基于神经网络Q-learning算法的智能车路径规划*
2019-03-14卫玉梁靳伍银
卫玉梁,靳伍银
(兰州理工大学机电工程学院,兰州 730050)
0 引言
机器学习分为监督学习、无监督学习以及强化学习3种,其中强化学习是以环境反馈为学习策略的机器学习方法[1-2]。蒙特卡罗算法、Q学习算法、模拟退火法、遗传算法等都属于强化学习[3];由Watikins提出的Q-learning算法是强化学习算法中应用较为广泛的一种,其特点是不依赖于环境的先验模型[4-5]。因此,Q强化学习算法是一种无模型的在线学习算法[6]。本文采用Q强化学习算法来解决智能小车在行走过程中,特别是在环境中设置除起点和目标位置以外,还有其他路障时的路径规划和规避问题。由于Q学习算法的量化过程会影响到最终的实验效果,从而采用RBF网络对Q强化学习算法进行优化,提高Q学习算法效果,加强智能小车的自治导航能力。
1 Q-learning算法原理
Q学习算法是一种类似于动态规划的强化学习方法[7]。可以为智能系统提供一种学习能力,通过这种能力可以使系统在马尔科夫环境中利用经历的动作序列选择最优动作集,而且这种能力不依赖于马尔科夫环境的模型[8]。所以Q-learning学习算法也是马尔科夫决策过程MDP(Markov Decision Process)的另一种表达形式[9]。
首先将小车路径规划问题建模为有限的、离散的MDP,用数组{S,A,R,P}表示,其中 S 为小车的位置状态空间,A为小车可用控制指令组成的动作空间,R为对应状态的奖赏回报,P为状态之间的转移概率。

图1 强化学习框图
强化学习框图如图1所示,智能小车路径规划决策系统每步可在有限动作集合中选取某一动作,并将这个动作作用于环境中,环境接受该动作后状态发生转移,同时给出奖赏R。例如,小车路径规划决策系统在t时刻选择动作at,环境接受这个动作后由状态st转移到st+1。
上述R及st+1的概率分布取决于at及st。环境状态st以如下概率变化到st+1:

定义表示状态st的值函数,用来从长期的观点确定并选择最优动作,在策略π的作用下:


式(3)表明策略π*能够使值函数Vπ(s)取得最大值。
定义动作值函数Q如下:


又根据式(3),可得:
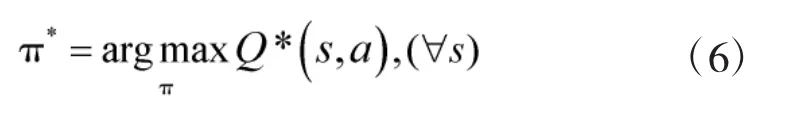
上式表明,在路径规划时仅需要对现在的状态Q(s,a)的局部值不断作出反应,就可以选择出全局最优的移动策略。其迭代公式为:

2 神经网络的Q-learning算法实现
传统Q学习算法的流程如图2所示:随机初始化 Q(s,a)值根据当前 Q 和位置 st,使用一种策略,得到并进行动作at,到达新的位置st+1,获得奖励R更新之前位置的Q值。当达到目标状态时,此次迭代过程结束。

图2 传统Q学习算法的流程
本文利用RBF网络较强的函数逼近能力,实现Q-learning的动作值函数Q进行逼近,网络结构如图3所示。

图3 基于RBF的Q算法网络结构

第2层为隐层,在这一层当中,每一个节点采用P维高斯函数,第K个RBF节点的表达式为:


3 基于Q学习算法智能小车路径规划
Q强化学习系统结构如图4所示,在图4中,整个系统只有一个决策单元,这个单元承担着马尔科夫过程中的动作奖赏R的评价和动作的选择任务。

