国家高性能计算环境事件流系统的设计*
2019-04-18赵一宁肖海力
赵一宁,肖海力
中国科学院 计算机网络信息中心,北京 100190
1 引言
网格环境通过整合、管理和调度分布式的异构计算资源,使其形成一个虚拟的计算集群,实现提高高性能计算资源利用效率、提高用户服务可靠性的目标。国家高性能计算环境是由中国科技部长期资助建设的中国国家级网格计算环境[1-2],目前已经接入全国范围内的17个结点的计算集群,其中包括目前计算能力排名世界第一和第二的神威太湖之光和天河二号,聚合计算资源总量超过185 PFlops,总存储量60 PB。国家高性能计算环境使用中国科学院计算机网络信息中心自主研发的网格中间件SCE[3]为用户提供便捷的高性能计算服务。
在国家高性能计算环境中,各种程序和系统通常都会以日志的形式记录运行中发生的各种事件。这些数据数量庞大,而且其中含有许多有助于维护系统安全和稳定运行的重要事件记录。通过监控、分析、展示这些事件,可以对环境形成有效支撑。在过往的研发工作中,设计了网格环境日志分析框架LARGE(log analysing framework in grid environment)[4],通过分析日志来发现隐藏在环境日志中的隐含信息。
然而由于环境设备遍布于各地的计算集群中,记录事件的各类日志难以直接被获取。同时由于系统程序记录事件的方式各自不同,日志的格式也变化多样,系统维护人员几乎不可能快速准确地理解其中所表达的内容。
针对这种情况,设计了国家高性能计算环境事件流处理与分发系统,专门用于收集环境中各种系统程序的日志数据。环境事件流处理与分发系统以Apache Kafka与Logstash程序组成消息的收集与分发平台,通过实现事件工厂来对收集到的环境事件进行分类、解析、筛选、处理和封装。事件工厂由采集模块、分拣模块、解码模块、过滤模块、处理模块和封装模块六部分组成,通过一系列加工流程,将原本内容形式各异的事件日志转化为统一格式的标准事件,并提供给包括日志分析框架和环境展示平台在内的各种对事件有需求的应用。将环境事件流处理与分发系统部署到了环境服务器中并进行了实际运行测试,结果表明该系统的事件处理和转发的延时较低,完全可以满足环境应用对于事件实时响应方面的需求。
本文首先具体介绍国家高性能计算环境对于事件流处理与分发系统的需求,然后在第3章介绍事件流系统的系统结构和主要组成部分。第4章将阐述关于事件工厂的设计。第5章将给出关于事件流系统的实际运行测试结果。第6章是日志传输与分析的相关工作介绍。第7章将对本文进行总结,并且对未来的工作作出展望。
2 背景与需求介绍
国家高性能计算环境[1]是由中国众多国家级计算中心和高校的计算集群聚合而成的大型高性能计算环境,其中中国科学院计算机网络信息中心是环境的北方主结点,也是其运行管理中心。国家高性能计算环境使用中心自主研发的SCE中间件[3]作为资源调度核心,将来自多个集群的异构资源整合起来并通过统一的接口提供给环境用户,实现了轻量化、稳定、可靠、低维护成本等目标。通过SCE中间件,国家高性能计算环境聚合计算能力超过185 PFlops,为国内众多高校和机构的研究人员提供了优质计算资源,应用成果遍及量子化学、分子模拟、高能物理、生物科学、流体力学、材料科学、大气与海洋学、天文学等众多研究领域。
