基于MRMD的滚动轴承损伤程度识别方法研究*
2019-04-08郭佳靖章翔峰冉祥锋
郭佳靖,姜 宏,章翔峰,冉祥锋
(新疆大学 机械工程学院,乌鲁木齐 830047)
0 引言
滚动轴承作为机械设备中易受损的部件之一,其工作条件相对恶劣。一旦发生故障将导致机械设备的严重损坏以及灾难性事故的发生。若能够及时针对滚动轴承损伤程度进行准确评估,更加主动地启动维护模式,对于减少事故发生率,提高设备使用效率都拥有重要的意义及应用价值。
对滚动轴承损伤程度进行准确识别,首先要提取能够表征损伤程度加深的特征量。欧璐等[1]通过提取信号Hilbert包络谱的频率特征和能量熵特征实现轴承故障诊断。程小涵、刘蕴哲等[2-3]结合时频域统计特征和能量谱指标,利用投影寻踪和距离评估判别方法研究特征指标的聚类性和敏感性,筛选出关键特征完成轴承故障识别。本文决定结合时、频域特征指标建立特征集。为降低计算的复杂性及提高分类精度,需将表征轴承损伤状态变化的敏感特征筛选出来。郭宏伟等[4]利用皮尔逊相关系数对选出的特征进行冗余分析,再利用SVMRFE算法筛选出关键特征。肖艳与王欣杰等[5-6]利用ReliefF和F-score特征选择方法剔除冗余特征,实现关键特征的选择。各个特征选择方法的选择标准并不相同,利用单一方法容易造成特征的错选和漏选[7]。因此本文提出一种基于最大相关最大距离的特征选择方法,利用皮尔逊相关系数度量类别与特征间的相关性,利用ReliefF和F-score方法评判特征的类别可分性,以完成关键特征的选择。将筛选的敏感特征子集对应的数据样本输入到概率神经网络[8]分类器中进行训练和识别,完成轴承损伤程度的评估。
1 特征提取及特征集的构建
实现对轴承的损伤程度的准确识别,关键是要找到对损伤状态变化较为敏感和聚类能力强的特征指标。由于轴承故障机理的复杂性,单一特征或单域特征难以全面、准确刻画轴承运行状态的复杂性[9]。针对轴承不同故障对应的振动信号与特征指标的关系已有诸多研究,但是对轴承某一故障损伤程度加深情况下信号与特征指标的关系研究较少。针对轴承损伤状态的变化,特征的敏感性和聚类性也不一样,为选取关键特征以全面描述轴承损伤程度变化,同时能够兼顾所选特征的敏感性和稳定性,决定选取时域特征和频域特征构建多域特征集。时域特征指标共18个,包括12个有量纲指标和6个无量纲指标。频率特征指标共12个。30个特征指标的表达式如表1所示。

