MGSC:一种多粒度语义交叉的短文本语义匹配模型
2019-06-06吴少洪彭敦陆苑威威
吴少洪,彭敦陆,苑威威,陈 章,刘 丛
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
语义理解在自然语言处理任务中具有十分重要的地位,早期的研究表明,无论在语法结构上做何种深入研究,都难以达到理想的效果.后来发现,一个完整的自然语言处理任务绕不开语义理解这个环节[1].随着人工智能和深度学习的发展,智能化文本应用正在深入人们生活的方方面面,而语义匹配问题广泛存在于这些应用之中.例如,智能检索和智能问答,这两种应用中最基本的问题就是如何进行文本的正确匹配,那么如何更好地理解用户的语义(意图)就显得格外重要.在智能检索中,用户给出目标检索文本,然后系统通过智能算法在大量数据中查找、排序并将最合理的结果返回给用户,其中就涉及用户检索文本匹配的问题;在智能问答系统中,需要在答案列表中匹配到和用户意图相近的答案.
如表1所示,一个问题及其所对应的若干回答.我们需要在答案列表中找出和问题最匹配的答案.
传统的匹配方法没有考虑语义信息,一般从词、句式、语法结构出发,依赖于人工设定的特征和规则,这种硬性的匹配不仅很难达到满意的效果,还需要花费大量人力物力.而采用机器学习方法,特别是基于深度神经网络的学习方法,能够实现文本特性的自动提取,因而避免了硬性匹配的缺陷[2].一个成功的匹配算法需要对语言对象的内部结构以及它们之间的相关语义进行充分建模.基于这一目标,本文提出了一种用于匹配两个短文本语义的深度神经网络模型——多粒度语义交叉模型,来解决诸如信息检索中信息匹配或者问答系统中问答匹配的问题.实验发现,多粒度语义交叉模型不仅能够捕获不同层次上丰富的匹配模式,而且能够获取不同粒度语义的交互特征,在相关任务上具有突出的表现.

表1 问答匹配的例子Table 1 Example of QA matching
2 相关工作
文本匹配是自然语言处理中一个基础性问题,而语义匹配是文本匹配研究的重要方向,从根本上解决文本匹配问题.在许多任务中都有应用场景.比如,在信息检索中,要求在文本库中找到与用户检索目标相匹配的信息;在问答系统或问答机器人应用中,需要实现问题和答案的智能匹配;在机器翻译中,需要进行两种语言表达的匹配.
目前,关于文本匹配问题的解决方案已经从传统的基于统计的方法转移到基于深度神经网络的方法上.例如,传统的匹配方法中,两个文本中出现相同词的个数越多,词序列的排序越接近,则相似度越高.但是,这样的方法越来越难以满足日益提升的用户使用体验.而基于深度神经网络的方法,是将文本映射到一个语义空间,数字化地来表示文本.一般的做法是采用词向量表示文本中的词,即分布式表示[3].文本分词后,将得到的词语分别进行向量表示,并组合成矩阵来表示文本.然而,简单的词向量组合难以联系文本的上下文信息,丢失了文本的许多语义信息,同时也忽略了词语之间的内在联系.于是,一些模型引入循环神经网络的方法捕获文本上下文信息,如2015年ShengxianWan等人提出的MV-LSTM模型[4].
总体来看,目前关于深度文本匹配模型主要有三种类型.第一种是基于单文本的,即用一个向量表示文本,再对文本向量做相似度计算,比如2015年Baotian Hu,Hang Li等人提出的ACR-I模型[5]、DSSM模型[10].第二种是在单文本上做多语义表示,通过不同粒度的语义计算文本相似度,如MultiGranCNN模型[6]和MV-LSTM模型[4].第三种则认为更早地让两文本交互,再提取深层次的交互信息更有利于解决文本匹配问题,比如Baotian Hu,Hang Li等人提出的ACR-II模型[5]、Pang L 等人提出的MatchPyramid模型[14]等.
