改进的ABE在公有云存储访问控制中的研究*
2019-04-18鲍安平吕湛山
许 萌,鲍安平,吕湛山
1.南京信息职业技术学院,南京 210023
2.山西晋煤华昱煤化工有限责任公司,山西 晋城 048000
1 引言
随着计算机网络以及软硬件技术的蓬勃发展,云存储技术以及相关应用正处于快速成长的阶段[1]。这使得数字资源的在线传播变得愈加便捷,人们只要通过手机等无线设备就可以轻松地获取各类数字资源。然而考虑到云端设备是大多为第三方拥有,通过云端来分享数字资源有可能会威胁到数据拥有者的隐私。因此针对云存储建立敏感数据隐私保护机制就变得至关重要。不仅如此,任何云存储平台涉及到海量用户的活跃参与,因此急需一套细粒度的访问控制机制来设置海量用户的访问权限。
属性基加密算法[2-3](attribute-based encryption,ABE)是一种具有相当应用前景的技术,它不仅能够保证数据存储的安全性,还能够实现灵活的访问权限设置。基于属性的密码体制目前包含两大类经典的算法,一类是基于密文策略的属性加密算法[4-5](ciphertext-policy ABE,CP-ABE),该算法将访问策略嵌入到密文当中,而用户的私钥则绑定了一个用来表示用户身份的属性集合。另一类是基于密钥策略的属性加密算法[6-7](key-policy ABE,KP-ABE),该算法将访问策略嵌入至用户的私钥,而密文则与一个属性集合相关。当属性集合与访问策略足够接近并完成匹配的话,用户就能够成功获取数据的明文。相比传统公钥加密算法,ABE最大的特点在于它具有一种模糊性质,即能够实现加密数据的多对多分享。因此以上性质使得ABE能够为公有云上的数据存储与分享提供既安全又灵活的访问控制。
1.1 相关研究
Sahai和Waters[3]首次提出了一种模糊的基于身份加密算法(fuzzy identity-based encryption,FIBE)。FIBE采用一种描述性的属性集合来定义身份,该算法为ABE算法的提出开创了先河。Goyal等人[6]在FIBE的基础上首次提出了一种KP-ABE算法,将访问策略嵌入到密钥当中,而属性集合则嵌入到密文当中,该算法结构简单但是功能有限,并不适合在公有云环境中应用。Bethencourt等人[4]受到启发,有针对性地提出了一种CP-ABE算法,使得加密者能够自由制定访问策略,为ABE算法在数据存储与访问控制领域的应用奠定了基础。文献[8]提出了一种基于多鉴权中心的ABE算法,每个健全独立拥有各自的主密钥并且管理不同的属性,这使得单个健全中心不再具有独立获取明文的能力。Hur[9]指出多个鉴权中心共同产生非常庞大的互动开销,提出由健全中心和数据存储中心协作产生主密钥,并提出了一种间接撤销方式,在提高了计算效率的同时也丰富了ABE的功能。文献[7]提出了一种在标准模型下实现完全安全性的KP-ABE方案,同时计算效率与选择性安全模型下的方案相当。文献[10]采用零知识证明使两个鉴权中心互动产生主密钥从而有效防止密钥托管问题的产生,同时支持密钥追责,用户不可以轻易地将自己的私钥交由他人使用。文献[5]提出了一种支持直接撤销的CP-ABE方案,鉴权中心通过维护一个撤销列表实现细粒度的快速撤销,同时其密文、私钥和公钥的长度都有所优化,整体效率在一定程度上有所提高。Karati等人[11]考虑到双线性配对是影响ABE计算效率的主要因素,提出了一种不需要双线性配对的ABE算法,但是该算法采用阈值门作为访问策略,因此算法在整体显得不够灵活。文献[12]针对托管、滥用等密钥管理难题,提出了一种分布式的密钥管理协议,同时采用一种外包解密的思想使得解密者不需进行任何双线性配对就可以获取明文,但是算法整体的计算负载仍然非常大。
1.2 研究动机
