基于多源域深度迁移学习的液晶面板缺陷检测算法*
2019-04-24[]
[]
1 概述
液晶面板的缺陷检测是保证液晶面板质量的重要的一环。液晶面板种类多样,其缺陷种类繁多,如何高效的进行液晶面板的缺陷检测已经成为了热门的研究课题。
目前在液晶面板缺陷检测方面主要有两种思路:(1)以机器视觉与机器学习为代表的手动提取特征的方法;(2)利用深度神经网络自动提取特征的深度卷积神经网络的方式。两种方法在液晶面板缺陷的检测问题中均遇到了瓶颈,一是液晶面板缺陷的不规则性、随机性及其与背景差异性低等特性导致手工提取特征的方法作用甚微,检测效果达不到工业生产的要求[1];二是由于各类缺陷数据集的采集、标记和制作需要耗费大量的人力物力,导致数据集从质量和数量上均出现数据贫瘠现象,从而使得基于深度卷积神经网络的缺陷检测系统出现训练数据匮乏、模型泛化能力不足和模型稳定性差等问题。因此必须解决在缺陷检测问题中所面临的数据贫瘠问题。在缺陷检测领域中,现有的高质量数据集匮乏并且分散在并没有打通的各个项目当中,大多数缺陷检测任务所能利用的数据比较单一,标签标记的水平也参差不齐。
另一方面,在公开的优质数据集中,如在ImageNet的残差网络[2]在识别物体时已经超越人类的性能,Google的Smart Reply[3]系统在谷歌海量优质数据的训练下可以自动处理所有移动手机的10%的回复,其神经网络翻译模型系统已经被用在了超过10种以上的语言之中。这些成功的模型都是在精心多年收集的数据集上进行训练的。然而当我们把这些机器学习的模型应用在自然环境中时,模型会面临泛化性能下降、模型稳定性差等问题。在此情况下,尽管最先进的模型在它们被训练的任务和域上展示出了和人类一样甚至超越人类的性能,然而还是遭遇了明显的表现下降甚至完全失效的问题。
因此,有必要从迁移学习的角度出发,对不具有海量数据集的缺陷目标检测领域展开研究。近年来已有较多关于迁移学习的研究进展,清华大学的Tan.C等人[4]跟据迁移学习的方式的差别将目前的迁移学习分为四大类:基于实例的深度迁移学习[5-6]、基于映射的深度迁移学习[7-8]、基于网络的深度迁移学习[9-11]和基于对抗的深度迁移学习[12-13]。其中基于实例的迁移学习是指使用特定的权重调整策略,通过为那些选中的实例分配适当的权重,从源域种选择部分实例作为目标训练集的补充。基于映射的深度迁移学习是指将源域和目标域种的实例映射到新的数据空间,在这个新的数据空间中,来自两个域的实例都是相似且适用于联合深度神经网络。基于网络的深度迁移学习是指服用在源域中预先训练好的部分网络,包括其网络结构和连结参数,将其迁移到目标中使用的深度神经网络的一部分。基于对抗的深度迁移学习是利用生成对抗网络[14]技术,找到适用于源域和目标域的可迁移表征。