多语义方法和直接建模方法在许多实验中被证明比基于单文本的方法效果好,但两者在不同的匹配任务中表现得各有优势.本文提出多粒度语义交叉模型,对两文本进行建模匹配.该模型结合了多语义和直接建模两种思想:首先通过两个方向的循环神经网络分别获取文本的上下文信息,得到不同粒度的语义表示,再由这些不同粒度的语义信息两两进行语义信息交互,进一步获得含有语义交互信息的交互矩阵,对交互矩阵进行一系列的卷积和池化操作后,再由一个多层感知机输出两个文本的匹配度.实验表明,本文的模型具有出色的竞争力.
3 多粒度语义交叉模型
3.1 问题定义与分析
对于给定的样本数据sample={score,s1,s2},其中s1,s2表示给出的两个短文本(例如问答系统中的一问一答),score表示相应两个文本s1、s2的匹配度(例如问答系统中问答的相关程度),目标是训练一个匹配模型,能够合理地评估任意两个短文本间的匹配程度,使得M(s1、s2)⟹score.例如,给出问答对:
s1:长颈鹿吃什么?
s2:它吃树叶和嫩枝.
通过模型,判断s1、s2是否匹配,匹配度有多少.
考虑文本上下文的信息关联,可通过两个方向的长短期记忆模型LSTM(Long Short-Term Memory)[7]来获取文本上下文信息,将文本的词向量嵌入矩阵定义为该文本的原语义,那么将原语义通过正向的LSTM得到正向的语义表示,称为正语义,将原语义通过反向的LSTM得到反向的语义表示,称为反语义.如图1所示,每个语义矩阵由三个向量组成,向量代表的语义的粒度是不一样的,例如在正语义中“长颈鹿/吃”就包含了“长颈鹿”和“吃”两个部分的语义信息,而有的向量只表示一个词语的语义信息,如原语义中的三个向量.

图1 “长颈鹿吃什么”三种语义的矩阵表示Fig.1 Three kinds of semantic matrix representation of “What Giraffe Eats”
考虑两个短文本语义之间的交互信息.很明显,两个文本语义之间的交互信息越多,则两个文本语义的匹配度也越高,一个简单有效的做法是直接对两个文本语义矩阵做余弦相似度计算.
考虑不同粒度语义之间的交互.前人对于文本匹配的研究一般只考虑两个待匹配文本原语义之间的交互信息,或者只考虑多种语义(比如,原语义、正语义和反语义)串联之后的交互信息,例如MV-LSTM模型[4].本文试图考虑不同粒度的语义之间的交互信息来帮助计算匹配度.
如图2所示是s1的正语义和s2的正语义的交互图,其中两个文本中重要的匹配信息用粗线表示,类似“长颈鹿—它”和“长颈鹿/吃/什么—它/吃/树叶/和/嫩枝”这两种匹配关系的匹配粒度是不一样的.所以考虑不同粒度语义之间的交互,以获得更多文本间的匹配信息.
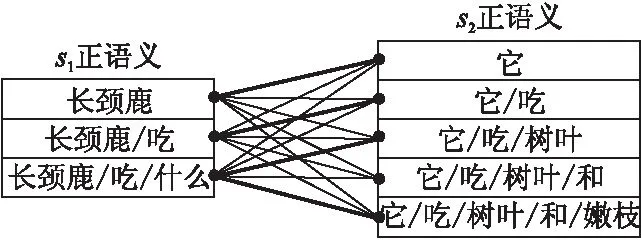
图2 不同粒度语义交互Fig.2 Semantic interactions with different granularities
考虑所有交互信息特征的融合和提取.本文尝试采用张量和卷积神经网络的方法来融合和提取交互信息中重要的特征表示.最后根据所提取到的特征,通过多层感知机计算两个短文本的匹配度.
3.2 模型
基于以上分析研究,本文提出了多粒度语义交叉模型来解决文本匹配的问题,模型如图一所示.模型主要包括四个部分:
a)多粒度语义,包括原语义、正语义和反语义的准备;
b)语义交叉,包括语义交叉和交互张量的计算过程;
c)卷积和池化,包括若干个卷积层和池化层的计算;
d)多层感知机,用于计算匹配度.