尽管国内外学者对ABE算法进行了众多的研究,但是在公有云的数据存储与访问控制领域,ABE距离实际应用还存在两个亟待解决的问题:
(1)从安全角度考虑,最主要的问题在于现有方案当中的鉴权中心必须是完全可信的机构,因为鉴权中心负责生成全部的公钥和私钥。这就意味着鉴权中心可以在用户不知情的情况下,可以利用主密钥独立自主地生成私钥,进而尝试解密截取的密文。这个 问题 被称 为密 钥托 管 问题[8-10,13](key escrow problem),是ABE与生俱来的安全性难题。
(2)从计算复杂度考虑,ABE在加解密计算过程中涉及大量的双线性配对,而双线性配对本身就需要消耗很大的计算资源[11,14]。在个人电脑乃至大型服务器端,这样的计算消耗尚可以接受。但在移动云计算逐渐普及的今天,即使软硬件技术得到极大的发展,移动端的电力和计算资源仍然是非常珍贵的[15]。因此在这样的情况下,如果将现有的方案直接应用于移动端,那么对优化用户使用体验来说将是一次巨大的考验。
针对以上问题,本文基于KP-ABE改进了ABE算法,改进如下:一方面在鉴权中心无法独立生成私钥,即使其安全等级下降为半可信,算法仍然能够提供安全的密钥管理;另一方面,改进的算法在加解密过程中不需要进行任何的双线性配对,相比现有的ABE算法具备更高的计算效率,更适合在移动端构建轻量级的加密与访问控制方案。最后的规约证明表明,本文方案在随机预言机模型下能够抵抗选择密文攻击。
2 模型架构
本文算法应用在云存储访问控制当中的模型架构如图1所示。模型当中包含四类主要角色:
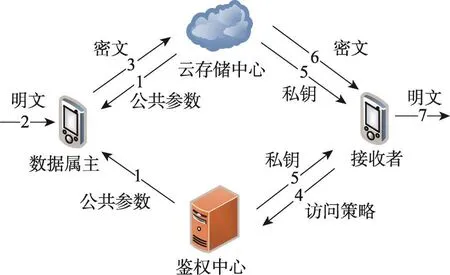
Fig.1 Architecture of model图1 模型架构
(1)数据属主:该角色拥有对数据的所有权,并试图通过移动设备将数据上传至云平台,并向指定的群体分享该数据,同时不希望被该群体之外的人获取该数据。
(2)鉴权中心:该角色在框架内是唯一的,负责密钥的生成与发布并使之用于访问权限的控制。
(3)云存储中心:该角色负责存储和管理经过加密的数据,同时在本文算法当中也将承担一部分的密钥生成与发布工作。
(4)接收者:该角色试图通过移动设备访问云存储中心,并获取云存储中心当中的数据。
本文算法将通过以上四类角色的互动来实现云存储平台上数字资源的访问控制。在平台启动时,鉴权中心以及云存储中心基于密码学原理并结合系统中的全局属性生成一套公共参数,并向全网的数据属主广播该公共参数。每个接收者在平台中注册时将获得自己的访问策略,由鉴权中心和云存储中心经过协商分布式地生成接收者的私钥。数据属主通过云存储平台分享数字资源之前,首先根据自己的属性集合并结合公共参数对数据进行加密操作,然后将密文上传至云存储中心。当某个接收者尝试下载数字资源时,他将利用自己的私钥试图解密密文,若其访问策略与密文中的属性集合相匹配,那么则可以顺利解密得到数字资源的明文,反之则无法解密从而获取不到关于数字资源的任何信息。
3 算法设计
本文算法通过四个子算法实现数据属主、鉴权中心、云存储中心以及接收者之间的互动,最终实现云存储的安全访问控制,具体如下:
3.1 初始化算法
受文献[12]启发,在本文提出的改进方案中,初始化算法由密钥中心和云存储中心共同执行。首先定义全局属性空间为 Ω={θ1,θ2,…,θn}。设G 和GT是两个阶为大素数q的加法循环群,P为群G的一个生成元。定义一个哈希函数为H:G→Zq。算法首先输入一个安全参数k,然后由密钥中心生成一组唯一的、与全局属性空间相对应的整数参数{t1,t2,…,tn}∈Zq。对于全局属性空间中的任意一个属性θx∈Ω,计算Tx=txP。同时,云服务中心选择一个唯一的元素y∈Zq并计算Y=yP。最终,初始化算法输出基本公共参数:
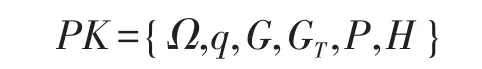