在单源域迁移学习方面,目前已有较多相关研究[15-16],但是如果源域和目标域的相关度比较小,仅仅只是简单粗暴的进行直接迁移将导致负迁移问题,这不仅不能促进对缺陷目标检测的性能,而且还会降低整体的检测精度。同时,仅仅利用一个源域的数据也是对数据集资源的浪费,因此有必要采取多源域深度迁移学习的方式,从多种不同相似任务的数据集上挖掘更多有用的特征信息,使得网络具有更好的泛化性能和鲁棒性。
本文的研究是在基于网络的深度迁移学习基础上进行的,以Mask R-CNN网络[17]为基础框架,通过混淆域学习的迁移学习方式在多源域数据集上实现了对液晶面板缺陷目标的精准检测。
2 多源域深度迁移学习定义
2.1 迁移学习问题的定义
定义1:(域)数据(domain)由两个部分组成,特征空间X和边缘概率分布P(X),其中。
定义2:(任务)给定一个域D={X,P(X)},一个任务T由一个标签空间Y以及一个条件概率分布P(Y|X)构成,该条件概率分布是从由特征—标签对组成的训练数据中学习得到。
如图1所示,为深度迁移学习概念示意图。
2.2 多源域深度迁移学习定义
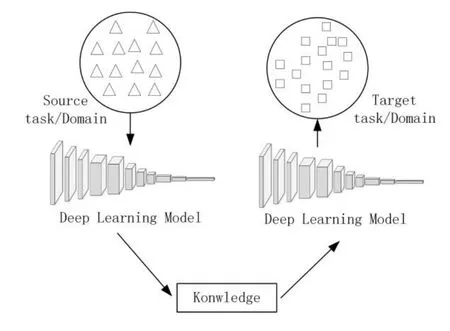
图1 深度迁移学习示意图
3 多源域深度迁移学习的液晶面板缺陷检测
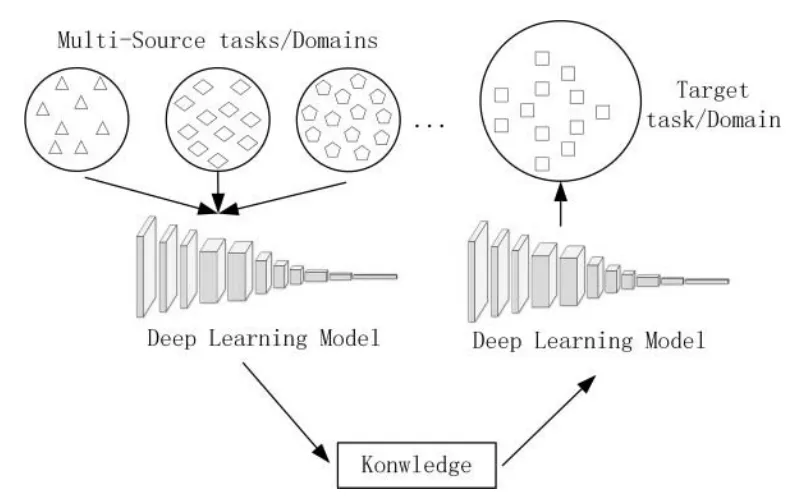
图2 多源域深度迁移学习示意图
本文采用Mask R-CNN作为多源域迁移学习的主干网络,Mask R-CNN是何凯明在2017年提出的目标检测深度神经网络框架,是目前领先的目标检测算法。该网络使用了一个全卷积层Mask层,并整合了焦点损失[18]、特征金字塔[19]和Faster R-CNN等[20]算法,将检测和目标分割同时完成,实现了较高的检测精度。但是直接将该算法应用在液晶面板缺陷检测的任务时,结果表明检测性能达不到工业生产的要求,一是因为数据质量参次不齐,二是此类小目标识别问题需要提取更加精细化的特征。本文以此框架为基础,进行了基于混淆域学习的方式迁移学习训练,最终得到了对液晶面板缺陷能够精准检测的模型。
3.1 基于混淆域的深度迁移学习算法框架