出于维护环境正常稳定运行的目的,系统管理人员需要监控环境状态和获取环境内部所发生的事件信息,以确保及时迅速地对环境产生的问题进行预防和处理。事件信息通常以日志的形式记录在各程序指定位置,方便管理人员对过往系统事件历史进行查阅。但由于国家高性能计算环境是一种聚合而成的复杂环境,其中包含了多种多样的程序和系统,因此各类事件也是复杂多变的,其事件表述格式、存储位置、内涵信息也都各不相同。例如,对于计算集群来说,所能产生的事件可能主要包括资源调度、计算任务的运行、硬件的工作状态等信息;而对环境层面的SCE中间件来说,所产生的事件可能更多的是关于用户登录认证、命令和请求的获取和交互、中间件与计算集群的网络交互等内容。
尽管不同类型维护人员对于这些信息的关注重点不同,但都需要一个关于信息的传输、筛选和提示功能。如果对于每一种类型的信息都各自建立一套处理系统,则所耗费的工作量巨大而且重复性高成本高,因此最好的解决办法就是建立一个统一的环境事件系统,对环境各处产生的多种类型事件进行采集和集中处理,然后再根据需求将这些信息分门别类地发送到相关人员和应用处。
因此设计了国家高性能计算环境事件流处理与分发系统。该系统将基于数据分发服务技术(data distribution service)[5],在环境事件产生源进行采集传输,根据事件内容和系统关注重点进行筛选和整合重构,并整理成为统一的格式,再分类发送到系统接口处。其他应用可以以订阅事件类型的方式接收特定类型的事件,在获取关注类型的同时避免接收不需要的信息。最终通过该系统实现事件处理即时化、内容分类具体化、服务接口统一化、消息分发定制化。
3 系统结构
环境事件流处理与分发系统作为国家高性能计算环境中对于事件的专用处理系统,其基本功能即消息数据的传输、存储与分发功能。采用Apache Kafka作为系统的基本数据分发平台,在此之上建立事件工厂模块,针对环境中几种主要的事件内容格式进行解析、筛选、处理分析和格式转换。此外使用Logstash作为系统的数据采集工具。图1为国家高性能计算环境事件流处理与分发系统的基本架构图。

Fig.1 Structure of event stream processing and distributing system图1 环境事件流处理与分发系统结构图
Apache Kafka是由Apache软件基金会开发的一个开源消息系统项目[6],目标是提供一个统一、高通量、低延迟的消息分发平台。Kafka基于Apache Zoo‐keeper实现多服务器间提供一致性服务,每个Kafka服务器被称为代理(Broker)。Kafka通过设置主题(Topic)实现消息分类,来自消息生产者(Producer)的消息被发送到指定主题中,存储于Kafka服务器中,消息消费者(Consumer)则通过订阅所需要的主题来接收这些类型的消息。在环境事件流处理与分发系统中,Kafka将同时承担两个任务,一是将采集到的数据按照其数据源类型发送到事件工厂的分拣模块等待处理,二是将事件工厂输出的统一格式的事件分类存储并发送到订阅相关事件类型的应用处。
Logstash是Elastic公司开发的一款开源数据处理程序[7],主要用于数据采集和传输,同时具备基本的数据标记和格式处理功能,通常用于日志收集工作。环境事件流流出与分发系统将采用Logstash将数据从源设备采集并添加格式类型标签,并经由Kafka转送到事件工厂。从Kafka的角度,Logstash是消息生产者,订阅事件的应用是其消息消费者,而事件工厂既是消费者也是生产者,它从Kafka接收原始数据并加工成事件再发送到Kafka处等待各个应用获取相关内容。