密钥中心保留自己的主密钥:
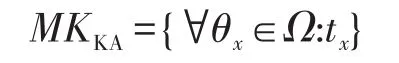
然后输出自己的公共参数:
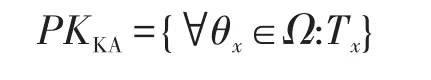
与此同时,与服务中心保留自己的主密钥:
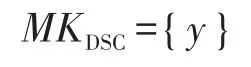
然后输出自己的公开钥:
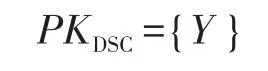
最终初始化算法输出公共参数为:

3.2 密钥生成算法
为了防止密钥托管,有些学者提出了多鉴权中心的方案[16-17]。本文算法不打算增加任何实体,而是利用鉴权中心和云存储中心的协作共同生成密钥。算法输入为鉴权中心和云存储中心的主密钥MKKA和MKDSC以及公共参数params。当接收者发出私钥生成请求时,他需要提交一个访问策略T。对于访问策略T,其中任意一个叶节点均表示某一个属性,而其余所有的非叶节点均为阈值门。对于任意一个节点x,均有一个索引值index(x)与之相对应,如果该节点是非叶节点,如果它的子节点个数是mx,那么该节点的阈值为kx(1≤kx≤mx),相应的阈值门为(kx,mx);如果该节点是叶节点,则该节点的阈值门为(1,1)。随后鉴权中心与云存储中心通过以下步骤共同生成数据访问者的私钥:
(1)云存储中心生成一个随机数r∈Z*q,计算A=ry并将其发送给鉴权中心。
(2)为了不失一般性,假设访问策略T的根节点为root,其阈值为kroot。当鉴权中心获得参数A后,为访问策略的根节点生成一个随机多项式qroot(X),该多项式满足以下两个条件:
①多项式的次数为droot=kroot-1;
②多项式常数项等于参数A,即qroot(0)=A。
(3)对于任意节点的子节点x,设其阈值为kx,鉴权中心同样生成一个对应的随机多项式,该多项式满足以下两个条件:
①多项式的次数为dx=kx-1;
②多项式常数项为qx(0)=qparent(x)(index(x)),其中函数parent(x)返回x的父节点。
(4)对于访问策略中的任意属性θx,鉴权中心发送Dx=qx(0)+tx给接收者。
(5)云存储中心发送D=r给接收者。
最终,数据访问者获得关于访问策略T的私钥为:
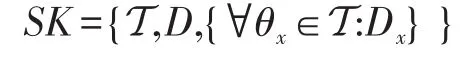
3.3 加密算法
该算法由数据属主执行,算法输入为公共参数params、数据属主的属性集合S和待分享数据的明文m。首先选择一个秘密参数s∈Zq,然后执行如下计算:
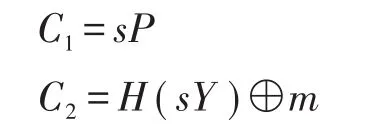
对于属性集合中的任意属性θx∈S,计算:
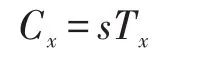
最终算法输出密文:
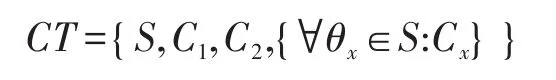
3.4 解密算法
该算法由接收者执行,算法输入为公共参数params、待分享数据的密文CT和接收者的私钥SK。在说明算法执行步骤前首先引入关于拉格朗日插值的概念,假设对于一个元素有限的数值集合S={a1,a2,…},关于其中任意一个元素i的拉格朗日插值表示为:
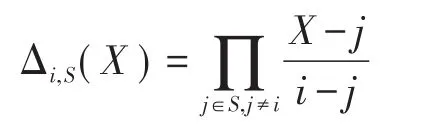
其次定义两个函数:
Λ(x):对于访问策略中的任意一个节点x,返回x所拥有的全部子节点。
Λ′(x):对于访问策略中的任意一个节点x,返回x所拥有的全部子节点的索引值。
对于访问策略中的任意节点x,解密算法将执行一个函数DecryptNode(x),该函数的执行过程如下:
若x是叶节点,则计算:
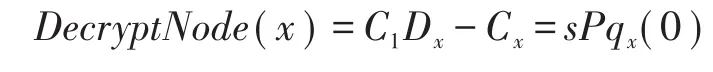