设X为样本的输入空间,x∈X为一个输入样本;Y为缺陷类型的标签空间,y∈Y为一个对应的标签。将源域和目标域上存在的分布分别记作,他们均是未知的分布,且他们有着一定的相似性和差异性。整个目标检测任务的学习最终的目的是给定目标域中的任一个样本x,通过其分布能够预测其准确的标签y。由于目标域的数据质量和数量都不足以表达该目标检测任务的真实分布,所以仅仅只在目标域上进行训练得到的预测的性能并不理想。多源域迁移的作用就在于能够利用多源域的分布对目标域的分布进行补充,将多种分布的知识整合至目标域中。如图3所示,整个网络由四个部分组成,第一部分是由Mask R-CNN的特征提取骨干网络组成的特征提取模块(Feature extraction Module,FEM),第二部是由Mask R-CNN的分类回归和全卷积网络部分所组成的液晶面板缺陷目标检测模块(LCD Defect target detection module,LDTDM),第三部分为全卷积层和交叉熵组成的域分类模块(Domain classification module,DCM),第四部分则是多源域学习网络结构中承上启下的关键部分:多源域逆梯度层(Multi-source domain reverse gradient layer,MDRGL)。
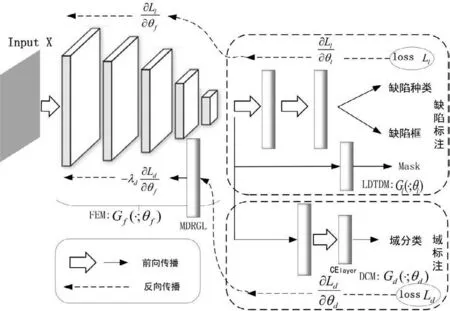
图3 基于域混淆学习的多源域深度迁移学习算法框架
3.2 基于混淆域的深度迁移学习的损失函数及其反向传播算法
为了保证源域数据集对目标域做出正向影响,本算法在网络的特征提取模块进行了混淆域学习,保证该模块内源域数据和目标域数据均对网络的参数学习均有贡献。要保证源域数据对目标域是正迁移(即对目标域分类器性能有促进而非破坏),则必须保证源域学习和目标域学习具有域不变的特性,也即分布函数式子(1)和(2)
他们应具有相似的分布,由于该分布函数均属于高维空间,且随着学习不断迭代的过程会不断改变,所以直接测量二者的相似度来做出调整是比较困难的。但从域分类损失函数的角度分析是可以解决这个问题的,可以观察到如若要保证FEM部分对不同域数据具有域不变特性,只需保证该模块输出的特征对域的分类效果几乎没有即可,也即域分类损失最大。与此同时,域分类损失函数其本身的任务决定了其目标是习得参数 使得损失函数最小,因此对特征提取模块的域混淆学习变成了二者的对抗学习,将其公式化可以表述如式(3)所示的损失函数。