图4 Q强化学习系统结构
综上所述,Q学习算法在对智能小车的路径进行规划时,不依赖于环境的初始环境,而是在动态环境中实现其路径的规划。为了实施并且准确获取其所处的环境的动态数据信息,判断环境的实际状况,在智能小车上配置有4个距离的传感器,用于检测智能小车与路障之间的距离等,然后通过数据采集电路将这4个传感器获得的位置等信息传递到核心芯片,由其计算所得的结果作为系统的输入,即小车在每个S环境时可作出的动作指令集合为向4个方向的移动,即A={上,下,左,右}系统工作流程如下:
1)对工作环境st进行观测;
2)选定一个动作a并执行;
3)对下一个环境st+1进行观测;
4)接收强化信息rt;
5)调整Q值。
4 仿真实验及结果分析
4.1 基于Q-learning智能小车路径规划算法仿真GUI仿真系统
为了验证本文所采用算法的有效性及相对于其他算法的优越性,基于MATLAB平台建立了Q-learning智能小车路径规划算法GUI仿真系统,其界面如图5所示。
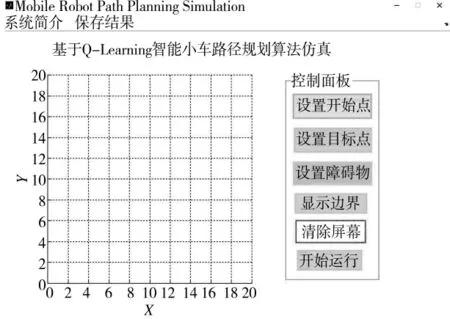
图5 小车路径规划GUI仿真系统
系统中主要包含了“显示”和“设置”两大块,通过右边的“设置”来定义仿真过程中的智能小车的起点、终点以及运动过程中的各种路障。在界面的任务栏上同时设置了系统简介以及保存结果两个功能选项。
4.2 仿真结果
本文中在简单路障和复杂路障两种环境下进行仿真研究,同时加入基于势场的Q学习算法作为比较,具体仿真结果如图6和下页图7所示。
