基于分词的关联规则预测系统研究
2018-12-13王志超孙建斌秦瑞丽
王志超 孙建斌 秦瑞丽
(航天长征化学工程股份有限公司 北京 101111)
0 引 言
由于媒体的丰富和网络的快速传播,新闻已经成为大数据的一个重要组成部分。新闻包括传统报刊杂志新闻,如《人民日报》《化工报》等;也包括各门户网站和新闻网站的实时新闻,如新浪、百度等。在我国,最重要的新闻报道往往聚焦于政府政策动向的跟踪和及时传播,时效性影响重大。然而,重大政策的形成往往有一个过程,包括初期的调研论证、理论研究、政策试探、舆论反应、试点安排、政策修订、正式颁布实施等阶段,每一个阶段都有大量新闻的跟踪和报道。对该类新闻进行深度挖掘和学习,利用关联规则研究其频繁项集,可以根据产生的频繁项集得到一段时间内关注任务的关联因子的变化,由此可以提前预测相关政策和动向的变化。
利用新闻进行预测,是国内外学者对舆情监控的研究热点之一。唐晓波等[1]提出在互联网新闻文本信息挖掘中,融合新闻热度和读者态度建立高频情感词典,在新闻文本预测分析中对预测结果利用情感频度加权排序,可以获取更好的准确性。然而该方法在新闻推荐等领域可用,在缺乏“情感频度”或不宜收集“情感频度”方面效果不明显。庞有明等[2]在研究信用债估值时引入新闻舆情语料,并重点关注舆情的情绪变化,然而该方法对于实际的应用效果不太明显。Patel等[3]在股票市场走向预测分析中,引入新闻舆情监控,并利用分类、还原和统计技术进行研究,用于指导投资。Xu等[4]利用极端机器学习和灰度Verhulst模型理论在热点新闻点击率预测上应用有一定效果。然而,对于新闻的理解,分词技术的应用是基础。张洪刚等[5]在分词方法中利用双向长短时记忆模型,但该方法较为复杂。李雪莲等[6]提出基于门循环单元神经网络的中文分词法,试图解决长短时记忆模型的复杂性。
本文提出利用基于隐层马尔可夫模型的中文分词方法[7,9]并以报纸及刊物新闻作为数据源,通过对新闻数据预处理及关联规则挖掘[10-11],进行行业政策和发展方向预测研究,并以“煤化工”行业为例。首先,选取新闻标题作为本文预测任务的原始数据集,对新闻标题进行分词;其次,将分词所得的每组新闻标题词集进行语义统一,作为关联规则研究的项集;最后,利用Apriori算法对事务集进行关联规则挖掘,得到以“煤化工”等为关键字满足最小支持度和最小置信度的关联规则,并以此作为煤化工政策和发展方向的预测依据。实验证明,基于新闻分词的关联规则挖掘对政策和方向预测具有很好的作用。
1 新闻标题分词技术研究
分词是指将完整的一句话根据其语义分剪成一个词语项集,该词语项集作为参与关联规则挖掘的基本单元[5-6]。语义分词分两步:
(1) 基本分词 对新闻标题做初始分词,如2014年8月22日《中国化工报》行业时评刊文标题《传统煤化工要有“世界级”理想》,进行初步分词后其结果为:
“传统 /j 煤化工 /n 要 /v 有 /v “ /w 世界级 /b ” /w 理想 /n”。
其中,各词后面所标注“/”为词性,根据英文文法词性标注。
(2) 词语修剪及语义统一 将基本分词所得词集中无实意的虚词及一字动词等剪掉,只保留部分实词,包括动词、名词、量词、代词等,无意义词通过词性标注即可识别,如标注为“/w”即为标点符号,而一字动词则通过词性和词长识别。词语实化即对初始分词集合进行语义统一,如代词(词性为“/p”)变为实词、比喻中的喻意词(词性为“/m”)变为本意词等,该例中词语修剪后的词集不存在代词等,所以保留修剪后词集结果不变。该步结果为:
“传统 /j 煤化工 /n 世界级 /b 理想 /n”。