若x是非叶节点,记x的任意子节点z经过该函数计算过后得到的结果为Fz,那么该函数对于x的计算为:
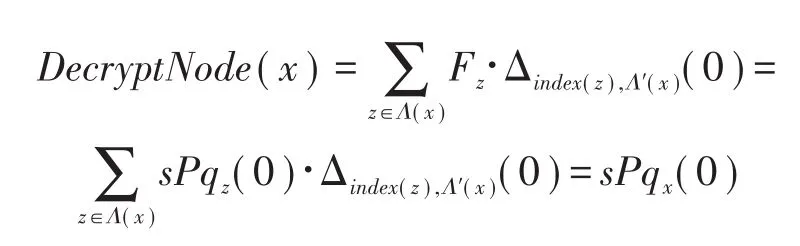
经过以上函数的迭代计算得到:
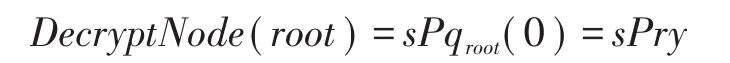
最终通过以下计算得到明文:

4 算法分析
4.1 机密性
算法将因子H(sY)嵌入到了密文当中,该秘密隐藏了云存储中心的主密钥MKDSC=
在任意不同的两种明文的加密过程中,由于加密算法在因子H(sY)中还嵌入了不同的秘密随机数s,即使接收者每次都能正确执行解密操作,他也只能获得与当前密文相关的秘密。也就是说,每一个因子H(sY)只与当前的密文相关,接收者无法通过之前获得的因子去解密其他的密文,因此保证了密文与密文之间的安全隔离,彼此不互相干涉机密性。
4.2 抗合谋攻击
合谋攻击是一种针对密码系统的经典攻击方式。合谋攻击指的是若干个攻击者通过沟通协商,将各自持有的私钥组件进行拼接组合,非法地生成一个全新的私钥。这个全新的私钥拥有更强大的解密能力,能够解密那些利用私钥组件无法单独解密的密文。
在私钥生成阶段,云存储中心每生成一个全新的私钥之前都会产生一个独特的随机数r。云存储中心将这个随机数与其主密钥MKDSC=
4.3 抗密钥托管
本文算法利用鉴权中心与云存储中心的协作实现私钥的分布式生成。在私钥生成阶段,云存储中心产生一个随机数r并与其主密钥相乘获得待分享的因子ry,紧接着将因子ry发送给鉴权中心。随后鉴权中心负责生成相应的接收者私钥。
对于云存储中心来说,它不能知道鉴权中心的主密钥MKKA={∀θx∈Ω:tx},从而无法恢复出私钥当中的组件{∀θx∈T:Dx}。而对于鉴权中心来说,它不知道云存储中心的主密钥MKDSC=
为了说明本文方案在抗密钥托管方面进行改进的效果,将本文算法与其他类似的抗托管算法进行了对比,对比结果如表1所示。在这里定义一方将一组数据发送给另一方为1次交互。在表1当中列出了现有的克服密钥托管的方案,在生成私钥时所需的交互次数总数。改进的ABE算法具备分布式的密钥生成机制,其所需的交互次数为1次。文献[8]为了克服密钥托管问题,采用了多鉴权中心的方法,每个鉴权中心负责生成关于一部分属性的密钥组件。在生成私钥的过程中由于每两个鉴权中心之间需要完成一些交互,因此当鉴权中心个数为n,总体上生成私钥所需的交互次数复杂度为O(n2)。文献[13]为了克服这种复杂度攀升的问题只采用了两个鉴权中心,而两个鉴权中心只需要进行一次交互即可实现私钥的发布。文献[9]进一步将鉴权中心的部分功能转移至云存储中心上去,在不需要增加任何实体的情况下需要3次交互就可以有效克服密钥托管问题。文献[12]在此基础上通过更多的交互实现了私钥的分布式管理,每次生成私钥需要进行8次交互。因此本文方案在抗密钥托管的同时,将生成私钥所需的交互次数降低到仅1次,相比表1中其他方案是最高效的。另外,本文方案所采用的模型只需要一个鉴权中心,利用该鉴权中心与云存储中心进行交互即可,不需要增加额外的鉴权中心来承担密钥管理工作,因此在模型复杂度上尽可能做到了简洁。综上所述,本文方案的抗密钥托管功能是比较高效、简洁的。

Table 1 Comparison of different escrow-free mechanisms表1 不同抗托管机制的对比
4.4 计算效率
为了分析本文算法经过改进后的计算性能,将本文算法与文献[4-7,18]中的算法进行了对比。为便于分析比较,如表2所示,首先定义了若干变量。

Table 2 Definitions of some variables表2 若干变量的定义
