融合协同过滤与上下文信息的Bandits推荐算法*
2019-04-18王宇琛王宝亮侯永宏
王宇琛,王宝亮,侯永宏
天津大学 电气自动化与信息工程学院,天津 300072
1 引言
随着互联网的飞速发展,每天都有海量信息不断产生和传播,进而出现信息过载问题。因此在互联网在线服务中,推荐系统应运而生,并且因其能够有效过滤信息,同时为用户进行精确的个性化服务而成为研究热点。尤其在电子商务、新闻、音频、视频、广告投放等领域,起到越来越关键的作用。
传统的推荐算法如协同过滤,基于内容的过滤、混合推荐算法等,都非常依赖用户的历史行为信息[1]。但在现实的推荐场景中,用户对商品的行为信息矩阵非常稀疏,并且每天都会产生新的用户和商品,这将导致传统的推荐算法无法为部分用户进行准确的个性化推荐,这就是所谓的数据稀疏性和冷启动问题。针对这些问题,往往希望通过获取额外的信息对新用户、新商品进行模型构建,进而完成个性化推荐[2],但事实上额外信息并不易获取,并且用户信息和商品信息是随时间动态变化的。
针对以上问题,适应稀疏、缺失的信息成为推荐算法的基本要求。在强化学习领域,多臂赌博机算法(Bandits)是解决冷启动与动态推荐的有效方法,又名探索-开发策略(exploration-exploitation method)。探索(exploration)是指通过为用户推荐新的商品,希望找到用户反馈最佳的全局最优商品,但是过度探索将会消耗大量的推荐机会,导致在有限的推荐次数内无法获得当前最优推荐。开发(exploitation)是指基于当前用户反馈信息,为用户推荐当前已知商品中能够得到用户最优反馈的商品,但是过度开发将会导致陷入局部最优解,无法找到所有商品中用户最感兴趣的商品。因此,只有合理平衡探索与开发,才能得到最佳推荐结果。
传统的多臂赌博机算法没有充分利用用户对商品的反馈信息,并且在推荐过程中没有引入特征的概念。近年来结合上下文的多臂赌博机受到高度关注,应对冷启动问题有不错的效果[3]。但是基本的结合上下文的多臂赌博机没有考虑到协同信息的重要性,在很多推荐场景中,具有相似兴趣的用户对同一个物品的反馈可能是一样的,因此在给目标用户推荐商品时,参考邻居用户的选择倾向,可以得到更好的推荐效果[4]。因此,文献[5]提出为目标用户推荐商品时,根据用户偏好将用户聚类,把目标用户所在类簇的平均特征视为目标用户特征,并基于多臂赌博机算法预测某一商品的可能收益,再实时观察真实反馈更新目标用户特征。但是聚类后同一类簇内的用户往往非常多,用整体特征代替类簇内的某一用户特征,虽然引入了用户的协同作用,但是会导致用户本身的特征起到的作用非常小,从而使得计算结果与用户真实偏好相差很大,而且同一类簇内所有用户共享一个特征,会牺牲推荐的个性化。
本文基于以上研究背景,提出了能有效解决用户冷启动的协同过滤线性多臂赌博机算法(collaborative filtering context linear Bandits,COLINBA),该算法与之前相关算法相比,在结合上下文的多臂赌博机算法基础上,引入了更加精细的协同效果。当为目标用户推荐商品时由用户与其邻居用户共同决定,并且通过邻居用户相似度权重因子控制邻居用户对推荐的贡献程度,从而保证目标用户自身特征起主导作用,且引入了协同效果,优化推荐性能。此外,相比文献[6]中提出的基于矩阵分解(matrix factorization,MF)提取特征的方法,本文将自然语言处理中的潜在狄利克雷分布(latent Dirichlet allocation,LDA)主题模型用于推荐系统中的商品特征提取,从而避免了现实数据中商品用户矩阵极其稀疏导致矩阵分解不佳的问题。并且矩阵分解只能利用评分信息或0-1反馈信息,而无法利用含有更大信息量的文本评价信息,引入LDA主题模型恰好可解决该问题,并且从模型原理角度论证了该方法可行性。最后在实验中,运用LDA模型从真实数据集提取商品潜在特征,并基于COLINBA算法用商品特征不断拟合用户特征,从累计误差和点击率的角度与其他算法对比推荐结果,验证了本文算法的有效性。
