一种结合随机游走和粗糙决策的文本分类方法
2019-06-06柴玉梅王黎明
韩 飞,柴玉梅 ,王黎明 ,刘 箴
1(郑州大学 信息工程学院, 郑州 450001)2(宁波大学 信息科学与工程学院,浙江 宁波 315211)
1 引 言
伴随着互联网发展的热潮以及人工智能领域技术的不断革新,赋予机器情感已成为研究中的重要课题.情感分类作为其中的重要手段,在社会媒体处理领域有了良好的发展,如舆情监控、商务决策等[1].由于各大主流媒体平台的开放性,人们通常会在评论区表达其主观情绪特征,因此针对用户行为偏好的分析具有很高的研究价值[2,3].
由于用户在浏览网页时其行为的随机性与模糊性,有学者通过用户对网页的点击行为进行分析并建立模型,从而实现针对用户行为的网页排序,并取得了良好的效果.本文把随机游走模型在网页排序中的方法应用在词网络图的构建中,结合粗糙集模型,把词网络图构建后的情感词极性分析结果进行离散化处理,并对属性值进行加权,扩充了随机游走模型的使用范围,通过最终的粗糙决策置信度对加权后的属性文本进行类别划分.
模糊性词汇的判别一直是文本分类中的重要课题,本文通过对数据集的标词、分词等处理,对词汇进行特征选择,得到候选特征,提出基于扩展随机游走模型的情感词极性判别算法,得到模糊性词汇的情感极性,进一步得到候选属性集.结合词汇情感极性,建立文本情感决策表.运用粗糙集的知识,对候选属性进行离散化处理,提出基于粗糙集的文本情感类别判定模型,从而得到最终文本情感分类.本文流程框架图如图1所示.
2 相关工作
文本情感分类是指通过分析文本中的立场、观点、态度等主观信息,挖掘文本中的情感倾向,从而对其倾向类别进行判定,目前已经提出了一系列的情感分类方法[4-8].

图1 文本类别判定流程框架图Fig.1 Flow chart of text categorization decision
由于社交媒体的开放性不断增加,评论和博客可能被分为不同的极性组,如正、负和中性,以便从输入数据集中提取信息. Tripathy等人[4]利用有监督机器学习方法对这些评论进行分类,使用朴素贝叶斯(Naive Bayes,NB),最大熵(Maximum Entropy,ME),随机梯度下降(Stochastic Gradient Descent,SGD)和支持向量机(Support Vector Machine,SVM)方法,依据精度,召回率,F度量和准确率等评价标准,对不同方法的准确性进行了严格的考察.Turney等人[5]以情感词为中心,采用点互式信息检索(Pointwise Mutual Information,PMI)和潜在语义分析(Latent Semantic Analysis,LSA)两种方法用于评估词关联度,并取得了较高的准确率.在对情感类别划分的基础上,有些学者利用算法框架对情感分类结果进行优化.Silva等人[6]提出了一种半监督学习框架,从无标签数据构建的相似性矩阵中捕获无监督信息,并与分类器相结合,通过自训练算法来产生更好的情感分类结果.实验数据集从Twitter中选取,结果表明,提出的框架可以提高情感分类的准确性.由于文本维度通常很庞杂,对特征的降维也是情感分类中必不可少的工作.吴钰洁等人[7]通过建立一种概率图模型,并用其对词语中的情感概率值进行计算,再通过信息熵公式归一化其情感特征值,最后进行情感分类,实验也表明其方法的有效性.在文本评论中,用户偏好使得情感判定类别产生倾斜,Tian等人[8]提出了一种基于句子的实例转移方法,通过使用辅助数据集(源数据集)来处理不平衡的正负文本产品评论数量.该方法结合了规则和监督学习混合方法来识别每个产品评论的主题句,并将主题句的特征集添加到情感分类的特征空间.
随机游走模型是针对用户浏览网页的行为建立的抽象概念模型.Rao等人[9]提出一种基于单词极性构图的问题求解框架,每个节点表示要确定其极性的单词,并且可以有两个标签:正或负.Kok等人[10]提出了一种基于随机游走模型的方法来学习双语平行语料库.文中采用随机游走来计算达到释义排序所需的平均步数,而更好的“更接近”感兴趣的词组.随机游走模型也可用于多标签分类学习中,郑伟等人[11]提出了一种基于随机游走模型的多标签分类算法,将多标签数据映射成为多标签随机游走图,有效解决多标签分类问题.