其次,从密钥尺寸、密文尺寸以及加解密过程中所需的双线性配对次数三方面对本文算法以及其他类似算法进行了分析。结果如表3所示,文献[4]设计了一种基于密文策略的属性加密方案,由于支持数据属主直接定义访问策略,导致接收者私钥尺寸过大,同时接收者必须执行大量的双线性配对才能获取消息明文。文献[5]提出了一种支持用户直接撤销的ABE方案,将接收者的身份信息植入到其私钥当中,同时由鉴权中心维护一个撤销用户的列表,在执行加密算法时将列表植入到密文当中。可以看出,文献[5]的方案相比其余方案并不算大,但是在密文当中植入了撤销列表,并为每个撤销用户配置了1个位于循环群G上的唯一元素,而且在解密时需要额外执行2Nr次双线性配对。文献[6]最早提出了KPABE算法,其密钥尺寸、密文尺寸以及双线性配对次数都非常小,计算效率高,但是考虑到只实现了KPABE算法的核心功能,其计算和存储代价仍然不理想。文献[7]提出的是一种在标准模型下完全安全的ABE算法,该算法建立在合数循环群上,而其他方案都是建立在素数群上,但是可以看出该方案在提高了系统的安全性的同时保持了与文献[4]方案相当的计算效率,无论是密钥尺寸、密文长度还是解密时需要执行的双线性配对数量,都与文献[4]方案基本相当。文献[18]为了增强访问策略的表达性,采用了属性矩阵来构成属性之间的等级关系,其中属性矩阵的行数L代表了等级总数,但是这也导致了接收者不得不执行大量的双线性配对来获取消息明文。

Table 3 Performance comparison表3 性能对比
在本文所提出的改进ABE方案中,密钥尺寸与文献[6]方案相比只多出一个,在假设访问策略与属性集合所包含属性的平均数目相当的情况下,本文所提出的方案在密钥尺寸上几乎是文献[4]和文献[7]方案的50%。同时,本文改进的ABE算法在密文尺寸上与文献[4]和文献[18]所提方案相同,都是(2Nas+2)几乎是文献[6]和文献[7]方案的2倍。然而,本文方案在加解密过程中不需要执行任何的双线性配对,极大地降低了计算开销,这是其他方案都不具备的性质。因此,文本改进的方案在效果上对于移动端的数据属主和接收者更为友好,更适合于在移动云计算环境下部署的相关应用,例如通过手机端进行私人健康数据、企业内部文件以及社交媒体数据的安全存储与分享。总之,不论是数据属主还是接收者,只需要在移动端执行少量的加解密计算即可以实现数据在公有云上的存储、分享等操作。
5 安全性证明
5.1 困难假设
对于本文所设计的方案,其安全性是构建在计算性Diffie-Hellman问题[19](computational Diffie-Hellman problem,CDH)的困难性基础之上的。
定义(计算性Diffie-Hellman困难假设)已知一个阶为素数q的加法循环群G,设P是群G的一个生成元。那么,已知群G中的两个元素P1=aP和P2=bP,其中a,b∈Zq,不存在一个概率性的算法能够在多项式时间内计算出P3=abP。
5.2 证明过程
基于给出的困难假设,给出如下的定理:
定理如果计算性Diffie-Hellman问题是困难的,那么本文设计的方案在随机预言机模型下能够抵抗选择明文攻击。
证明为了给出定理证明,沿用了文献[20]中的证明思路设计了如下的挑战游戏:
(1)初始化阶段
定义一个阶为素数q的加法循环群G,P为群G的一个生成元。挑战者C选择两个随机数a,b∈Zq,然后将P、P1=aP和P2=bP发送给模拟器B。
(2)询问阶段
本阶段敌手将向模拟器发起以下三种询问并试图从中获取信息:
①公共参数询问:模拟器B定义一个随机预言机H:G→Zq,将参数
②私钥询问:模拟器生成第二个列表List2={T,D,{Dx}}。当A发送关于访问策略T的私钥询问时,B开始扫描整个列表。如果T中包含列表List1当中的属性,那么告知A游戏结束并显示错误代码ERROR1;如果T不包含List1当中任意属性的话,选择两个随机数r,R∈Z*q并为T的根节点root分配一个随密结果m=CT⊕H(X),并将新的{S,CT,X,H(Xm)},添加进List3里。