本文剩余部分的结构如下:第2章介绍相关工作;第3章介绍本文提出的方法,包括本文算法基于的推荐模型,引入LDA主题模型提取商品潜在特征的原理和过程,以及本文提出的COLINBA算法;第4章介绍实验结果和对比分析;第5章对本文进行总结。
2 相关工作
近几年,多臂赌博机算法因为能够有效应对冷启动问题,提升推荐准确性,在推荐算法领域受到越来越多的关注。
将多臂赌博机运用于推荐,其基本思想是将n件商品视为n个臂的多臂赌博机,摇臂j对应商品j,推荐出最优商品等价于找到收益最大的摇臂。在第t轮推荐中,向用户i推荐商品j,并且得到该用户的反馈值。推荐系统的目的是在T轮推荐结束时,为每位用户推荐的累积误差最小,但对于新用户而言无法预知商品的真实收益,推荐将会陷入探索开发困境,即在有限的推荐次数内,根据当前对每件商品的预估收益,开发可获得最大收益的商品;或者尝试探索新商品,进而找到全部商品中收益更大的商品。
ε-greedy算法是一种基本的多臂赌博机算法。该算法在第t轮推荐中,以1-ε的概率选择当前已知可获得最大反馈的商品,以ε的概率随机选择一件新商品,最终根据用户真实反馈更新被选中商品的期望与方差。ε-greedy算法将探索与开发分开考虑,每一次推荐都根据ε随机选择探索或开发,该算法的优点是复杂度低,但预测准确度有待提升。
与简单的随机探索策略不同,另一类算法称为置信区间算法,置信区间算法假设商品的实际收益μj与期望收益有很高的概率在置信区间ct,j内,公式如下:


由此可知,置信区间是与迭代次数有关的函数,当某商品被选择次数较少时其置信区间相对较大,算法倾向于选择该商品,相当于探索;当商品被选择多次,其置信区间不断减小,算法会倾向于选择期望反馈大的商品,相当于开发。随着不断地迭代,期望反馈将会越来越精确,置信区间ct,j越来越小,最终期望反馈将会与真实反馈μj相等。
在置信区间算法的基础上,文献[3]提出了LinUCB(linear upper confidence bound)算法,首次为传统多臂赌博机算法引入特征的概念,认为用户特征和用户选择的商品的特征之间存在线性关系,并且用置信区间衡量探索的收益可靠性,该算法成功运用到雅虎新闻的个性化推荐系统当中,能够在较少的迭代次数下快速拟合到新用户的特征。基于引入特征的多臂赌博机思想,文献[6]提出一种融合矩阵分解的MFLinUCB(linear upper confidence bound with matrix factorization)算法,该算法根据用户对商品真实评价与预测评价的误差,使用矩阵分解算法更新用户和商品特征,再对新的特征使用多臂赌博机策略进行商品推荐,实验结果表明在收敛速度和准确率等方面比LinUCB更好。
此外,用户的社交关系中蕴含着丰富的信息,有助于提升推荐准确率[7]。文献[5]提出了一种LinUCB算法的改进算法CLUB(cluster of Bandits),该算法认为用户的相似性能够体现在特征上,因此可以依据用户特征对用户进行聚类,并且用类簇内用户平均特征代表类内所有用户,从而在为目标用户推荐时引入用户协同,并且在每一轮推荐后根据目标用户反馈对该用户特征以及用户类簇进行更新。文献[8]在此基础上提出同时对用户与商品进行聚类的COFIBA(collaborative filtering Bandits)算法。文献[9]提出了一种时间因子,认为用户反馈与用户特征会随着时间而变化。以上算法都是对传统多臂赌博机算法的改进算法。
根据上述的算法介绍可知,针对冷启动问题,过去的算法基本都是先随机初始化特征,或简单地提取用户和商品特征,将其作为算法的输入,并采用Bandits算法思想进行预测,但是没有合理利用上下文信息和相似用户的协同作用。为此本文提出了一种结合上下文的用户协同多臂赌博机推荐算法,和一种更加适用于推荐领域的基于文本评价信息提取特征的方法,可以很好地解决特征提取和特征更新问题,并在用户冷启动中更快地拟合用户特征。