粗糙集理论是一种比较新的处理模糊性和不确定性的软计算工具,被认为是前沿领域.基于粗糙集的离散化具有一定的特点,必须满足决策系统离散化的一致性要求.张娇鹏等[12]提出一种面向数据取值更新的批处理机制,根据粗糙集和信息熵的概念,提出了一种面向数据取值动态变化数据集的特征选择方法,可一次处理一组变化数据,拓展了粗糙集在特征选择方向的应用,实验证明了算法的有效性.Sun等人[13]提出了一种基于决策属性的连续属性离散化方法,该方法考虑了决策属性的重要度,连续属性依照重要度依次离散化,实验结果表明该方法有效减少断点并提高识别精准度.孙梦等人[14]提出了一种基于粗糙集的优势关系排序问题,利用向量相似度和并列对象准则对排序向量进行赋权,得到最终排序结果.实验表明其方法的合理性.Chen等人[15]提出了一种区间数离散化算法,基于多属性决策建立区间决策样本,确定区间对象间的相似矩阵,并利用最小离散区间得到最终离散化结果,实验证明了算法的有效性.
3 相关概念
3.1 基于图论的随机游走模型
随机游走模型可以预测不同节点之间的潜在关系,也可应用于文本分类中[16].通过构建图框架,进而找出相邻节点间的关系,每个节点可以用一个单词进行表示,如果有多关系节点,那么就调整节点间的边缘强度[17].
使用随机游走模型来识别单词的极性,可以假定使用一个词网络,其中一些词被标记为正或负.在这个网络中,如果有关联,两个词是相连的.不同来源的信息来决定两个词是否相关.例如,一个词的同义词都是语义相关的,连接语义相关词背后的隐藏信息是单词往往有相似的极性.现在假定一个随机游走者沿着网络从一个未标记的词w开始,随机游走一直持续到游走者走到标记的词为止.如果词w是正的,那么随机游走击中一个正词的概率就更高;如果w是负的,那么随机游走击中负词的概率就更高.因此,如果词w极性为正,那么从w开始到正节点的随机游走的平均时间应该比从w开始到负节点的随机游走的平均时间小得多.如果w没有明确的极性,可以说它是中性的.
假设在词关联图G中,从一个具有未知词极性的节点i开始,在第一步后移动到节点j的概率为Pij.如果我们重复随机游走N次,则可以将正/负词的游走结束次数的百分比作为其正/负极性的指标.从w开始的随机游走到达正/负节点的平均时间也是其极性的指标.
W是词典中词汇的集合,构建一个图G,其节点V都是W中的词汇,边E是对应词汇间的相关性.通过归一化节点i之外的边的权重,定义从节点i到节点j的转移概率P[18]:
(1)
式中,k代表与i相邻的所有节点,P代表在第t步的节点i到第t+1步的节点j的转移概率.注意到,权重Wij的矩阵是对称的,而转移概率矩阵P由于节点出度归一化,不一定是对称的.
把首次达到目标节点所用的时间h(i|k)定义为随机游走者第一次进入状态节点k所用的步数平均数[19],初始i≠k.G=(V,E)是具有V个顶点,E条边的图,顶点集S是V的子集,S∈V,在图G中第i点开始游走,i不属于S.因此,第一次到达目标节点所用时间h(i|S)可以形式化描述为:

(2)
其中,Pij是i到j点的转移概率,h(j|S)表示节点j第一次到达目标节点S所用的时间.
3.2 粗糙集基础理论
粗糙集是一种有效的数学工具,用于处理数据的不完整和不确定的信息,是由波兰科学家Pawlak[20]在1982年提出.使用粗糙集时,数据必须是离散的,但实际上决策表的大多数属性是连续的,这一特性也大大限制了粗糙集的使用范围,因此,连续的属性应该被替换为有限的语义变量,这就是连续属性的离散化处理.在离散化过程中,为使属性可以满足粗糙集理论对属性约简和规则归纳的需求,需要依赖不同的离散化方法,如区域知识离散化、等距离散化、等频离散化等.