语义统一是将代词实化、喻词本意化,同时也是建立关联规则类的一个关键步骤。
1.1 基于ICTCLS的基本分词
ICTCLS是中科院计算所研发的汉语分词系统,采用了层叠隐马尔可夫模型以完整统一理论框架进行分词。本文以此为基础做新闻标题的初始分词。
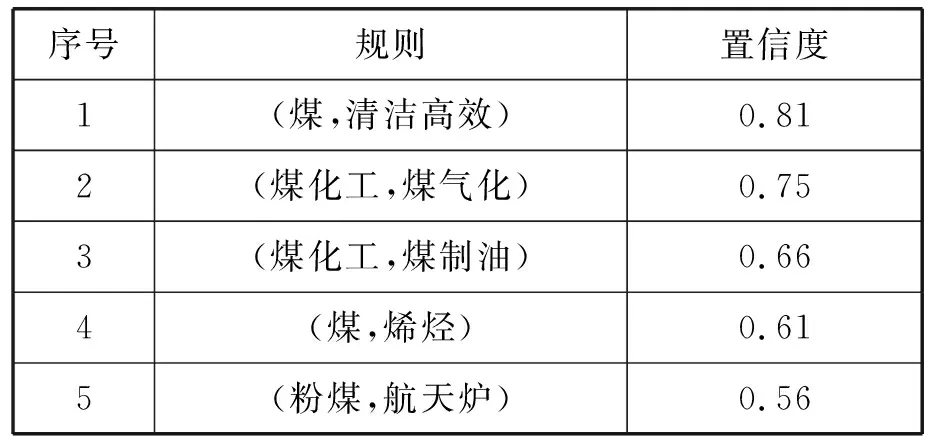
定义1(分词句集) 设S={s1,s2,…,si,…,sn},其中,si为第i个原始句串,1 对分词句集S中第k个原始句串sk进行基于层叠隐马尔可夫模型的ICTCLS分词,sk∈S。首先对sk进行原子切分,即将原始句串标记开始结束,并将各字单独为词;其次对原子切分序列进行N-最短路径粗切分,找到相邻单字组词后序列联合概率最优N结果;对最优N结果进行人名地名识别;最后对识别后的N结果优化并标注类及词性,输入分词结果,表示为Mk,Mk={mk1,mk2,…,mkj},其中mkh(h=1,2,…,j)为原始句串sk分词结果集中的第h个词语。Mk作为中间项集进行分词修剪及实化,而分词句集产生的每一个Mk组成了预事务集。 定义2(预事务集) 设M={M1,M2,…,Mn},其中Mk(k=1,2,…,n)为分词句集第k个句子的分词结果集,Mk={mk1,mk2,…,mkj},其中mkh(h=1,2,…,j)为分词结果集中的第h个词语。M作为ICTCLS分词结果的预事务集,进行下一步的词语修剪及语义统一。 ICTCLS算法分词后,得到预事务集M作为本节进行分词修剪和语义统一的对象。由于原始新闻标题分词后存在无实意词,如虚词“的、地”,单字动词“有、做”等。分词修剪及语义统一的目的即为生成适宜关联规则算法处理的数据集,将无实意词去掉后的数据集大小少于处理前,使得算法处理的干扰减小且计算速度更快,而语义统一即是将预事务集标准化,得到更为准确的事务集,也使得关联规则计算更加精确。 定义3(项集) 定义2所得Mk经分词修剪和语义统一后的词语集合即为项集,用Ik表示。Ik={ik1,ik2,…,ikj},其中ikh(h=1,2,…,j)为二步分词所得词语,是参与关联规则的元数据。 定义4(事务集) 设D={I1,I2,…,In},其中Ik(k=1,2,…,n)为项集,则D为参与关联规则挖掘的事务集。 具有修剪及语义统一分词算法ICTCLS_TRIM算法描述如下: BEGIN INPUTS //S为分词句集 FORk=1 ton Mk=ICTCLS(Sk) //对每一项句集应用ICTCLS做初始分词 Ik=Reduce&Unify(Mk) //对预处理项集进行分词修剪及语义统一 ENDFOR Split(D, Array(Keywords)) //关键字修剪,将非目标项集过滤掉 OUTPUTD //D为任务相关事务集 END 由于本文针对特定行业特定方向的新闻分词关联规则挖掘,所以在上述算法中,利用Split(D, Array(Keywords))将非含关键字和关键义的项集修剪掉,使得关联规则挖掘数据集更加精确,事务集D作为关联规则挖掘的数据录入。 本文采用改进的Apriori算法对形成的事务集进行关联规则分析,Apriori算法是由Rakesh Agrawal和Ramakrishnan Srikant两位博士在1994年提出的关联规则挖掘算法[12]。该算法主要用于对频繁项集的递归挖掘,在所有满足最小支持度的频集中,发现满足最小可信度的强关联规则。 定义5(支持度) 即某项集X在事务集D中出现的概率,用Supp(X)表示,如下所示: Supp(X)=Occor(X)/Count(D) 最小支持度即为满足最小Supp(X)的项集,当给定最小支持度Supp(CONST)时,如果存在Supp(X) >Supp(CONST),则称X为频繁项集。 