3 本文提出的方法
在这一章中,首先介绍了本文算法适用的推荐场景,以及基于的推荐系统模型和预备知识;然后提出了基于LDA生成模型提取商品潜在特征的方法原理和过程;最后介绍本文提出的COLINBA算法。
3.1 本文模型和预备知识
本文模型和算法在仅利用商品历史文本评价的场景下,解决用户冷启动问题。由于被推荐对象为新用户,因此用户真实特征未知。对新用户特征进行统一初始化后,希望在尽可能少的推荐次数内,根据商品特征和新用户对多轮推荐商品的反馈,即点击与否,不断修正用户特征,使得推荐越来越准确,进而解决用户冷启动问题。
在每一轮推荐过程中t=1,2,…,T,针对目标用户it∈U,系统会为之生成一份含有c件商品的候选商品集,商品集中商品对应的潜在特征为Cit={xt,1,xt,2,…,xt,c}⊆ℝd,特征采用LDA生成模型提取,具体方法会在下一节中详细介绍,商品特征维数与用户特征维数都为d。在本文模型中,认为用户特征与商品特征之间存在线性关系,即用户的特征与该用户感兴趣的商品特征之间有较高相似度。系统预测出用户最感兴趣的商品推荐给用户,并获得用户的反馈结果。在第t轮推荐中,一方面,由于用户特征随着每一轮的推荐和反馈不断更新,因此之前t-1轮的推荐商品以及用户每次的反馈都会影响当前推荐。另一方面,在为目标用户推荐时,引入了邻居用户协同,提升推荐性能。利用特征向量相似度计算方法,总是可以找到与被推荐用户的特征最为相近的几位用户,称之为邻居用户。当用户特征准确时,目标用户与邻居用户的行为偏好最为相近。但由于本文旨在解决用户冷启动问题,即在第一次推荐或推荐次数较少时,拟合到的用户特征尚不准确,因此根据特征相似性计算到的邻居用户与被推荐用户的行为偏好偏差较大,对推荐帮助不大,但随着推荐次数增加,邻居用户协同的作用会越来越显著。用户特征更新细节以及邻居用户协同过程会在算法部分详细介绍。
系统为用户推荐之后,用户会对推荐结果进行反馈,这代表推荐的成功与否。在经典的结合上下文的多臂赌博机算法中[3,10],用户的偏好用用户特征向量ui表示的,进而用户i的反馈值可以由用户特征ui与商品的潜在特征x计算出:


此外,累计误差也常用于验证算法性能。具体而言,在每一轮推荐中,系统都会计算推荐时预测的用户反馈与用户真实反馈之间的差值,定义第t轮学习过程中的误差rt为:

可见,误差越小,代表算法的推荐结果更加接近用户的真实选择。本文同样采用基于点击率的累计反馈误差(cumulative regret,CumReg)衡量预测反馈与真实反馈之间的误差,表达式为:

其中,j为最终推荐给用户i的商品,为预测的反馈结果,rt为用户真实的反馈结果。在本文中,将运用以上方法验证本文算法在解决推荐问题的有效性。
3.2 提取商品潜在特征
在本节中,提出了运用LDA主题模型从用户评价信息中提取商品潜在特征的方法。
文献[6]提出运用矩阵分解的方法从商品用户矩阵中提取特征并用于多臂赌博机算法,实验证明相比LinUCB在收敛速度和准确率方面有所提升。但基于矩阵分解提取特征要求矩阵不能过分稀疏,而在现实场景中,某一用户反馈过的商品相比于商品总数是极其稀少的,因此该方法需要剔除掉大量反馈较少的商品和不活跃用户,从而降低矩阵稀疏性对矩阵分解的影响,但会导致在推荐时商品选择多样性降低。另一方面,矩阵分解只能利用评分信息或0-1反馈信息,而无法利用含有更大信息量的文本评价信息。采用本文提出的基于LDA模型提取特征的方法,只需去除少量被评论极少的商品,就可利用评价文本训练得到商品特征,极大地提升了信息利用率,并且保留了更多的候选商品。
LDA是一种非监督概率生成模型,可以根据主题生成文档,也可以用于提取文档主题。LDA模型假设用户在完成一篇文章时,首先会确定几个主题,进而从主题对应的词语集中以一定概率选择词语。重复这两步骤就可生成一篇文章。LDA模型最初由Blei等人在文献[11]中提出,并应用到许多领域,包括邮件分类[12]、社交网络[13]、文本切割[14]等。近些年,LDA还被用于推荐系统中的文本推荐[15-16]。