定义1.(信息集合系统)一个信息集合系统可以用一个四元组表示:IS=
1)U为研究对象的非空有限集合,即论域.
2)A为属性的非空有限集合,即属性集.
3)V=∑a∈AVa为属性A的值域,其中Va为属性a∈A的值域.
4)f:U×A→V为信息函数,表示对每一个x∈U,a∈A,f(x,a)∈Va.
如果A中的属性表示为分类的结果,则信息系统IS被定义为DT=(U,C∪D,V,F),其中A=C∪D,C∩D=φ,C为条件属性集,D为决策属性集,该信息系统也被称为决策表.
定义2.(不可分辨关系)给予决策表DT=(U,C∪D,V,F),对于任意属性集B⊆C∪D,则B的不可分辨关系IND(B)定义为[21]:
IND(B)={(x,y)∈U×U:∀a∈B(f(x,a)=f(y,a))}
(3)
不可分辨关系IND(B)把论域U划分为相互不连接的子集,即等价类.IND(B)的所有等价类的集合记为U/IND(B),简记为U/B.U/B也可称之为IND(B)对论域U的划分,对任意X⊆U,X/B={E∩X:E∈U/B∧E∩X≠Ø}称为IND(B)对X的划分.对任意x∈U,使得[x]B表示为IND(B)中包含x的等价类.
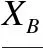

(4)
定义4.(正域)给予决策表DT=(U,C∪D,V,F),对于任意属性集B⊆C∪D,称POSB(D)为D的B正域.其所有对象为论域U的子集,使得U/D能准确划分来自属性B的集合,其中[22]:
(5)

(6)
定义5.(约简)给予决策表DT=(U,C∪D,V,F),B⊆C∪D,a∈B,若IND(B)=IND(B-{a}),则a为B中冗余的,否则称a为B中必要的.若任一a∈B都为B中必要的,且IND(C∪D)=IND(V),则称B为V的一个约简[23].
定义6.(相对决策约简) 给予决策表D=(U,C,D),B⊆C,a∈B,若B为D中独立的,且POSB(D)=POSC(D),则称B为C的一个D相对决策约简.
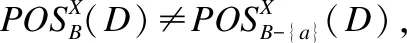

由于Pawlak的粗糙集模型更适合于处理含有离散属性的数据,所以在粗糙集中,连续属性的离散化应当作为数据的预处理步骤.因此,连续属性离散化是粗糙集中的一个重要工作.目前的离散化方法主要分为两种,一种是在有监督和无监督框架内的算法,一种是基于单变量和多变量的算法.
有监督算法通过考虑分类信息进行离散属性,如NB算法.在NB算法中,通过构造切割点对所有属性进行排序.例如,连续属性v的属性值为r0,…,rn,决策类d(r0),…,d(rn),则v中的属性切割点Ca=(ri+ri+1)/2,其中d(ri)≠d(ri+1),0≤i≤n-1.无监督算法则不考虑分类信息,其效果没有有监督算法好,如EF(Entropy-Feature)算法[24].
单变量算法在一个决策表中一次只考虑一个独立的条件属性,多变量算法则是同时考虑几个条件属性,通常情况下,多变量算法是考虑所有属性在内的.目前多数离散化算法都是单变量的,没有考虑决策表中多依赖关系,因此会有丢失正确分类信息的风险.传统的连续属性离散化方法一般分为4步:
Step1.对连续属性值按照某种规则进行排序.
Step2.初步确定连续属性的切割点划分.
Step3.按照某种给定的标准继续划分切割点 或合并切割点.
Step4.如果Step 3得到判定标准的终止条件,则终止整个连续属性离散化过程,否则继续Step 3执行.
4 基于随机游走模型的情感词极性计算
对于随机游走模型在情感词极性判别上的应用,最重要的是需要构建词的图框架,将数据映射成随机游走图,在图框架中加入词间的相关关系,进而得到对未知词极性的判别.其中,在进行词性判别前,需要对文本进行特征选择,以得到候选特征词.在此基础上,本文提出了基于扩展随机游走模型的情感词极性判别算法,通过同义词词典构建词关联图,加入未知极性词,计算随机游走转移概率,进而预测未知单词极性.