表1 时频域特征指标
2 特征选择
多数特征选择方法利用特征间的相关性来排除冗余特征,或通过评估特征的类别可分能力筛选出聚类能力强的敏感特征。然而,在实际计算时只能两两比较特征间的相关性,当特征数目较大时,运算量巨大且效率低下。针对特征冗余性的判断若没有统一标准易造成错误决策,从而影响后续轴承损伤程度识别的准确率[10]。评判特征间的类别可分能力其实就是要找到使不同类别样本的类间距离最大,类内距离最小的特征量。不同距离评判方法拥有不同筛选特性和适用范围,利用单一距离评判方法易造成关键特征的漏选和错选。遂提出一种将相关性评价函数和距离评价函数相结合的特征选择方法。
最大相关最大距离(MRMD)方法的重点是找到一种特征排序度量标准,其中包括:分析目标类别和特征子集间的相关性以及不同特征的类别可分性。本文利用皮尔逊相关系数度量类别与特征间的关联度,利用两种距离评价函数评判特征的类别可分能力。在特征集中选出相关性和距离综合最大的特征,得到低冗余度和目标类关联性强的特征子集。
为便于理解该方法,针对算法中需要用到的概念和已知量进行符号定义。将输入数据D分为N个标签,特征集中共有M个特征F={fi,i=1,…,M},目标类别为C。目标是找到包含m个关键特征的特征子集Rm,达到对不同样本类别的进行分类达到最大贡献。
2.1 最大相关
目标类别C和特征子集Rm具有最大的相关性,此时可以得到最小的分类误差。皮尔森相关系数适用于连续变量的计算并且易于实现,选择该测度计算相关性。
两个向量X和Y的皮尔逊相关系数可以定义为:
(1)
(2)
(3)
(4)
xK和yK是向量X和Y中的第K个元素,结合两个特征向量可以组合为多维向量。特征i的最大相关性可以定义为:
maxMRi=|PCC(Fi,Ci)|(1≤i≤M)
(5)
2.2 最大距离
为进一步排除冗余特征,在最大距离特征评价准则下综合ReliefF和F-score两种特征选择方法完成关键特征的筛选工作。
Relief算法的核心思想是对每个待识别的特征分配一个相关性加权值,使用加权值的大小衡量特征的类别可分能力。本文用其改进算法ReliefF对多类轴承损伤程度样本进行区分。
在该算法中,对每一个不同类都找出所选样本的k个近邻,使用每类的先验概率进行加权,将k个近邻对权值的贡献进行平均实现权值的更新,该方法提高了特征有效性估计的可靠性。其算法的实现过程如下所示:
输入参数:特征权值初始化为零:Wj=0
(1)forj=1:T
从训练样本中选择一个样本x
(2)fori=1:M
找出x的k个同类近邻;
(3)for 从每一个类别C≠class(x)
找出样本x的k个不同类近邻;
(4)计算每个特征的权值
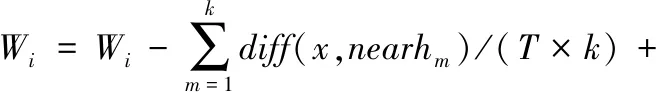
(6)
将计算所得的Wi根据其值大小进行排序,取Wi较大的前k个特征作为所筛选的关键特征。
F-score是一种基于类内类间距离的特征评价算法。实际碰到的问题多是多分类问题,需将原始公式进行改良。文献[11]对原公式进行了具体改进从而适合多分类样本的特征评价问题。
给定样本集xk∈Dm,k=1,2,3,…,n;N为样本类别数,nj为第j类样本的个数,其中j=1,2,…,N。第i个特征的F-score值如下定义:
(7)

通过式(6)和式(7)可以定义最大距离的表达式,如下所示:
maxMDi=max(Wi+Fi)
(8)
2.3 最大相关最大距离
在对计算所得评分进行归一化后,可以线性相加综合反应该特征的类别可分性和类别相关性,结合上述两个约束标准可以定义最大相关最大距离的表达式如下所示:
max(MDi+MRi)
(9)
在式(9)中目标类别与特征子集间的相关性以及不同特征的类别可分性占有相同的权重,利用此公式不一定能得到最优特征子集。因此对最大相关与最大距离赋予不同的权重因子以获得最好的特征选择结果,对式(9)进行改进如下所示:
max(μMDi+(1-μ)MRi)
(10)
式中,μ的取值范围为0≤μ≤1,递增步长为0.1。
3 基于MRMD的轴承损伤程度识别方法
3.1 步骤
利用MRMD特征选择方法进行轴承损伤程度的识别步骤如下:
(1)研究对象为轴承内圈裂纹故障,包括4种不同损伤程度的数据样本,分为训练样本集和待测样本集。对原始数据样本提取时域、频域特征统计量共计30个,组成原始特征集。
(2)将权重因子以0.1为步长进行赋值,即μ=0,0.1,…,1。利用MRMD分别得到不同权重因子对应的特征子集。利用ELM[12]以每次递增一个特征的方式计算分类正确率,以分类正确率为评判标准确定最佳权重因子μ以及应选取关键特征的个数m。
(3)分别采用皮尔逊相关系数、ReliefF、F-score、MRMD特征选择方法,对建立的多域特征集的各个特征进行评分并排序。比较4种特征选择方法的排序结果。将得分高的前m个特征作为敏感特征子集。
(4)同样以分类器正确率为标准,验证4种特征评价方法所筛选的特征子集是否具有较好的类别可分性和类别相关性。将特征子集对应的训练样本输入到PNN分类器中进行训练和测试,根据分类正确率对不同的特征选择方法的性能进行评判,完成轴承损伤程度的识别。
3.2 实验数据分析
为了验证本文所提出方法的有效性,轴承试验数据来源美国Case Western Reserve University 滚动轴承验测试数据[13]。对象选择电动机驱动端支撑轴承,型号为SKF6205。使用电火花加工在轴承上布置单点故障。故障类型选择内圈裂纹故障,裂纹宽度分别为0.18mm、0.35mm、0.53mm、0.71mm。采样频率为12 kHz,转速为1797r/min,采集4种不同损伤程度的数据样本。
每种状态数据样本取28组数据共计112组,每组数据包括4096个点,组成112×4096原始特征矩阵,计算特征值组成112×30特征矩阵作为特征选择算法初始输入信息。类别标签N=4,待选特征子集F中共30个特征,依照前节给出所定义计算公式带入具体参数计算特征评分。利用分类器进行识别时,每种状态数据取16组作为训练样本,12组为测试样本用于轴承损伤程度的识别。
根据已知参数利用MRMD方法按照步骤(2)求取不同权重因子对应的特征子集并进行降序排列。采用ELM分类器测试特征子集,按照排序结果逐一添加特征。ELM激活函数选择Sigmoid函数,隐含层节点数为4。不同权重对应分类正确率的变化如图1所示。
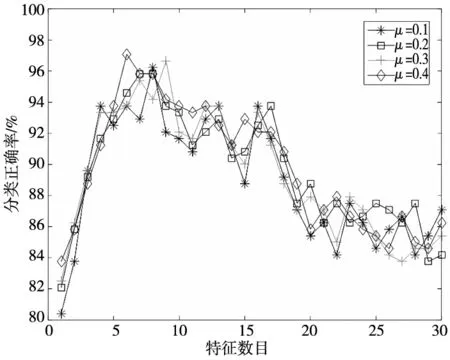
(a) μ=0.1~0.4对应分类正确率曲线