在环境各组件发生事件时,是由相应组件程序分别记录自己的事件日志,其中包含了所有可能产生的事件类型。然而在实际应用时,相关维护人员或应用程序往往只关心某一种到几种类型的事件。因此建立事件分类是环境事件流处理与分发系统所必须实现的环节。根据环境实际运行情况和使用需求,初步将事件划分为以下七大类:
(1)用户操作:表示用户在环境客户端执行了一种操作或请求,包括查询环境资源、提交作业、传输文件等。
(2)管理操作:该类事件为仅有管理权限的用户才能执行的操作的记录,包括建立用户组、修改用户权限等。
(3)作业状态:这类事件表示用户作业发生了状态变更,例如作业准备、作业运行、作业完成,以及提交产生错误、作业运行失败、作业被终止等异常事件,相关应用可以通过事件消息中记录的作业号来追溯相应作业。
(4)应用状态:主要表示集群中的应用程序的变更情况,主要包括安装、升级或版本变更、卸载等。
(5)集群状态:对于计算集群的当前状态的报告,可能是一种服务器与目标集群间的周期性通讯的事件,记录了集群的运行状态、当前作业数等相关参数。
(6)警报事件:这种类型的事件代表环境中产生了需要注意或及时处理的问题,例如密码攻击、磁盘已满、内存溢出、CPU过热、程序运行出现段错误等等,对实时性有一定要求。
(7)新日志模式:在进行事件处理时,系统日志将根据已经定义的日志模式库中的记录进行格式匹配,而日志模式则是对于过往日志的类别总结[8],然而当系统日志出现了不存在于过往日志的新模式记录时,系统无法判断是否需要针对该模式制定新的环境警报规则和策略,因此需要将其内容作为一种事件发布给制定警报规则的维护人员处。
相关应用程序在订阅事件时,将以上述七种类型为对象。对于每种类型事件还可以具体划分子类的情况,各应用需要自行定义相应的处理办法。在未来实际运行过程中如果出现新的需求,也可以在上述七种事件类型以外增添更多的基础事件类型对象。
4 事件工厂工作流程
在国家高性能计算环境中,环境中间件的组件和集群程序以及操作系统都可能成为环境事件的产生源,这些程序记录事件的方式各不相同,也就难以使用一种通用的方法获取其中信息。以Linux操作系统日志和SCE中间件日志为例,Linux系统日志的格式通常为英文句式,属于人类可读内容,然而对于机器来说其中的关键内容较少,仅存在于语句的特定位置;而SCE中间件日志的表现形式为许多字段,每个字段仅包含必要信息内容,特点是信息量大,便于机器提取信息,但人类不可读,仅具备专家知识的人员才能理解。对于这两种不同的事件形式,相关应用不可能使用同一种解析方法获取其中的信息。
出于此种需求,在环境事件流处理与分发系统中增加了事件工厂模块。事件工厂主要用于接收各种类型格式的事件,并使用各自的解析方法对其中主要内容进行提取,然后筛选可能含有重要内容的事件进行统一处理,最终将这些事件信息封装成为符合事件工厂统一接口的格式发布成为各种事件类型。当相关应用接收到订阅的事件时,只需要按照事件工厂的统一接口进行解析就可以获取其中的关键信息。
图2为事件工厂的内部模块以及工作流程图。如图所示,事件工厂主要包含六个模块,对于每一个需要分发的事件消息,都需要经过这六个模块。对于经由Kafka而来的原始数据,首先由采集模块将其获取到事件工厂处等待处理。采集模块通过实现Kafka的消费者客户端来达到收集原始数据的目的。