4.1 特征选择
在文本分类中,特征词及其类别倾向于服从CHI分布(Chi-squared Distribution),高CHI值意味着较高的特征分类能力,CHI值计算公式如下[25]:
(7)
其中N代表训练集大小;A代表属于c类并且包含单词t的文本数量;B代表不属于c类并且不包含单词t的文本数量;C代表属于c类但不包含单、词t的文本数量;D代表不属于c类并且不包含单词t的文本数量.
尽管CHI在文本分类中有着较好的表现,但仍有一些缺陷存在.首先,高频词的出现会导致高CHI值,但是它并不一定有较高的区分能力.其次,有些单词在较少的文本中频繁出现,有着很好的区分能力,但CHI值偏低,导致被低估.通过对原始CHI记录日志的处理,能有效降低高CHI值.改进的CHI计算公式如下[26]:
(8)
其中,A+B代表包含单词t的文本数,N代表文本总数.如果t在所有类别中都出现并且频率很高,则其CHI值接近于0,因此可以筛选出来不具备特征属性的高频词.
4.2 词汇情感极性判别
基于随机游走模型的描述以及对游走状态的预测,本文提出基于扩展随机游走模型的情感词极性判别算法.首先构建一个词汇关联图,并在图中定义随机游走.令S+和S-分别表示已经标记为正或负的目标词的两组顶点.
对于任何给定的词w,如前所述迭代地计算两组Tn的h(w|S+)和h(w|S-). 然后将两次Tn之间的比例用作给定字的正/负值的标准.该方法可以很容易地从双向分类(即正或负)扩展到三向分类(正,负或中性).通过设置正和负Tn比例的阈值λ,并且只有当两组Tn有明显差异时才将单词分为正或负,否则将其分类为中性.图的构建采用哈工大社会计算与信息检索研究中心提供的同义词词林(扩展版),分别以Pos(w)、Neg(w)和Neu(w)来表示正、负和中性词,算法如下:
算法 1.基于扩展随机游走模型的情感词极性判别算法(EDEW)
输入:词关联图G(V,E);
输出:词情感极性Sentiment(w).
1 给定原始词节点w,w∈V;
2while(Pos(w)←φorNeg(w)←φ)
3 从w出发,随机k个rw;
4ifrw→Pos(w)then
5E[h(w|S+)]←h*(w|S+);
6endif;
7elseifrw→Neg(w)then
8E[h(w|S-)]←h*(w|S-);
9endelse;
10endwhile;
11 设置扩展参数λ(0<λ<1);
12ifh*(w|S+)≤λh*(w|S-)then
13Sentiment(w)←Pos(w);
14endif;
15elseifh*(w|S-)≤λh*(w|S+)then
16Sentiment(w)←Neg(w);
17endelse;
18else
19Sentiment(w)←Neu(w);
20endelse
在算法1中,结合词关联图,得到最终词汇情感极性.在1中,V表示词关联图中节点,w表示原始词节点;在3中,k表示随机游走次数,rw表示随机游走的散列个数;在45中表示如果其中一个游走散列到达目标节点Pos(w),则游走结束,得到h(w|S+)的目标期望值h*(w|S+).
在二分类情况下,每个词汇极性必须为正或负,如果h*(w|S+)大于h*(w|S-),则该原始词汇极性判定为负,否则判定为正.这可以通过在算法1中设置扩展参数λ=1来实现.