本文认为提取文本主题与提取商品潜在特征存在对应关系,即文章与商品文字评价信息对应,文章主题与商品特征对应,由此提出运用LDA从用户评语中提取商品的潜在语义,即商品的潜在特征,因此需要计算LDA模型中的文章-主题多项式概率分布Θ,主题-单词多项式概率分布Φ。为了便于表述,在下文中统一用文档表示商品的文字评价信息。由此可以将每件商品在潜在特征空间用文档-主题概率分布视为商品特征向量。吉布斯抽样[17]是一种能够根据语料库有效估计LDA生成模型概率分布Θ和Φ的方法。本文采用吉布斯抽样估计LDA模型的概率分布,通过多轮迭代,对在文档d中的每个单词w,根据条件概率分布P(w|d)为单词抽样出特征f,如下所示,直到LDA模型参数收敛。
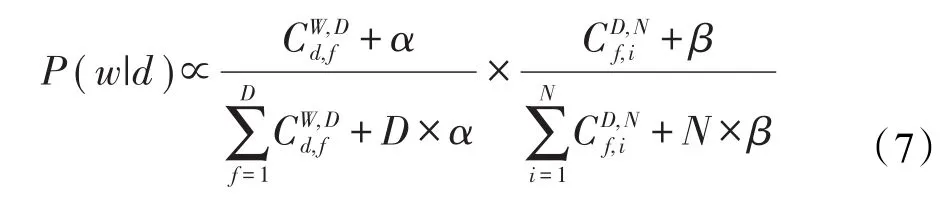
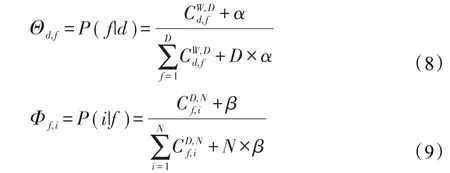
由上述分析可知,概率分布Θ可等价于商品的文本评价的潜在主题分布,即商品特征向量。在为新用户进行多轮推荐的过程中,根据用户对每次被推荐商品的反馈,即点击与否,可用商品特征不断修正新用户的初始特征,进而使用户预测特征逐渐拟合用户真实特征。
3.3 本文算法
本节将介绍本文提出的算法COLINBA的具体内容。该算法基于强化学习中的多臂赌博机思想,将商品视为不同的臂,为用户推荐时在探索与开发之间权衡。与传统的多臂赌博机算法不同,COLINBA引入了邻居用户的协同作用,并基于用户反馈不断修正用户特征。
为了便于描述该算法,本节重新定义部分模型中的参数。与文献[3,8,18]相同,COLINBA采用预测特征向量ωi,t代表未知的用户真实特征向量ui。在第t轮推荐中,当为用户it∈U进行推荐时,系统可以得到其预测特征向量ωi,t,同时为该用户随机生成候选商品池Ci,t={xt,1,xt,2,…,xt,c}⊆I,商品池内商品数目为c,商品特征是通过LDA模型从商品评价数据集中提取出的,特征维度为d。推荐系统将根据本文提出的算法,为用户从候选商品集Ci,t中计算出用户最可能点击的商品并推荐,进而得到用户反馈值ri,t。向量ωi,t-1将根据反馈信息更新,算法的目标就是通过多轮推荐,不断将用户i的预测特征向量ωi,t逼近用户真实特征向量ui。具体而言,与文献[3]中提出的LinUCB算法相同,用户特征向量ωi,t-1由逆矩阵和向量bi,t-1共同决定。由于COLINBA算法主要针对用户冷启动问题,因此矩阵Mi,t初始化为d维单位矩阵,向量bi,t的初始化为d维零向量。Mi,t矩阵同时决定着预测特征向量ωi,t-1趋近于用户实际向量ui的置信区间上限CBjˆt,t(xt,k)的取值。
本文在为用户从候选商品池中选择商品推荐时,引入用户协同的思想,进而加快算法的收敛速度,提升推荐的准确度。具体而言,在第t轮推荐中为了能够从商品池Ci,t中为目标用户推荐出最佳商品it,本文通过余弦相似度(cosine similarity measure method,COS)[19]计算出目标用户it的h位最邻近用户Ni,t={ui,1,ui,2,…,ui,h},由邻居用户与目标用户共同构造出协同偏置向量,取代传统算法中的向量ωi,t-1,向量代表目标用户it与其h位最邻近用户的加权平均偏好,这意味着COLINBA的推荐结果由目标用户与其h位邻居用户Ni,t共同决定。但与文献[18]中仅简单叠加用户参数的方法不同,COLINBA算法中邻居用户的影响程度由邻居用户与目标用户的相似度权重系数qi,j决定,该系数为用户it与邻居用户ui,j之间的余弦相似度:
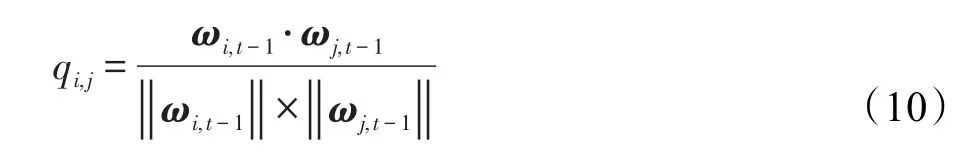
