个句子向量匹配来推断蕴含关系,无法匹配到细粒度的词语匹配关系,对中立关系的识别不是很好.为了更好的推断句子间词和短语级别的匹配情况,Wang等人[14]提出mLSTM模型,该模型对前提文本和假设文本建模的两个LSTM模型产生的注意力向量拼接,进行匹配后再预测,这个方法可以很好的识别词和短语的匹配情况,却无法兼顾句子的全局特征的分布与局部特征的定位.Liu等人[15]提出使用双向的LSTM模型(BiLSTM)有利于提取句子的全局信息而不受句子语序影响,同时融合“Inner-Attention”机制,利用句子本身的表示来进行指导Attention,进一步提升了模型的识别效果,但是没有考虑句子间的组合特征.Wang等人[16]的BiMPM模型提出了对句子匹配工作进行多视角的计算方法,从多个视角去提取句子的特征,通过对给定的两个句子分别编码,从多个方向进行匹配,能够充分提取句子的语义信息.本文借鉴了多视角匹配的思想,提出了多粒度、不同层次的句子交互策略,利用深度神经网络模型(BiLSTM)获取句子的全局特征,融合注意力机制提取句子的局部特征,在对句子进行编码的过程中,采用不同的交互策略对输出的上下文向量进行多样性匹配,通过最大池化、加权平均池化等操作,完成句子对的建模,其中最大池化仅保留给定范围的最大特征值,有助于强化重要语义,如公式(1)所示;平均池化是对给定范围的所有值取平均,全面考虑每个方面的局部信息,避免信息丢失,如公式(2)所示;最后整合句子间的匹配向量进行蕴含关系的预测.这种方法能够捕捉两个句子之间的多样性交互特征,减小句子损失,侧重关注前提文本到假设文本之间的正向蕴含关系的识别,提高模型预测质量.
(1)
(2)
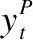
3 模型设计
为了能获取自然语言推理所需的更多语义信息,降低句子的语义损失,本文从句子匹配角度,提出一个多粒度、不同层次句子交互自然语言推理模型.整个模型框架如图1所示,从下至上分别是输入层、句子编码层、交互层、MLP和Softmax分类层,下面简单描述下该模型.