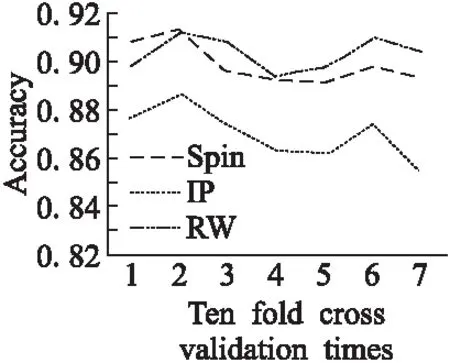
由于计算转移概率P时,需要归一化节点之外边的权重W(0 (9) 其中,Pij表示从节点i到节点j归一化后的游走权重值,Wkmin表示K次游走权重调整中的最小值,Wkmax表示K次游走权重调整中的最大值. 在文本情感分类中,候选属性集决定待分类的文本维度,通过特征选择及情感词极性判定,得到较低维度的文本,使得属性集更具有代表性.候选属性集的获取步骤如下: Step1.对训练文本进行分词. Step2.根据式(8),计算词汇CHI值,筛选词征,得到候选特征集. Step3.通过EWPDA算法,得到候选特征集的情感极性权重,结合词汇特征,进而构成候选属性集. 通过上述3个步骤,得到候选属性集,由于在计算情感极性前,进行了文本的特征选择,所以得到的文本维度有了一定程度的约简,降低了词汇图计算的时间复杂度. 文本决策表[27]也叫作文本判定表,它可以把复杂的逻辑关系和多种条件组合的情况表达的比较明确,由于它逻辑结构的严格性,可用于对文本属性类别进行判定.在文本情感分类中,常常将单个词汇作为分类特征用以构造文本表示向量,而情感词汇对分类的贡献要高于普通词汇.因此,我们用来建立一种带有特征情感词汇极性的文本表示模型. 表1 文本情感决策表Table 1 Decision table for text sentiment 形式化该模型,一个文本Doci被表示为在一组属性(F1,P1),(F2,P2),…,(Fn,Pn)下的取值所构成的向量(wi1,…,wij,…,win),其中属性(Fj,Pj)由特征Fj和其词汇情感极性权重Pj组成,wij表示文本Doci在特征Fj下的权重,在表1中,“D”列表示文本的情感倾向类别,取“正”或者“反”. 为了克服传统离散化方法排序规则的复杂度问题,本文对传统的离散化方法做出了改进,通过随机游走模型中对游走边的权重划分,得到每个词的游走权重,对于每个游走权重,结合候选特征词,从而得候选属性集C.第j个候选属性表示为(Fj,Pj),结合不可分辨关系的定义,进而得到等价类的划分U/IND(B).为解决传统离散化方法中切割点选取过多导致的数据冗余问题,本文提出基于情感词极性权重序的属性离散化算法,算法可以有效减少切割点数量,得到最优的离散化决策表. 对于决策表DT=(U,C∪D,V,F),其属性B⊆C,hi∈B,则IND(h)在论域U中划分的等价类表示为U/{hi}. 算法 2.等价类计算 输入:DT=(U,C∪D,V,F),B⊆C, U={x1,…,xn}; 输出:B对应对象集U的划分U/B. 1 对对象集U进行排序; 2t←1,k←1,B1←{x1}; 3fori←2 tondo ifxi和xk对于B中的每个属性具有相同值; Bt←Bt∪{xi}; endif; else t←t+1; B←{xi}; k←i; endelse; endfor; 4U/B←Bt 算法3.基于情感词极性权重序的属性离散化算法(ADPWS) 输入:决策表DT=(U,C∪D,V,F), U={x1,…,xn},C={h1,…,hm}, B⊆C; 输出:决策表DT*=(U*,C*∪D*,V*,F*). 1T={X1,…,X|T|},Xi⊆U,1≤i≤|T|,h是需要离散化的属性,j←1;t←|T|;count←0; 2whilej 3low←Max({f(x,a):x∈Xj}); 4high←Min({f(x,a):x∈Xj+1}); 6 通过算法2计算Xj/(C-{h}),Xj+1/(C-{h})和(Xj∪Xj+1)/(C-{h}); 8count←count+1; 9Ycoount←Xj∪Xj+1; 10 在T中用Ycount取代Xj和Xj+1,j←j+2; 11ifj=tthen 12count←count+1,Ycount←Xj; 13 在T中用Ycount取代Xj; 14endif; 15else 16 获取属性切割点c=(low+high)/2, 17P←P∪{c}; 18count←count+1,Ycount←Xj; 19 在T中用Ycount取代Xj,把T分为两个子集 20T1={Y1,…,Ycount}和T2={Xj+1,…,Xt}; 21ifcount>1orj+1 22 通过算法2计算U/{hi}={X1,…,Xq},并得到离散化属性hi; 23endif; 24endelse; 25endwhile; 26 返回离散化决策表DT* 在算法3中,结合等价类计算算法,最终得到离散化决策表DT*.