相似度权重系数qi,j的取值在-1到1之间,qi,j的取值越靠近1,则邻居用户与目标用户越相近,其对推荐结果的影响越大,qi,j的取值越靠近-1,则效果相反。与其他算法相似,向量同样由逆相关矩阵与向量决定:


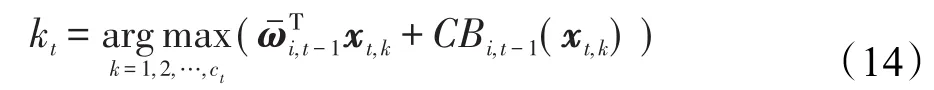
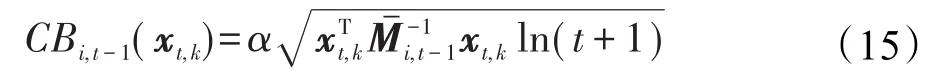
其中,参数α决定着算法在推荐中偏重于探索的程度。
在每一轮推荐完成后,系统将得到用户it的反馈值ri,t,向量ωi,t-1基于反馈信息更新为ωi,t。本文算法基于为用户推荐的商品特征更新Mi,t-1、bi,t-1为Mi,t、bi,t,学习率为反馈值ri,t。用户反馈形式采用用户点击反馈,即当用户点击了推荐的商品,则ri,t=1,反之ri,t=0。在更新用户参数时不考虑协同的影响,即只对本轮推荐的目标用户进行更新,其他用户不参与更新。
算法时间复杂度方面,基于LDA生成模型提取商品潜在特征是提前在离线条件下完成的,COLINBA算法在时间方面的消耗主要分为两部分,包括计算用户之间的相似矩阵,以及为当前用户推荐时计算候选商品池中所有商品的分数。其中用户相似矩阵在实际中通常采取离线计算的方式并周期性更新,而非实时更新。因此,在线推荐过程中只需实时计算用户协同特征向量i,t-1和候选池中商品分数即可。其中,计算用户协同特征向量i,t-1的时间复杂度为O(dj),d表示用户和商品特征维数,j表示用户邻居数,计算商品分数的时间复杂度为O(dc),c表示商品
其中,与传统多臂赌博机算法相同,CBi,t-1(xt,k)为向量近似于用户真实向量ui的置信区间上界。池中的商品数。因此本文算法为一位用户推荐一次的时间复杂度为O(d(j+c)),即时间复杂度与特征维数、邻居数与商品池中商品数的和成正比,适合用于大规模数据集的推荐。

4 实验部分
在本章中,将采用真实的数据集Delicious和Last.fm模拟在线推荐过程,基于LDA生成模型提取商品的潜在特征,对本文提出的COLINBA算法与作为对比的 LinUCB、MFLinUCB、DynUCB(dynamic clustering of contextual multi-armed Bandits)和COFIBA等算法进行实验评估。采用的评价指标包括点击率CTR和累计误差CumReg,实验表明本文算法较其他算法有一定提升。
4.1 数据集
Delicious数据集采集自社交书签网站Delicious,其包含1 861位用户和69 226件商品(URL),以及用户对这些URL所打的文本评价标签53 388种。本文基于被打标签的URL来生成用户反馈信息:如果某一用户对某一URL打过标签,则认为用户对该URL的反馈为1,否则为0。Last.fm数据集采集自音乐流服务Last.fm,其包含1 892位用户,17 632件商品(歌手),以及11 946种文本评价标签。采用同样的方式定义某用户对某商品的反馈值。
Delicious和Last.fm数据集中存在部分商品仅有极少用户对其打过标签,将这些商品的标签集合视为文章则意味着文章内文本量极少,基于LDA主题模型从这样的文章中提取到的主题向量将会存在大量0值和非常接近于0的数值,从而无法准确表征商品,在后续推荐过程中会对推荐准确率和用户特征迭代产生误导。因此,针对Delicious数据集,首先对商品按照评价数进行排序,剔除了评价数较少的部分噪声商品,保留了热度较高的3万件商品,然后基于新构建的数据集,对用户活跃度进行排序,保留较为活跃的1 000名用户。对于Last.fm数据集,同样保留评价数较多的1万件商品和较为活跃的1 000名用户。
4.2 离线模拟在线推荐
在线推荐场景中,根据推荐算法可预测用户点击概率最大的前k件商品,展示给用户,根据用户真实的点击反馈,更新模型和相应参数并再次推荐,使得推荐准确性不断提升。