1)简单路障下的路径规划效果
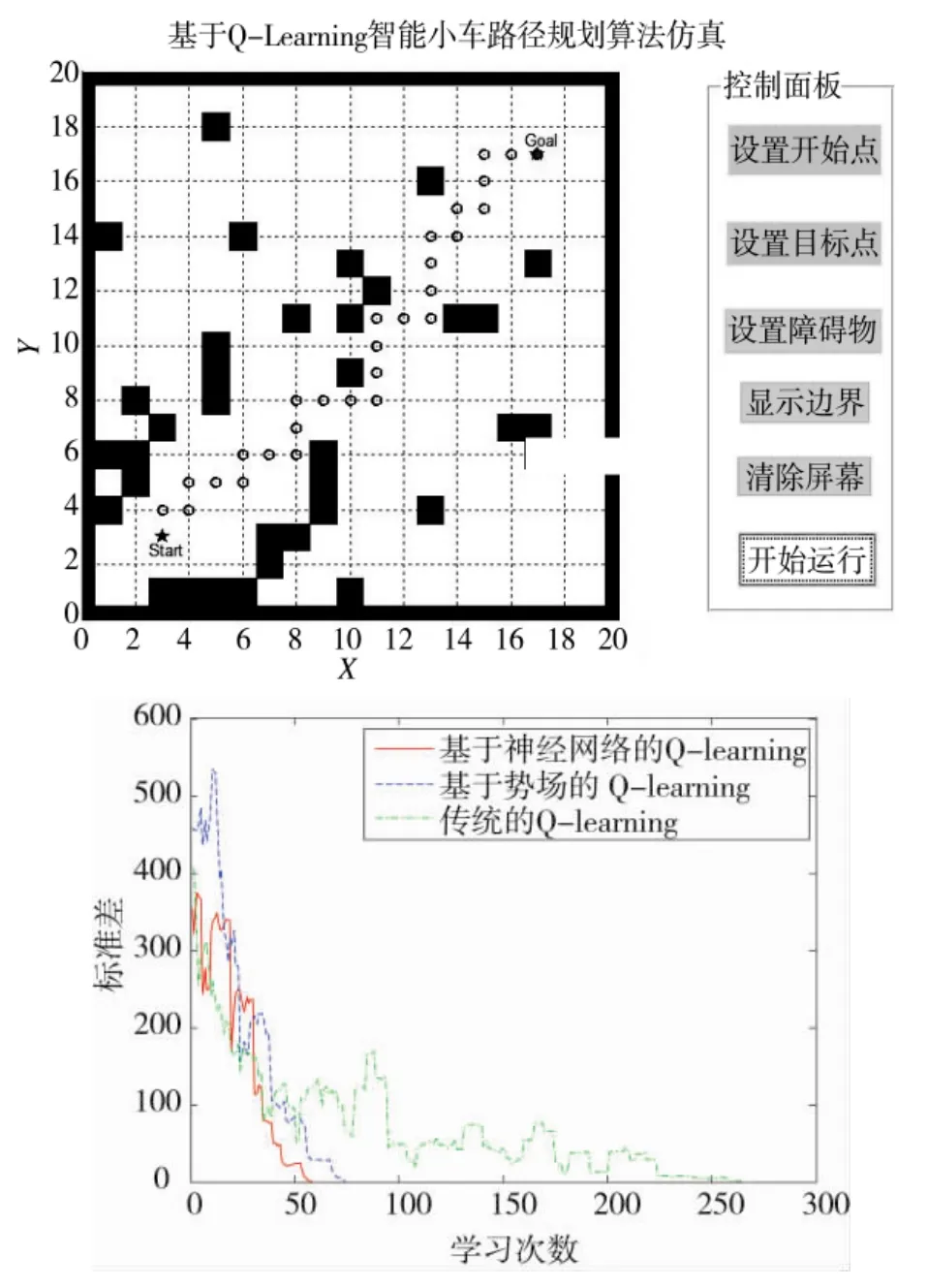
图6 简单路障下的路径规划效果
2)复杂路障下的路径规划效果
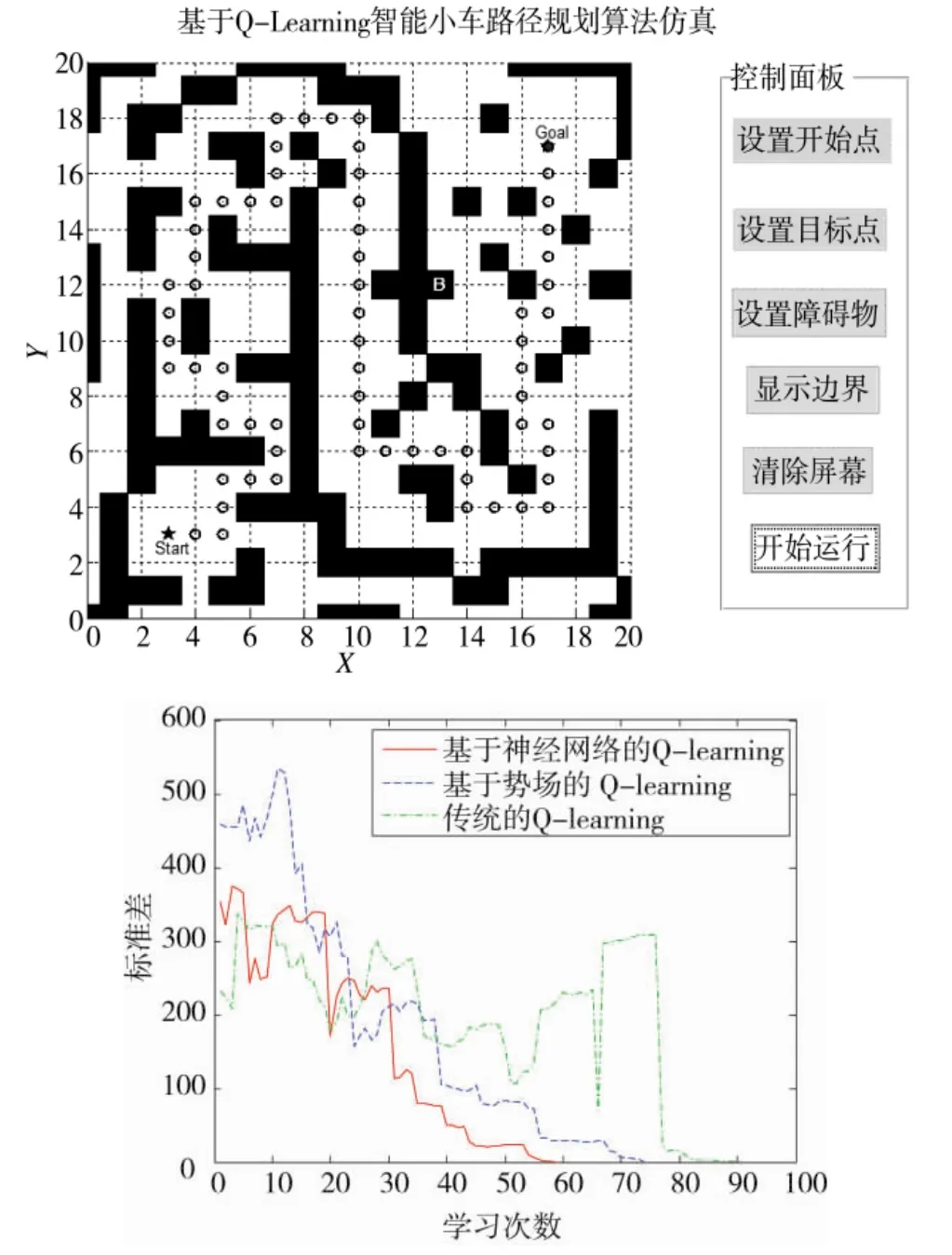
图7 复杂路障下的路径规划效果
上述仿真结果表明,本文所提出的算法能够实现智能小车行走过程中的全局路径规划,对在环境中设置有除起点和目标位置以外的路径规划和路障规避问题有着良好的表现。同时对于Q算法而言,本文所采用的基于神经网络Q-learning算法无论是在相对简单或是相对复杂的环境中,其效率均为最高,收敛速度也最快,其次是基于势场的Q-learning算法,传统的Q-learning算法收敛速度最慢、效果最差。
5 结论
本文针对智能小车行走过程中的全局路径规划和路障规避问题,提出了一种基于神经网络Q强化学习算法。利用MATLAB开发了基于神经网络Q-learning强化学习算法智能小车全局路径规划和路障规避仿真平台,仿真结果表明:
1)本文所提出的算法能够实现智能小车行走过程中的全局路径规划,对在环境中设置有除起点和目标位置以外的路径规划和路障规避问题有着良好的表现。
2)基于RBF网络逼近的Q-learning算法相对与其他两种算法其效率最高,收敛速度最快,大大地提高路径规划的效果和收敛速度。
3)基于Q学习算法的策略能使智能小车获取自学习功能,增强了其自导航的能力。为移动机器人、无人车等在货物运输、智能驾驶以及军事方面的应用提供了一定的参考意义。