定义6(置信度) 即在频繁项集X出现的条件下,频繁项集Y也出现的条件概率,表示为Conf(X→Y)=Supp(X∪Y)/Supp(X)。 新闻分词关联规则算法,基于分词的关联规则算法Apriori_Split描述如下: BEGIN INPUTS //S为原始新闻标题 D=ICTCLS_TRIM(S) //通过具有语义修剪的ICTCLS进行分词 L1=Large_Supp(D,Supp_THRESHOLD) //选取满足最小支持度的1_项集 FORk=2 ton Ck=apriori-gen(Lk-1) FORdi∈Ddo Ci=subset(Ck,di); //事务di中包含的候选集 forCi∈Ctdo Ci.count++ ENDFOR Lk={Ci∈Ck|Ci.count3minsup} ENDFOR 算法Apriori_Split中,首先利用具有语义修剪的新闻分词算法ICTCLS_TRIM将原始新闻集变成适于关联规则的事务集。通过计算支持度和置信度产生频繁1-项集L1,对各1-项集进行关联规则的计算。在第k次循环中,过程先产生候选k-项集的集合Ck,Ck中的每一个项集是对两个只有一个项不同的属于Lk-1的频集做一个(k-2)-连接来产生的。Ck中的项集是用来产生频集的候选集,最后得到频集Lk,而Lk也必然存在Lk∈Ck。算法经过两次循环,其算法复杂度为O(n2)。 本文基于新闻分词的关联规则,实验数据集选取2014年7月31日至2014年9月3日期间,包括《中国化工报》、《山西日报》、《中国煤炭报》、《山西经济日报》、《昌吉日报》、《中国国土资源报》等在内的众多报刊中标题、摘要、正文中存在“煤化工”关键字的前100项新闻标题为本次实验数据集。 本实验中,为提高计算速度,为多关键字进行编号并处理,如本文实验数据集: {煤,煤化工,煤科,煤层气,粉煤,…},即编号为{1,2,3,4,…},则试验中ID为1的关键词即为“煤”,而如果某一新闻分词组中出现“煤”的次数为2则数据标记即为{1 2},该表示方式{IDTimes},ID为数据集编号,Times即为出现次数,如此将实验数据集进行处理。 发展方向类={甲醇,煤制气,煤气化,煤油气,热变换,煤电,聚丙烯,…} 关联规则的类的设定属于半监督,该处基于专家知识形成,即分类越科学,规则生成越准确。由此,根据本文所定规则及数据集进行试验,前五个规则结果如表1所示。 表1 预测实验结果表前五项结果 结果分析:本文试验中以置信率大于0.5进行结果的筛选,并展示了前五项试验结果。其中置信率最高的为(煤,清洁高效),这也反映了当前环保的趋势,(煤化工,煤气化、煤制油)反映了煤化工产业的工艺方向,而(媒,烯烃)则反映的是当前中国煤化工的产品结果,(粉煤,航天炉)则是粉煤应用较多的技术标准。实验表明,本文方法给出的预测方向同当前的方向是匹配的,极大地提高了预测的准确性。 本文提出基于分词的关联规则预测方法,首先对待预测方向近期新闻标题进行层叠隐马尔可夫模型的初步分词,对得到的词集进行虚词修剪及喻词实化等语义统一,该步骤得到的事务集通过分词修剪和语义实化后更加精确,降低了无义词的干扰。最后通过本文提出的基于分词的关联规则算法Apriori_Split对事务集进行计算,得到预测方向的规则,并以此为依据形成对未来发展的预测。该方法由于对参与关联规则的事务集的精确处理,有效提升了关联规则预测的准确性。1.2 分词修剪及语义统一
2 分词关联规则Apriori_关联规则算法
3 实 验
4 结 语