随后数据来到分拣模块,由于在负责源设备采集的Logstash程序已经为数据打上了数据源的标签,分拣模块将根据这些标签决定将数据发往何处。分拣模块还需要负责分行数据整合的问题:在记录日志时,部分程序会出现把一条消息分成多行日志进行记录的情况,而Logstash是以行为单位进行数据采集的。分拣模块就需要实现处理此类情况的方法,将分行的数据重新合并为一条事件记录,再发送到目标车间。
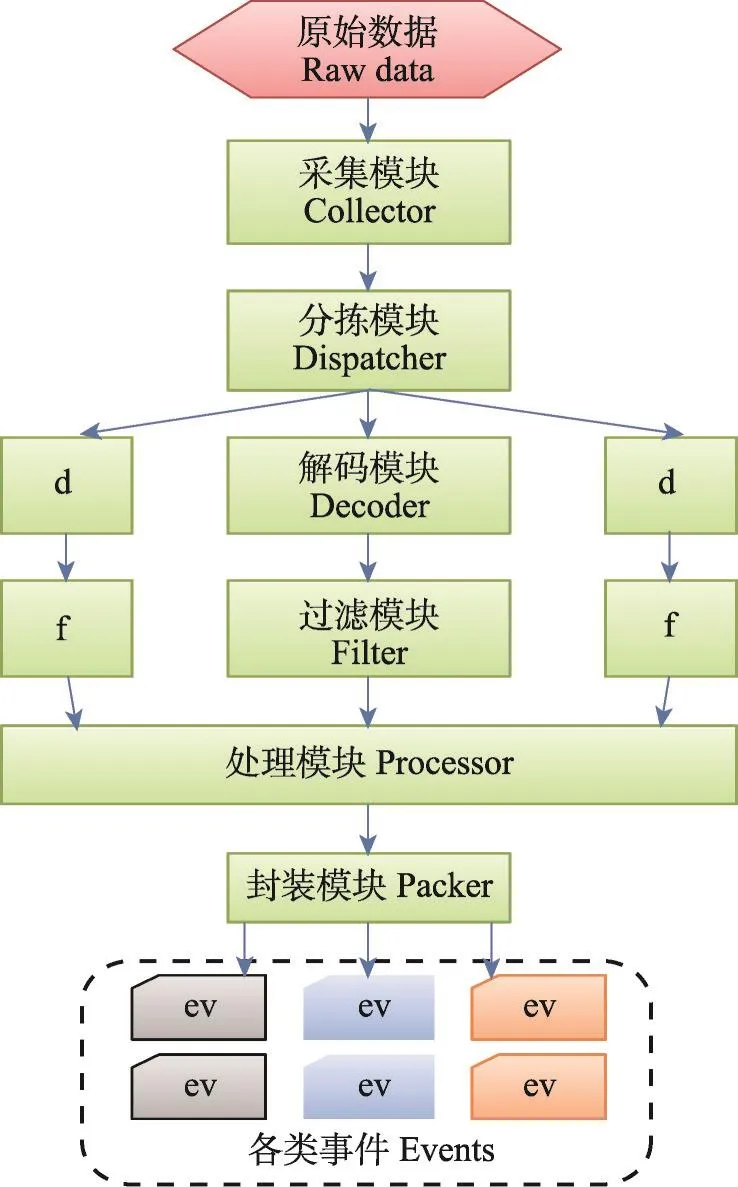
Fig.2 Workflow of modules in event factory图2 事件工厂模块工作流程图
根据原始日志格式的不同,事件工厂内存在多个工作车间,每个车间都包含两个模块的步骤,分别为解码模块和过滤模块。事件流系统需要收集多少种格式的日志,事件工厂就需要相应数量的车间用于处理相应日志格式。解码模块的主要工作就是根据车间对应的日志格式进行解码,将原始的一行数据分解为若干个字段,每个字段是一个(key,value)的值对,key代表字段标识,同时也表示了字段含义,value是字段值,也即内容信息。例如一个几乎必需存在的标识就是事件时间,基本上所有种类的日志记录都需要记录发生时间,但记录格式可能不同。而该值将在解码模块被分解出来并形成时间戳的统一格式。
过滤模块将根据需求对经由解码模块处理过的事件进行筛选过滤,因此部分不被相关人员和应用所关注的事件将在此处被丢弃。以Linux系统日志为例,系统日志车间的过滤模块与两个模式库进行交互,分别为日志模式库Pl和警报模式库Pa。日志模式库包含过往系统日志记录的所有日志模式,警报模式库则仅包含部分需要关注的日志模式(为日志模式库的子集),并且注明了关注原因。当系统日志事件e来到过滤模块时:
(1)判断e是否匹配于警报模式库Pa中的任意一种模式:
(1.1)若e与Pa成功匹配,则为其添加关注原因的字段并将其发往处理模块;
(1.2)若e没有匹配到警报模式,则进入步骤(2)。
(2)将e与日志模式库Pl中的日志模式进行匹配:
(2.1)若e仍未成功匹配Pl,则判断e为新日志模式,将被添加相关字段并发往处理模块;
(2.2)若e与Pl匹配成功,则e为环境普通事件,事件流系统将不再对其进行任何处理(即丢弃事件)。
通过了过滤模块的事件将来到处理模块,该模块用于多条事件的综合处理。处理模块存在的原因是:并非所有事件都独立成为一个需要关注的事件,例如用户密码输入错误的记录,当其单独存在时可能仅仅表明用户的偶然输入错误,但如果短时间内同一账户连续多次输错密码,则很可能代表一次需要警报的密码攻击。处理模块就是用来处理此类由多条事件组合而成的综合事件,它需要建立若干队列用于存储可能组成不同综合事件的单条事件记录,同时还需要周期性地执行清理工作,删除那些已经经过较长时间但仍未组成综合事件的单条记录。对于本身即构成需要发布的事件的单条记录和已经成型的综合事件,处理模块会将其发往封装模块。
封装模块会对事件进行最终处理,将被分为多个字段的事件重新打包成为一个完整的字符串,该字符串需符合环境事件流处理与分发系统所定义的事件工厂统一接口的格式。该接口为JSON格式的信息内容,分为两到三个层级:第一层级为事件公共报头,包含了事件发生时间和事件类型;第二层级为事件主体,其中的字段标识根据第一层级的事件类型而定。部分事件还有第三层级内容,通常为事件主体的关键内容的参数或详细属性值。下面为一个经过封装的事件内容格式的样例:

封装模块还实现了Kafka的生产者客户端功能,经过封装的事件将根据其类型发布到Kafka的相应主题之中。至此为一个事件经历的完整的事件工厂工作流程。
当一个订阅环境事件的应用接收到事件时,首先读取第一层级中的事件类型(type)字段,根据该字段的内容判断其第二层级存在哪些字段。以上面的事件内容为例,应用程序发现其type字段为用户操作(USER_OP)时,根据事件接口格式它就可以知道在该事件第二层级中会包含用户名、用户访问地址和该操作类型(op字段,此处该值代表“查询计算资源”)等字段,结合第一层级的时间字段,该应用即可得知用户usr1在某一时间执行了一次查询资源操作。若该应用需要进一步分析这次操作,则根据操作类型可以获知本次操作包含哪些操作参数字段,例如用户请求的CPU核数(8核)、目标计算应用(app4)等内容。通过累积该类型事件的记录,环境管理人员即可统计分析得出某段时间内用户对于资源的需求情况。
5 系统工作效果
国家高性能计算环境事件流处理与分发系统的主要目的是对环境中的事件数据进行采集和传输,同时进行一些基本的格式和内容处理。对于这种类型的系统,数据发送延时是一项关键指标。对于集群的各种事件消息,希望能尽快地发送到对此有需求的各种环境应用处。
因此初步实现了环境事件流处理与分发系统的各个模块基本功能,并将其部署到了国家高性能计算环境中进行效果测试。设置了一台虚拟机的日志服务器专门用于收集来自环境各部分的日志,并将事件流系统安装在该服务器上,对收集来的日志进行转换处理和分发,同时设计实现了一个简单的测试应用来订阅事件流系统所发布的所有事件,并计算接收到事件的时间与事件流系统采集到该事件时间之间的延时。
本实验主要设备日志服务器虚拟机的CPU为2 400 MHz的英特尔4核处理器,64位操作系统,内存总量为4 GB。由于其他设备与日志服务器的系统时间可能存在不一致的情况,统一以日志服务器的系统时间为准。本实验的主要目的为测试系统中事件工厂的事件处理速度,因此实验的结果仅包括事件工厂对事件的处理时间以及事件经由Apache Kafka发布到测试应用所花费的时间,而不包括网络传输时间以及不同设备间系统时间不一致所产生的误差。
以分钟为单位计算了该分钟内产生事件总数和事件平均延时,事件对象为环境中的系统日志,总共采取了约90 min的数据结果。图3为每分钟内事件平均延时,可以看到,环境事件流处理与分发系统对于系统日志的处理事件和发布时间均值大都在5 ms至10 ms之间波动,部分时刻会达到14 ms,但总体上不超过20 ms。在不考虑网络等其他不在可控范围之内的延迟的情况下,环境事件流系统对于单个事件的处理速度是比较快的,完全可以满足环境应用对于事件的时效性需求,并起到实时响应和处理的效果。