本文基于Delicious和Last.fm数据集,采用离线模拟在线推荐的方法,仿真本文算法的推荐效果。具体而言,数据集中的信息为用户对商品的评价信息,进而可理解为用户对其评价过的商品是有过点击行为的。本文算法希望解决用户冷启动问题,因此在实验中用户都为新用户,即在预测推荐商品时,假设用户在数据集中的点击行为是未知的。根据本文算法预测得到用户可能点击的商品后,再参照该用户在数据集中的真实点击记录,若预测商品恰为用户点击过的商品,则认为用户反馈为1,推荐成功,反之用户反馈为0,推荐失败,即用数据集中的用户点击记录模拟用户对推荐商品的反馈行为。具体为每一位用户推荐时,为更接近真实应用场景,并未从所有商品中选择,而是先构建一个含有20件商品的商品集,其中一件从该用户真实点击过的商品中随机生成,其他19件为用户未点击过的负例商品。若根据算法计算得分最高的商品恰为正例,则推荐成功;若预测结果为负例,则代表用户不会点击,推荐失败。根据用户反馈结果更新模型和相应参数,并再次推荐。
4.3 构建商品潜在特征
本文实验在提取商品特征时,同样基于Delicious和Last.fm数据集,即利用商品的历史评价信息提取商品特征。在现实场景中仅需收集足够多老用户对某商品的文本评价,就可基于LDA主题模型生成该商品的潜在特征,并且评价越多,特征的表征准确性越高。
首先对数据集内标签单词进行清洗,将每一个商品的所有标签单词装入对应的文档中,从而构建出每个商品的标签单词集。然后将其输入LDA模型计算商品-潜在主题概率分布和单词主题概率分布。具体而言,首先要设定LDA生成模型的狄利克雷概率分布参数α和β,以及主题数D。在文献[17]中,提出了参数的最优设定方法,β=0.1和α=50/D,本文采用该标准计算模型参数。可见,关键要选取合理的主题数D,文献[11]提出了具有良好适应性的Perplexity指标,可用来评价主题数对模型的影响:
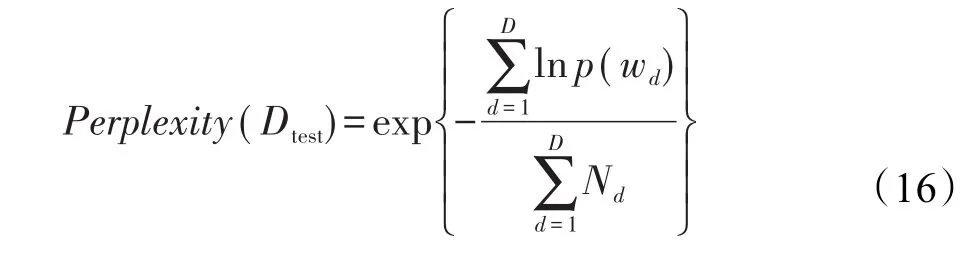
该指标的值越小代表模型性能越好。因此,通过改变主题数,即商品特征的维度,观察Perplexity的趋势,在最低点时即为最佳值。得到图1性能曲线。
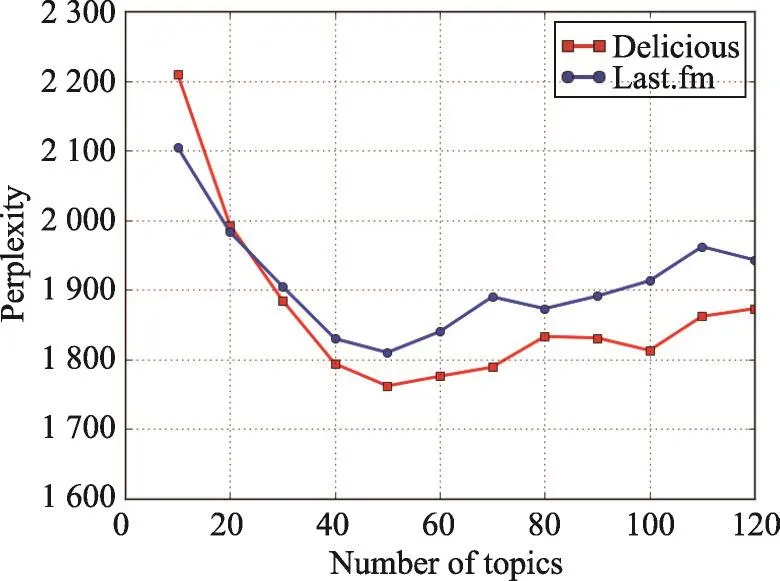
Fig.1 Perplexity of LDA model on different number of topics图1 LDA模型的困惑度随主题数的变化
结果显示当模型主题数为50时,Perplexity取得最小值,模型性能达到最优。因此本文设定潜在主题数为50,即特征维度为50。
常用的商品特征提取方法还包括矩阵分解,如之前所述,该方法仅利用了用户对商品的评分或0-1反馈,而引入自然语言处理中的主题模型可以挖掘商品评价信息进而构建商品潜在特征,常用的方法有TF-IDF(term frequency-inverse document frequency)、LDA模型。表1对比了通过以上三种方法提取商品特征后,基于本文COFIBA算法推荐并迭代10 000次时的CTR,其中LDA_0.5代表仅利用50%的评价文本训练商品特征。实验结果表明,在两数据集上,基于文本主题提取方法TF-IDF、LDA能得到更高的点击率,因为其利用了信息量更大的商品评价文本,能够更加准确地表征商品特征,其中LDA的效果更佳。此外,当仅用一半的文本训练LDA模型时,CTR会急剧下降,因此在实际运用中,商品的评价信息越丰富,提取到的特征表征效果越好。

Table 1 CTR based on different feature extraction methods表1 基于不同特征提取方法的点击率
4.4 评价指标
本文采用文献[3]中的评价方法,使用离线数据集模拟在线推荐过程,不划分训练集和验证集,在整个数据集上计算CTR和CumReg随迭代增加的变化情况,衡量算法性能。公式如下所述:
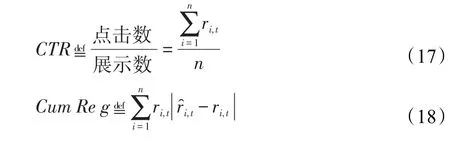