(b) μ=0.5~0.7对应分类正确率曲线

(c) μ=0.8~1对应分类正确率曲线 图1 不同权重对应分类正确率曲线
由图1可知,随着特征数目的增加分类正确率先逐渐增大到达峰值后呈缓慢下降趋势。不同权重对应的最高分类正确率也不同,当μ=0.4时达到最高分类正确率为97.1%,所需特征数目为6个。所以本文选择权重因子μ=0.4,选取前m个关键特征的个数m=6。
接下来采用皮尔逊相关系数、ReliefF、F-score以及本文所提出的MRMD特征选择方法,对建立的多域特征集的各个特征进行评分并排序。依照前节给出的计算公式带入具体参数计算评分,结果如图2所示。
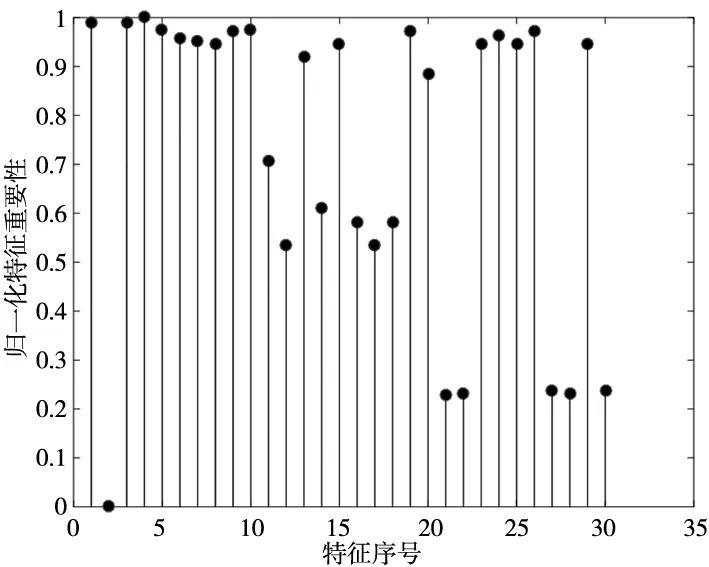
(a) 皮尔逊相关系数评分