3.2.1 多粒度语义
模型的输入是预先训练好的词向量.目前已有一些现存的词向量训练工具,如Word2vec[3]或者Glove[8]等基于大量文本无监督生成的词向量.已有研究表明,利用这些工具所得的词向量具有普适性(或通用性),在很大程度上能够给模型带入更多知识.对于短文本,其词向量嵌入表示为:
S=[x1,x2,…,xi,…,xn]T
(1)
其中,xi表示文本中第i个词的词向量,词向量的维度为d,文本中词的个数为n,文本的原语义Sr=S,Sr,即为文本的原语义.
在此,模型利用正向LSTM和反向LSTM来获短得文本上下文不同粒度的语义信息,即正语义和反语义.
在LSTM中包含有三个门控单元:遗忘门、输入门以及输出门,分别用ft、it和ht分别来表示.它们的计算过程如下:
ft=σ(Wf·[ht-1,xt]+bf)
(2)
it=σ(Wi·[ht-1,xt]+bi)
(3)
(4)
Ct=ft*Ct-1+it*Ct
(5)
Ot=σ(WO·[ht-1,xt]+bo)
(6)
ht=Ot*tanh(Ct)
(7)
其中,·表示点乘,*表示点对点的乘法,xt是输入层的值;Wf,Wi,WC,Wo是权重矩阵.σ是sigmoid激活函数,tanh是双曲正切激活函数.ht表示t时刻LSTM单元的输出.
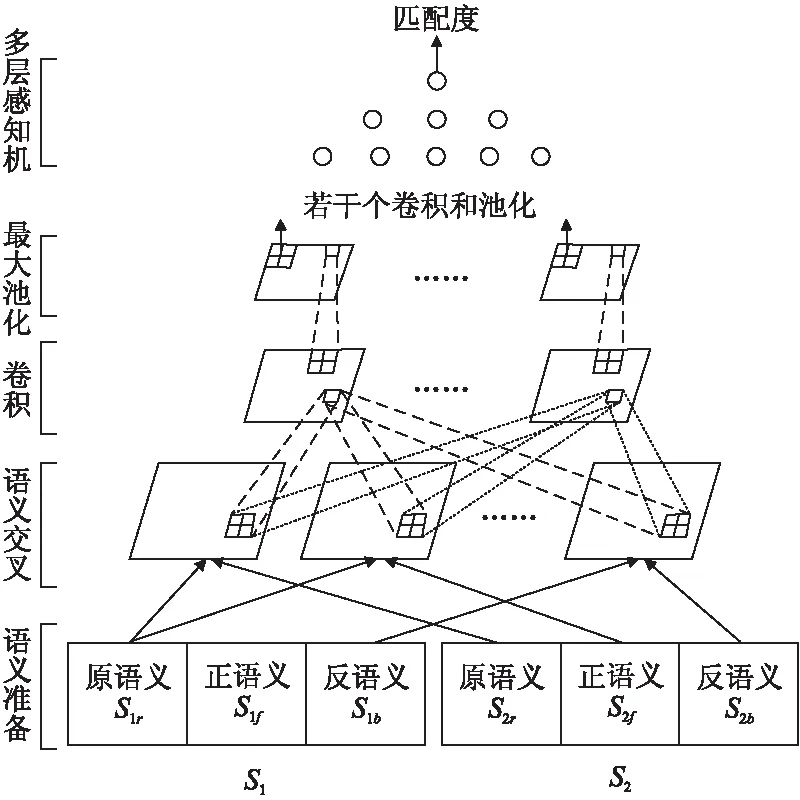
图3 多粒度语义交叉模型Fig.3 Multi-granularity semantic cross model
以文本的原语义作为输入,通过正向的LSTM,模型可以得到文本的正语义表示Sf:
Sf=[hf1,hf2,…,hft,…,hfn]T
(8)
类似地,以文本的原语义作为输入,通过反向的LSTM,得到反语义表示Sb:
Sb=[hb1,hb2,…,hbt,…,hbn]T
(9)
这里,hft表示t时刻正向LSTM的输出,hbt表示t时刻反向LSTM的输出,令
len(hft)=len(hbt)=len(xt)=d
(10)
即hft、hbt的维度和词向量的维度一致,都为长度d.