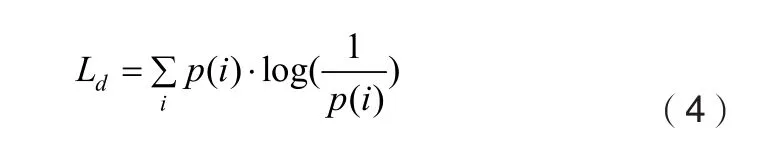
其中,n为源域数,本文选取了四个源数据域的数据集参与混淆训练,因此n取值为4。
基于式(3)混淆域损失,多源域深度迁移算法的训练最终要寻找的最佳参数如式(5)和(6)所示。
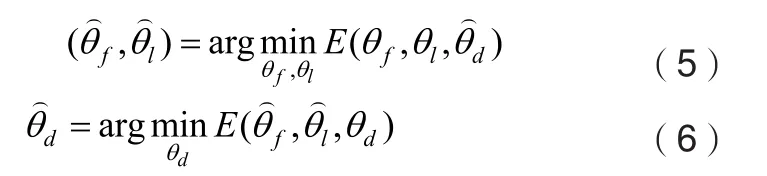
在参数学习阶段,仍采用SGD的学习算法进行反向传播,特征提取模块和缺陷检测目标检测模块所学习的参数和学习方法和Mask R-CNN一致。混淆学习在域分类模块向后传播的梯度为,在缺陷目标检测模块其向后传播的梯度为。MDRGL层为多源域逆梯度层,其目的是改变梯度方向流动时的符号,为特定域的梯度附上不同的权值,保证域混淆过程中权值更新的进行。网络的各个部分参数更新规则如式(7)-(9)所示:
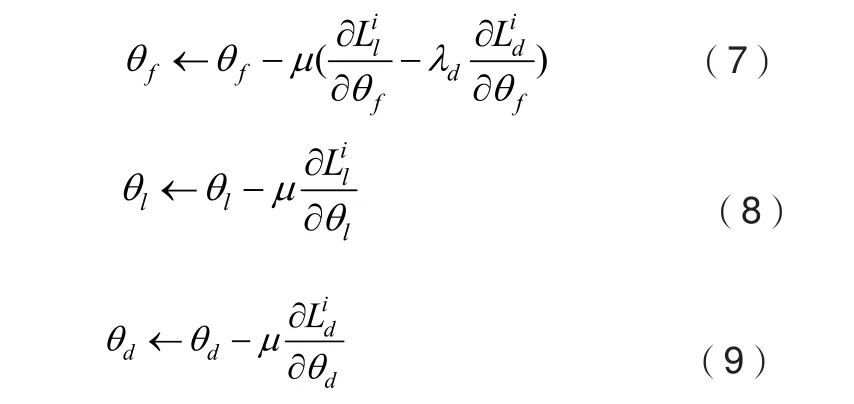
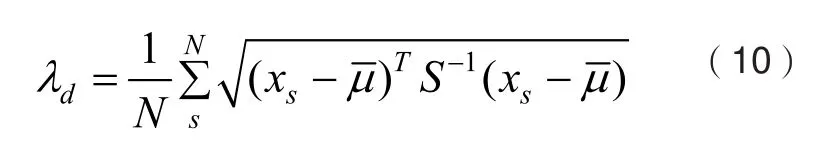
4 仿真实验
4.1 实验评价指标
本论文中使用所有缺陷类别的平均准确率(mean Average Precision,mAP)作为最终的评价指标,其定义为所有缺陷类别的准确率-召回率曲线面积之和除以缺陷类别数目,如式(11)所示。
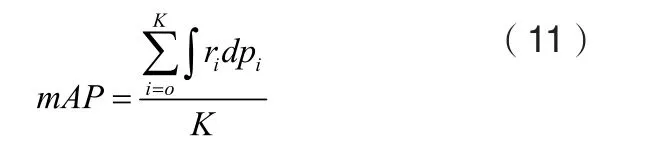
4.2 实验结果分析
本实验的环境为Intel Core i7-7700HQ 、CPU2.80 GHz、GPU Nvidia1080、内存8GB的平台上,利用Tensor flow2.0平台完成。本实验使用的数据集为自制的液晶面板缺陷数据集,该数据集主要由6种液晶面板缺陷组成,这六种缺陷类别分别是:Mura、划痕、暗点、亮点、划缺和漏光。数据集中包含每种缺陷类别的图片数量约800张。为进行多源域的迁移学习,本文收集了多种类似液晶面板图像的四种源域数据集,它们分别是DAGM数据集、GDXay数据集、Crack Forest数据集和Isheet数据集。其中DAGM数据是一个在2007年在“工业光学检测的弱监督学习”比赛中所发布的数据集;GDXay数据集是论文[21]所发布的工业缺陷的X射线数据集。Crack Forest数据集是论文[22]所发布的针对城市道路缺陷的数据集。最后一个Isheet是本文所收集制作的铁皮缺陷数据集。
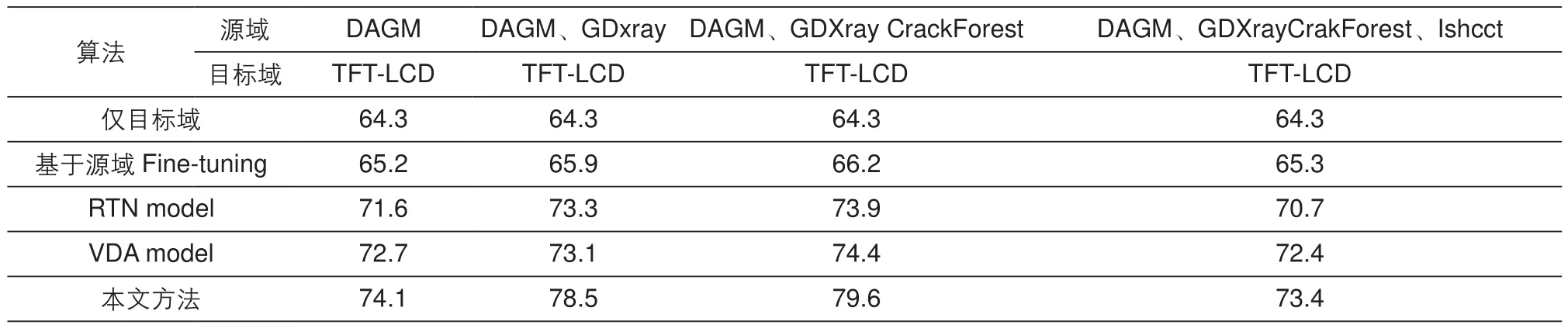