(b) F-score评分

(c) ReliefF评分
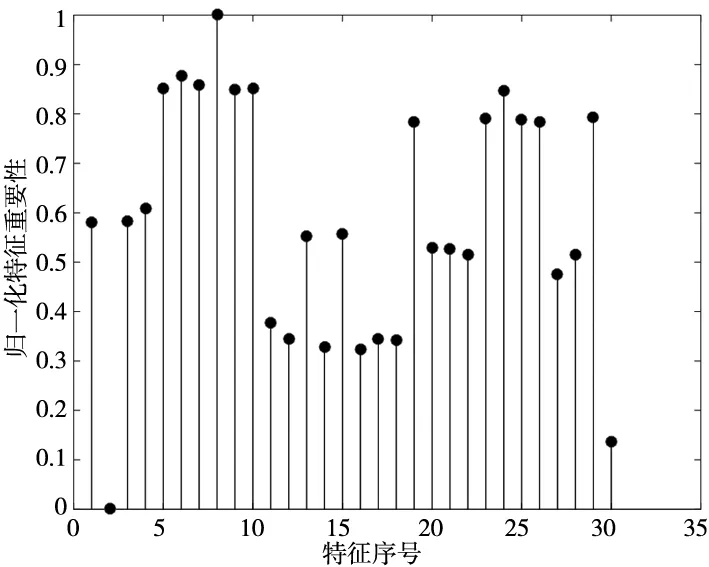
(d) MRMD评分 图2 特征评分结果
由图2中的评分结果可以看出4种特征选择方法得到的评价结果有较大差别。为更直观的了解所筛选特征的重要性,将所有特征值按评分从高到低排序。依照之前计算所得m=6,4种特征选择算法统一选取评分最高的前6个特征,排序结果如表2所示。4种特征选择方法所选取的6个特征存在着较大的差别。为验证MRMD较其他方法拥有较好的特征筛选能力,将4种方法所筛选特征对应的数据分布样本输入到PNN中进行训练和识别,验证MRMD方法所筛特征的类别可分能力。
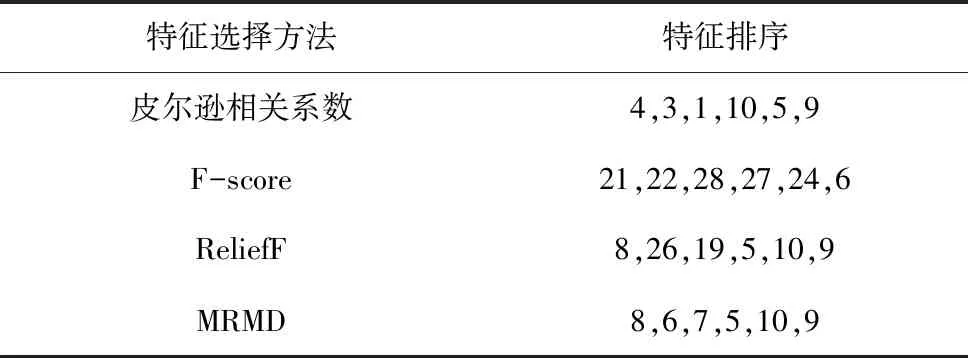
表2 特征排序结果
PNN的学习与训练过程较为简单,能够较快的完成样本的训练和预测工作且噪声对其影响较低,能够用线性方法计算非线性数据。输入层神经元个数特征矩阵的维数30;模式层神经元个数等于总样本数112,激活函数为高斯函数;求和层神经元个数为样本类别数4。
每种损伤状态共计28组数据,其中16组作为训练样本,12组作为测试样本。由于样本均为随机选取,对测试样本重复10次识别过程,得到共计120组样本的损伤程度识别结果,并以平均准确率近似代表实际准确率,分类准确率如表3所示,括号内为识别样本总数。

表3 分类准确率
由表3可以看出,由MRMD所选特征样本输入到PNN分类器中得到的测试集准确率高达97.92%,只有极少部分数据样本出现错误识别。以分类正确率为依据可知MRMD特征选择方法具有较好的特征评价和筛选能力。表中前3种方法特征样本的测试集准确率较低,不能单独使用某一方法进行特征筛选。
4 结束语
针对轴承损伤程度难以识别的问题,以轴承内圈裂纹故障为研究对象,提出一种基于MRMD特征评价准则的特征选择方法,研究30种常用时频域特征指标对不同损伤程度轴承数据的敏感性和类别可分性。利用MRMD方法对所有特征进行评价,将得到的评分来衡量各特征指标的类别可分能力。MRMD方法集成皮尔逊相关系数、F-score、ReliefF特征选择算法,综合考虑不同类别数据样本间的距离以及不同类数据样本和类别标签间的相关性。最后结合西储大学的轴承实验数据,依据评分排序得到6个关键特征。利用PNN分类器进行验证,MRMD方法得到较高的正确率,证明该方法在轴承损伤程度识别方面的可行性和使用价值,其较单一特征选择方法能够筛选出类别可分能力强的关键特征。该方法的提出能为轴承状态的检测和安全运行筛选出可靠特征,提高了轴承故障诊断的准确性和可靠性。