(3)挑战阶段
敌手A向模拟器B提交两段长度相同的明文m0和m1,以及一个挑战属性集合S*。模拟器随后检查挑战属性集合中的所有属性是否都在List1当中。如果存在属性不在List1中,那么告知A挑战结束并返回错误代码ERROR4;如果所有属性都在List1中,那么检查所有属性在List1里对应的元素c。若存在c=0,那么告知A挑战失败并返回错误代码ERROR5,否则从List3中随机抽取元素H(X),选择一个随机的比特β∈{0,1}以 及 一 个 随 机 数 s∈Z*q,随后开始计算。最终模拟器机多项式qroot,使得droot=kroot-1,同时使得qroot(0)=R。
③解密询问:模拟器生成第三个列表List3={S,CT,X,H(X),m}。当A发送一个关于属性集合S的密文并请求解密时,B开始检查S当中的属性是否出现在List1中。如果S当中存在属性不在List1里,那么告知A游戏结束并显示错误代码ERROR2;否则进一步检查S当中的属性在List1当中对应的元素c。如果存在属性对应的元素c=1,那么告知A游戏结束并显示错误代码ERROR3;否则生成一个S可满足的访问策略T,并生成对应的私钥。模拟器通过该私钥计算 X=D-1DecryptNode(root)和H(X)。最终B返回加B返回挑战密文。敌手A通过密文输出β′作为对β的猜测。如果β′=β,那么敌手取胜,同时模拟器输出P′3=s-1X给挑战者C作为CDH问题的解。
由以上游戏流程可知,当ERROR1、ERROR2、ERROR3不发生时,模拟器返回的所有结果都是有效的,而且与本文的方案在真实环境中的计算结果无法区分。同时当ERROR4和ERROR5不发生时,模拟器才有可能借助敌手的结果给出CDH难题的正确解。记以上游戏过程中公共参数询问的次数为q1,私钥询问的次数为q2,解密询问的次数为q3。设全局属性空间大小为每一个访问策略里包含的属性平均个数为u。根据以上参数可以得到ERROR1到ER ROR5不发生的概率。这些事件的概率如表4所示。

Table 4 Occurrence probabilities of all events in challenge game表4 挑战游戏中所有事件发生的概率
根据表4中各个事件的概率可得,模拟器给出CDH问题正确解的优势ε′为:
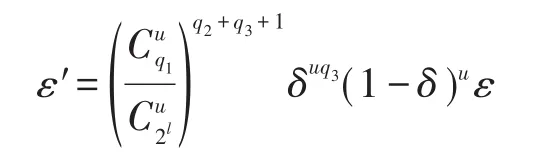
因此若存在多项式时间的算法能够以不可忽略的优势给出CDH问题的正确解,那么一定存在多项式时间的敌手能够以不可忽略的优势破解本文的方案。而正因为CDH问题是难解的,那么可以证明,本文方案是安全的。
6 结束语
针对现有ABE方案的不足,基于KP-ABE改进了现有的ABE算法,设计了一种高效的抗托管云存储访问控制模型,该模型在不增加任何实体的情况下能够分布式地生成接收者私钥,解决了ABE算法中的密钥托管问题。由于加解密过程中不需要进行任何双线性配对,该模型能够保证较高的计算效率。最后通过规约证明本文方案在随机预言机模型下能够抵抗选择密文攻击。提出的算法在安全性以及算法效率两方面对现有的ABE算法进行了改进,适合个人医疗电子数据管理系统、大型企业信息管理系统、网络云盘等基于公有云的应用场景。相比现有的ABE算法,更适合在移动端构建轻量级的加密与访问控制方案。
此外,提出的算法在密文长度上仍然保持着较长的尺寸,某种程度上可以认为是以存储为代价换取了计算效率的提升。同时算法仅仅在普适的公有云环境下构建,尚未针对具体的应用采取优化措施。因此实现进一步缩短密文的尺寸,同时在真实应用场景下进行实际的部署,将是下一步工作考虑的重点。