在1中,T={X1,…,X|T|}为属性h当前区间集合;在3和4中,通过相邻区间的最大值和最小值,进而得到切割点的划分c=(low+high)/2;通过5可以计算6中的正域,即基于(C-{h})的分类划分.在7中判断基于(C-{h})划分下Xj,Xj+1的正域之和是否与Xj∪Xj+1相等. 在算法3中,若用m,n分别表示C和U的基数,在最坏情况下,1的算法时间复杂度为O(m×nlog2n),则整个算法的时间复杂度为O(m2×nlog2n). 粗糙集理论包含了对信息系统的约简,通过去除冗余信息,完成对规则的提取,实现在没有任何先验知识基础上的系统分类.在连续属性离散化的过程中,也包含了对决策表的约简,通过选择切割点并且合并相邻间隔区间,得到决策表中条件属性的约简.通过离散化后的决策表可以获得知识系统中的隐含数据,即决策规则,以此增加对新对象匹配的可能性.一般地,在文本数据处理过程中,不可避免的会出现“维数灾难”问题,在文本向量空间中,维数灾难问题就转化为了高维特征空间的线性划分问题,其维数的增加就会导致数据稀疏,从而引出属性值匹配困难,这也是本节需要解决的问题. 本节提出了基于粗糙决策置信度的文本情感类别判定算法,通过分类文本中的条件属性及其游走权重值,找出文本在训练集中的等价类,并计算其决策类的置信度,然后计算在属性特征及相对应文本位置下的权重,构造在决策类下的隶属度函数,得到最终的文本情感类别判定.通过计算在待分类文本中每个属性的隶属度,从而避免了多属性值的匹配困难问题和其所引发的数据稀疏问题. 定义7.(粗糙决策隶属度)给予决策表DT=(U,C,D),其中B⊆C,j∈B,x∈U,其中属性均为符号值属性,j*为属性j下的一个条件属性,Cd为一个决策类,Cd={x∈U|C(x)=d},则 (10) (11) 其中,称μcd为文本在决策类d下的粗糙决策置信度.情感极性权重Pj已经归一化,wij≠0,μcd(U)越接近于1,则表明其隶属于决策类Cd的可信程度越高. 算法4.基于粗糙决策置信度的文本类别判定算法(TCRDC) 输入:决策表DT*=(U*,C*,D*),待分类文本 U*=(U1,U2…,Un); 输出:文本类别集合CPOS,CNEG. 1CPOS,CNEG←Ø,i=1; 2foreachU∈U*do 3ifi≠nthen 4 通过公式(14)计算μcd(Ui)的值; 5i=i+1; 6C(U)=μcPOS(Ui); 7CPOS=CPOS∪argmax{μcPOS(Ui)}; 8endif; 9elseifC(U)=μcNEG(Ui); 10CNEG=CNEG∪argmax{μcNEG(Ui)}; 12endfor 在待分类文本U中,CPOS和CNEG分别表示正反两种情感类别,由μcd(U)得到的正反两类文本分别为: (12) 其中: CPOS={x∈U|C(x)=POS} (13) 通过计算文档的置信度,从而得到其隶属于正反两类文本的最大值,就是对于正反两类文本的最大置信度的分类. 实验数据采用第6届中文倾向性分析评测语料及第3届自然语言处理与中文计算会议评测语料,记作COAE2014及NLPCC2014,在COAE2014中提取其中对食品饮料的评论文本400篇,其中正面文本200篇,负面文本200篇;在NLPCC2014中提取其中对音乐及电影的评论400篇,其中正面文本200篇,负面文本200篇,总计共800篇文本语料.由于评论中人群主要涉及对于食品饮料使用及电影观看后的评价,都是作为普通消费者人群,因此具有一定的代表性.使用其中600篇语料作为训练数据集,剩余200篇作为测试数据集.通过分词工具对所有文本进行分词及词性标注,并采用人工方式对文本情感类别进行标注,情感文本数据集如表2所示. 表2 情感文本数据集Table 2 Emotional text dataset 通过第3.1节介绍的方法后获取候选文本属性集,由于选取较少特征词会损失一定的实验精度,选取过多特征词虽不会对结果造成直接影响,但会造成数据冗余,提高算法的时间复杂度.