3.2.2 语义交叉
语义交叉层的主要工作是将两个文本的信息进行融合形成交互特征张量.模型将两个待匹配的文本的三种语义信息(原语义、正语义、反语义)进行两两交互,重组之后,得到交互张量Sc:
SC=[c1,c2,…,cp]
(11)
其中,c为文本语义的交互矩阵,p表示交互矩阵的数量.在图3中,p=9,即语义交叉层包含9张交互特征图.例如c2表示图3中S1的原语义和S2正语义的交互矩阵,其计算方式为:
(12)
其中,S1r表示第一个文本的原语义,S2f表示第二个文本的正语义.我们把语义之间的这种交互称为语义交叉.
3.2.3 卷积池化
卷积层的工作主要是利用卷积核过滤提取特征,每个卷积核相当于一个“过滤器”,可以过滤掉相关程度较低的匹配信息,使得相关程度高匹配特征突显出来.卷积层对融合层得到的张量表示Sc进行卷积计算,即以Sc作为卷积层的输入.对于卷积层的每个输出z,有
(13)
其中,卷积核W={w1,w2,…,wk},k为卷积核权重数量,b为偏置;xij表示Sc中的元素,f为ReLu激活函数.
最大池化层,其作用是对卷积层卷积出来的特征值进行筛选,保留每个池化区域最大的特征值,忽略池化区域较小的特征值.保留较大的特征值往往能够体现交互矩阵中较重要的交互信息.池化层,其输入为卷积层的输出,对于池化区域为2×2的池化层,其输出Rt可表示为:
Rt=maxt({z2i-1,2j-1,z2i-1,2j,z2i,2j-1,z2i,2j})
(14)
其中,Rt表示池化层第t个池化区域的输出,z表示卷积层的输出.
3.2.4 多层感知机
模型的最后使用多层感知机来计算匹配度,对卷积层和池化层筛选保留的重要交互特征进行计算.其输出为两个短文本的匹配度.其计算公式为:
U=fu(WuR+b),score=fscore(WscoreU+b)
(15)
其中,Wu和Wscore为权重矩阵,R为池化层的输出,b为偏置项,fu为ReLu激活函数,fscore为sigmoid激活函数.当目标只需要判断匹配与不匹配时,匹配问题可以视为匹配与不匹配的二分类问题.对于分类问题,激活函数fscore设为softmax激活函数,预测每个类别的概率值P,P的计算表达式为:
(16)
其中,Pj表示预测第j类的概率,xj表示第j类的数值,共有(m+1)个类别.
4 实验与分析
我们在两个公开的数据集上进行了实验,涉及两个任务,分别是问题去重和问答匹配.实验通过模型在两个任务上的表现以及和其他模型的比较来验证模型的有效性,在两个不同类型的任务上的表现不仅可以证明模型的竞争性,也可以在一定程度上验证模型在语义匹配任务上的通用性.
4.1 实验设置
实验环境为Linux系统,采用基于TensorFlow的Keras深度学习框架搭建模型.实验使用斯坦福大学公开的Glove1https://nlp.stanford.edu/projects/glove
词向量1,并将每个词向量做归一化的预处理.文本长度取固定长度,超过长度截断,不足补零.对于未登录词,采用在(-0.2,0.2)的均匀分布随机生成的向量表示.模型中的参数,包括LSTM、CNN以及多层感知机的参数,都使用反向传播训练学习.
实现MGSC模型的基本设置:
实验1.问句长度取10,答案长度取40,选用Adadelta作为优化器,学习率0.1,向量维度50维.
实验2.两个句子长度均取20,选用Adam作为优化器,学习率0.001,向量维度300维.
4.2 实验1:问答匹配
问答系统实验采用WIKIQA[9]数据集,该数据集包含3047个问题和29258个句子,其中有1473个句子是标记为相应问题的答案.每个问题对应若干句子,当句子被标签为0表示不是该问题答案,被标签为1时,则相反.