图1 融合Attention多粒度句子交互自然语言推理模型框架Fig.1 Architecture of multi-granularity sentence interaction natural language inference model based on Attention mechanism
在该模型中,输入层首先将前提句子P和假设句子H独立进行编码,将句子中的每个单词表示为d维向量;编码层利用BiLSTM模型融合Attention机制对输入的单词序列逐个进行编码生成句子向量,但保留每个隐藏层单元输出的上下文向量,将上下文信息融合到P和H每个时间步的表示中;交互层就是比较P和H每个时间步的上下文向量和所有向量,为了比较上下文向量,我们设计多粒度、不同层次的交互匹配方法,对P和H在编码过程中进行文本语义对齐,利用不同的交互策略,得到融合注意力权重上下文向量,结合最大池化或者平均池化的方法进行句子匹配生成新的表示向量.本文提出的交互策略是融合注意力机制利用句子间交互特征的加权对句子建模,交互的基本单位是BiLSTM模型的每个时刻的输出向量yt,即每个时刻上下文的语义信息;最后将输出的匹配向量传入MLP层进行聚合处理后传至分类层,使用3-way Softmax函数为激活函数,输出分类的结果,标签即蕴含、中性和矛盾.
(3)
3.1 编码层
本层的主要工作是利用BiLSTM模型融合Attention机制对输入层的单词向量序列进行编码,将其转换为一个独立的句子表示向量.融合Attention机制的自然语言推理模型有基于静态Attention[13]和基于动态Attention[14],其核心思想都是根据一句话的信息自动地关注另一句话中重要的信息,但在现实生活中,人在接收一句话时,会凭经验判断出这句话哪些词比较重要,而不需要根据其他句子信息,借鉴该思想,我们利用句子本身的表示来指导Attention.
Attention机制为输入特征向量计算一个注意力分布,对不同的特征向量赋予不同权重,从而实现注意力的分配,计算方法如公式(4)-公式(6)所示.
yt=G(yt-1,st,ct)
(4)
st=f(st-1,yt-1,ct)
(5)
(6)
其中st为t时刻编码器的隐藏状态,即隐藏层的输出,ct为注意力得分,包含了输入序列对当前输出重要性权重分布.
通过注意力权重的计算,最终得到是参数对历史隐藏层状态加权求和的结果向量.因此,注意力机制侧重于对某个输出结果辨识出输入序列中不同元素的贡献度,即捕捉句子对中不同特征的重要性,能减少计算任务的复杂度.
3.2 交互层
句子经过BiLSTM编码后生成句子表示向量,传入到交互层进行句子匹配工作,句子匹配是指比较两个句子并判断句子间关系,其主要工作是聚合前提句子和假设句子之间的组合特征.传统的匹配方法主要采用同一层次的词与词交互匹配[13]或者句子与句子交互匹配[2],这种单粒度同一层次的匹配方法只关注捕捉句子自身的语义信息,忽略了句子内部词语之间及不同层级句子之间的组合特征,造成语义损失.在自然语言推理任务中,判断句子对蕴含关系是否成立要考虑前提句子P对假设句子H的影响,所以在对假设句子H建模时通过对每个时间步的匹配计算,从不同粒度和层次引入P的交互信息,能减少语义损失.本文考虑了推理关系涉及的方向性特征和句子自身具备的多粒度信息,结合Attention机制在BiLSTM模型基础上提出一种多粒度不同层次的句子交互匹配方法.
本文提出的方法从词语和句子两种粒度出发,将词语、句子之间的注意力权重作为前提句子与假设句子之间的交互信息,通过多样性交互策略获得更丰富的语义组合特征,与上下文向量进行加权,池化输出句子新的表达向量.为了比较前提句子P与假设句子H,本文设计了6种交互策略,分别是同一层次单粒度的3种交互和跨层次多粒度的3种交互,并将各种策略生成的句子表达向量拼接进行策略融合.
3.2.1 单粒度交互
单粒度交互是指词语粒度或者句子粒度的交互,通过对句子对建模过程中产生的上下文向量进行全匹配,能够抽取词语之间的交互特征.包括句子内词粒度交互、句子间词粒度交互、句子间句粒度交互,如图2所示.
1)句子内词粒度交互
如图2(a)所示,句子内词粒度交互是指对句子本身的上下文向量之间进行注意力权重的计算,这种方法能捕捉到句子内的语义特征,突出每个词语在句子中的重要性,计算方法如公式(7)-公式(8)所示,其中yP和yH为前提句子P和假设句子H本身的上下文向量,fm表示匹配函数,用来度量向量之间的匹配度.
(7)
(8)
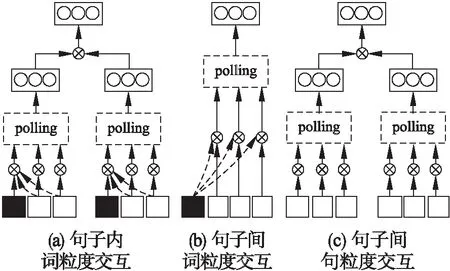
图2 单粒度交互,图中并行网络结构的最左侧灰色矩形表示该句子的某个时刻上下文向量,右侧所有的矩形表示该句子每个时刻上下文向量,下同Fig.2 Single-granularity interaction,the left gray rectangular of the parallel network architecture depicts context vector at a certain moment and all of the right rectangular depicts context vector at each moment of the sentence,the same as below
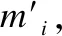
(9)
(10)
2)句子间词粒度交互

SP×H=(yP)T·(yH)
(11)
(12)
(13)
(14)
3)句子间句粒度交互
如图2(c)所示,句子间句粒度交互就是直接对BiLSTM层建模后的两个句子表示向量作对应元素的匹配计算,仅保留最大的匹配结果.该方法能够获得句子级别的交互信息,得到句子对语义关系推断的贡献度,计算方法如公式(15)所示,利用最大池化筛选特征值.
y=(m)max-polling=max[yP⊙yH]
(15)
3.2.2 多粒度交互
多粒度句子交互是指词语与句子粒度交互,将句子向量和词语的上下文向量匹配,抽取跨层级的词语和句子特征,包括词语-句子全交互、融合注意力机制的交互两种方法,如图3所示.这种方法不仅丰富了句子建模中的语义信息,同时强化了自然语言推理任务中正向蕴含的推断.