其中,ri,t为用户i的真实反馈,为预测反馈值,n为用户总数。CTR表示每一轮推荐的商品得到用户反馈的次数占用户总数n的比值,最大值为1。CumReg表示每一轮推荐n位用户预测反馈与真实反馈的累计误差。
如4.2节所述,当每一次为用户推荐时,需要随机生成候选商品池Ci,t={xt,1,xt,2,…,xt,c}⊆I,商品数c=20,其中第一件商品xt,1为随机抽取一件原数据集中用户it真实点击的商品,其余19件从该用户未点击的商品中随机抽取。如果算法为用户推荐的商品恰为该用户点击过的商品,则认为推荐成功,用户反馈值ri,t=1,否则ri,t=0,从而模拟在线推荐和反馈的过程。
4.5 对比算法介绍
本文提出的算法为引入协同过滤的多臂赌博机算法,因此对比算法分为两大类:第一类为未引入协同的LinUCB算法[3]和MFLinUCB算法[6],LinUCB默认用户和商品的潜在特征与最终预测反馈值之间存在线性关系,进而提出了结合上下文语境的多臂赌博机算法,MFLinUCB在LinUCB的基础上融入矩阵分解算法,提出使用矩阵分解算法更新用户的特征。第二类为基于聚类方法进而引入邻居用户协同作用的多臂赌博机算法,DynUCB[18]和 COFIBA[8],DynUCB基于传统的k-means算法进行动态聚类。COFIBA则采用在用户和商品两方面同时动态聚类的方法引入协同的效果。
4.6 结果分析
为便于比较不同算法的性能,在计算累积误差Cum Re g时以随机推荐为基础,计算各种算法测试结果与随机推荐测试结果的比值,作为相对测试结果,下文中都以相对测试结果进行分析。并且所有算法用到的特征采用相同维度,都采用本文提出的LDA特征提取方法计算商品特征。
首先以CTR作为指标,衡量COLINBA算法的参数α的取值,以及邻居用户数m对推荐结果的影响。分别从Delicious数据集中的1 861名用户和Last.fm数据集中的1 892名用户中随机选择300名用户作为测试推荐对象,测试在基于两数据集迭代10 000次的条件下参数α对CTR的影响,以及邻居用户数m对CTR的影响。测试结果如图2、图3所示。
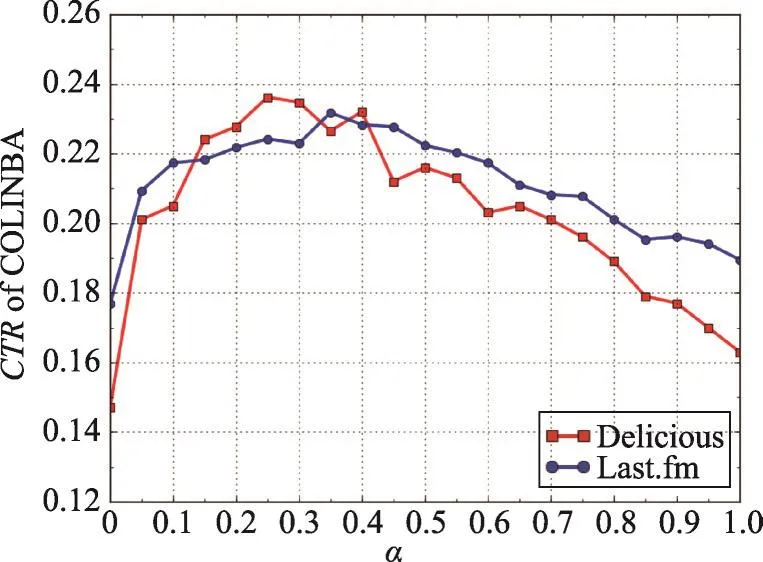
Fig.2 CTRof COLINBA on different values ofα图2 α取不同值时COLINBA算法的CTR
根据图2可知,参数α的取值变化会对推荐结果产生影响,且在不同数据集中的影响程度不同。具体而言,Delicious数据集的α最优值为0.25;Last.fm数据集的α最优值为0.35。在后续对比实验中,对于COLINBA算法均采用上述α最优值。
图3中,柱状图表示COLINBA算法中邻居用户数m的取值变化对点击率的影响,直线A代表邻居用户的权重因子设置为0的情况,即不采用邻居用户协同仅根据目标用户特征推荐时的用户点击率,直线B为50位邻居用户的权重因子全部设置为1,即用目标用户与50位邻居用户的平均特征代替目标用户特征时的点击率,可等效为将相似用户聚类后的类簇整体特征代替用户特征的推荐结果。可见,COLINBA中引入带有邻居相似权重因子的邻居协同能够提高点击率,并且邻居用户个数也会影响推荐准确率,其中,当邻居数为20时,用户的点击率最高。并且继续增加邻居数时,点击率开始小幅度下降,这是因为随着邻居数的增多,大量与目标用户相似度低的用户也被当作了邻居用户参与协同过滤,从而会对推荐结果产生错误的影响,但由于引入了相似度权重因子,从而控制这些用户的影响程度较小,当邻居用户增多时点击率下降比较缓慢。此外,不采用协同过滤思想方法推荐结果较差,直接将邻居用户特征向量相加的方法的推荐结果更差,因为后者在为目标用户推荐时,大量不相关的用户起到了很大的作用,从而导致推荐结果不是用户真正感兴趣的商品。
在Delicious和Last.fm数据集上,以相对累计误差CumReg作为评价指标,各种算法的结果如图4所示。