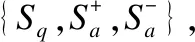
(17)
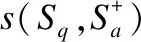
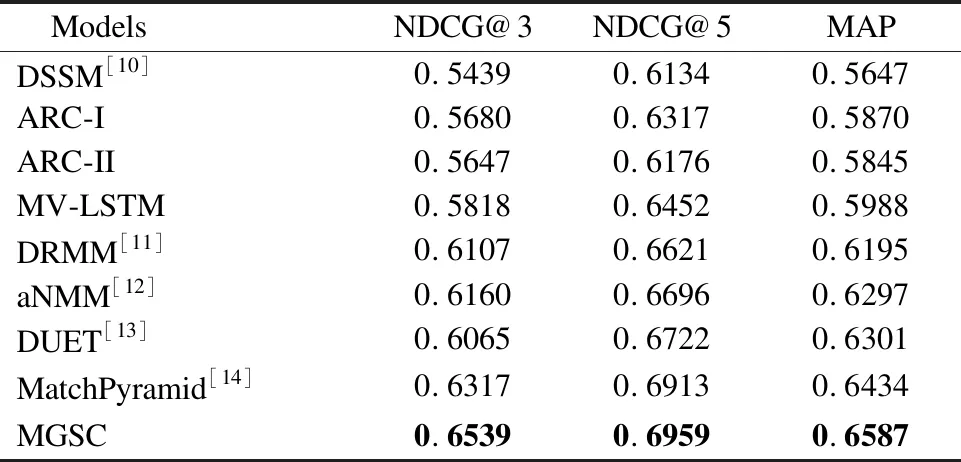
表2 WIKIQA数据集上的实验结果Table 2 Experimental results on the WIKIQA dataset
表2是各种模型在WIKIQA数据集上的表现结果.从实验结果可见,MGSC模型与其它模型相比,具有较好的计算效果.在MAP、NDCG@3以及NDCG@5上,MGSC模型都显示了最好的结果.不同于句子复述或者相似问题去重的任务,待匹配文本可能在用词上就明显存在相似性,而问答的匹配,问题和答案一般在用词上的区别更大,甚至问题和答案没有出现一样的词语.MGSC模型能够在问答数据上有优异的表现,体现出模型在语义上的匹配能力.
针对MGSC模型的四种变形,我们在WIKIQA数据集上进行了实验.这四种变形是通过在同等实验条件下,改变语义交叉特征图的数量和种类而得到的.在图4中,MGSC@1模型只用到两个句子原语义的交叉,包括一张交叉特征图;MGSC@3模型用到两个句子的原语义与原语义、正语义和正语义、反语义和反语义交互形成的三张交叉特征图;MGSC@4模型是两个句子的原语义和正语义两两交互,形成四张语义交叉特征图,不加入反语义;MGSC@9模型,即我们提出的MGSC模型,采用两个句子的原语义、正语义、反语义之间两两交互形成的九张语义交叉特征图.该图表明,语义交叉是一种行之有效的语义匹配方法.比较MGSC@1模型和MGSC@4模型,可以看到模型中加入正向语义带来明显的效果提升;比较MGSC@1和MGSC@3两个模型,同样能说明加入正向语义和反向语义的优势;比较MGSC@1模型和MGSC@4、MGSC@9三个模型,实验结果表明,不同粒度的语义交叉能够带来效果的有效提升.

图4 关于MGSC模型的几种模式的比较Fig.4 Comparison of several variations of the MGSC model
4.3 实验2:问句去重
在一些问答平台上,用户往往会提出意图相似的问题,将这些意图类似的问题去重,能够带来更好地用户体验,是非常有意义的一件事,特别是像国内知乎、国外Quora这样大型的知识分享平台.比如Quora,每个月有超过一亿的访问量,所以毫无疑问的用户会提出相似的问题.许多问题具有相同的意图,用户需要花许多时间在这些相似的问题中寻找最想要的答案,回答问题的用户也不喜欢被同样的问题提问多次.于是Quora在Kaggle发起了相似问题去重的挑战.
Quora发布的训练数据集有404289个样本,一共包含537933个问题,每个样本包括样本编号、两个问题的编号,两个问题的文本以及标签,标签为1表示两个问题表达同样的意图,标签为0则不同.
实验将404289个样本随机划分为8:1:1的比例分别作为训练集、验证集和测试集.实验将该问题定义为“意图相同”和“意图不同”的二分类问题,以二分类交叉熵作为目标函数,计算公式定义为:
(18)
其中,θ表示模型中的参数,m训练包括组已知样本,(xi,yi)表示i第组数据,xi及其对应的类别标记yi,yi取0或1,hθ(xi)表示模型的输出.