图3 多粒度交互Fig.3 Multi-granularity interaction
1)词语与句子全交互
如图3(a)所示,词语与句子全交互就是将句子P的每一个前向(反向)上下文向量和句子H的表示向量作比较,计算方法如公式(16)所示.这种方法能够得到句子P中每个词语和句子H的语义相似性.
(16)
2)融合注意力的平均池化匹配
如图3(b)所示,融合注意力机制的交互能够得到句子 P与H的交叉粒度信息,同时利用注意力机制进行特征筛选.
首先计算句子P和句子H中每一个上下文向量之间的匹配值s,如公式(17)所示.
(17)
随后利用s对句子H中的每个前向(反向)上下文向量做加权求平均操作,得到句子H的表示向量,再用句子P中的每个前向(反向)上下文向量与句子H的表示向量匹配.
(18)
公式(18)表示对句子H的所有上下文向量加权取平均,最后通过公式(19)比较句子P的上下文向量和这个平均值向量:
(19)
3)融合注意力的最大池化匹配
融合注意力的最大池化交互如图3(b)所示,整个交互过程可以参考平均池化匹配,只是平均变成了取最大计算公式如公式(20)-公式(21)所示.
(20)
(21)
3.2.3 匹配函数
句子间匹配本质就是对句子对向量进行距离的计算,本文采用的距离计算方法是向量相减后对应元素相乘(Element-wise Subtraction),该方法是Tai等人[17]在2015年提出的一种向量距离计算方式,能够将交互匹配计算更为精细,同时又免去参数引入的问题,计算方法如公式(22)所示.
fm(v1,v2)=(v1-v2)⊙(v1-v2)
(22)
4 实验结果及分析
4.1 实验数据集及评价指标
数据集:本文实验采用的是斯坦福大学发布的SNLI[6]语料,该语料一共包含570,000的人工手写英文句子对,其中549367 对用于训练数据,9842对用于验证数据,9824对用于测试数据,对测试数据每个句子对除了前提文本、假设文本、标签外还包含五个人工标注,数据集样例如表2所示.
表2 SNLI数据集样例
Table 2 Sample dataset on SNLI

前提文本标签/人工标注假设文本A man inspects the uniform of a figure in some East A-sian country.contradictionC C C C CThe man is sleep-ing.An older and younger man smiling.neutralN N E N NTwo men are smil-ing and laughing at the cats playing on the floor.A black race car starts up in front of a crowd of peo-ple.contradictionC C C C CA man is driving down a lonely road.A soccer game with multi-ple males playing.entailmentE E E E ESome men are pla-ying a sport.A smiling costumed woman is holding an um-brella.neutralN N E C NA happy woman in a fairy costume holds an umbrella.
我们对实验数据集进行了分析,发现训练集中包含“蕴含”标签句子有183187个,“中性”标签句子有182764个,“矛盾”标签数据有183187个;验证集中包含“蕴含”标签句子有3329个,“中性”标签句子有3235个,“矛盾”标签数据有3278个;测试集中“蕴含”标签句子有3368个,“中性”标签句子有3219个,“矛盾”标签数据有3237个,由此判断整个数据集的标签分布较均衡,因此实验过程中不需要考虑不同标签的权重.
评价指标:自然语言推理任务的评价指标是分类准确度,计算方法如公式(23)所示.
(23)
4.2 交互策略对比及分析
在实验中我们采用300D GloVe来作为预训练词向量,且在训练的过程中词向量不予更新,采用Adam优化方法更新参数,设置单词的最大长度为15,句子最大长度为40,字符向量维度为20D,batch大小设为128,BiLSTM层维度为300,学习率设为0.0001.为了缓解模型过拟合问题,我们在模型输入输出处应用dropout,设dropout设为0.3,在损失函数中加入了一个l2正则项,应用Early stopping保持模型的泛化能力,设Early stopping为5.
我们将BiLSTM模型作为基准模型,通过对不同粒度交互策略的贡献度进行实验分析,可以发现不同粒度融合模型在训练过程中的表现优于BiLSTM模型,如图4和图5所示.
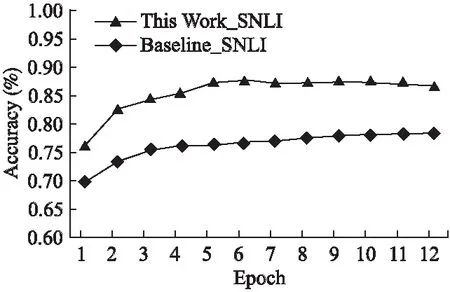
图4 SNLI交互策略的对比实验(准确率)Fig.4 Interaction strategy comparison experiment on SNLI(Accuracy)
针对3.2节的交互策略,我们进行了详细的实验,对比分析不同策略下的性能,结果如表3所示,我们可以得到如下结论.
1)无论是单粒度交互还是多粒度交互,不同粒度的交互策略融合都能够提升模型的表现.
2)在SNLI语料上单粒度策略融合模型准确率分别比句子内交互策略提高3.6%、比句子间交互策略提高2.4%,多粒度策略融合模型比词语-句子交互策略提高0.4%、比融合注意力的池化提高0.5%,说明句子间的交互信息对模型的提升效果大于句子内交互,且词语与句子的交互信息对句子推理最为重要.
3)整个组合模型准确率比单粒度策略融合模型提高1.8%,比多粒度策略融合准确率提高0.2%,说明本文提出的交互策略能有效提升模型表现效果.