表1 算法性能对比表
表1展示了本文所提出的算法和目前在迁移学习领域表现最好的几种算法进行对比的结果。表中涉及的算法如下:第一行为Mask R-CNN仅在目标检测数据集TFTLCD上进行训练,第二行为Mask R-CNN网络在对应的源域数据集上进行预训练之后,在目标数据集上进行Fine-tuning,第三行为论文[23]所提出的基于迁移学习的RTN网络,其主要算法为将网络的前大半部分层的预训练参数迁移至目标任务的网络,作为其特征提取模块,并在其后添加自适应分类器(adaptive classifiers,AC)进行预测。第四行为论文[24]在2017年所提出的VDA算法(Visual domain adaptation,VDA),其核心思想是将自适应学习和迁移学习结合,基于自适应的矩阵进行知识的迁移。本文将上述四种算法框架在表1所示的四种源域数据集和液晶面板缺陷数据集上进行了性能对比。
实验结果表明,来自多源数据的丰富度越明显时,算法在目标域上表现有显著提升,但从表的最后一列观察得到其性能有所下降,其主要原因在于该数据集Isheet为自制的铁皮缺陷数据集,其与目标域特征相差较大,因此产生了负迁移。从表的纵向结果可以看到,相对于仅在目标域的液晶面板数据集TFT-LCD数据集上训练所得的检测效果而言,本文所提的算法有23.8%的提升,达到了79.6%的mAP。同时,本文算法在液晶面板任务检测中的性能也超过了目前性能最优的VDA和RTN算法。同时,本文针对Mura缺陷对比了上述几种学习算法框架,得到了他们的precision-recall图,如图4所示。
5 结束语
本文提出了基于Mask R-CNN的多源域迁移学习的液晶面板缺陷检测方法,主要针对缺陷检测问题中普遍存在的数据不足和模型泛化性能较差等问题,采用来源于四种源域的数据进行混淆域学习。实验表明,该算法与已有的缺陷检测算法对比,具有更高的检测精度和泛化性能,在液晶面板数据集TFT-LCD上达到了79.6%的mAP,相比非迁移学习方法提升了23.8%。该算法还且拥有良好的检测效率,适用于工业生产的要求。
本文认为针对此类训练数据不充足的异常检测类型的问题,在迁移学习方面仍有进一步研究的空间,后续的研究将在针对优化缺陷知识的迁移方式上展开。
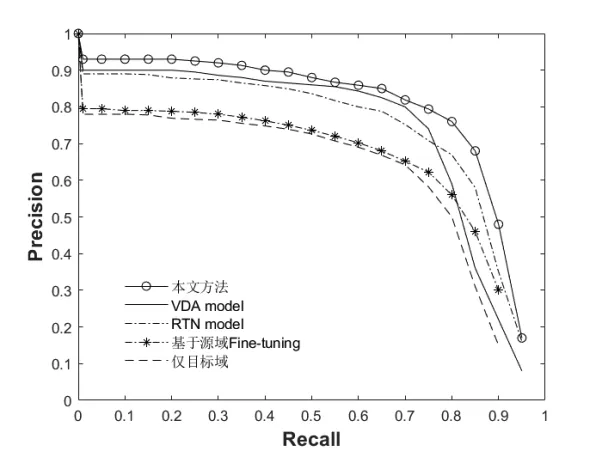
图4 不同算法下Mura缺陷的Precise-Recall图