根据图4可知,各算法性能均优于随机推荐。在Delicious数据集上,LinUCB收敛速度最快,但其收敛后累积误差最大。DynUCB算法和MFLinUCB算法性能有所提升。COLINBA和COFIBA的性能最好,COLINBA算法收敛后的累计误差最小,为0.80,但其收敛速度比COFIBA稍慢。在Last.fm数据集上,LinUCB、DynUCB和MFLinUCB收敛速度较快,但是累积误差最大,在迭代20 000次时收敛累计误差为0.81、0.79和0.78。COLINBA和COFIBA性能最好,在迭代到25 000次时累计误差达到最小值0.74和0.76。
以相对累积误差作为评测指标时,在两个数据集上测试结果都显示本文提出的COLINBA算法在准确度上有一定的提升。以CTR作为评价指标,各算法的结果如图5所示。
可见,在Delicious和Last.fm数据集上,以点击率作为评价指标,仍然是COLINBA和COFIBA的性能最好,但在迭代至收敛时,COLINBA的点击率更高。在Delicious数据集上,LinUCB算法迭代15 000次达到最优值0.17,DynUCB算法迭代15 000次达到最优值0.22,MFLinUCB算法迭代15 000次达到最优值0.23。COFIBA算法的收敛速度最快,迭代10 000次达到最优值0.24。COLINBA的点击率最高,迭代20 000次达到最优值0.27。在Last.fm数据集上Lin-UCB算法收敛速度最快,但是最优值仅为0.19。Dyn-UCB算法迭代15 000次达到最优值0.22。MFLin-UCB算法迭代20 000次达到最优值0.23。COFIBA算法迭代20 000次达到最优值0.24,COLINBA算法的点击率最高,迭代25 000次达到最优值0.25。

Fig.5 CTRof 5 algorithms varying with the number of iterations on 2 datasets图5 在两数据集上5种算法的CTR随迭代次数的变化情况
由上面的结果分析,可以得到以下一般性结论:LinUCB算法为Bandits算法引入了特征的思想,采用置信区间上界算法对新用户进行推荐,并认为回报和相关特征成线性关系,在算法迭代初期有很好的效果,但随着迭代次数增加,其性能无法持续提升。该算法在较短时间内可获得较好推荐效果,因此适用于简单并需要快速处理的应用场景。
MFLinUCB算法在LinUCB的基础上融合了矩阵分解算法,在推荐过程中根据用户对商品真实评价与预测评价的误差,使用矩阵分解算法更新用户特征,再对新的特征使用多臂赌博机算法进行商品推荐。该算法相比LinUCB在性能上有所提升,并且更加适应稀疏数据。
DynUCB算法在LinUCB的基础上采用传统的k-means算法对用户进行聚类,用聚类的整体特征代替类簇内用户特征,从而引入了相似用户的协同作用,在迭代初期效果不错,但是随着迭代次数的增加,用聚类整体特征与用户实际特征偏差较大,无法获得更好的推荐结果。
COFIBA算法和DynUCB算法相比,采用同时对用户和商品聚类的方法,在用户和商品两方面同时引入了协同的效果,其推荐结果比DynUCB更好。
COLINBA算法引入了带有相似度权重因子的邻居用户的协同作用,从而在邻居用户协同的同时保证了用户本身行为偏好的重要性。实验表明随着迭代次数的增加,能够取得更好的推荐效果。
根据实验结果显示,不同的算法在不同的数据集上表现略有不同。对于COLINBA算法,其在Delicious数据集的测试结果要好于Last.fm,故在实际推荐应用中,要根据实际数据集情况选择恰当的算法。
5 结束语
本文提出一种引入邻居协同的多臂赌博机推荐算法COLINBA,基于LDA主题模型提取文本潜在主题的原理,提取商品特征,并根据用户反馈不断修正用户特征向量。该算法具有很好的通用性,能深入挖掘商品评价信息,并利用用户协同提升推荐性能。采用真实数据集进行测试并分析实验结果,验证了本文算法的有效性。下一步将会考虑同时利用用户、商品之间的相似信息构造协同过滤模型,进一步提高推荐精度。