图5 SNLI交互策略的对比实验(平均损失)Fig.5 Interaction strategy comparison experiment on SNLI(Average Loss)
4.3 模型性能分析
在本节,我们将本文设计模型与下面几种优秀的模型进行了对比:
LSTM[18]:采用word-by-word方法进行前提句子和假设句子的匹配.
Tree-based CNN[19]:采用基于树的卷积过程提取句子结构特征然后通过最大池化聚合并分类.
mLSTM + Attention[20]:将对前提句子和假设句子建模的两个LSTM模型产生的注意力向量拼接,进行匹配后再预测.
表3 交互策略对比实验结果表
Table 3 Result of the interaction strategy comparison experiment

实验内容匹配策略Acc(%)单粒度 句子内交互82.1句子间交互83.3单粒度策略融合85.7多粒度 词语-句子交互86.9融合注意力的池化86.8多粒度策略融合87.3组合模型不同粒度融合87.5
可分解的注意力模型[6]:对前提句子和假设句子的每一个单词对应匹配,结合神经网络和矩阵运算将两个文本的注意力机制求解问题分解为两个子问题.
表4 模型对比实验结果表
Table 4 Comparison results of related model

来源模型Acc(%)Bowman LSTM80.6Mou Tree-based CNN82.1WangmLSTM + Attention86.1Parikh 可分解的注意力模型86.8Wang BiMPM86.9本文多粒度信息交互87.5
BiMPM[16]:对前提句子和假设句子分别编码,从两个方向P→ H,H→P对其匹配.在匹配过程中,从多视野的角度,一个句子的每一步都与另一个句子的所有time-step对应匹配.最后用一个BiLSTM被用来集合所有匹配结果到一个固定长度的向量,连上一个全连接层得到匹配的结果.
表4为不同模型的在SNLI语料上的实验结果,可以看出引入Attention机制的模型准确率比没有引入的要高,说明Attention机制的引入对模型的表现效果具有提升作用,在同时也可以看到本文模型的准确率达到了87.5%,优于同类最优模型.
5 结束语
本文从句子匹配角度对自然语言推理进行了研究,针对传统同一层次的单粒度匹配中存在句子语义损失和信息不足问题,首先我们引入了Attention机制捕获句子的局部特征,对不同特征计算概率分布,减小处理高维输入数据的计算负担,同时提高模型的预测质量;其次提出了多粒度不同层次的句子交互匹配方法,在句子建模过程中运用不同的交互策略,利用不同层次和不同粒度之间的信息交互获取丰富的语义信息,这种方法在计算过程中会直接将句子中任意两个上下文向量、或两个层次的表示向量之间的关系通过一个计算步骤直接联系起来,所以序列中不同位置、不同粒度的特征之间的距离可以被极大地缩短,通过实验验证这种不同粒度不同层次融合方法要优于单粒度和多粒度交互方法.最后将本文的方法与其他优秀的自然语言推理模型进行了实验比较,准确率达到87.5%,说明了本方法在最佳配置下的表现要优于同类其他最优模型.