王素格等[28]提出一种面向非平衡文本情感分类的TSF特征选择方法,通过在COAE2014选取的图书评论数据集,显式组合正相关和负相关特征,去考量特征的平衡性用以表达文本信息.本文综合文本数量及文本平衡性,为使特征词的选择能更好代表实验结果,因此在600篇训练数据集里,选取候选特征词700个,里面包括了积极词汇特征数350个,消极词汇特征数350个,部分词汇特征如表3所示. 表3 情感词汇示例Table 3 Examples of emotional words 自旋模型(Spin)、标签传播方法(Label Propagation Algorithm,LP)都是针对情感词的词汇极性判别方法,Spin模型通过计算文本的近似概率函数去优化被选参数,只需少量种子词就可高精度定义语义倾向,但该方法需要手动标注种子词,在数据规模较大的情况下时间复杂度过高;LP方法是一种基于图的半监督学习方法,其基本思路是用已标记节点的文本标签去预测未标记节点的文本标签,但该方法缺少对文本标签信息的验证;而本文提出的RW方法可以通过随机游走选取种子词,并且对种子词进行十折交叉验证,来验证其准确率.本文把训练数据集分为10份,每份含有特征词汇80个,通过7次十折交叉验证比较RW与Spin模型,LP方法的准确率,如图2所示. 图2 十折交叉验证准确率对比Fig.2 Accuracy rate of ten fold cross-validation 由图2可以得出,不考虑参数影响,随机游走算法通过十折交叉验证准确率要优于Spin模型和LP方法.在7次十折交叉验证中,由于分组数据的不同,其准确率也会随之波动,但每种算法波动趋势趋于一致,RW算法与其余两组数据对比中,在数据的耐受性方面表现较好. 在实验中,称原始词汇节点为种子词,本文设计了针对不同方法的5组10种子词实验,通过求取不同种子词的加权平均值,将RW算法与Spin模型、LP方法、SO-PMI方法的情感词汇极性判别的准确率进行对比.其中,SO-PMI方法是将PMI引入计算词语的情感倾向中,从而达到捕获情感词的目的,在本文中SO-PMI的计算公式为: (14) 其中,w是具有未知极性的单词,hitsw,pos是在搜索查询给定单词时返回的命中次数和提取的所有正种子词.hitspos是搜索所有正种子词时的命中数,类似地定义了hitsw,neg和hitsneg.对比实验结果如图3所示. 图3 不同方法中10种子词结果对比 Fig.3 Comparison of ten seeds vocabulary in different methods 在选取种子词进行验证的过程中,考虑到随着SO-PMI方法中数据量的增加,其准确率会有所上升,在选取SO-PMI方法中的数据时的数据量为1×107,属于比较平均的数据量,而更高的数据量对结果对比影响较小.LP方法效果较差,随机游走方法稍优于Spin方法.总体来看,在对比这几种经典构图算法中,随机游走算法为结果较优的算法. 虽然随机游走在上述结果表现较好,但是未考虑参数对算法准确率的影响,由于随机游走模型中样本K值和最大游走Step对最终情感极性判别的准确率影响较大,并且最后特征的权重与步数有很大的相关关系,所以下面要讨论K值及最大游走Step对随机游走的准确率的影响,如图4所示.由于不同类别特征在训练时对λ的敏感度不同,实验通过不断调整扩展参数λ,在0.1-1.0之间进行测试,在训练数据集中,选取λ=0.8能得到较为清晰的结果. 图4 参数对准确率的影响Fig.4 Influence of the parameters on the accuracy 从实验结果可以看出,不断增加的Step与准确率有一种先增后减的趋势,而不断增加的K值与准确率成正比.在试验中设置初始Step为5,这是因为如果Step小于5,则准确率波动太大,使得结果缺少可信度.由于Step越少,则从种子词节点搜寻到正确情感词汇极性的概率越大,所以Step的增加,会导致寻找到正确情感词极性的概率变小,而当Step取15左右时,能得到较好的结果;而对于K值来说,由于最大散列数的增加,越大的K值使得能搜寻到正确结果的概率越大,实验结果也更加说明了Step及K值对准确率的影响. 通过计算情感词极性倾向强度值,结合公式(9)计算随机游走权重百分比,对每个特征在文本中的权重予以赋值[29],赋权之后的文本决策表如表4所示. 