针对图3中出现的事件处理延时会不定期向上波动的问题,也观察了实验期间每分钟事件产生数量与该分钟内平均事件处理延时之间的关系。图4展示了实验期间系统日志事件的每分钟内事件数量。图5为每分钟内的事件数量和事件延时的对比结果。可以看到在实验期间,多数时候环境系统日志平均每分钟产生的事件数量在约75到140条,少数时候会增加到150条,最多时接近250条。虽然结果有一些偏差,但总体上有一个较为清晰的线性趋势,即当单位时间内所产生的事件数量增加时,事件流系统对于单条数据的平均延时会相应增加。然而由于事件处理延时在整体上表现在一个相当低的范围,即毫秒级的标准,因此预测在环境事件流量继续增加时,事件流系统对于环境事件的处理延时可能会提升一个数量级,但仍然处于一个较为迅速的范围内,可以满足环境应用对事件的时效性需求。此外环境事件流量突然增大这种情况属于偶发情况,在绝大多数时间内,环境会处于一种正常平稳运行的状态,对于事件处理的速度也会维持在高标准。

Fig.3 Average delay for event process in each minute图3 每分钟内事件处理过程平均延时
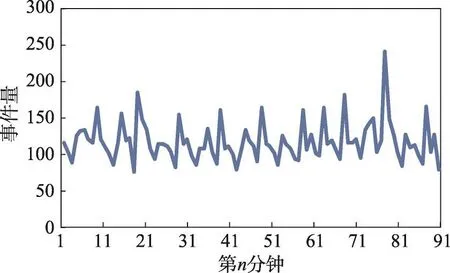
Fig.4 Event throughput in each minute图4 每分钟内事件数量
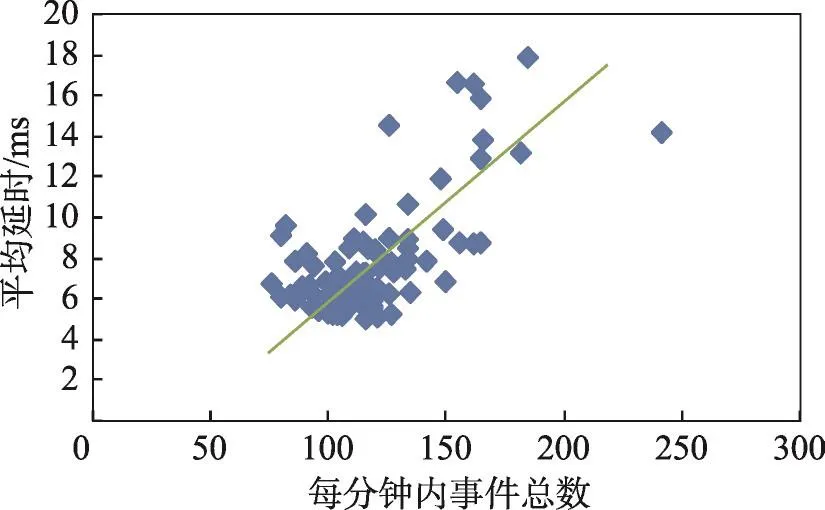
Fig.5 Average delay against event throughput图5 事件流量与事件平均延时的关系
6 相关工作
在过往的研究中设计实现了网格环境日志分析框架LARGE[4]。LARGE是部署在中科院超级计算环境中的日志分析框架,其主要工作内容如下:
(1)采集环境中的日志信息实现集中存储;
(2)对日志进行解码重构和统计分析,得到初步结果;
(3)通过人工整理形成对环境有帮助的反馈。
为了实现对于日志的监控规则的自定义,提出了日志模式提炼算法[8]对过往日志进行总结并获得一个数量较少的日志模式集合,并以日志模式为单位进行定义日志规则的工作。
本文介绍的环境事件流处理与分发系统是对LARGE系统研究开发工作的延续。在研究过程中出现了更多需求和相关使用场景,因此针对环境事件采集的环节进行了更加详细的流程设计和定义扩展,使之适用于更多的环境应用,从而形成了事件流系统。环境事件流处理与分发系统的主要工作内容如下:
(1)采集环境中的日志原始数据;
(2)进行初步解码过滤和重组,封装成标准格式;
(3)对事件分类,发送到相关应用处。
相对LARGE系统,事件流系统只进行基础的日志过滤和格式处理,而仍然保留原始信息的完整内涵,这些信息将由包括LARGE处理分析模块在内的其他环境应用进行更具体更有针对性的解读和使用。在事件流系统中,日志模式仍然起到了重要作用,事件流系统通过日志模式的比对来实现日志事件的过滤工作。
目前对于分布式系统中关于监控和日志处理的研究工作主要集中在对系统状态的监控和对日志数据的传输方面。Ganglia[9]是UC Berkeley主导开发的一个开源项目,目标是实现对系统的CPU、内存、磁盘使用率、网络等状态的监控。Nagios[10]也是一种系统监控工具,可以使用插件实现通过网页展示系统状态的功能。在中科院超级计算环境中已经部署配置了基于Nagios的监控系统[11],它与LARGE共同承担了对环境的监控和分析的工作。
Scribe(https://github.com/facebookarchive/scribe/)是Facebook的日志收集系统,可以将日志从各个源设备传输到一台集中存储设备上。相似的系统还有由Cloudera开发的Flume[12],它将传输流程分为source、channel和sink三部分,每部分都有多种选择。这些数据传输工具都可以被用于实现LARGE的日志收集模块。Chukwa(http://chukwa.apache.org/)是 Hadoop项目中开源的分布式系统数据收集和分析工具,包含了数据收集、重组、分析和展示的完整流程。由于系统情况的差别,Chukwa不能直接应用于超级计算环境,但仍可以作为一个有益的参考。