实验从损失和正确率两个指标来评价测试模型,评测比较的模型包括本文提出的MGSC模型、ARC-I、MV-LSTM以及MatchPyramid[14]和MatchSRNN[15]模型.
如图5、图6所示,MGSC模型表现出色,相比其他模型,在损失Loss和正确率Accuracy两个评价指标上都取得了竞争性的效果.在实验中发现,对于短文本任务,去除停用词会严重破坏短文本的语义信息,对最后的评价指标有大约2%~3%的影响.去除停用词之后,MGSC模型的正确率大概有82%,MatchPyramid模型的大约有82.5%,而不去除停用词,MGSC模型和MatchPyramid模型都差不多能达到85%左右的正确率.
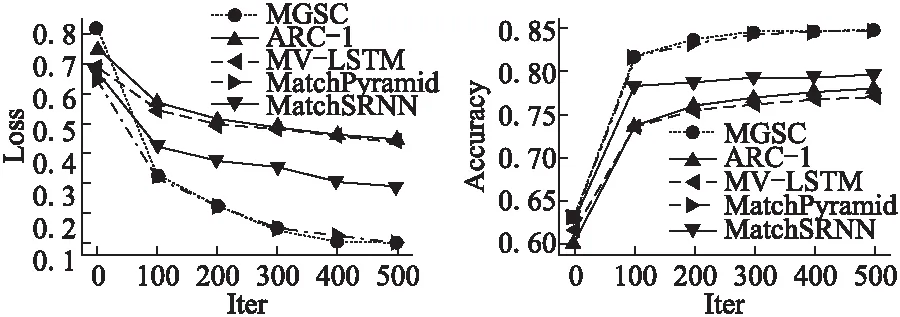

图5 几个模型在Quora数据集上的损失比较Fig.5 Compare the loss of several models on Quora dataset图6 几个模型在Quora数据集上的正确率比较Fig.6 Comparison of the accuracy of several models on Quora dataset
4.4 讨论与分析
可解释性一直是深度学习为人诟病的地方,许多深度神经网络模型虽然在各个方面取得了突破性的效果,但是并没有给出严格的解释.
已有的深度学习神经网络模型,在应用循环神经网络模型的时候,往往只提取循环神经网络的最后时刻的输出.即使是使用了循环神经网络每一时刻的输出,也是将生成的语义向量矩阵和词嵌入矩阵做串联,形成新的向量矩阵表示(每个词向量变长),比如MV-LSTM模型.本文提出的多粒度语义交叉模型则抛弃以往的做法,将LSTM生成的语义向量矩阵和文本本身的词嵌入矩阵分别利用,这样可以最大程度地保留文本各个粒度的语义信息.
我们试图这样来解释语义交叉.LSTM在时刻的输出其实是包含了从零时刻到时刻的所有信息,以文本序列处理的状况来说就是包含了前个输入的单词的信息.所以简单地将LSTM在时刻的输出和单词原本的词向量串联后作为新的的做法显然并不是很合理.本文将文本原语义、正语义和反语义独立表示,作为文本不同粒度的语义表达.再通过将两个待匹配文本相同或不同粒度的语义进行交互,获取两个文本的语义交叉特征图.而不同语义之间的交互给出了两个语句之间不同粒度的重点关注的交互信息.在特征图中,对于比较重要的信息用较大的数值来表示,而对特征图做卷积操作本质上是为每张特征图分配权重的过程,以此来综合考虑所有特征图的匹配特征,从而判断两个文本是否匹配.
5 结 论
本文提出了多粒度语义交叉模型——MGSC模型,以此来解决类似文本复述、问题去重、问答匹配或者信息检索排序的问题.模型主要有两个创新点,一是对同一短文本采用不同粒度的语义表达,二是通过两个文本不同粒度的语义表示交互获取两个短文本的交互特征.通过分析验证,文本匹配模型引入多粒度的语义信息以及不同粒度的语义交叉信息能够提高文本匹配任务的匹配准确率.在Quora Duplicate Questions和WIKIQA两个数据集上实验结果表明MGSC模型相比已有模型具有一定的优势,且在语义匹配任务中具有一定的通用性.