表4 情感词极性处理数据表示Table 4 Expression of emotion word processing data 表4中共有训练文本600篇,包含特征选择及权重处理后得到的700个特征,包括“好产品、努力、问题、呵护、关怀、激进、圆滑、讽刺、强化、……”得到的特征文本矩阵为600×700,每个特征词的情感极性权重均为归一化后的结果,每个特征词在文本所占比重也为归一化后的结果.其值越接近1,则特征在文本中所占的比重越大. 表5 离散化后的决策表Table 5 Decision table after discretization 如表5所示,当特征在文本下权重值为0,使得离散化后的特征权重仍然为0.可以看出,算法3能够保证文本决策表离散化后的分类能力仍能保持不变. 为了对比本方法的效果,将通过三个指标进行比对,一是切割点的数量(CU);二是离散化时间(TI);三是属性压缩比率(RI),与本方法对比的三种经典方法是NB、ME、EF.具体结果如表6所示. 表6 离散化数据指标对比Table 6 Data index comparison after discretization 为了在试验中排除由于硬件问题导致的数据不稳定,统一机器参数信息(OS:Windows 7;CPU:Inter(R) Pentium(R) CPU of 2.10 GHz;Memory:4GB)并对每个算法的计算时间都进行了5次验证,最终结果取平均值.可以看出,ADPWS算法在切割点数量和数据属性的压缩比率上都优于其他方法,但在时间花费上没有EF算法效果好.由此可以得出,ADPWS方法在切割点选取和属性压缩方面效果较好,但在运行时间上还有进一步的改进空间. 使用ADPWS算法对决策表DT进行离散化后,得到离散化决策表DT*,离散化后的属性为文本最终属性,下一步通过粗糙决策置信度对测试集文本进行表示,同时使用多种评价指标对分类结果进行对比,查准率(P)、查全率(R)、F1值.同时,使用多种分类算法与粗糙决策置信度方法进行对比,SVM、K近邻(k-Nearest Neighbor,KNN)、NB、文献[30]的粗糙隶属度分类方法(P-B).其中,F1值是 (15) 公式中α取1时的结果,F1值是取P值和R值的加权调和平均,F1值越大,则说明实验的方法越有效.实验还通过分析正类文本和负类文本的P值、R值、F1值,来得到更全面的测试评价指标,实验结果如图5所示. 图5 不同分类方法结果对比Fig.5 Comparison of the classification results of different methods 由图5可以看出,在多评价指标下,本文所提出的方法均取得了较好的效果,在负类查准率、正类F1值指标下均优于其它几种方法,几种评价指标下相比较于P-B方法、KNN方法的正确率有所提升,正确率提升约1.85%,表明数据离散化后的属性分类能力与原属性相比并没有丢失. 文本情感分类问题,一直是研究的热点,如何提高分类效率,减少分类过程中的数据维度,同时又不损失精度,这是本文所需要解决的主要问题.随机游走模型多用于排序问题,本文推广了随机游走模型,将文本空间转化为词汇图,提出了基于扩展随机游走模型的情感词极性判别算法,有效判别情感词极性,最终得到候选属性集;通过对候选属性集的处理,结合特征权重,构建情感词汇决策表,提出基于情感词极性权重序的属性离散化算法,得到离散化决策表;为把离散化后的属性特征进行表示,提出粗糙决策置信度模型,对文本进行最终决策分类.实验对算法进行了分析,均取得了较优的效果,但有些步骤仍有改进的空间,比如离散化算法中的时间复杂度问题,通过进一步的优化应能得到理想的效果.由于每个步骤都有可能对实验的最终分类结果造成精度的损失,如何提取整合方法中的优点以提高整体精度,这也是今后工作的一个要点.4.3 获取候选属性及建立文本情感决策表

5 基于粗糙集的连续属性离散化
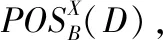

6 基于粗糙决策置信度的文本情感类别判定



11 end else;
CNEG={x∈U|C(x)=NEG}7 实验结果与分析
7.1 实验数据

7.2 文本情感词极性判别



7.3 文本情感决策表离散化




7.4 文本情感类别判定

8 总 结