在环境事件流处理与分发系统中使用了Logstash作为事件传输平台的一部分。Logstash是Elastic公司开发的数据采集软件,它与Elastic公司开发的其他软件具备更好的结合度。近年来对于Elastic公司开发的ELK组合(ElasticSearch、Logstash、Kibana)的研究和使用呈现显著增长趋势[13-15],ELK可以作为一个实时的数据分析框架,并且对日志流处理有一定优势。不过ELK框架提供的分析功能相对简单,需要设计其他辅助分析程序来满足特定系统或环境对分析的需求。
Apache Eagle是Apache项目推出的一款开源的分布式系统实时安全监控分析方案(http://eagle.apache.org/),主要针对 Apache Hadoop和 Apache Spark等大数据平台。Eagle实现了关于系统行为、yarn应用、jmx数据、系统服务日志等数据的分析功能,并且提供了关于安全、性能等方面的警报引擎。Eagle的工作流程主要分为三步:首先整合来自目标大数据平台的相关日志和数据;然后将实时的数据流进行标准化等处理并在警报引擎中进行评估;最终生成警报、趋势报告等输出结果。可以看到Eagle与本文介绍的环境事件流处理与分发系统具有一定的相似性,而且Eagle系统中同样使用了Kafka作为数据传输的解决方案。相比而言,Eagle的主要分析对象是Apache项目的各种系统、程序、服务和数据,并且提供了相应的警报功能,是一个综合性的处理工具;而环境事件流系统的主要设计目标是解决国家高性能计算环境中的各类事件信息和相关数据的传输问题,并实现了初步的内容解析和分类,是整个环境监控分析的一个关键模块。对于环境数据的实际使用等方面的功能则交由订阅事件的相关应用来实现,包括网格环境日志分析框架LARGE、环境事件展示平台等。
7 总结与展望
本文介绍了关于国家高性能计算环境事件流处理与分发系统的设计。事件流系统的主要目标是通过专用的系统来收集国家高性能计算环境中产生的各种事件信息,并按照事件内容分类发送给对事件有需求的环境应用处。采用Apache Kafka与Logstash的组合作为系统基本的消息收集和分发平台,并着重设计实现了事件工厂用于对各种事件进行梳理和封装。事件工厂包含了六种模块,通过对事件内容的解析和过滤选取含有重要信息的事件,并通过综合处理整合多条事件记录形成综合事件,最终封装成符合事件工厂统一格式的事件消息,再通过分发平台按照其事件类型分发给订阅相关类型的环境应用。将环境事件流处理与分发系统部署到环境服务器中并进行了运行测试,结果证明系统在事件处理传输方面具有较低的延时,可以满足环境相关应用对事件获取的需求。
接下来将进一步扩展事件工厂对于环境各种事件格式的解析处理功能,以应对更多的环境事件类型。还将研究多样的针对事件的环境应用,包括多维度日志分析和监控、环境用户行为特征分析、环境事件流可视化展示界面等,通过多样的方式最大化利用事件流系统,为国家高性能计算环境的稳定运行和维护工作提供更多更好的支持。
